一.导论
目前深度学习已经在2D计算机视觉领域取得了非凡的成果,比如使用一张图像进行目标检测,语义分割,对视频当中的物体进行目标跟踪等任务都有非常不错的效果。传统的3D计算机视觉则是基于纯立体几何来实现的,而目前我们使用深度学习在3D计算机视觉当中也可以得到一些不错的效果,目前甚至有超越传统依靠立体几何识别准确率的趋势。因此咱们现在来介绍一下深度学习在3D计算机视觉当中的应用吧!本博文参考了前几天斯坦福大学最新出的CS231n课程(2020/8/11新出),新课增加了3D计算机视觉和视频/动作分类的lecture,同时丰富了生成对抗网络(GAN)的内容,但暂时国内还无人翻译,因此小编将其翻译整理成博文的形式供大家参考,如有错误之处,请大家见谅,同时欢迎大家讨论。
二.3D计算机视觉训练集以及表示方法
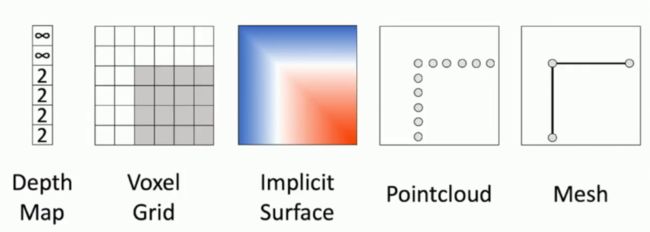
在3D计算机视觉当中,我们可以采用于训练的模型共有以上几种,分别是:
1.Depth Map(深度图)
2.Voxel Grid(翻译过来很奇怪,因此就保留原英语)
3.Implicit Surface(隐表面)
4.PointCloud(三维点云)
5.Mesh
那么什么是Depth Map(深度图)呢?咱们来看看
三.Depth Map(深度图)
深度图的图像如下所示:

在左上角有一张关于斯坦福大学寝室的图片,我们可以将其转化为右上角的深度图,其中深度图当中不同的颜色表示了不同物体距离摄像头的距离,距离摄像头的距离越大,则显示出来的颜色则越红。我们假设有一个神经网络,我们只需要输入一张图片,就可以得到图片当中的所有位置距离摄像头的距离,这样是不是很酷呢?那么我们如何使用神经网络对一系列的图片训练成为深度图的形式呢?一些研究人员便立马想到可以使用全卷积神经网络(Fully convolutional Network)来实现这个过程,全卷积神经网络(Fully convolutional Network)是我们之前在2D计算机视觉当中所采用的用于图像分割的神经网络,之前图像分割得到的是每一个像素点显示的是属于某一个物体类别的概率值,而现在我们把同样的神经网络用于深度图当中就可以得到图像当中某一个像素距离摄像头的远近大小。这样就可以完美得到咱们的深度图训练模型了,我们甚至可以把这个全卷积神经网络替换成U-net以期在一些特定数据集上得到更好的效果。模型如下所示: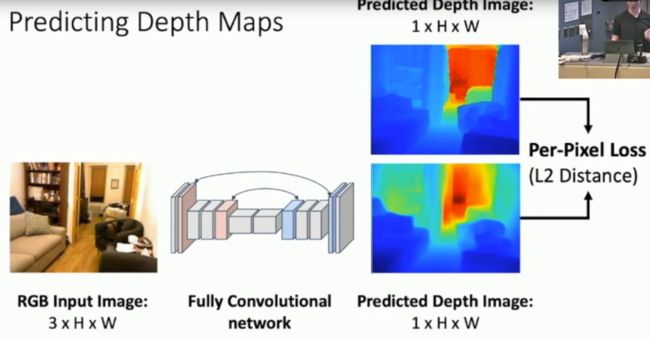
这个模型首先也是输出一个3通道的彩色图片,经过一个全卷积神经网络(FCN)然后对深度图进行估计,输出的深度图仅仅具有两个通道,因为第三个通道的维度为1,意味着我们输出的深度图实际上是黑白的,用黑色或者白色的深度来表示距离摄像头的距离,图像当中使用了彩色仅仅是因为看起来更加方便。同时这里的loss使用了L2距离进行损失函数的编写。
但是!!!!细心的同学肯定会发现其中有一定的问题,那就是同一个物体,拥有不同的大小,他们如果仅仅通过一张图片来判定他们离摄像头的距离是不一定准确的。因为图片当中并没有包含物体有关深度的信息。
