这是本公众号的第 14 篇原创文章
线程是每个Java开发者都绕不开的大山。而线程池更是工作中用得最多,面试也问得最多的知识点。
但很多小伙伴其实对线程池还处于一知半解的状态,不清楚它的核心原理和逻辑,甚至不知道该如何更好地配置线程池参数。接下来咱们就来聊聊,如何更好地驾驭线程池。
为什么使用线程池?
了解一个技术,首先要了解它产生的原因。
大家可以想一想,如果只是为了开多线程去跑一些任务,我们不用线程池也可以做到,new一个Thread,调用start()方法就走起。那为什么我们还需要线程池?
线程池主要有这三个作用:
- 统一管理
- 复用线程
- 控制并发数量
统一管理不难理解,线程池其实算是一个线程的调度系统。线程池里面有一个调度线程,这个调度线程用于管理布控整个线程池里的各种任务和事务,例如创建线程、销毁线程、任务队列管理、线程队列管理等等。
复用线程是线程池最大的优势。因为创建和销毁线程开销比较大,如果为每个任务都创建一个新的线程,那其实是不划算的。线程池实现了线程的复用,使得一个线程可以执行多个任务,这在需要大量线程的场景下(比如HTTP请求等),可以很大程度地节约机器资源。
控制并发数量指的是使用线程池可以控制同时运行的线程数量。大家知道多线程的优势在于利用计算机的多核心处理能力,但计算机的核心数量是有限的,比如4核、8核等,如果线程数量太多,切换线程有上下文的开销,反而会让整个机器的吞吐量下降。
❝
吞吐量指的是单位时间内能够处理的任务数量。
❞
线程池的原理
了解到为什么使用线程池以后,我们再来看看它的原理。
首先我们上一个图:
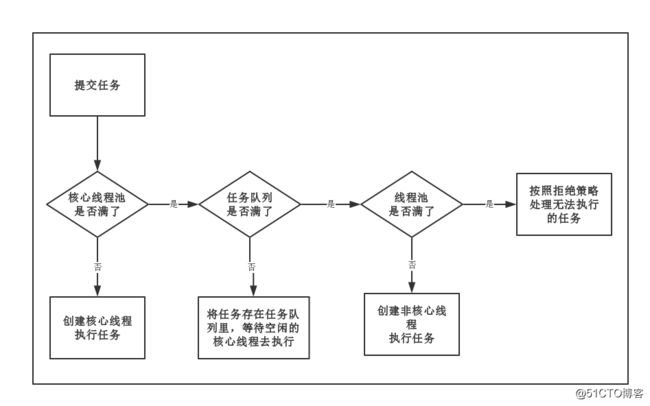
线程池原理图
然后我们来解释一下图里说的几个概念:
「核心线程」:线程池中有两类线程,核心线程和非核心线程。核心线程默认情况下创建后,就会一直存在于线程池中,即使这个核心线程什么都不干(铁饭碗),而非核心线程如果长时间的闲置,就会被销毁(临时工)。
「任务队列」:等待队列,维护着等待执行的Runnable任务对象,是一个线程安全的阻塞队列。
「线程池满」:指的是核心线程+非核心线程的总线程数量达到线程池设定的阈值。
「拒绝策略」:线程池满以后,表示当前线程池没有能力处理更多的任务了,那如果来了新的任务该怎么办呢?所以在创建线程池的时候,可以指定这个拒绝策略。
线程池的七个参数
上面介绍了线程池的原理,里面提到的各种阈值,都是在线程池的构造方法里可以指定的。Java使用ThreadPoolExecutor这个类来实现的线程池。它有几个重载的构造方法,参数从5个到7个不等,但最终都是调用的7个参数的这个构造方法,下面我们分别来介绍一下这几个参数。
// 七个参数的构造函数
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
其中,前面4个参数好理解,名字也很表意,它们代表的意义分别是:核心线程的最大值,线程总数(核心+非核心)最大值,非核心线程空闲时间,非核心线程空闲时间的单位。
然后介绍一下后面三个参数。
workQueue
任务队列,是一个线程安全阻塞队列BlockingQueue
- LinkedBlockingQueue:链式阻塞队列,底层数据结构是链表,默认大小是Integer.MAX_VALUE,也可以指定大小;
- ArrayBlockingQueue:数组阻塞队列,底层数据结构是数组,需要指定队列的大小;
- SynchronousQueue:同步队列,内部容量为0,每个put操作必须等待一个take操作,反之亦然。
- DelayQueue:延迟队列,该队列中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。
❝
一般来说,用LinkedBlockingQueue和ArrayBlockingQueue的场景较多。选择哪个在于你想不想限制任务队列的数量。
❞
threadFactory
创建线程的工厂 ,用于批量创建线程,统一在创建线程时设置一些参数,如线程名称、是否守护线程、线程的优先级等。ThreadFactory也是一个接口。如果不指定,会使用DefaultThreadFactory新建一个默认的线程工厂。
很多时候我们会自己实现一个ThreadFactory,在里面指定线程的名称前缀,这样在排查问题的时候就能一眼看到这个线程是在这个线程池里面创建的。
handler
「拒绝处理策略」,线程数量大于最大线程数就会采用拒绝处理策略,四种拒绝处理的策略为:
「ThreadPoolExecutor.AbortPolicy」:默认拒绝处理策略,丢弃任务并抛出RejectedExecutionException异常。
「ThreadPoolExecutor.DiscardPolicy」:丢弃新来的任务,但是不抛出异常
「ThreadPoolExecutor.DiscardOldestPolicy」:丢弃队列头部(最旧的)的任务,然后重新尝试执行程序(如果再次失败,重复此过程)。
「ThreadPoolExecutor.CallerRunsPolicy」:由调用线程处理该任务。
如何复用线程的?
