第三单元作业总结
JML语言基础以及工具链
一.JML语言
- 定义
JML是一种在java代码中形式化描述指定函数或者变量要求的语言。也就是说,JML相当于一份伪代码,编程者需要在这份伪代码的前提下完成真正的代码编写。 - 使用
JML的好处
使用形式化语言描述代码功能,比使用自然语言描述更加清晰易懂。并且JML语言还配备有一套自动化测试方案,能够测试代码在极端数据(比如最大值、最小值、0、null)的情况下的功能执行是否正确。 - 部分语法
| 语法 | 定义 | 举例 |
|---|---|---|
\result |
表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值 | ensures \result == a - b |
\old(expr) |
表示一个表达式expr在相应方法执行前的取值,该表达式涉及到评估expr中的对象是否发生变化 | ensures expr == \old(expr) |
\not_assigned(x,y,...) |
用来表示括号中的变量是否在方法执行过程中被赋值。如果没有被赋值,返回为true ,否则返回 false 。用于后置条件的约束,限制一个方法的实现不能对列表中的变量进行赋值。 | \not_assigned people, group |
\nonnullelements(container) |
表示container对象中存储的对象不会有null | \nonnullelements(people) |
\forall |
全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束 | (\forall int i,j; 0 <= i && i < j && j < 10; a[i] < a[j]) |
\exits |
存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束 | (\exists int i; 0 <= i && i < 10; a[i] < 0) |
\sum |
返回给定范围内表达式的和 | (\sum int i; 0 <= i && i < 5; i) |
\max |
返回给定范围内表达式的最大值 | (\max int i; 0 <= i && i < 5; i) |
\min |
返回给定范围内的表达式的最小值 | (\min int i; 0 <= i && i < 5; i) |
b_expr1<==>b_expr2,b_expr1<=!=>b_expr2 |
等价关系符 | ... |
b_expr1==>b_expr2 |
推理操作符 | ... |
requires |
前置条件 | requires a != 0 |
ensures |
后置条件 | ensures \result == a |
public normal_behavior |
正常功能 | ... |
public exceptional_behavior |
异常行为 | ... |
signals |
定义抛出异常 | signals (Exception e) a == 0 |
invariant |
不变式(invariant)是要求在所有可见状态下都必须满足的特性 | invariant (\forall int i; 0 <= i && i < integer.length - 1; integet[i] <= integer[i + 1]) |
二.工具链
使用较广的JML工具链是OpenJML以及jmlunitng。由于年代久远,这些工具链在使用起来会有一些意想不到的bug。
JML完整工具链地址:http://www.eecs.ucf.edu/~leavens/JML//download.shtml。其中有OpenJml包下载链接。
下载jmlunitng.jar地址:http://insttech.secretninjaformalmethods.org/software/jmlunitng/。
部署SMT Solver
一.配置
下载完成OpenJml即可在Idea中部署。这里推荐一篇较为清晰的博客:https://www.cnblogs.com/Yzx835/p/10907084.html。
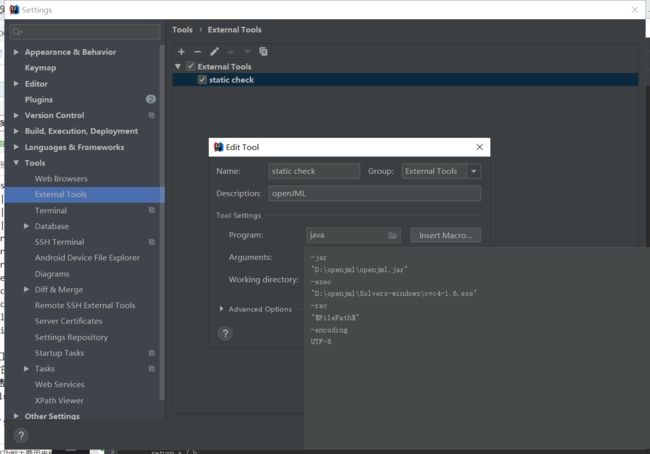
我的配置如下图:

二.验证
-check进行语法检查
openjml -check code.java

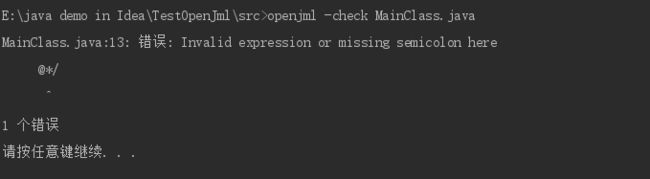
可以看出,缺少了一个分号被检查出来了。
-esc静态检查
java -jar D:\openjml\openjml.jar -esc -prover cvc4 -exec D:\openjml\Solvers-windows\cvc4-1.6.exe MainClass.java
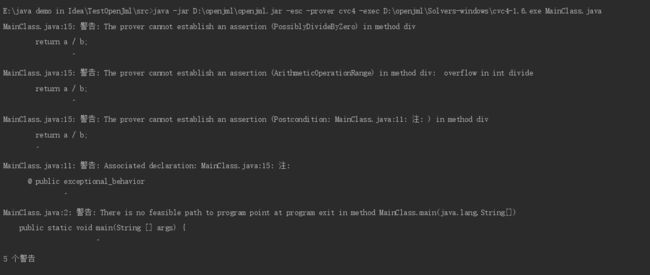
可以看出,主要检查出了三个错误:1.除0;2.除法溢出;3.没有抛出异常。由此可见,静态检查能使程序员提前知道运行代码时可能出现的错误及其实现与规格不符的地方,便于查错。
rac动态检查
这里需要用到两条命令行:
java -jar D:\openjml\openjml.jar -rac MainCLass.java
java -cp D:\openjml\jmlruntime.jar; MainClass
运行情况如下:

