Ranking第7名,2020 CrowdHuman大赛Baseline发布
今年5月,2020 CrowdHuman人体检测大赛启动上线,本届比赛是CrowdHuman人体检测赛的第二期。2019年北京智源人工智能研究院联合旷视科技共同推出了两个检测任务的新基准:Objects365和CrowdHuman,并同步开放了数据评测。Objects365基准目标用于解决具有365个对象类别的大规模检测,而CrowdHuman则针对人群中的人体检测问题。智源希望这两个数据集能够为推进目标检测研究提供多样化、实用性的基准。
扫描下方二维码
或点击阅读原文
前往大赛官网报名参赛

本次比赛将于8月24日截止提交
赛题简介
2020 CrowdHuman人体检测挑战赛是为了推动行人检测技术的发展而举办的,旨在针对现有行人检测数据集的密集场景不足等问题进行改善。在计算机视觉领域,目标检测至今仍然是较为活跃的一个研究方向,而行人检测就是更具体的目标检测,即只需要检测出图片中的行人即可。与通用目标检测相比,行人检测有自己的差异化特征。此外,从落地空间以及实用价值来看,行人检测更是一个值得研究的课题,例如可以用于自动驾驶、城市安全等领域。
1. 任务描述
比赛任务要求选手们利用训练集数据设计、训练人体检测算法模型,模型输入为图片id以及图片文件,需要输出图片中的人体标注框体所在坐标以及置信度。
2. 比赛数据集
本次比赛发布的CrowdHuman数据集包含15,000张训练图片、4,370张验证图片和5,000张测试图片。CrowdHuman数据集图片中总计有47万个人类实例,每张图片中平均有 22.6个人,同时存在各种各样的遮挡。每个人类实例都用头部边界框、人体可视区域边界框和人体全身边界框标注。
CrowdHuman图片样例
3.评测标准
本次比赛采用Jaccard Index(JI)评测方法。JI评测标准较为适合密集场景的检测任务。具体来说,给定一组检测框D和标注框G,JI定义为:
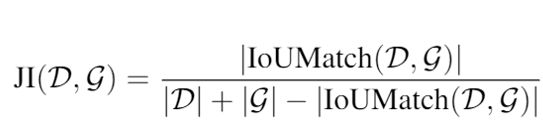
其中,IoUMatch定义如下:

Baseline模型
本baseline基于IterDet,略微修改了配置文件。原工程地址:https://github.com/saic-vul/iterdet
该算法于2020年5月发布,是目前CrowdHuman数据集的SOTA。Baseline线上得分0.7809,目前位于智源2020 CrowdHuman 大赛排行榜第七名。
1. 赛题分析
本题是一个典型的目标检测问题,针对目标检测已有大量的研究论文和开源项目,例如faster-RCNN、YOLO等等。
与绝大多数的目标检测任务不同,比赛数据集CrowdHuman待检目标更加地密集、拥挤甚至有严重的重叠现象。从下表可以看出,该数据集平均每张图的人物数达到了22.64个,远大于其他主流的人体检测数据集。这是本赛题的难点所在。
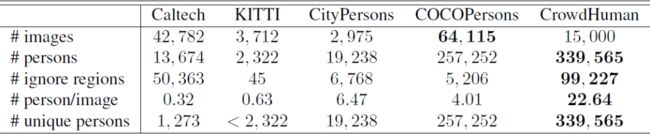
人体检测数据集对比
下面放一个样例图片大家感受一下:
CrowdHuman图片样例
2. Baseline算法特点
IterDet算法的主要贡献是提供了一种解决大量密集目标检测问题的新方法。IterDet算法主要通过迭代的方式循序渐进地进行多次检测,每次检测都会引入上次检测的结果作为特征(即下图的History map):
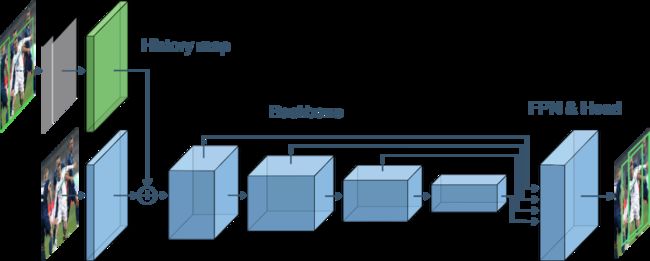
IterDet History map
论文在检测网络部分并没有做太多的创新,因此可以替换Backbone和FPN & Head来进一步提升算法性能。
3. 目录结构
本算法使用mmdetection框架进行开发,目录结构也比较典型。
1)mmdet是主要的代码文件夹,在mmdetection的基础上论文作者修改了以下文件:
mmdet/datasets/init.py
mmdet/datasets/pipelines/transforms.py
mmdet/datasets/pipelines/formating.py
mmdet/datasets/crowd_human.py
mmdet/models/dense_heads/anchor_head.py
mmdet/models/dense_heads/rpn_head.py
mmdet/models/roi_heads/bbox_heads/bbox_head.py
mmdet/models/backbones/resnet.py
mmdet/models/detectors/init.py
mmdet/models/detectors/iterdet_faster_rcnn.py
