(详细总结)python爬取 163收件箱邮件内容,收件箱列表的几种方法(urllib, requests, selenium)
需求:最近有一个需求,需要将163邮箱收件箱里面的所有邮件的内容全部copy下来,整理到一个word里面,不多也就28页的邮件(不要问我为什么有这需求,不告诉你),自己手动去ctrl+ cv 的话,估计要搞吐。然后就想能不能用python的爬虫来实现,虽然过程比较苦(后期改bug改的要吐了)。但是会后还是将需求实现了。这基本也算是入门了 urllib、requests、selenium这几个py库。以及辅助的 BeautifulSoup4、python-docx等处理html和word 的py库。好了话不多说,开始我的表演。
总结需求:
1.实现163邮箱自动登录
2.进入收件箱,然后获取收件箱列表
3.通过收件箱列表,依次点击进入邮件,获取邮件里面的邮件内容。
3.然后将获取的邮件内容,写入word
经历了这次疯狂的查文档查资料,最后总结,现在网上的相关文档检测太多了,但是最官方的还是,官方文档(英文),实在看不懂的,可以翻译,或者查找看一看有没有中文的官方文档。 以上用到的库,我基本上都是参考官方中文文档的,下面的博客中会给出文档链接。学会看官方文档是非常有帮助的
一、通过Urllib实现
urllib这是python内置用于处理http相关请求库,官方文档:https://docs.python.org/3/library/urllib.request.html#module-urllib.request 。 性能方便不说,因为我暂时还没感受到,urllib基本上可以解决多数的爬虫问题。我最开始就是用urllib的。虽然后面没有解决问题。但是大部分问题它是解决了的。
刚开始我是先百度了一下, 看了看有没有类似的需求,果然有类似的需求,一共找到了两篇,
第一篇
第二篇
第一篇是通过 Firefox浏览器做的测试,第二篇博客是在第一篇记得基础上通过Chrome浏览器做的测试。
他们的需求:
1. 模拟163邮箱的登陆
2. 获取登陆后的收件箱页面
3. 获取页面中的邮件信息
分析实现
基本实现可以参考 第一篇 第二篇
总结思路:
1. 用浏览器登陆邮箱以获取请求登陆的url以及收件箱网页的url
2. 向该url发送登陆请求,获得response,并利cookie缓存登陆的信息及状态
3. 提取response中的sid码,这是下一步请求所需要的
4. 利用sid码和cookie重新请求,获得响应,重定向至收件箱网页,获取页面信息
5. 提取收件箱列表信息
以上用urllib实现自动登录到进入收件箱,再到获取收件箱列表的信息,代码如下:
import urllib.request
import re
import http.cookiejar
import urllib.parse
import requests
import json
class Mail:
def __init__(self):
self.loginUrl = "https://mail.163.com/entry/cgi/ntesdoor?df=mail163_letter&from=web&funcid=loginone&iframe=1&language=-1&passtype=1&product=mail163&net=t&style=-1&race=-2_42_-2_hz"
# 设置代理,以防止本地IP被封
self.proxyUrl = "http://202.106.16.36:3128"
# 初始化 sid
self.sid = ""
self.username = '*******'
self.pwd = '*******'
self.loginHeaders = {
'Accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "mail.163.com",
'Referer': "http://mail.163.com/",
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
self.post = {
'savelogin': "0",
'url2': "http://mail.163.com/errorpage/error163.htm",
'username': self.username,
'password': self.pwd
}
# 对post编码转换
self.postData = urllib.parse.urlencode(self.post).encode('utf8')
# 使用http.cookiejar.CookieJar()创建CookieJar对象
self.cookie = http.cookiejar.CookieJar()
# 使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象
self.handle = urllib.request.HTTPCookieProcessor(self.cookie)
print("--" * 100)
for item in self.cookie:
print(item.name, item.value)
self.opener = urllib.request.build_opener(self.handle)
