Java 正则表达式使用详解
今天研究开源项目,哆啦A梦,研究里面显示log 的原理。 后来发现,用到了正则表达式。觉得很有用,就捡起来,重新研究一下。
学习思路指导:
每一门学问,最好的深入学习方法,是去其官网,研究其说明文档。而不是看别人的博客。
因为很多东西,都是从官网那里看来的。我这篇博客,你也不必多看。按照我推荐的网址,你好好学,肯定比我讲得好。
官网地址:https://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html
正则表达式语法:
Characters
x The character x
\\ The backslash character
\0n The character with octal value 0n (0 <= n <= 7)
\0nn The character with octal value 0nn (0 <= n <= 7)
\0mnn The character with octal value 0mnn (0 <= m <= 3, 0 <= n <= 7)
\xhh The character with hexadecimal value 0xhh
\uhhhh The character with hexadecimal value 0xhhhh
\x{h...h} The character with hexadecimal value 0xh...h (Character.MIN_CODE_POINT <= 0xh...h <= Character.MAX_CODE_POINT)
\t The tab character ('\u0009')
\n The newline (line feed) character ('\u000A')
\r The carriage-return character ('\u000D')
\f The form-feed character ('\u000C')
\a The alert (bell) character ('\u0007')
\e The escape character ('\u001B')
\cx The control character corresponding to x
\ 表示反斜杠,下面的\a 在正则里面表示为:\\a, 因为反斜杠在正则里面是\\。
\n 表示新的一行,正则里面为\\n
Character classes
[abc] a, b, or c (simple class)
[^abc] Any character except a, b, or c (negation)
[a-zA-Z] a through z or A through Z, inclusive (range)
[a-d[m-p]] a through d, or m through p: [a-dm-p] (union)
[a-z&&[def]] d, e, or f (intersection)
[a-z&&[^bc]] a through z, except for b and c: [ad-z] (subtraction)
[a-z&&[^m-p]] a through z, and not m through p: [a-lq-z](subtraction)
用来表示一组字符的集合,比如[abc] 就会匹配a,b,c 。
Predefined character classes
. Any character (may or may not match line terminators)
\d A digit: [0-9]
\D A non-digit: [^0-9]
\s A whitespace character: [ \t\n\x0B\f\r]
\S A non-whitespace character: [^\s]
\w A word character: [a-zA-Z_0-9]
\W A non-word character: [^\w]
预定义的一些字符集,比如. 表示除了换行符以外的任何字符。
\d 表示 一个数字,因为正则里面\ 用\ 表示,所以写在正则里面就是\d.
POSIX character classes (US-ASCII only)
\p{Lower} A lower-case alphabetic character: [a-z]
\p{Upper} An upper-case alphabetic character:[A-Z]
\p{ASCII} All ASCII:[\x00-\x7F]
\p{Alpha} An alphabetic character:[\p{Lower}\p{Upper}]
\p{Digit} A decimal digit: [0-9]
\p{Alnum} An alphanumeric character:[\p{Alpha}\p{Digit}]
\p{Punct} Punctuation: One of !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Graph} A visible character: [\p{Alnum}\p{Punct}]
\p{Print} A printable character: [\p{Graph}\x20]
\p{Blank} A space or a tab: [ \t]
\p{Cntrl} A control character: [\x00-\x1F\x7F]
\p{XDigit} A hexadecimal digit: [0-9a-fA-F]
\p{Space} A whitespace character: [ \t\n\x0B\f\r]
\p{Lower} 表示小写字母,a-z 里面的任何一个数字。
Boundary matchers
^ The beginning of a line
$ The end of a line
\b A word boundary
\B A non-word boundary
\A The beginning of the input
\G The end of the previous match
\Z The end of the input but for the final terminator, if any
\z The end of the input
边界点,比如^ 表示一行的开始,\A 表示整个字符串的开始。
Greedy quantifiers
X? X, once or not at all
X* X, zero or more times
X+ X, one or more times
X{n} X, exactly n times
X{n,} X, at least n times
X{n,m} X, at least n but not more than m times
X? 表示X 这个表达式出现一次,或者一次也不出现。
Reluctant quantifiers:
X?? X, once or not at all
X*? X, zero or more times
X+? X, one or more times
X{n}? X, exactly n times
X{n,}? X, at least n times
X{n,m}? X, at least n but not more than m times
X?? 表示X 这个表达式出现一次,或者一次也不出现。
Logical operators
XY X followed by Y
X|Y Either X or Y
(X) X, as a capturing group
