Scrapy设置随机请求头爬取猫眼电影TOP100并用xpath解析数据后存入MongoDB
Scrapy设置随机请求头爬取猫眼电影TOP100并用xpath解析数据后存入MongoDB。
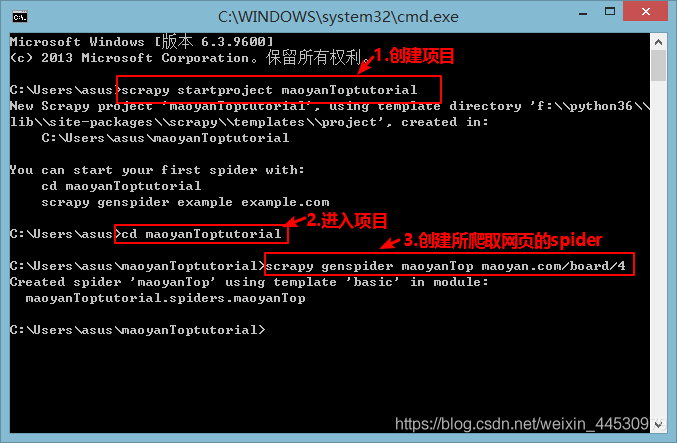
**1、**首先我们先创建一个scrapy项目,运行CMD后按下图所示进行创建:
**2、**项目创建好后,用pycharm打开项目maoyanToptutorial。在爬虫过程中,我们常会使用各种伪装来降低被目标网站反爬的概率,其中随机更换User-Agent就是一种手段。当我们的scrapy项目创建完成并执行时,首先会读取setting.py文件的配置,而在框架机制里又存在一个下载中间件,在setting.py里是默认关闭的,所以要先开启它(即去掉注释)。
setting.py
#随机跳变User-agent
DOWNLOADER_MIDDLEWARES = {
'maoyanToptutorial.middlewares.MaoyantoptutorialDownloaderMiddleware': 543,
}
注释去除后来到middlewares.py文件填补相关程序,在改文件下有一个类MaoyantoptutorialDownloaderMiddleware,在该类下定义一个方法,此方法主要是创建一个UA列表即:
def __init__(self):
#UA列表
self.USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
同样的在MaoyantoptutorialDownloaderMiddleware类下有一个process_request方法,主要是为了实现从UA列表中随机返回一个UA,我们将它改写为:
def process_request(self, request, spider):
request.headers['User-Agent']=random.choice(self.USER_AGENT_LIST)
至此,我们就实现了在scrapy中设置随机User-Agent,接下来我们将分析目标站点的URL请求规律后实现用xpath提取数据并存入MongoDB.。
**3、**打开chrome的开发者工具,切换到Network后刷新页面,观察到服务器返回给我们的东西里只有第一个请求URL:https://maoyan.com/board/4里有我们所需要的数据,切换到Response可以找到所需要的数据,如下图所示:
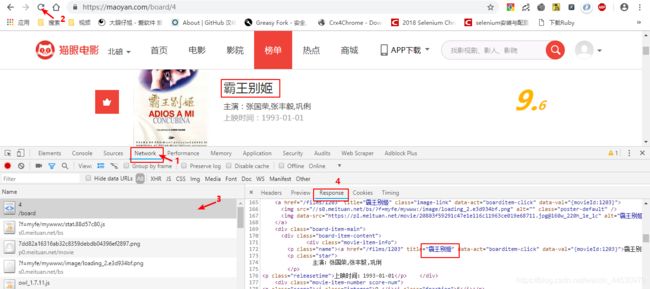
接着我们点击下一页获取更多的信息,并找到对相应的URL为:https://maoyan.com/board/4?offset=10 ,对URL进行比对分析后我们可以发现其中变化的字段为offset后的数字,且每次以10个偏移度增加,由此我们可以得到一个简化的URL为:https://maoyan.com/board/4?offset={“偏移度增加10”} ,接下来我们开始写爬虫程序。
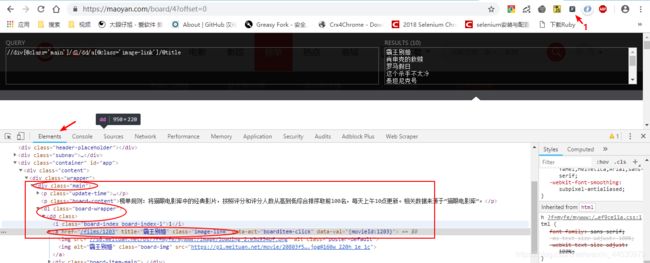
**4、**由Response中的信息可知,我们所提取的数据在某些节点中,为了能够更好的解析页面信息,此处我们使用XPath解析库来提取节点,然后再调用相应方法获取它的正文内容或者属性值,此外我们还借助chrome浏览器的XPath Helper插件来辅助检查我们所写的匹配规则是否正确。比如以提取电影名为例,如下图所示:
**5、**知道提取规则后 ,我们开始写相应代码,首先来到items.py下定义item对象,即:
import scrapy
class MaoyantoptutorialItem(scrapy.Item):
title = scrapy.Field()#电影名称
star = scrapy.Field()#演员
releasetime = scrapy.Field()#上映时间
score=scrapy.Field()#评分
为了将数据存入MongoDB,我们还需在pipelines.py下添加以下代码:
pipelines.py
import pymongo