前面我们提到线程池的三个好处:统一管理、复用线程、控制并发线程数量。统一管理体现在threadFactory,控制并发线程数量体现在workQueue。那线程池是如何复用线程的呢?
ThreadPoolExecutor在创建线程时,会将线程封装成「工作线程worker」,并放入「工作线程组」中,然后这个worker反复从阻塞队列中拿任务去执行。这个Worker是一个内部类,它继承了AQS,实现了Runnable:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
// 省略
}注意这里的“工作线程组”不是前面提到的任务队列workQueue,而是一个HashSet:
private final HashSet workers = new HashSet(); 这个worker在创建后,就会去任务队列里不断拿新的任务出来,然后调用这个任务的run()方法。具体源码在worker.runWorker方法里。
所以看到这里你明白了吗?我们通过线程池的execute(Runnable command)方法,扔进线程池的线程,并没有像我们平时创建线程一样,新建一个Thread,然后调用start方法去启动,而是由一个个worker直接调用run()方法去执行的,这样就达到了复用线程的目的。
使用线程池应该注意什么?
最最重要的一点,注意参数。每一个参数都需要仔细考量,尤其是核心线程数量、最大线程的数量、非核心线程存活时间。
如何配置线程池的参数是一个难题,它需要你考虑到方方面面,尤其是你的程序不只一个线程池的时候。而且这跟你的任务数量也有一定的关系,所以最好提前做好预估和调研。
核心线程不要太多,一般是CPU核心数量的2倍即可。
了解原理后,可以根据业务场景去设置线程池的参数。
绝大多数时候其实是核心线程在工作,只有当任务队列满之后,才会启动非核心线程。所以任务队列是有讲究的,如果你使用基于链表的阻塞队列,那它的最大长度是Integer.MAX_VALUE,大量的任务堆积可能会导致OOM。
所以在任务数量可以大概预估的时候,尤其是执行一些自己写的task之类的程序,比较推荐用基于数组的阻塞队列,限制一下阻塞队列的长度。这样超过长度的,就可以启动一些临时线程去处理,加大系统的吞吐量。
拒绝策略也很重要,如果不是很重要的任务,可以直接丢弃掉。如果任务比较重要,会影响到应用的主要逻辑,那还是抛一下异常比较好。
JDK提供了一个创建线程池的工具类Executors,提供了一些静态方法用于方便地创建一些特殊的线程池。它其实也是调用的ThreadPoolExecutor的构造方法,只是封装了一下,看起来更语义化。
其实如果你了解了线程池的原理,可以看看这几个静态方法的源码,看看它们分别是用的什么参数,对自己以后配置线程池参数也有一些参考价值。
线程池大概就介绍到这里,如果你想了解更多的Java线程知识,可以去github搜索RedSpider1/concurrent,这是我们之前写的一本关于Java多线程的,成体系的开源电子书,基本上涵盖了绝大多数Java多线程知识点。欢迎star,issue,pr。
关于作者
微信公众号:编了个程(blgcheng)
个人网站:https://yasinshaw.com
- 笔名Yasin,一个努力学习写作的程序员;
- 阿里巴巴高级Java开发工程师;
- RedSpider技术社区发起人;
- 开源书籍《深入浅出Java多线程》作者。
这个公众号很多技术干货,关注肯定不后悔
加个星标可以第一时间看到最新文章
你知道,转发和在看的人都升职加薪了
推荐阅读
- 在Java代码中打日志需要注意什么?
- 一次性把Java的四种引用说清楚!
- 带你通关全栈树型结构设计:从数据库到前端
- 我为什么要做公众号?
- 一个慢SQL引起的惨案
Yasin x
喜欢作者