# 将opener安装为全局
urllib.request.install_opener(self.opener)
# 模拟登陆并获取sid码
def login(self):
try: # 发出请求
self.request = urllib.request.Request(self.loginUrl, self.postData, self.loginHeaders)
except urllib.error.HTTPError as e:
print(e.code)
print(e.read().decode("utf-8"))
self.response = urllib.request.urlopen(self.request)
for i in self.cookie:
print(i)
# 需要将响应中的内容用read读取出来获得网页代码,网页编码为utf-8
self.content = self.response.read().decode("utf8")
# 打印获得的网页代码
print(self.content)
self.sidpattern = re.compile('sid=(.*?)&', re.S)
self.result = re.search(self.sidpattern, self.content)
self.sid = self.result.group(1)
print("self.sid:", self.sid)
def messageList(self):
listUrl2 = "https://mail.163.com/js6/s?sid=%s&func=mbox:listMessages&welcome_yx_red=1&YdWelbannerShow=1&YxGreetShow=deptId=1|projectId=14&YxRcmdShow=deptId=1|projectId=117_deptId=1|projectId=117_deptId=1|projectId=13_deptId=1|projectId=117_deptId=1|projectId=13_deptId=1|projectId=117_deptId=1|projectId=13_deptId=1|projectId=117&YxLeftNavBottomShow=deptId=1|projectId=117&BizCloseNone=1&topNav_mobileIcon_show=1&welcome_welcomemodule_mailrecom_click=1&welcome_welcomemodule_yxRecomDwon_click=1|1|1&mbox_folder_enter=1" % self.sid
listUrl1 = 'http://mail.163.com/js6/s?sid=%s&func=mbox:listMessages' % self.sid
Headers = {
'Accept': "text/javascript",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "mail.163.com",
'Referer': "https://mail.163.com/js6/main.jsp?sid=%s&df=mail163_letter" % self.sid,
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
# 发起请求并获得响应
request = urllib.request.Request(listUrl2, headers=Headers)
response = self.opener.open(request)
# 提起响应的页面内容,里面是收件箱的信息
content = response.read().decode("utf-8")
return content
if __name__ == "__main__":
# mail = Mail()
# mail.login()
# print(mail.messageList())
问题
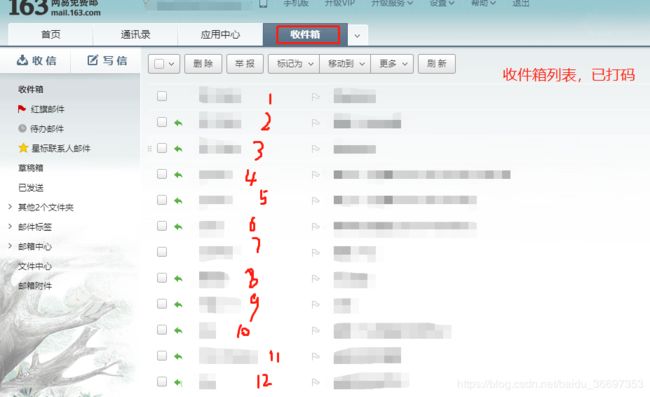
将以上的思路运用到自己的需求当中来,确实可以解决从自动登录到获取收件箱列表信息, 但是当点击进入某一个邮箱获取具体内容的时候,如下图,点击进入1,可以进入看到具体的邮件内容。

抓包可以看到,最主要的url请求
Request URL:
https://mail.163.com/js6/read/readhtml.jsp?mid=407:xtbBlxfYQlSIdiX3-wAAsd&userType=ud&font=15&color=4D677D
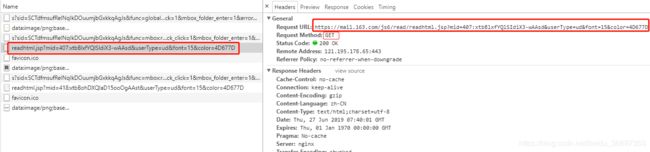
返回的response 是html,其实就是我们的邮件内容。

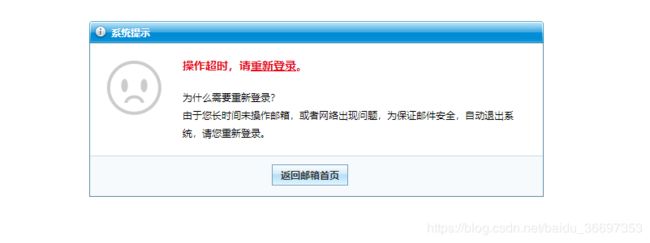
所以说,按道理用之前的cookie和当前的url去发送请求,按道理返回给我们的就是我们想要的html(邮件的内容),但是我按照以上思路,编写代码实现,返现返回的html根本不是我们所想要的, 得到的HTML界面是
代码如下:
import urllib.request
import re
import http.cookiejar