mmdet/models/detectors/iderdet_retinanet.py
2)configs是配置文件目录,在原框架基础上论文作者修改了以下文件:
configs/iterative/*
3)tools目录是主程序入口及一些工具,在原框架技术上论文作者修改了以下文件:
tools/convert_datasets/crowd_human.py
tools/convert_datasets/toy.py
tools/convert_datasets/wider_person.py
4)evaluate是线下评测相关文件,具体使用方式见后文。
5)prostprocessing是后处理相关文件,用于生成针对比赛的可提交的结果文件。
4. Baseline运行步骤
1)环境配置:
在原工程文件中,作者在Get Started文件中详细地阐述了从配置文件路径结构到预训练模型推论以及模型训练的详细步骤。各位参赛选手可以按照原工程的说明进行环境配置。
2)下载数据集,将数据文件放置在data/crowd_human目录下。
3)下载权重(链接在原工程readme文档中),放置在work_dirs/iterdet/crowd_human_full_faster_rcnn_r50_fpn_2x/目录下。
4)运行转换程序
python tools/convert_datasets/crowd_human.py
5)运行测试程序
python tools/test.py configs/iterdet/crowd_human_full_faster_rcnn_r50_fpn_2x.py work_dirs/iterdet/crowd_human_full_faster_rcnn_r50_fpn_2x/crowd_human_full_faster_rcnn_r50_fpn_2x.pth --out result.pkl --eval bbox
运行结束后会在根目录生成result.pkl和file_info.pkl文件。
6)生成提交结果
由于CrowdHuman的提交格式为(x,y,h,w),所以需要运行以下文件进行转换:
cd postprocessing
python postprocessing.py
运行完成后将会在目录下生成submission.txt文件,参赛选手可前往大赛官网提交评测。比赛提交地址:http://competition.baai.ac.cn/c/34/format/introduce?sourceType=public
7)线下评测
评测代码已包含在本baseline的evaluate目录下,若各位选手需要线下评测可以按如下方式运行:
cd evaluate
python demo.py
经过测试,线上成绩优于线下成绩,线下得分大约为0.74。
5. Baseline算法说明
关于IterDet算法本身,各位可以参考相关论文。除了该方法以外,在本baseline中还进行了一些提分操作:
在两个检测器的FPN中,在每个卷积层之后添加一个批标准化层,这将稍微提高性能。
不要冻结ResNet的第一个block,因为我们在这个block之前添加了历史和可训练的卷积层。
在baseline的最后,作者向参赛选手推荐了2019 CrowdHuman检测大赛冠军队伍在知乎上分享的比赛心得。各位参赛选手可以在仔细阅读后,基于本baseline继续优化提升分数。
值得一提的是,2019 CrowdHuman大赛冠军团队成员葛政于今年6月在biendata社区b站官方号分享了2019 CrowHuman竞赛的技术方案和比赛技巧,近期biendata将发布直播整理的文字稿件供各位同学交流学习。
2020智源人工智能系列大赛
2020年5月,2020 智源人工智能系列大赛正式启动。本届大赛由北京智源人工智能研究院主办,旷视科技、智谱·AI等人工智能科技企业协办。2020 智源系列大赛全年共将举办10场赛事,本届赛事的赛题将专注于医疗、交通、教育等领域。
去年9月首届智源人工智能大赛启动,赛事期间共吸引了接近9,000名来自顶尖高校、科技企业、科研机构的数据科学学者。2020 智源大赛依托于智源数据开放研究中心(BAAI OPEN DATA),将本届赛事全面升级。本届大赛以智源竞赛平台为赛事举办主体,并同步开放赛题数据集共享,秉承着以数据与知识共享为宗旨通过人工智能竞赛,选拔培育人工智能创新人才。
智源数据开放研究中心以“数据共享”、“数据竞赛”、“数据研究”三大主题为建设目标,旨在促进人工智能领域的数据与知识共享。中心以“三大主题,一个平台”为行动方针,通过研究数据开放核心技术,搭建数据开放研究平台,推进人工智能领域的创新发展。