逻辑操作符,X|Y 表示 X 或者 Y 都可以匹配到。
Special constructs (named-capturing and non-capturing)
(?X) X, as a named-capturing group
(?:X) X, as a non-capturing group
(?idmsuxU-idmsuxU) Nothing, but turns match flags i d m s u x U on - off
(?idmsux-idmsux:X) X, as a non-capturing group with the given flags i d m s u x on - off
(?=X) X, via zero-width positive lookahead
(?!X) X, via zero-width negative lookahead
(?<=X) X, via zero-width positive lookbehind
(?X) X, as an independent, non-capturing group
(?X) X, as a named-capturing group 作为一个组,name 是你的组的名字。
正则表达式一些点:
1.^ 和 [^] 是完全不一样的意思,^表示开始,[^] 表示不包含字符
2.\\w 表示一个字符串,后面有* 有+ 才表示多个
3.\\* 和 \\\\* 表达的不一样 \\* 表示的并非正则。 因为如果是正则,那么* 表示0个或多个前面的字符,但是*前面不是任何的字符
所以,不认为是一个正则,而是简单的* 号匹配 \\\\* 表示 0个 或多个\
4.\\* 表示* ,\\表示转义,正则表达式的特殊字符需要转义
5.ide 都有标识,是字符串,还是正则
6.正则表达式\ 用\\表示,所以文档里面说的\w 就是\\w. 所以在String 里面,\\ 表示反斜杠,正则里面的话,就是\\\\
正则表示式测试题:
// final String filterPattern = "ResourceType|memtrack|android.os.Debug|BufferItemConsumer|DPM.*|MDM.*|ChimeraUtils|BatteryExternalStats.*|chatty.*|DisplayPowerController|WidgetHelper|WearableService|DigitalWidget.*|^ANDR-PERF-.*";
//
// Pattern pattern = Pattern.compile( // log level
// "(\\w)" +
// "/" +
// // tag
// "([^(]+)" +
// "\\(\\s*" +
// // pid
// "(\\d+)" +
// // optional weird number that only occurs on ZTE blade
// "\\*\\s*\\d+" +
// "\\): ");
////
////
// String text = "05-29 22:09:49.248 D/yuan (27862): onVisibilityChanged----com.zhangyue.iReader.bookshelf.ui.ViewGridBookShelf{3f8ec1a VFED..CL. ......ID 0,0-1080,2571}";
// Matcher matcher = pattern.matcher(text);
// if (matcher.find()) {
// char logLevelChar = matcher.group(1).charAt(0);
//
// String logText = text.substring(matcher.end());
// if (logText.matches("^maxLineHeight.*|Failed to read.*")) {
//
// } else {
//
// }
//
// String tagText = matcher.group(2);
// if (tagText.matches(filterPattern)) {
//
// }
//
// int processId = Integer.parseInt(matcher.group(3));
// }
/**
* java 中 在 Java 中,\\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
* 表示一位数字的正则表达式是 \\d,而表示一个普通的反斜杠是 \\\\。
* 一个反斜杠是\\\\ 是因为前面两个\\是 表示我要插入一个正则表达式,后面的\\ 第一个斜杠是转义,第二个\ 是真正的\.
* 其实你写字符串的时候,第非正则表达式,表示一个斜杠的写法也是\\
*
*/
//true 因为正则中,\ 用\\ 表示,所以,java 字符串里面的"\\",在正则里面就是\\\\
// Pattern pattern = Pattern.compile("\\\\");
// System.out.println(pattern.matcher("\\").find());
//编译报错 因为这是一个斜杠 斜杠把" 给转义了,没有完整的字符串
// Pattern pattern = Pattern.compile("\\");
// System.out.println(pattern.matcher("\\").find());
//false
// Pattern pattern = Pattern.compile("\\w");
// System.out.println(pattern.matcher("\\").find());
//true 两个斜杠的正则
// Pattern pattern2 = Pattern.compile("\\\\\\\\");
// System.out.println(pattern2.matcher("\\\\").find());
// false 正则表达式\\\\n 对应的字符串是\\n, 也就是\n 字符串,不是换行符,
// Pattern pattern2 = Pattern.compile("\\\\n");
// System.out.println(pattern2.matcher("\n").find());
// true 正则表达式\\\\n 对应的字符串是\\n, 也就是\n字符串
// Pattern pattern3 = Pattern.compile("\\\\n");
// System.out.println(pattern3.matcher("\\n").find());
//// true 直接写的字符串 匹配 没有使用正则,因为正则是\\
// Pattern pattern2 = Pattern.compile("\n");
// System.out.println(pattern2.matcher("\n").find());
// true 因为\\n 是正则表达式定义的换行
// Pattern pattern2 = Pattern.compile("\\n");
// System.out.println(pattern2.matcher("\n").find());
//正则表达式 true 不太明白这个三个斜杠 其实是
// Pattern pattern2 = Pattern.compile("\\\n");
// System.out.println(pattern2.matcher("\n").find());
