V8引擎工作机制
V8引擎工作机制
0.前言
在翻译文章从嵌入V8开始中,从一个较为黑盒的角度介绍了如何将V8引擎嵌入到自己的C++项目中,并简单的介绍了一些相关API和概念。
本文将会从一个概念层次上介绍V8引擎的工作机制。涉及的源码不多,仅对一些接口进行介绍,后续会在其他文章中进行详细的源码分析。
1. 工作机制演化
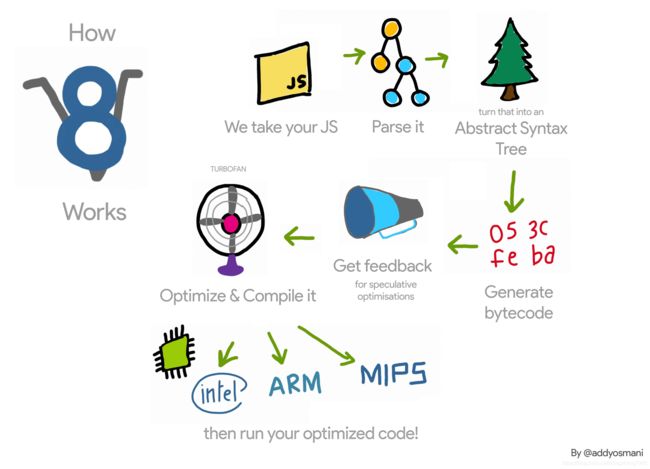
V8引擎主要能力是将JavaScript源码解释编译,并运行。现阶段的工作机制可以分为以下几个阶段:
- Parser:解析器,将JS源码解析为AST(抽象语法树,Abstract Syntax Tree);
- Ignition:基于寄存器的解释器,用于将AST转换为字节码;
- TurboFan:基于Ignition生成的字节码,生成对应平台的机器码,并对其进行优化和反优化。
总体而言可以用下图来形象地表示:
其实,该工作流程其实是经过较大的重构的。在5.9版本之前,V8引擎是没有生成字节码这一过程的,而是直接将AST通过Full-codegen快速生成为未优化的机器码,之后再通过Crankshaft对热点函数进行优化编译。
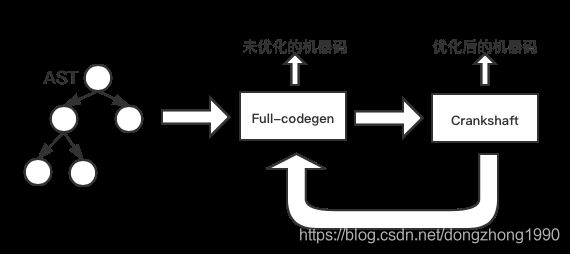
这种方式跳过了字节码,极大减少了转换时间。
然而这种优化方式还是过于激进了,谷歌又对其进行了大幅度重构,最终产生了现在的引擎工作机制。这次重构的起因是Chrome的一次bug上报:crbug.com/593477,对Facebook第一次加载时,v8.CompileScript花费了165ms,再次加载加入v8.ParseLazy,花费时间增长到376ms。然而期望的情况时缓存功能应该对JS脚本的解析结果进行了缓存,花费时间不应该这么长。
后面经过分析发现,因为机器码占用空间过大,无法一次性将所有JS代码编译成机器码缓存下来,所以只编译最外层的JS代码,内部代码则留到第一次被调用时再编译。然而Facebook的开发者将各个独立module编译成单独的文件,其中用到很多闭包,如:
__d('getActiveElement', [], function (module) {
var MY_CONST = 1;
module.exports = function getActiveElement(){
...
};
});
这就导致了,缓存机制只能作用于最外层的__d()上面了,内部真正需要缓存的逻辑代码却被忽略掉了。
通过这个bug可以看出直接转换机器码的问题,那就是机器码占用空间过大,无法一次性编译全部代码,而只运行一次的代码又浪费了内存资源。在没有引入字节码时,大约有30%的堆空间用于存储未优化的机器码。
于是乎,V8团队又将主流的字节码引入了引擎,期望通过牺牲执行时间换空间。字节码比机器码紧凑很多,减少占用内存空间;因为内存占用过大问题的消除,可以提前编译所有的代码,这样又提高了代码的启动速度。同时这次重构也带来了一些潜在的优点:1. 简化了V8的代码复杂度。在之前的机制中,每次新增一个JS语言特性,都需要对不同的编译管线进行更新,而在新的Ignition+TurboFan管线中,则减少了巨大的工作量;2. 优化和反优化更便捷,因为字节码是固定不变的,所以TurboFan可以直接从字节码来进行优化,同时反优化时,可以不再考虑JS源码和AST。
2. 解析器Parser
解析器Parser的主要作用是将JS源码转换为抽象语法树AST。其代码主要在./src/parsing/目录中。核心类是Parser:
// ./src/parsing/parser.h
class V8_EXPORT_PRIVATE Parser : public NON_EXPORTED_BASE(ParserBase<Parser>) {
...
};
这个类主要管理调度解析流程,内部拥有Scanner、ParseInfo等,最终会产生出一个AST。
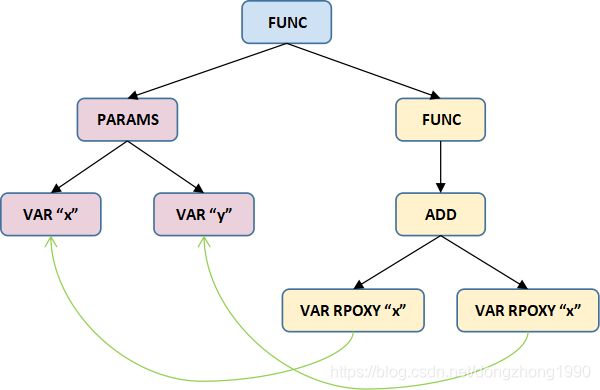
举个简单例子:
function add(x, y) {
return x + y;
}
可转换为下图示意:
详细的代码会在后续文章中分析。
3. Ignition
Ignition的总体设计可以参考V8引擎官方的设计文档《Ignition design document》。
Ignition的设计目标是为V8建立一个解释器来执行低层级的字节码,可以让只运行一次或非热点的代码以字节码形式存储,这样可以使其空间更紧凑。
Ignition通过继承于AstVisitor的BytecodeGenerator类对函数的AST进行遍历。BytecodeGenerator以函数为单位,为每个节点生成相应的字节码,并作为SharedFunctionInfo对象中的一个属性与函数关联。函数的代码入口设置到Builtins的InterpreterEntryTrampoline的stub中。函数运行时,这个stub先初始化合适的栈帧,然后为第一个字节码调度到字节码处理程序,从而在解释器中执行该函数。其中字节码处理程序是由TurboFan生成的,与字节码一一对应。
Ignition是基于寄存器的解释器,这些寄存器是函数栈帧中分配的寄存器文件中特定的slot,即一小块内存。根据字节码的参数指定操作的寄存器。
仍以上面的add函数为例。Ignition会遍历这个AST,产生如下的字节码:
StackCheck
Ldar a1
Add a0, [0]
Return
这里的Ldar、Star等都有相应的字节码处理程序,这些字节码处理程序会由TurboFan生成。例如Ldar表示从寄存器中读取数据加载到累加器中(LoaD Accumulator from Register),其对应的字节码处理程序如下:
// ./src/interpreter/interpreter-generator.cc
// Load accumulator with value from register .
IGNITION_HANDLER(Ldar, InterpreterAssembler) {
TNode<Object> value = LoadRegisterAtOperandIndex(0);
SetAccumulator(value);
Dispatch();
}
这个字节码处理程序并不直接调用,而是通过每个字节码处理程序调度到下一个字节码,即上面的Dispatch方法。
在生成字节码过程中,BytecodeGenerator还会为各种变量、Context对象指针等分配寄存器,具体的分配方式将会在专门的文章中通过代码仔细分析。
因为JavaScript时动态语言,一般只有在运行时才知道变量的确切类型。所以Ignition在运行函数时,还会收集一些信息(例如变量类型等),将其保存在反馈向量中,并将其传递给TurboFan,用于加速对字节码的解释运行。比如对o.x这样的属性访问,V8会缓存其获取过程的信息,并在后续执行相同字节码时,不需要再次搜索对象o中x的位置。这里讲到的获取过程和缓存机制,就是V8高性能的杀手锏——隐藏类(Hidden Class)和内联缓存(Inline Cache)。这些都会在后续文章中单独分析讲解。
4. TurboFan
参考文章《Introduction to TurboFan》
V8的管线是由解释器和编译器组成的,其中的解释器就是上节介绍的Ignition,而编译器就是本节所要介绍的TurboFan。TurboFan是V8的优化编译器,借力于一个叫做“节点海(Sea of Nodes)”的概念。TurboFan的主要作用是将Ignition的字节码编译为机器码,并根据Ignition运行时提供的反馈向量进行优化或反优化。其优化管线如下图所示:
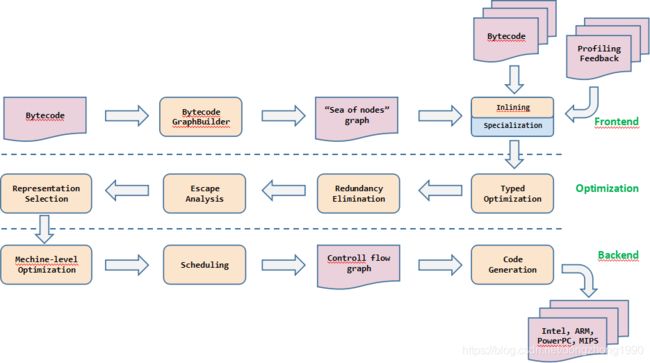
TurboFan主要利用了基于类型预测的优化技术和基于节点海(“Sea of Nodes”)的机器码生成技术。这些都会在后续单独的文章中分析。
5. 垃圾回收
V8的高效垃圾回收机制也是其高性能的助力之一。
V8中所有的对象都是通过堆来分配的,当代码声明变量并且赋值时,该对象的内存就分配到堆中。如果堆内存不够,就继续申请内存,知道大小达到V8限制为止。此时就会触发V8的垃圾回收动作。
V8采取了一种分代回收的策略,即将堆内存划分为不同的生代,根据各个生代的特点执行不同的垃圾回收算法。V8里主要会处理新生代和老生代两个分区。
- 新生代特点是区域小、回收频繁。主要采用Scavenge算法,利用空间换时间。
- 老生代特点是对象生命周期长,占用内存较多。主要采用Mark-Sweep和Mark-Compact相结合的策略,节省空间。
详细的算法分析会在单独的文章中进行分析。
总结
本文主要从一些概念层次对V8引擎进行了介绍。V8的高性能是由其采用了很多优化方法相结合决定的。这些都非常值得我们去深入研究。
我也会在后续文章中不断的进行学习、分析。