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url=mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url=crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client=pymongo.MongoClient(self.mongo_url)
self.db=self.client[self.mongo_db]
def process_item(self,item,spider):
name=item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
接着在setting.py文件的配置数据库的连接参数,即添加以下代码:
setting.py
MONGO_URL='localhost'
MONGO_DB='MAOYANTOP'
#启用MongoPipeline
ITEM_PIPELINES = {
'maoyanToptutorial.pipelines.MongoPipeline': 300,
}
**6、**以上内容设置好后,来到spiders文件下的maoyanTop.py实现主要的爬取逻辑,代码如下:
maoyanTop.py
# -*- coding: utf-8 -*-
import scrapy
from maoyanToptutorial.items import MaoyantoptutorialItem
class MaoyantopSpider(scrapy.Spider):
name = 'maoyanTop'
allowed_domains = ['maoyan.com/board/4/?offset=']
start_urls = ['https://maoyan.com/board/4/?offset=']
# 下一页前缀url
next_base_url = 'http://maoyan.com/board/4'
def parse(self, response):
if response:
movies=response.xpath('//div[@class="main"]/dl/dd')# 获取每页所有电影的节点
item = MaoyantoptutorialItem()
for movie in movies:
title=movie.xpath('.//a[@class="image-link"]/@title').extract_first()
star=movie.xpath('.//div[@class="movie-item-info"]/p[@class="star"]/text()').extract_first()
releasetime=movie.xpath('.//div[@class="movie-item-info"]/p[@class="releasetime"]/text()').extract_first()
score_1=movie.xpath('.//div[contains(@class,"movie-item-number")]/p[@class="score"]/i[@class="integer"]/text()').extract_first()
score_2=movie.xpath('.//div[contains(@class,"movie-item-number")]/p[@class="score"]/i[@class="fraction"]/text()').extract_first()
item['title']=title
item['star'] = star.strip()[3:]
item['releasetime'] = releasetime.strip()[5:]
item['score'] = score_1+score_2
yield item
# 处理下一页
next=response.xpath('.').re_first(r'href="(.*?)">下一页')
if next:
next_url = self.next_base_url + next
# scrapy会对request的URL去重,加上dont_filter=True则告诉它这个URL不参与去重
yield scrapy.Request(url=next_url,callback=self.parse, dont_filter=True)
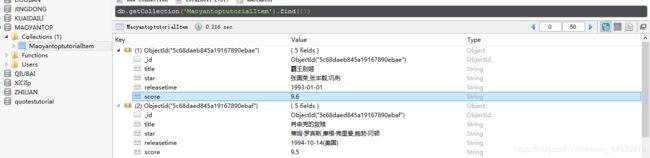
**6、**爬取结果如下图: