SpringBoot整合Mybatis和ShardingJDBC实现分库分表
案例描述
通过一个简单的案例实现SpringBoot+Mybatis+ShardingJdbc分库分表实践
通过商品表(good)进行演示:最简单的good表有三个属性:id,good_name, good_type
- 根据id进行分库,当id<=20时使用database0,id>20时,使用database1
- 根据good_type进行分表:当good_type为偶数时,使用good_0,当good_type为奇数时,使用good_1
创建数据库
通过MySQL进行相应代码展示:
create database database0;
use database0;
create table `good_0`(
id bigint(20) primary key ,
good_name varchar(64) COLLATE utf8_bin default '',
good_type bigint(20) default 0
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
create table `good_1`(
id bigint(20) primary key ,
good_name varchar(64) COLLATE utf8_bin default '',
good_type bigint(20) default 0
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
create database database1;
use database1;
create table `good_0`(
id bigint(20) primary key ,
good_name varchar(64) COLLATE utf8_bin default '',
good_type bigint(20) default 0
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
create table `good_1`(
id bigint(20) primary key ,
good_name varchar(64) COLLATE utf8_bin default '',
good_type bigint(20) default 0
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
以下为项目演示
引入pom文件
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.2.5.RELEASEversion>
<relativePath/>
parent>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.20version>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>com.dangdanggroupId>
<artifactId>sharding-jdbc-coreartifactId>
<version>1.5.4version>
dependency>
配置数据源信息
通过@ConfigurationProperties和@PropertySource注解,将相关配置信息单独配置在一个properties文件中,从而避免项目庞大后,application.properties文件变的膨胀
- 在main主类中启用自定义配置属性
/**
* 注意:其他博客写道需要通过exclude去除JPA的自定义Datasource配置,但亲测不需要也可以。这个大家还是可以尝试
* @SpringBootApplication:启动类注解
* @EnableConfigurationProperties:启用自定义配置
* @MapperScan:后面将说到的,Mybatis的Mapper文件扫描路径
* @EnableTransactionManagement:启用事务管理器
*/
@SpringBootApplication
// 去除数据库数据源自动配置,改为自定义配置,使用ShardingJDBC
//@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
@EnableConfigurationProperties
@MapperScan("com.wechat.dao.mapper")
@EnableTransactionManagement(proxyTargetClass = true)
public class WeChatGatewayApplication {
public static void main(String[] args) {
new SpringApplication(WeChatGatewayApplication.class).run(args);
}
}
- 通过自定义属性文件配置数据源:
shardingjdbc.properties
datasource0.driver-class-name=com.mysql.cj.jdbc.Driver
datasource0.url=jdbc:mysql://localhost:3306/database0?serverTimezone=UTC
datasource0.username=root
datasource0.password=root
datasource0.database-name=database0
datasource1.driver-class-name=com.mysql.cj.jdbc.Driver
datasource1.url=jdbc:mysql://localhost:3306/database1?serverTimezone=UTC
datasource1.username=root
datasource1.password=root
datasource1.database-name=database1
配置数据源1:Datasource0Config.java
@Data
@Component
@ConfigurationProperties(prefix = "datasource0")
@PropertySource("classpath:shardingjdbc.properties")
public class Datasource0Config {
private String driverClassName;
private String url;
private String username;
private String password;
private String databaseName;
public DataSource createDataSource(){
DruidDataSource dataSource0 = new DruidDataSource();
dataSource0.setDriverClassName(driverClassName);