import urllib.parse
import requests
import json
class Mail:
def __init__(self):
#和上面的相同
# 模拟进入指定收件箱,获取mid
def getMid(self):
messages = self.messageList()
pattern = re.compile("'id':(.*?),\n", re.S)
# .*? 表示匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
# 获取mid,mid表示点击进入相关收件邮箱所需要的唯一mid
mails = re.findall(pattern, messages)
mids = []
for mail in mails:
mid = mail.rstrip("'").lstrip("'") # 出去左右单引号
# print("mid:",mid)
mids.append(mid)
return mids
# 获取每一个邮箱里面的具体信息
def getOneInfo(self):
'''
分析了下网页格式,进入到某一个收件箱,需要一个mid
:return:
'''
mids = self.getMid()
print("type(mids[1])", type(mids[1]))
flag = 0
# 以'72:1tbiSB3aQlXlsHtcfQAAsX': 作为测试用例
for mid in mids:
if mid != '72:1tbiSB3aQlXlsHtcfQAAsX':
flag += 1
else:
break
print("flag:", flag)
listUrl1 = "https://mail.163.com/js6/read/readhtml.jsp"
new_list_url = 'https://mail.163.com/js6/s?sid=%s&func=mbox:readMessage&mbox_toolbar_previous=1|1&mbox_mobile_ul_icon_show=2&l=read&action=read' % self.sid
print("listUrl1:", listUrl1)
Headers = {
'Accept': "text/javascript",
'Accept-Language': "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Connection': "keep-alive",
'Host': "mail.163.com",
'Referer': "https://mail.163.com/js6/main.jsp?sid=%s&df=mail163_letter" % self.sid,
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:52.0) Gecko/20100101 Firefox/52.0"
}
post = {
'mid': str(mids[flag]),
'userType': "ud",
'font': "15",
'color': "064977"
}
# 对post编码转换
postData = urllib.parse.urlencode(post).encode('utf8')
try: # 发出post请求
request = urllib.request.Request(listUrl1, postData, Headers)
except urllib.error.HTTPError as e:
print(e.code)
print(e.read().decode("utf-8"))
# 打开请求
# response = urllib.request.urlopen(request)
# 通过全局opener打开 请求 opener 里面有登录保存的cookie
response = self.opener.open(request)
print(self.cookie)
content = response.read().decode("utf8")
# print(content)
# 打印获得的网页代码
自己分析了无法获取正确HTML的原因,也请教了身边python爬虫大神, 得出以下几点原因
0.估计是动态加载的原因,所以无法直接获取。
1.现在遇到的问题就是,获取邮件里面的内容的时候,发送请求 会导致 邮箱过期。所以 拿不到response,我估计是没有用到cookie, 发送请求的是时候导致sid改变了,因为每次登录会参数唯一的sid。之后的操作也是基于这一个sid的基础上进行的, 估计是这个请求导致sid改变了。所以会导致会话过期,返回的response不是我们想要的。
2.还有一个原因就是估计是有多个iframe嵌套的的原因。我们要访信息是在iframe里面,所以直接通过url去访问无法访问到里面的内容。
解决方法
大神们推荐我用selenium去解决。所以用urllib的方法获取邮件的具体内容以失败告终,如果那位大神看到本篇博客之后,能够指导小弟,如何用urllib的方式解决,小弟不胜感激。下面介绍用selenium自动化测试框架来爬取163收件箱的心路历程。
二、selenium的方式
什么是selenium?