比如我们有两只形状完全相同的鸟,但是其中一只鸟是另一只鸟大小的2倍,我们把小鸟放到离摄像头更近的位置,将大鸟放到离摄像头更远的位置,那么仅仅通过一张图片我们就会认为这两只鸟离我们的摄像头距离是一样大的!如下图所示: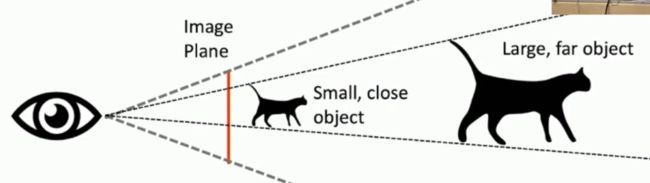
那么这样我们又该如何解决呢?聪明的研究人员设计了一个具有尺寸不变特征的的loss function来解决了这个问题,这个loss function的写法如下:
至于这个公式为什么会让图片的深度信息得以保留,这里不再赘述,感兴趣的同学可以翻看一下提出这个loss的论文,在2016年的世界顶级人工智能会议论文NIPS上发表,于纽约大学(New York University)提出,论文的链接如下:https://papers.nips.cc/paper/5539-depth-map-prediction-from-a-single-image-using-a-multi-scale-deep-network.pdf
同时呢,在深度图当中还有一种图叫做垂直表面法向量图,它的图像如下所示:

最后输出图像当中的不同颜色代表了这个物体的表面所朝空间当中的方向,比如绿色代表这个物体的表面是朝向右边的,而红色则代表这个物体的表面是朝向左边的。我们也可以使用全卷积神经网络(Fully convolutional Network)对这种输出的图像进行处理,其中的结构如下所示:
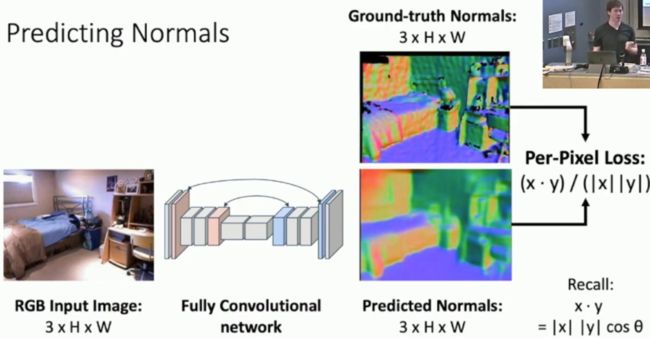
最后的Loss采用了(x*y)/(|x|*|y||)的方法,因为我们所预测的图像具备图像的方向和深度的信息,而图像的方向和大小正好可以由向量表示,岂不美哉?每一个训练集当中的图片的其中一个像素点都可以由一个向量来表示,同时具备深度(长度)和方向的信息。而原图当中某个像素点的大小可以表示为向量x,通过神经网络推测之后的同一个像素点则可以表示为向量y,因此我们可以使用公式(x*y)/(|x|*|y||)来衡量这两个向量之间的差距,其中(x*y)中的乘法使用了点乘,因此上下相除可得cos(theta)也就是图片当中某个像素点所具备的loss的大小,将整个图片当中所有像素点的大小加起来则可以得到整个图像当中loss的大小了。
四.Voxel Grid网格表示法
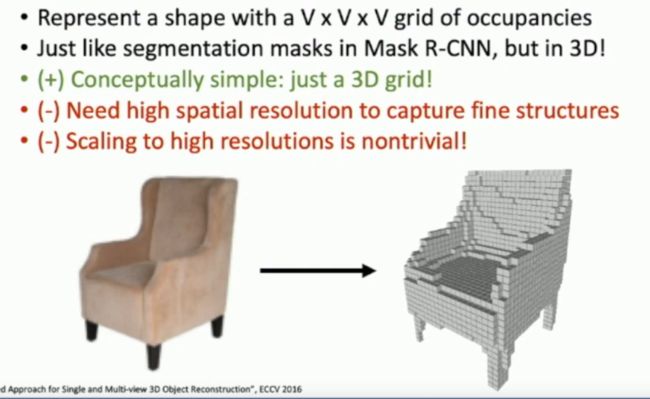
如上图所示,我们可以将一张二维的图片转为一张三维的Mesh图,什么是Mesh图呢?Mesh图就是在一个三维的,大小为V*V*V的空间立体当中,由一系列1*1*1正方体网格堆砌出来的三维立体图形,Mesh图当中的每一个网格只具有两个值,1或者0,1表示这个地方有正方体,0表示这个地方没有正方体。一个Mesh图当中只保留物体的形状和大小信息,而不保留物体的颜色以及纹理的信息。