dataSource0.setUrl(url);
dataSource0.setUsername(username);
dataSource0.setPassword(password);
return dataSource0;
}
}
配置数据源2:Datasource1Config.java
@Data
@Component
@ConfigurationProperties(prefix = "datasource1")
@PropertySource("classpath:shardingjdbc.properties")
public class Datasource1Config {
private String driverClassName;
private String url;
private String username;
private String password;
private String databaseName;
public DataSource createDataSource(){
DruidDataSource dataSource1 = new DruidDataSource();
dataSource1.setDriverClassName(driverClassName);
dataSource1.setUrl(url);
dataSource1.setUsername(username);
dataSource1.setPassword(password);
return dataSource1;
}
}
配置分库算法,实现ShardingJDBC提供的接口SingleKeyDatabaseShardingAlgorithm,实现分库规则(按照id字段是否大于20进行分库选择:DatabaseShardingAlgorithm.java
@Configuration
public class DatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm<Long> {
@Autowired
private Datasource0Config datasource0Config;
@Autowired
private Datasource1Config datasource1Config;
@Override
public String doEqualSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
long value = shardingValue.getValue();
if (value <= 20L) {
return datasource0Config.getDatabaseName();
} else {
return datasource1Config.getDatabaseName();
}
}
@Override
public Collection<String> doInSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<>(collection.size());
for (long value : shardingValue.getValues()) {
if (value <= 20L) {
result.add(datasource0Config.getDatabaseName());
} else {
result.add(datasource1Config.getDatabaseName());
}
}
return result;
}
@Override
public Collection<String> doBetweenSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<>(collection.size());
Range<Long> range = shardingValue.getValueRange();
for (long value = range.lowerEndpoint(); value <= range.upperEndpoint(); value++) {
if (value <= 20L) {
result.add(datasource0Config.getDatabaseName());
} else {
result.add(datasource1Config.getDatabaseName());
}
}
return result;
}
}
配置分表算法:实现ShardingJDBC提供的接口SingleKeyTableShardingAlgorithm,制定分表规则(按照good_type的奇偶性进行分表:TableShardingAlgorithm.java
@Configuration
public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Long> {
@Autowired
private Datasource0Config datasource0Config;
@Autowired
private Datasource1Config datasource1Config;
@Override
public String doEqualSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
long value = shardingValue.getValue();
for (String each : collection) {
if (each.endsWith(value % 2 + "")) {
return each;
}
}
throw new IllegalArgumentException();
}
@Override
public Collection<String> doInSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<>(collection.size());
for (Long value : shardingValue.getValues()) {
for (String tableName : collection) {
if (tableName.endsWith(value % 2 + "")) {
result.add(tableName);
}
}
}
return result;
}
@Override
public Collection<String> doBetweenSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
Collection<String> result = new LinkedHashSet<>(collection.size());
Range<Long> range = shardingValue.getValueRange();
for (Long i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
