导表工具开发(支持 JSON,Python,Lua,JS)
一 需求
1 提取需求
在正式的游戏开发团队中,策划很大一部分工作内容的产出,都是以 Excel 表格的形式。给到程序员后,通常都不会直接读取 Excel 表格的内容,而是先将 Excel 表格内容转换成程序语言能够识别的文本格式,比如:比较通用的 JSON格式,或者是 Lua 中的 Table,python 中的 Dictionary 等。
那么,需求就出来了:实现一个工具,读取 Excel 表格内容,转换成各语言能够直接识别的文本格式。
2 需求分析
用面向对象的思维来分析上述需求,至少有读和写两个对象。此外,还需要一个配置文件,来指定要读取 Excel 表格的路径,指定 Sheet,以及输出文件的路径;最重要的是,要定义表格中配置的数据格式。按照实现的顺序,总结如下:
- Define 对象——配置输入输出信息
- Reader 对象——读取 Excel 表格的内容
- Writer 对象——将读取的内容按不同格式存储到文本文件
上面提到的数据格式,需要提前确定,一般数据的格式有简单类型:整数,浮点数,布尔值,字符串,复合数据类型:数组和字典。假如策划输出了如下这样一张表格:
| 整数 | 浮点数 | 布尔值 | 字符串 | 数组 | 字典 | 备注 |
|---|---|---|---|---|---|---|
| 测试默认值 | ||||||
| 1 | 0.1 | 0 | a | 11.1 | hp:10 | |
| 2 | 1.1 | 1 | bb | 11.1;22.2 | hp:10;mp:20 | |
| 3 | 1.2 | 0 | ccc | 11.1;22.2;33.3 | hp:10;mp:20;atk:30 |
关于上面的配置文件,有几个点解释下:
- 备注列不导出,留给策划做下记录和说明等
- 数组和字典每一项之间这里用分号;分隔,这个分隔符可以在配置表中指定,避免字符串中有分号时,不好导出。
Excel 表格内容如图:

二 功能实现
在实现功能之前,先选取一门语言,“Life is short, you need Python”,寒风这里用的是 Python 实现的,当然也可以用其他语言实现,比如 nodejs 等。
1 配置文件
前面已经提到,配置文件中主要有两部分内容:
- 文件配置
- Excel 文件的路径
- Excel 文件中要导出 Sheet 的名字
- Sheet 表格中的主键
- 输出文件路径
- 数据类型定义
- Int
- Float
- Bool
- Str
- Array
- Dict
从 Excel文件表格中读出来的数据都是字符串格式,需要各种转换器,将读取到的数据转换成指定格式,这个转型也在配置文件中指定。在此之前,要先定义好各种数据类型的转换器:
class Converter(object):
"""类型转换器父类"""
def get_error_desc(self, data):
# 转换出错时返回的错误信息
return "%s 不是有效的 %s" % (data, self.__class__.__name__)
def get_default(self):
# 表格中没有配置数据时的默认信息,不同数据类型的默认值不一样,必须重写
raise NotImplementedError()
def convert(self, data):
# 数据转换方法,不同数据类型不一样,必须重写
raise NotImplementedError()
class Int(Converter):
def get_default(self):
return 0
def convert(self, data):
if data == "":
return self.get_default()
# 先转成 float,防止从配置表中读出来的数据是 “1.0” 这种,直接转换整形失败
return int(float(data))
class Float(Converter):
def get_default(self):
return 0.0
def convert(self, data):
if not data:
return self.get_default()
return float(data)
class Bool(Converter):
def get_default(self):
return False
def convert(self, data):
if data == "":
d = self.get_default()
else:
d = bool(int(data))
return d
class Str(Converter):
def get_default(self):
return ""
def convert(self, data):
t = str(data)
data = t.replace("\n", "\\n")
try:
f_value = float(data)
if int(f_value) == f_value:
data = str(int(f_value))
return data
return data
except Exception:
return data
class Array(Converter):
def __init__(self, date_type, split_char):
self.data_type = date_type
self.split_char = split_char
def get_default(self):
return []
def convert(self, data):
data = str(data)
if data == "":
return self.get_default()
item_list = data.split(self.split_char)
d = [self.data_type.convert(x) for x in item_list]
return d
class Dict(Converter):
def __init__(self, key_type, date_type, split_char):
self.split_char = split_char
self.key_type = key_type
self.data_type = date_type
def get_default(self):
return {}
def convert(self, data):
data = str(data)
if data == "":
return self.get_default()
d = [kv for kv in data.split(self.split_char)]
dict_data = {}
for kv in d:
(key, val) = kv.split(":")
dict_data[self.key_type.convert(key)] = self.data_type.convert(val)
return dict_data
数据类型定义完之后,就可以写配置文件。寒风这里目录结构如下:
proj
----test
----------def
----------in
----------out
所有脚本都放在 proj 下面,测试内容放在 test 下面,其中 define 目录放配置文件,in 目录放 Excel 文件,out 目录是生成各语言的文本文件存放目录。这个目录在正式项目中,根据项目实际情况修改,路径在配置文件中做响应的修改。上文示例中的 Excel 表格 的定义如下:
config = {
# 指定Excel文件(支持绝对路径和相对路径)
"source": "./test/in/test.xlsx",
# Excel文件的Sheet名字
"sheet": "SheetTest",
# 指定键值(上面第二列),如果没指定,默认以id为键值
"key": "int",
# 指定导出的目标文件(支持绝对路径和相对路径)
"target": (
"./test/out/test.json", # 导出 Json
"./test/out/test.py", # 导出 Python
"./test/out/test.lua", # 导出 Lua
"./test/out/test.js", # 导出 Javascript
),
}
# 表头数据类型转换定义
define = (
# 第一列:Excel的列名,第二列:导出的字段名,第三列:字段类型
("整数", "int", Int()),
("浮点数", "float", Float()),
("布尔值", "bool", Bool()),
("字符串", "str", Str()),
("数组", "array", Array(Int(), ";")),
("字典", "dict", Dict(Str(), Int(), ";")),
)
为了配置文件导入之后使用起来更方便,把配置文件变成一个对象。
class Define(object):
def __init__(self, define_filepath):
module_name = os.path.splitext(os.path.split(define_filepath)[1])[0]
define_module = __import__(module_name)
config = getattr(define_module, "config", None)
define = getattr(define_module, "define", None)
# 输入文件信息
self.excel_file = config.get('source')
self.sheet_name = config.get('sheet')
self.data_key = config.get('key')
# 导出文件列表
self.export_file_list = []
target = config.get('target')
for target_item in target:
target_file = os.path.abspath(target_item)
self.export_file_list.append(target_file)
# 数据类型定义二次处理
self.name_item_dict = {} # 列名对应导出的key
for idx, item in enumerate(define):
col_name = item[0] # 列名
self.name_item_dict[col_name] = item
Define对象的参数是配置文件的路径,这个类主要的功能是把配置文件中各数据,变成对象的一个属性,这样使用起来更加方便;另外还把定义文件转换成了以列明为 key 的字典,目的也是一样,方便使用。
2 读取 Excel
配置文件都弄好之后,就是读取 Excel 文件表格的内容。Python有很多成熟的第三方库可以读取 Excel 文件,寒风这里用的是 xlrd。安装好 Python 环境之后,使用 pip install xlrd 安装。主要设计用到库中三个函数:
- open_workbook 打开一个 excel 文件,返回一个 excel 对象
- sheet_by_name 获取 excel 对象中的 sheet,返回 sheet 对象
- cell 获取单元格对象,返回单元格对象
具体使用方式,可以参数官方文件,也可以参考下面的代码:
class Reader(object):
def __init__(self, define_obj):
self.define_obj = define_obj
excel = xlrd.open_workbook(self.define_obj.excel_file, encoding_override="utf-8")
sheet = excel.sheet_by_name(self.define_obj.sheet_name)
# 获取要导出的列及其下标
source_key_idx = {}
for col in range(0, sheet.ncols):
col_name = sheet.cell(0, col).value
if col_name in define_obj.name_item_dict:
source_key_idx[col_name] = col
# 读取数据
self.data_dict = {}
for row in range(1, sheet.nrows):
row_dict = {}
for col_name, item in define_obj.name_item_dict.items():
data_key = item[1]
type_class = item[2]
col = source_key_idx.get(col_name)
value = sheet.cell(row, col).value
row_dict[data_key] = type_class.convert(value)
table_key = row_dict[define_obj.data_key]
self.data_dict[table_key] = row_dict
Reader 对象,需要的参数是一个 define 对象,通过 define 对象可以获取到要读取的 Excel 表格信息。因为不是所有的列都需要导出,比如备注列,无需导出,所以在遍历之前,首先获取了需要导出的列,避免容易列的遍历。
Reader 写完之后,先测试一下已完成的代码,新键一个main 文件,在其中写上测试代码,如下:
if __name__ == '__main__':
# 添加文件搜索路径
path = os.path.abspath("./test/def/")
sys.path.append(path)
define_filepath = "./test/def/test_def.py"
define = Define(define_filepath)
reader = Reader(define)
print(reader.data_dict)
要注意的是,首先要将配置文件路径,添加到搜索路径中,否则在 Define 对象中 __import__ 时会找不到模块。下面是打印出来的内容:
{
0: {
'int': 0,
'float': 0.0,
'bool': False,
'str': '',
'array': [],
'dict': {}
},
1: {
'int': 1,
'float': 0.1,
'bool': False,
'str': 'a',
'array': [11],
'dict': {
'hp': 10
}
},
2: {
'int': 2,
'float': 1.1,
'bool': True,
'str': 'bb',
'array': [11, 22],
'dict': {
'hp': 10,
'mp': 20
}
},
3: {
'int': 3,
'float': 2.1,
'bool': False,
'str': 'ccc',
'array': [11, 22, 33],
'dict': {
'hp': 10,
'mp': 20,
'atk': 30
}
}
}
可以看到,这是 Excel 表格中的数据,已经正确的读取到内存中了,接下来,要将这些内容保存为各语言能够识别的文本文件。
3 写文本
3.1 基类
写文本有多中格式,每种格式不一样,因此需要先定义一个父类
class Writer(object):
def __init__(self, data_dict, filepath):
self.data_dict = data_dict
self.filepath = filepath
def save(self):
raise NotImplementedError()
传入一个字典和输出文件路径,这字典就是 Reader 中的读取到的内容;filepath 输出文件的路径,在 Define 对象中可以拿到。父类要求子类提供 save 方法,用于保存内容到文件。
3.2 JSON 格式
对于每种格式类型,从最简单的 json 开始,因为 python 提供了 dump 方法,因此可以直接将字典保存为 json 文件。
class WriterJSON(Writer):
def save(self):
with open(self.filepath, "w", newline="\n") as f:
json.dump(self.data_dict, f, indent=2)
有两个地方需要留意:
- 打开文件时,通过 newline 参数指定了文件的换行符,否则不同系统会不一致(windows:\r\n,mac:\r,linux:\n)
- 写文件时,通过 indent 指定缩进,不指定时,会保存为一行
在上面main文件中导入WriterJSON,加上下面2行代码 :
writer = WriterJSON(reader.data_dict, define.export_file_list[0])
writer.save()
运行可以看到保存的 json 文件 test.json,其部分内容如图所示:

3.3 Python 格式
Python 文件没有像 JSON 那样,直接可以调用的 dump ,因此需要实现一个 dump 方法。
class WriterPy(Writer):
@staticmethod
def dump(obj, root=False):
s = ''
if isinstance(obj, int) or isinstance(obj, float):
s += str(obj)
elif isinstance(obj, str):
s += '"' + obj + '"'
elif isinstance(obj, list):
s += '('
for i in range(len(obj)):