我们先来看一个有趣的问题,用什么方法可以对三维Mesh图进行分类呢?我们暂时不考虑将二维图像恢复到三维Mesh图的情况的话,常见的手段是使用立体3D卷积,如下图所示:
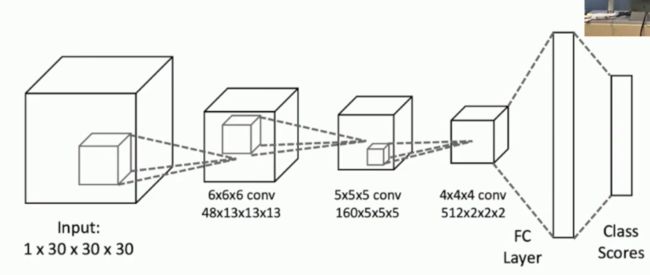
3D立体卷积和我们的2D卷积有一点不同之处,那就是卷积核的神奇之处是它竟然一个立体立方体!而不是一个二维的平面!在上图当中,我们的输入是一个四通道的1*30*30*30的Mesh图,输入的图像可能是一个椅子,也可能是一个床。我们通过三维卷积,不断地进行卷积以及池化的操作,接着使用全连接神经网络将其展开,最后使用softmax函数将其继续拧分类。我们使用3D卷积能够对立体图像的特征进行更为有效的检测,因为一个立体的图像不仅仅有长和宽上面的信息,还有其有关深度的相关信息,因此需要采用3D卷积。3D卷积的动态图如下所示,这个例题动态图当中卷积核的大小为3*3*3:
再回到我们刚才的问题,如何将一个二维的图像转化为Mesh图呢,我们可以采用的卷积神经网络如下所示: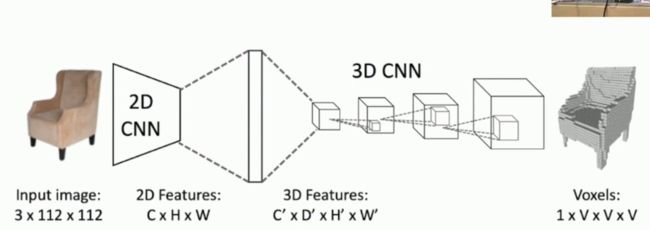
首先我们将二维的图像首先送入到一个2D卷积神经网络当中,用于提取这个二维图像的特征,然后通过全连接神经网络或者Flatten层将其展平一个一维的向量,这样就可以更加方便地转化reshape为四通道进行三维卷积的形式,前面我们已经说过三维卷积能够更好地抽象地还原和提取到图像在三维空间上的个特征,因此我们对刚才二维图像抽象出来的特征通过三维卷积进行还原,这是一个通过三维卷积进行上采样的过程。最后输出的结果就可以得到我们的Voxels grid图啦!
但是使用三维卷积常常就会用更为昂贵的代价来换取更为准确的结果,因为三维卷积使用的参数过多,如下图所示:
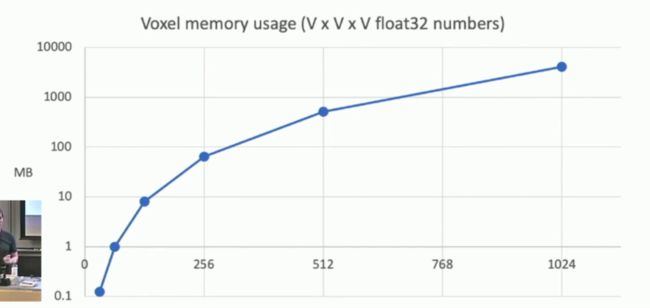
我们仅仅储存1024^3个Voxels grid网格就需要电脑4GB的显存,实在是太大了!好多电脑的显存还没有这么大呢!因此有些研究人员则直接使用二维卷积对图像进行三维的还原,当然效果肯定没这么好啦,如下图所示:
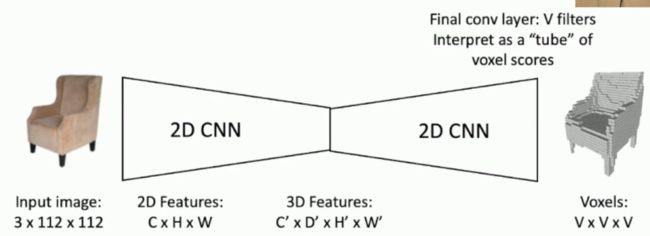
这个思想就很和我们的自编码器(Auto-Encoders)很像了。
五.采用隐函数
我们还可以采用物体在三维空间当中的函数图像来表示一个立体物体,我们再用神经网络来重新拟合出这个函数就好啦,个人觉得在这种方法不太合理,如下所示:

六.采用3D点云
采用3D点云应该是目前比较靠谱的方案,

在3D点云当中每一个点,都有三个参数,分别是每个点在x,y,z轴上的位置,对3D点云进行分类的话和对Mesh分类的方法差不多,也是经过一定的神经网络再经过softmax函数就可以得到最后的分类了!如下图所示: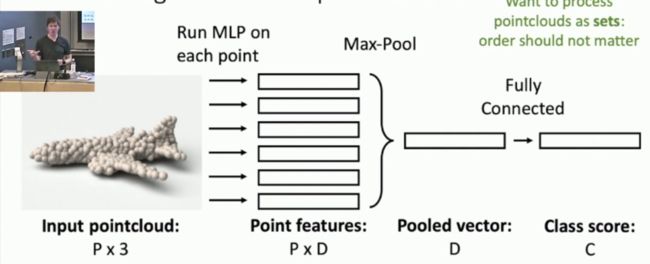
这就是小编今天分享的全部内容了,终于写完啦,如果觉得读了小编的文章您有收获的话,不要忘记了点击下方的“推荐”哦!您的支持就是对小编创作最大的动力!