可以看出,这条指令真正的运行了代码,并且找出了divide by zero错误。
部署JmlUnitNg并测试
一.部署JmlUnitNg
下载了jmlunitng.jar后,需要把这个包导入Idea中才能正确执行。导入方法如下:

二.运行自动化测试
- 首先需要生成测试代码,这个测试代码是按照
JUnit的格式编写的。这里以第三次作业的MyGroup.java作为测试代码。需要注意的是,如果使用了HashMap,需要完整写出HashMap的Key和Value,否则会报错。
java -jar D:\openjml\jmlunitng-1_4.jar MyGroup.java com\oocourse\spec3\*
运行结果如下:

生成了一堆文件,其中MyGroup_JML_Test.java是可以执行的代码,可以看到,代码是按照JUnit格式编写的。右键运行代码,得到如下结果:

有几个测试点fail了,由此知道在方法addPerson(Person person)中,没有判断null的情况导致出错,修改代码后,再次运行通过测试点。另外,可以看出,这种测试只会测试边界以及极端情况,如果需要测试一般情况,还是需要手动写数据或者测评机生成数据。
作业架构设计与测试
这三次作业都是按照课程组提供的架构设计的,也就是创建了三个类MyPerson,MyGroup,MyNetwork。现在分析,其实可以把有关图的操作单独构建一个类,实现isCircle、queryBlockSum、queryStrongLinked、queryMinPath等操作。这样可以减少MyNetwork类的复杂度,也使得层次更加清晰。
一.作业二
- 在性能方面,主要是
isCircle函数需要耗费大量查询时间。在作业一刚开始设计这个函数时,我选择的是dfs方法,因为那时数据限制较宽。在第二次作业测试的时候,发现当相互认识的人们递归深度太深,会导致爆栈,因此改dfs为bfs,解决了这个问题。另外,在MyGroup类中,每次addperson时,采用缓存机制,保存年龄的平均值、relationSum、valueSum等变量,可以避免之后的查询循环操作。 - 在强测和互测中,作业一和作业二都没有被hack。我自己构建了一个数据生成器,随机产生测试数据。但是这个数据生成器有明显的弊端,那就需要手动测试大量
isCircle之类的CPU timeoutbug。这也是导致我在作业三中出现CPU timeout的原因,现在想起仍然追悔莫及。
二.作业三
- 性能方面,由于增加了
qureyMinPath、queryStronglinked、queryBlockSum三个方法,需要使用合适的算法确保不超时。第三次作业我就是因为queryStronglinked、queryBlockSum方法不当导致了CPU超时。 queryMinPath需要使用堆优化的dijkstra算法。堆优化,就是在普通的dijkstra算法上增加使用了一个优先队列PriorityQueue,这样的话,每次只需要取出优先队列的队首即可,不需要遍历队列找到当前距离最小的点。由于在写代码时没有仔细考虑时间复杂度,导致了CPU超时。去掉了不必要的循环后,降低了CPU时间。queryBlockSum方法,由于我在写代码时,直接按照了JML的格式,导致时间复杂度达到了O(n^2),由此CPU超时。原因我认为有两个,一是我没有完全理解这个函数的意思,二是我的随机数据没有测出这个bug。其实这个函数是得到整个网络中,相互连接的人的圈子的个数,明白了意思之后,只需要从第一个人开始遍历,访问所有他能够isCircle到的人就行了。在修复bug时,我采用了dfs来遍历所有的圈子,并且记录访问过的人,从而降低了时间复杂度。queryStronglinked使用的是tarjan算法。要注意的是,有向图和无向图的tarjan算法有些许的差异,在使用时要小心。这里给出一篇关于有向图和无向图的tarjan算法博客:https://blog.csdn.net/hanhansoul/article/details/7558772- 强测中,我错了一半的点,都是
CPU timeout导致的;在互测中没有被hack。关于强测的翻车,我觉得还是因为我放松了警惕,没有手动构造一些可能超时的数据。随机生成数据的做法能满足普通情况下的测试要求。看来还是不能太依赖随机数据,今后需要注意一些极端数据的测试。
规格撰写和理解
JML编写和写代码还是有很多相似之处的,比如我们熟悉的循环操作\forall、存在操作\exists等。规格化语言消除了自然语言的歧义,提供了一个统一的规范,有利于检测代码的正确性。但是,我们不能直接把简单的JML语言理解为真正的代码实现,因为真正的代码实现需要权衡算法、数据结构等。一定要认识到规定前因后果和实现过程是不同的。另外,基于规格的测试只是简单地测试了边界数据,我们不能完全依赖于这种测试。在规格化测试的基础上,需要我们手动构造极端数据,并且利用测评机加以测试,才能更好地验证代码的正确性。