s += WriterPy.dump(obj[i])
if i == 0 or i < len(obj) - 1:
s += ', '
s += ')'
elif isinstance(obj, dict):
keys = obj.keys()
sorted(keys)
if root:
s += '{\n'
for k in keys:
v = obj[k]
s += '\t' + WriterPy.dump(k, False) + ': '
s += WriterPy.dump(v) + ', \n'
s += '}'
else:
i = 0
c = len(obj)
s += '{'
for k in keys:
v = obj[k]
s += WriterPy.dump(k, False) + ': '
s += WriterPy.dump(v)
if i < c - 1:
s += ', '
i += 1
s += '}'
return s
def save(self):
file_name = os.path.split(self.filepath)[-1]
val_name = os.path.splitext(file_name)[0]
content = "# -*- coding: utf-8 -*-\n\n"
content += val_name + " = " + WriterPy.dump(self.data_dict, True)
with open(self.filepath, 'w', encoding='utf-8') as f:
f.write(content)
实现了一个 dump 类方法,根据数据将其转换成字符串,对于复合数据类型,需要递归转换。在保存文件之前,还加入了编码声明和变量名,变量名使用的是文件名,方便导入,当然也可以使用一个固定的名字,比如 data 之类的。在 main 文件中加入导入文件,加入以下2行测试代码:
writer = WriterPy(reader.data_dict, define.export_file_list[1])
writer.save()
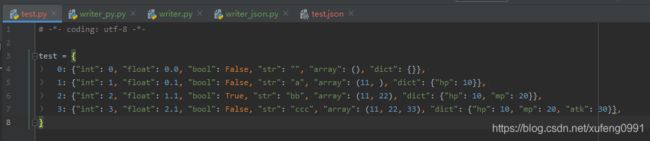
运行可以看到导出的文件 test.py ,其内容如下:
3.4 Lua 格式
同样,Lua 文件也是需要自己实现 dump 方法的,其方法大致跟 python 的一样。
class WriterLua(Writer):
@staticmethod
def dump(obj, root=False, is_key=False):
s = ""
if isinstance(obj, bool):
s += "true" if obj else "false"
elif isinstance(obj, int) or isinstance(obj, float):
if is_key:
s += "[" + str(obj) + "]"
else:
s += str(obj)
elif isinstance(obj, str):
if is_key:
s += obj
else:
s += '"{}"'.format(obj)
elif isinstance(obj, tuple) or isinstance(obj, list):
s += "{"
for i in range(len(obj)):
s += WriterLua.dump(obj[i])
if i == 0 or i < len(obj) - 1:
s += ", "
s += "}"
elif isinstance(obj, dict):
if root:
keys = obj.keys()
sorted(keys)
s += "{\n"
for k in keys:
v = obj[k]
s += "\t" + WriterLua.dump(k, False, True) + " = "
s += WriterLua.dump(v) + ", \n"
s += "}"
else:
i = 0
c = len(obj)
keys = obj.keys()
sorted(keys)
s += "{"
for k in keys:
v = obj[k]
s += WriterLua.dump(k, False, True) + " = "
s += WriterLua.dump(v)
if i < c - 1:
s += ", "
i += 1
s += "}"
return s
def save(self):
file_name = os.path.split(self.filepath)[-1]
val_name = os.path.splitext(file_name)[0]
content = WriterLua.dump(self.data_dict, True)
content = "local " + val_name + " = " + content
content += "\n\nreturn " + val_name
with open(self.filepath, 'w', encoding='utf-8') as f:
f.write(content)
测试方法跟 Python 一样,结果如下:

3.5 Javascript 格式
为什么已经有了 JSON 还需要 js 格式的呢,因为在 cocos creator 中,JSON 格式文件是异步加载的,如果是要 require ,需要使用 js 格式的模块。
class WriterJs(Writer):
@staticmethod
def dump(obj, root=False):
s = ''
if isinstance(obj, bool):
s += 'true' if obj else 'false'
elif isinstance(obj, int) or isinstance(obj, float):
s += str(obj)