for (String each : collection) {
if (each.endsWith(i % 2 + "")) {
result.add(each);
}
}
}
return result;
}
}
组装两个物理数据源以及相应的分库分表算法,定义一个逻辑数据源,即dataSource这个JavaBean:DatasourceConfig .java
@Configuration
public class DatasourceConfig {
@Autowired
private Datasource0Config datasource0Config;
@Autowired
private Datasource1Config datasource1Config;
@Autowired
private DatabaseShardingAlgorithm databaseShardingAlgorithm;
@Autowired
private TableShardingAlgorithm tableShardingAlgorithm;
@Bean
public DataSource dataSource() throws SQLException {
return buildDataSource();
}
private DataSource buildDataSource() throws SQLException {
//分库设置
Map<String, DataSource> dataSourceMap = new HashMap<>(2);
//添加两个数据库database0和database1
dataSourceMap.put(datasource0Config.getDatabaseName(), datasource0Config.createDataSource());
dataSourceMap.put(datasource1Config.getDatabaseName(), datasource1Config.createDataSource());
//设置默认数据库
DataSourceRule dataSourceRule = new DataSourceRule(dataSourceMap, datasource0Config.getDatabaseName());
//分表设置,大致思想就是将查询虚拟表Goods根据一定规则映射到真实表中去
TableRule orderTableRule = TableRule.builder("good")
.actualTables(Arrays.asList("good_0", "good_1"))
.dataSourceRule(dataSourceRule)
.build();
//分库分表策略
ShardingRule shardingRule = ShardingRule.builder()
.dataSourceRule(dataSourceRule)
.tableRules(Arrays.asList(orderTableRule))
.databaseShardingStrategy(new DatabaseShardingStrategy("id", databaseShardingAlgorithm))
.tableShardingStrategy(new TableShardingStrategy("good_type", tableShardingAlgorithm)).build();
DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule);
return dataSource;
}
@Bean
public KeyGenerator keyGenerator() {
return new DefaultKeyGenerator();
}
}
编写测试代码
- 定义实体类:Good.java
@Data
public class Good {
private Long id;
private String goodName;
private Long goodType;
}
- 定义Mapper:GoodMapper.java
@Mapper
public interface GoodMapper {
int insert(Good good);
}
- 定义Mapper.xml: classpath:mapper/GoodMapper.xml
<mapper namespace="com.wechat.dao.mapper.GoodMapper">
<insert id="insert" parameterType="com.wechat.dao.entity.Good">
insert into good(id, good_name, good_type) values(#{id}, #{goodName}, #{goodType})
insert>
mapper>
- 定义Controller接口:GoodController
@RestController
@RequestMapping("/goods")
public class GoodController {
@Autowired
private GoodMapper goodMapper;
@RequestMapping("/insert/{num}")
public String insertGoods(@PathVariable("num") Long num) {
Random random = new Random(System.currentTimeMillis());
for (int i = 0; i < num; i++) {
Good good = new Good();
good.setId(i + 0L);
good.setGoodName("Good-" + i);
good.setGoodType(random.nextInt(2) + 0L);
goodMapper.insert(good);
}
return "SUCCESS";
}
}
测试及结果
1 测试:通过http请求:
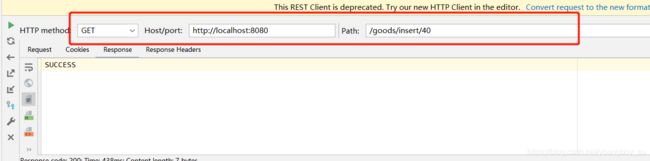
2. 结果查询:
-
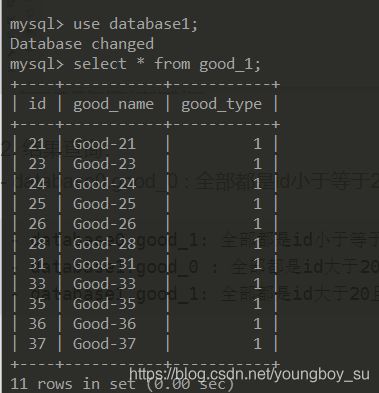
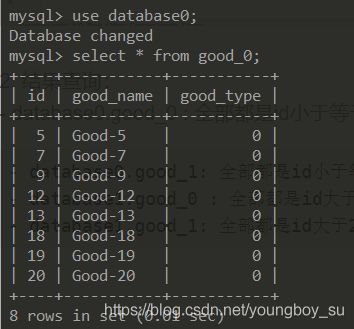
database0.good_0 : 全部都是id小于等于20且good_type为偶数的记录
-
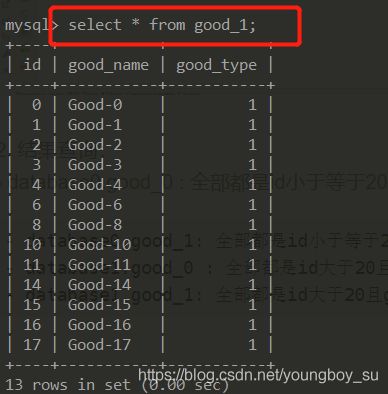
database0.good_1: 全部都是id小于等于20且good_type为奇数的记录
-
database1.good_0 : 全部都是id大于20且good_type为偶数的记录
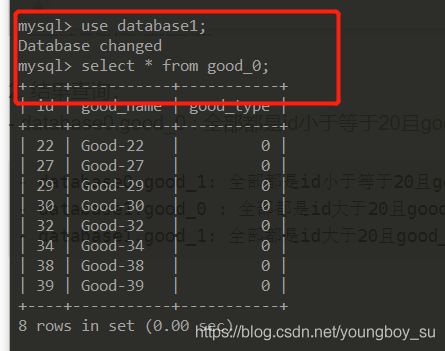
-
database1.good_1: 全部都是id大于20且good_type为奇数的记录