//正则表达式 false 正则是匹配一个换行符,字符是一个\,一个n
// Pattern pattern2 = Pattern.compile("\\\n");
// System.out.println(pattern2.matcher("\\n").find());
//正则表达式 false 正则是一个斜杠一个n 字符串是换行符
// Pattern pattern2 = Pattern.compile("\\\\n");
// System.out.println(pattern2.matcher("\n").find());
//正则表达式 true
// Pattern pattern2 = Pattern.compile("123\\w");
// System.out.println(pattern2.matcher("123a").find());
// fasle 原来正则和字符串匹配可以混着用
// Pattern pattern2 = Pattern.compile("123\\wabc");
// System.out.println(pattern2.matcher("123abc").find());
// true
// Pattern pattern2 = Pattern.compile("\\a");
// System.out.println(pattern2.matcher("\u0007").find());
//false
// Pattern pattern2 = Pattern.compile("\\.a");
// System.out.println(pattern2.matcher("aa").find());
//true 因为正则表达式. 就是任意字符
// Pattern pattern2 = Pattern.compile(".a");
// System.out.println(pattern2.matcher("aa").find());
//false 因为多个一个大括号
// Pattern pattern2 = Pattern.compile("\\p{Lower}{4,}}");
// Matcher aaaa = pattern2.matcher("aaaa");
// System.out.println(aaaa.find());
// //true
// Pattern p = Pattern.compile("\\p{Lower}{4,}");
// Matcher m = p.matcher("aaaaaf");
// System.out.println(m.find());
// (?X) X, as a named-capturing group
// Pattern p = Pattern.compile("(?\\w{3})");
// Matcher m = p.matcher("aaaaaf");
// if (m.find()) {
// System.out.println(m.group("aa"));
// }else {
// System.out.println("not find");
// }
// (?:X) X, as a non-capturing group 可以找到 ,并且打印组的时候有值
// Pattern p = Pattern.compile("(?:\\w{3})");
// Matcher m = p.matcher("aaaaaf");
// if (m.find()) {
// System.out.println(m.group());
// }else {
// System.out.println("not find");
// }
// (?=X) X, via zero-width positive lookahead 找得到 但是m.group 是空的
// Pattern p = Pattern.compile("(?=\\w{3})");
// Matcher m = p.matcher("aaaaaf");
// if (m.find()) {
// System.out.println(m.group());
// }else {
// System.out.println("not find");
// }
// (?<=X) X, via zero-width positive lookbehind 找得到 但是m.group 是空的
// Pattern p = Pattern.compile("(?<=\\w{3})");
// Matcher m = p.matcher("aaaaaf");
// if (m.find()) {
// System.out.println(m.group());
// }else {
// System.out.println("not find");
// }
// (?X) X, as an independent, non-capturing group 有值
// Pattern p = Pattern.compile("(?>\\w{3})");
// Matcher m = p.matcher("aaaaaf");
// if (m.find()) {
// System.out.println(m.group());
// }else {
// System.out.println("not find");
// }
// (?:X) X, as a non-capturing group 确实只是匹配没有记录值 groupCount 是 0
// Pattern p = Pattern.compile("(?:\\w{3})(?:\\w{3})(?:\\w{3})");
// Matcher m = p.matcher("aaabbbccc");
// if (m.find()) {
// System.out.println(m.group());
// System.out.println(m.groupCount());
// }else {
// System.out.println("not find");
// }
Pattern p = Pattern.compile("(\\w{3}){3}");
Matcher m = p.matcher("aaabbbccc");
if (m.find()) {
System.out.println(m.group());
System.out.println(m.groupCount());
}else {
System.out.println("not find");
}
在notepad++ 里面测试练习正则表达式:(超级爽,对学习正则很有帮助)
notepad 里面是支持正则表达式搜索的,我们可以在notepad++ 里面练习。不过有一点需要注意,notepad++ 里面反斜杠,就是一个, 只有java 正则表达式里面\ 用 \ 表式。
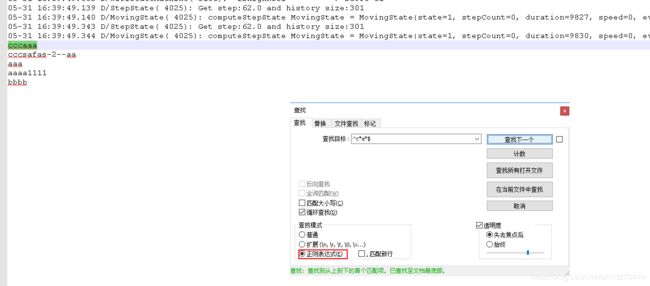
备注:interj ide 也支持正则搜索,也是\ 表示反斜杠:
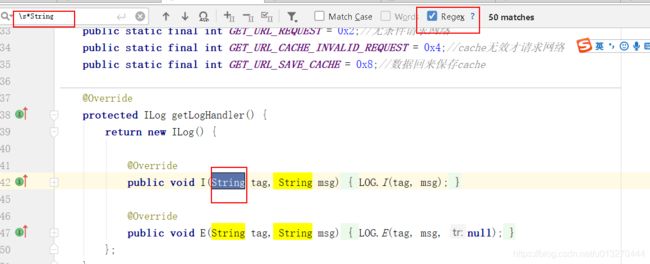
推荐观看:
超级推荐,官方权威:
https://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html
比较推荐,菜鸟
https://www.runoob.com/java/java-regular-expressions.html
其实,最重要的文档,还是源代码。看源代码里面怎么写的,你就知道你的正则表达式可以怎么写!