elif isinstance(obj, str):
s += '"' + obj + '"'
elif isinstance(obj, list) or isinstance(obj, tuple):
s += '['
for i in range(len(obj)):
s += WriterJs.dump(obj[i])
if i == 0 or i < len(obj) - 1:
s += ', '
s += ']'
elif isinstance(obj, dict):
if root:
i = 0
c = len(obj)
keys = obj.keys()
sorted(keys)
s += '{\n'
for k in keys:
v = obj[k]
s += '\t' + str(k) + ': '
s += WriterJs.dump(v)
if i < c - 1:
s += ', '
s += '\n'
i += 1
s += '};'
else:
i = 0
c = len(obj)
keys = obj.keys()
sorted(keys)
s += '{'
for k in keys:
v = obj[k]
s += str(k) + ': '
s += WriterJs.dump(v)
if i < c - 1:
s += ', '
i += 1
s += '}'
return s
def save(self):
file_name = os.path.split(self.filepath)[-1]
val_name = os.path.splitext(file_name)[0]
content = 'let ' + val_name + ' = ' + WriterJs.dump(self.data_dict, True)
content += '\nmodule.exports = {}; '.format(val_name)
with open(self.filepath, 'w', encoding='utf-8') as f:
f.write(content)
导出内容如下:

至此,已经实现了4种格式的导出格式文本,如果后续还有别的格式,只需添加 Writer 的子类即可。
三 整合流程
在每个功能都完成之后,需要将流程整合起来。在新增配置文件之后,无需改动任何代码,就能导出。因为整个导表工具的输入输出配置都是在配置文件中,可见传入配置文件的目录,每次导出整个目录中全部的 define 文件。
# 根据文件后缀名获取对应的存储对象
FORMAT2OBJ = {
"json": WriterJSON,
"py": WriterPy,
"lua": WriterLua,
"js": WriterJs,
}
def scan_define_files(define_dir):
"""
扫描目录下所有的 py 文件
:param define_dir: define文件所在的目录
:return: define 文件列表
"""
define_files = glob.glob1(define_dir, '*.py')
return [os.path.join(define_dir, file_name) for file_name in define_files]
def do_export_file(define_filepath):
print(define_filepath)
define = Define(define_filepath)
reader = Reader(define)
print(reader.data_dict)
for filepath in define.export_file_list:
filename = os.path.basename(filepath)
suffix = filename.split('.')[1]
writer_class = FORMAT2OBJ.get(suffix)
writer = writer_class(reader.data_dict, filepath)
writer.save()
def export_dir(path):
# 设置为搜索路径,方便导入定义文件
path = os.path.abspath(path)
sys.path.append(path)
defile_files = scan_define_files(path)
for filepath in defile_files:
do_export_file(filepath)
if __name__ == '__main__':
dirname = os.path.abspath("./test/def/")
export_dir(dirname)
如果是有多个项目,还可以继续将配置文件目录作为参数,动态的传入。
if __name__ == '__main__':
dirname = os.path.abspath(sys.argv[1])
export_dir(dirname)
然后新键一个bat脚本,在运行时传入配置文件目录:
py -3 main.py ./test/def/
pause
经过整合之后,配置表工作流程就变成这样了:
- 策划配置好 Excel 文件,提交到 Excel 目录 in
- 程序员在配置文件目录 def ,添加配置文件
- 运行导出,生成的对应语言的配置文件就在 out 目录
上面的例子太简单,而且是为了各种数据类型,定义的字段名。最后展示一个实际项目使用的示例:
![]()

四 后记
上面说到的只是最基础的导出功能,还可以在此基础上做各种优化。
- 比如导出的数据中,每一行都是一个字典,每一行中都有大量重复的key,能不能想办法优化掉?
- 对于配置表中的某些列,可能只有前端用到,或者只有后端用到,能不能优化掉?
- 配置文件中的数据,能不能也都全部写到 Excel 表格中?
这些问题,留给大家自己去考虑和取舍吧。
最后,我是寒风,欢迎加入Q群(830756115)讨论。
