二叉树的经典技巧及算法 I
1、 判断是否为二叉搜索树,二叉搜索树的基本特征是:左子树的所有节点都小于根节点,右子树的所有节点都大于根节点(假设没有相等的节点),也就是说左子树有上界,右子树有下界,其界为(无限小,无限大),对于根节点的左子树而言,其界为(无限小,根节点),对于根节点的右子树而言,其界为(根节点,无限大),随着层次的递增,下面的子树的上、下界也在更新,而且这个界越来越紧,如果一个二叉树不是二叉搜索树,那么它必然在某一层违反了上、下界,代码如下:
bool isValidBST(TreeNode* root) {
return isValidBST(root,false,0,false,0);
}
/* hasMini=false代表下界为无线小,hasMaxi=false代表上界为无限小 */
bool isValidBST(TreeNode* root, bool hasMini, int mini, bool hasMaxi, int maxi){
if(!root) return true;
//检验当前节点是否违反了上下界
if(hasMini && root->val<=mini) return false;
if(hasMaxi && root->val>=maxi) return false;
//递归检查左子树
bool isLeftValid = isValidBST(root->left,hasMini,mini,true,root->val);
if(!isLeftValid) return false;
//递归检查右子树
bool isRightValid = isValidBST(root->right,true,root->val,hasMaxi,maxi);
if(!isRightValid) return false;
return true;
}2、判断两棵二叉树是否相等,这个就相当直观了,从上往下,同时访问两棵二叉树对应位置的节点,代码如下:
bool isSame(TreeNode* root1,TreeNode* root2){
if(root1==NULL && root2==NULL) return true;
if((root1==NULL && root2!=NULL) || (root1!=NULL && root2==NULL)) return false;
if(root1->val!=root2->val) return false;
return isSame(root1->left,root2->left) && isSame(root1->right,root2->right);
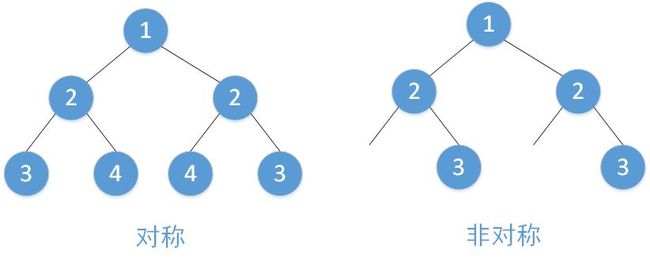
}3、判断一颗二叉树是否对称,对称与非对称的区别如下图所示,这个题不用考虑根节点,直接看它的两个子树是否对称就好,其实可以借鉴“判断两树是否相等”的代码,只要稍稍改造一下即可,代码如下:
bool isSymmetric(TreeNode* root) {
if(!root) return true;
return isSymmetric(root->left,root->right);
}
bool isSymmetric(TreeNode* root1,TreeNode* root2){
if(root1==NULL && root2==NULL) return true;
if((root1==NULL && root2!=NULL) || (root1!=NULL && root2==NULL)) return false;
if(root1->val!=root2->val) return false;
return isSymmetric(root1->left,root2->right) && isSymmetric(root1->right,root2->left); //这里有一些改动
}还有一种方法,即把每一层保存下来,看每一层是否对称,这里用到了队列,其实就是在层次遍历的基础上再稍微加点判断,代码如下:
bool isSymmetric(TreeNode* root) {
if(!root) return true;
deque//判断当前层是否对称
if((*i==NULL && *j!=NULL) || (*i!=NULL && *j==NULL)) return false;
if(*i!=NULL && *j!=NULL && (*i)->val!=(*j)->val) return false;
i++;
j--;
}
int length = d.size();
isEnd = true;
TreeNode* t = NULL;
while(length--){//把当前层的下一层节点依次入队
t = d.front();
d.pop_front();
if(t!=NULL) {
if(t->left || t->right) isEnd = false;
d.push_back(t->left);
d.push_back(t->right);
}
}
}
return true;
} 4 、修复二叉搜索树,即BST中有两个节点被交换了,找出这两个节点并把它们交换回来。基本思路如下,既然两个节点交换了,那么一定破坏了中序遍历下的相邻节点的先后顺序。举例如下:正常的序列为{1,2,3,4,5,6},比如交换了3和5,变成了{1,2,5,4,3},显然,首先碰到的异常对为{5,4},因为交换后是把大的放在了前面,接下来碰到的异常对是{4,3},因为交换后是把小的放在了后面,所以基本做法就是检测中序遍历下的相邻节点, 记录异常节点即可,代码如下:
