Python-kafka操作
文章目录
- 0. kafka的特点
- 1.配置windows环境
- 2. producer 向broker发送消息
- 格式化发送的信息
- 3. consumer 消费数据
- 4. group_id 解释
- 5. 遇到的bug
0. kafka的特点
消息系统的特点:生存者消费者模型,先入先出(FIFO)
• 高性能:单节点支持上千个客户端,高吞吐量
- 零拷贝技术
- 分布式存储
- 顺序读顺序写
- 批量读批量写
• 持久性:消息直接持久化在普通磁盘上,且性能好
• 分布式:数据副本冗余、流量负载均衡、可扩展
• 灵活:消息长时间持久化+Client维护消费状态
1.配置windows环境
window环境:
- 需在C:\Windows\System32\drivers\etc\hosts 中添加 ip+节点名(如 192.168.23.200 test-kafka)
- 先后开启消费者、生产者程序
代码如下:
2. producer 向broker发送消息
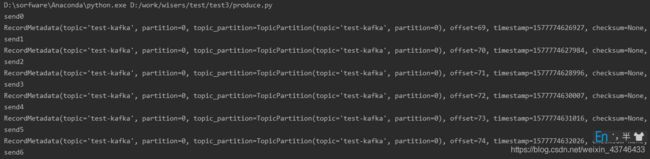
bootstrap_servers是kafka集群地址信息,下面事项主题 test-kafka 发送一条消息,send发送消息是异步的,会马上返回,因此我们要通过阻塞的方式等待消息发送成功(或者flush()也可以,flush会阻塞知道所有log都发送成功),否则消息可能会发送失败,但也不会有提示
关于上面这个可以通过删除send之后的语句试试,会发现broker不会收到消息,然后在send后加上time.sleep(5)之后,会看到broker收到消息。
# -*- coding: utf-8 -*-
import time
from kafka import KafkaProducer
from kafka.errors import KafkaError
topic = 'test-kafka'
producer = KafkaProducer(bootstrap_servers=["ip:端口"])
for i in range(10):
future = producer.send(topic, bytes(i), partition=0)
print("send" + str(i))
try:
record_metadata = future.get(timeout=10)
# 阻塞等待发送成功之后,会看到返回插入记录的信息:
# 里面包括了插入log的主题、分区等信息
print(record_metadata)
except KafkaError as e:
print(e)
time.sleep(1)
producer.close()
格式化发送的信息
import json
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=["test-kafka:30005"]
)
msg_dict = {
"interval": 10,
"producer": {
"name": "producer 1",
"host": "10.10.10.1",
"user": "root",
"password": "root"
},
"cpu": "33.5%",
"mem": "77%",
"msg": "Hello kafka"
}
msg = json.dumps(msg_dict)
producer.send('test-kafka', bytes(msg, encoding='utf-8'), partition=0)
producer.close()
print("success")
创建producer的时候可以通过value_serializer指定格式化函数,比如我们数据是个dict,可以指定格式化函数,将dict转化为byte:
优点:将格式化之后的信息发送给broker,不用每次发送的时候都自己格式化。
import json
producer = KafkaProducer(
bootstrap_servers=[
bootstrap_servers=["test-kafka:30005"]
],
value_serializer=lambda m: json.dumps(m).encode('ascii')
)
msg_dict = {
"interval": 10,
"producer": {
"name": "producer 1",
"host": "10.10.10.1",
"user": "root",
"password": "root"
},
"cpu": "33.5%",
"mem": "77%",
"msg": "Hello kafka"
}
future = producer.send("user-event",msg_dict)
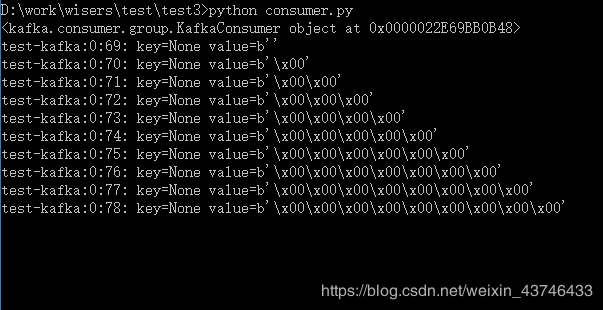
3. consumer 消费数据
from kafka import KafkaConsumer
consumer = KafkaConsumer("test-kafka",bootstrap_servers=["test-kafka:30005"])
print(consumer)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print(recv)
4. group_id 解释
topic到group质检是发布订阅的通信方式,即一条topic会被所有的group消费,属于一对多模式;group到consumer是点对点通信方式,属于一对一模式。
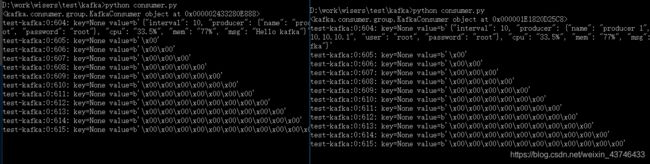
不使用group的话,启动10个consumer消费一个topic,这10个consumer都能得到topic的所有数据,相当于这个topic中的任一条消息被消费10次。
使用group的话,连接时带上groupid,topic的消息会分发到10个consumer上,每条消息只被消费1次
不加group_id 时开启两次相同的消费逻辑
from kafka import KafkaConsumer
consumer = KafkaConsumer("test-kafka",
bootstrap_servers=["test-kafka:30005"],
)
print(consumer)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print(recv)
添加group_id时:
from kafka import KafkaConsumer
consumer = KafkaConsumer("test-kafka",
bootstrap_servers=["test-kafka:30005"],
group_id='123456'
)
print(consumer)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (msg.topic, msg.partition, msg.offset, msg.key, msg.value)
print(recv)

当开启左方第二个消费者时,数据只能被消费一次。
5. 遇到的bug
kafka连接报错 kafka.errors.NoBrokersAvailable: NoBrokersAvailable
问题:
本地windows系统远程连接kafka报错,kafka.errors.NoBrokersAvailable: NoBrokersAvailable。
解决:
hosts文件需要修改,找到windows系统中的hosts文件,位置在C:\Windows\System32\drivers\etc\hosts,在里面加上如下格式内容:
IP地址1 节点名1 如 192.168.23.200 test-kafka
IP地址2 节点名2
参考:https://www.cnblogs.com/iforever/p/9130983.html