void recoverTree(TreeNode* root) {
vector1){
if(res[i]->val>res[i+1]->val){
if(!t1) {t1 = res[i]; t2 = res[i+1]; }// t2可能是t1的下一个节点,也可能在更靠后的位置
else {t2 = res[i+1]; }
}
i++;
}
int tmp = t2->val;
t2->val = t1->val;
t1->val = tmp;
}
void inorderTraversal(TreeNode* root, vector 这份代码使用了O(n)的额外内存,那么有没有O(1)的解决方案呢?回想一下,线索遍历的空间复杂度为O(1),唯一需要做的就是要保存当前节点的直接前驱结点,代码如下:
void recoverTree(TreeNode* root) {
TreeNode *pre = NULL; //当前节点的前一个节点
TreeNode *cur = root; //当前节点
TreeNode *t1 = NULL, *t2 = NULL;
while(cur){
if(!cur->left){
if(pre && pre->val>cur->val){
if(!t1){
t1 = pre;
t2 = cur;
}
else t2 = cur;
}
pre = cur;
cur = cur->right;
}
else{
TreeNode* p = cur->left;
while(p->right && p->right!=cur) p = p->right;
if(p->right==NULL){
p->right = cur;
cur = cur->left;
}
else{
p->right = NULL;
if(pre && pre->val>cur->val){
if(!t1){
t1 = pre;
t2 = cur;
}
else t2 = cur;
}
pre = cur;
cur = cur->right;
}
}
}
int tmp = t2->val;
t2->val = t1->val;
t1->val = tmp;
}5、把每一层的节点用一个next指针连起来,该层最后一个节点的next为NULL,要求空间复杂度为O(1),基本思路是:注意到根节点是不用处理的,即第一层已经用next连好了,所以顺着next我们就可以把下一层的连接构建好,代码如下:
/**
* Definition for binary tree with next pointer.
* struct TreeLinkNode {
* int val;
* TreeLinkNode *left, *right, *next;
* TreeLinkNode(int x) : val(x), left(NULL), right(NULL), next(NULL) {}
* };
*/
void connect(TreeLinkNode *root) {
TreeLinkNode* head = root;
while(head){
TreeLinkNode* p = head;
head = NULL; //下一层的头节点
TreeLinkNode* q = head; //下一层的尾节点
while(p){
if(p->left){
if(!head) {head = p->left; q = head; }
else{ q->next = p->left; q = q->next; }
}
if(p->right){
if(!head) {head = p->right; q = head; }
else{ q->next = p->right; q = q->next; }
}
p = p->next;
}
}
}6、找到所有和为某个值的路径(从根出发到叶子结点为一条路径),这个用递归很容易实现了,当走到叶子结点时,如果该路径的和满足条件,就把该路径加入到答案中,代码如下:
void pathSum(TreeNode* root, int sum, vector<int> path, vector<vector<int> > &pathSet){
if(!root) return ;
if(!root->left && !root->right){ //root为叶子节点
if(root->val==sum){
path.push_back(root->val);
pathSet.push_back(path);
}
}
else{
path.push_back(root->val);
pathSum(root->left,sum-root->val,path,pathSet);
pathSum(root->right,sum-root->val,path,pathSet);
}
}7、二叉树的最小深度,基本思路,比较所有的分支,取最小的,有点动态规划的感觉,代码如下:
int minDepth(TreeNode* root) {
if(!root) return 0;
if(!root->left && !root->right) return 1;
int d1 = 1+minDepth(root->left);
if(root->right==NULL) return d1;
int d2 = 1+minDepth(root->right);
if(root->left==NULL) return d2;
if(root->left!=NULL && root->right!=NULL) return d1 < d2? d1:d2;
}8、根据二叉树的前序遍历序列和后序遍历序列构建二叉树,基本思路: 前序遍历序列的第一个节点是根节点,那么在中序遍历中,该节点前面的都是左子树的节点,该节点后面的都是右子树的节点,接下来就可以把原问题转换为它的子问题:如果用两个序列去构建它的左子树(右子树),代码如下:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if(preorder.size()==0) return NULL;
return buildTree(preorder,0,preorder.size()-1,inorder,0,inorder.size()-1);
}
TreeNode* buildTree(vector<int>& preorder,int i,int j, vector<int>& inorder, int x, int y){
if(i>j) return NULL;
int mid = x;
while(inorder[mid]!=preorder[i]) mid++;
TreeNode *root = new TreeNode(preorder[i]);
root->left = buildTree(preorder,i+1,i+mid-x,inorder,x,mid-1);
root->right = buildTree(preorder,i+mid-x+1,j,inorder,mid+1,y);
return root;
}上述代码中,总是需要从中序遍历序列中寻找根节点,由于中序遍历序列是有序的(二叉搜索树),所以可以用折半查找,不过最快的还是Hash表了,下面是稍作改进后的代码:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if(preorder.size()==0) return NULL;
map<int, int> hashMap;
for(size_t i = 0; i < inorder.size(); i++)
hashMap[inorder[i]] = i;
return buildTree(preorder,0,preorder.size()-1,inorder,0,inorder.size()-1,hashMap);
}
TreeNode* buildTree(vector<int>& preorder,int i,int j, vector<int>& inorder, int x, int y,map<int,int>& hasMap){
if(i>j) return NULL;
/*
int mid = x;
while(inorder[mid]!=preorder[i]) mid++;
*/
int mid = hashMap[preorder[i]];
TreeNode *root = new TreeNode(preorder[i]);
root->left = buildTree(preorder,i+1,i+mid-x,inorder,x,mid-1);
root->right = buildTree(preorder,i+mid-x+1,j,inorder,mid+1,y);
return root;
}9、 根据二叉树的后序序遍历序列和后序遍历序列构建二叉树,这个思路跟上面的很类似,在后序遍历序列中,最后一个节点是根节点,其余的都跟上面的相同了,代码如下:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if(inorder.size()==0) return NULL;
map<int, int> hashMap;
for(size_t i = 0; i < inorder.size(); i++)
hashMap[inorder[i]] = i;
return buildTree(postorder,0,postorder.size()-1,inorder,0,inorder.size()-1,hashMap);
}
TreeNode* buildTree(vector<int>& postorder,int i,int j, vector<int>& inorder, int x, int y,map<int,int>& hashMap){
if(i>j) return NULL;
/*
int mid = x;
while(inorder[mid]!=preorder[i]) mid++;
*/
int mid = hashMap[postorder[j]];
TreeNode *root = new TreeNode(postorder[j]);
root->left = buildTree(postorder,i,j+mid-y-1,inorder,x,mid-1);
root->right = buildTree(postorder,j+mid-y,j-1,inorder,mid+1,y);
return root;
}10、寻找两个节点的最低公共祖先,如果是二叉搜索树,就简单了,如果当前节点均小于(大于)这两个节点,那么他们的最低公共祖先一定在当前节点的右子树(左子树)中,然后递归找,直到遇到某个节点,使得这两个节点不在同一侧,那么那个节点就是他们的最低公共祖先。但如果不是二叉搜索树呢?我们可以遍历树,找到这两个节点,并记录从根节点到它们的路径,然后在这两条路径上找它们的第一个非公共节点,代码如下:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(!p || !q) return NULL;
vectorreturn path1[i-1];
}
bool findPath(TreeNode *root, TreeNode *p, vector