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
selenium的中文官方文档网址: https://selenium-python-zh.readthedocs.io/en/latest/locating-elements.html
分析网页结构
分析163登录网络可以知道,登录界面的那个form表单是嵌套在iframe里面的。iframe的id和对应form里面的input的id都是动态生成的,所以用selenium的 find_element_by_id()方法是不能够定位到元素的。
只有用①② 进入到指定iframe然后才能定位成功
iframe = find_element_by_tag_name("iframe") ---------①
driver = switch_to.frame(iframe) ---------②
这里需要注意的是,通过方法①进入iframe框架里面,如果一个html里面有多个iframe,你就需要定位自己需要的iframe是哪一个,我当时数了一下,我们需要的是第一个 应该就是 driver.find_elements_by_tag_name("iframe")[0]
登录流程:
1.由于现在163的登录界面初始化,是通过二维码扫描登录的,所以需要点击密码登录,进入密码登录form。
2.然后通过 find_elements_by_xpath 定位到用户名和密码。
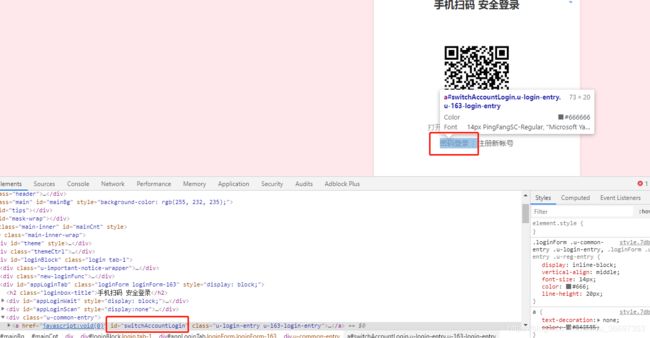
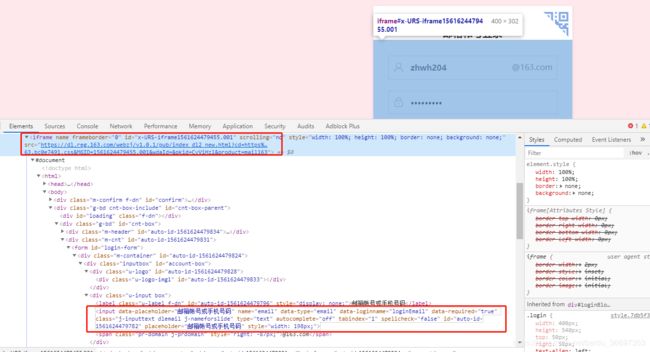
登录代码如下:
import time
from selenium import webdriver
from bs4 import BeautifulSoup
from docx import Document
class seleniumMail:
def __init__(self):
pass
def login(self):
driver = webdriver.Chrome()
driver.get('http://mail.163.com')
time.sleep(3)
# 登录
driver.find_element_by_xpath('//*[@id="switchAccountLogin"]').click()
iframe = driver.find_elements_by_tag_name("iframe")[0]
driver.switch_to.frame(iframe)
driver.find_element_by_name("email").clear()
driver.find_element_by_name("email").send_keys('*****')
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys("*****")
driver.find_element_by_id("dologin").click()
time.sleep(2)
return driver
进入收件箱,通过获取到的收件箱唯一id,来获取不同的邮件内容。
代码如下:
class seleniumMail:
def __init__(self):
pass
'''以下代码实现数据提取'''
def parse_item(maillist):
for m in maillist:
long_text = str(m.attrs['aria-label'])
yield {
'e_title': long_text.split('发件人 :')[0].strip(),
'e_sender': long_text.split('发件人 :')[1].split('时间:')[0].strip(),
'e_send_time': long_text.split('发件人 :')[1].split('时间:')[1].strip(),
}
def login(self):
driver = webdriver.Chrome()
driver.get('http://mail.163.com')
time.sleep(3)
# 登录
driver.find_element_by_xpath('//*[@id="switchAccountLogin"]').click()
iframe = driver.find_elements_by_tag_name("iframe")[0]
driver.switch_to.frame(iframe)
driver.find_element_by_name("email").clear()
driver.find_element_by_name("email").send_keys('****')
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys("*****")
driver.find_element_by_id("dologin").click()
time.sleep(2)
return driver
def getInfo(self, driver):
driver.switch_to.default_content() # 跳出iframe 。一定记住 只要之前跳入iframe,之后就必须跳出。进入主html
driver.find_element_by_xpath('//*[@id="_mail_component_22_22"]').click() # 点击收件箱
time.sleep(5)
html = driver.page_source
cookies = driver.get_cookies()
soup = BeautifulSoup(html, "html.parser")
count = self.process_soup(driver, soup)
total_page = int(driver.find_element_by_class_name('nui-select-text').text.split('/')[1])
print("total-page:", str(total_page))
print(driver.title) # 获取标题
print("success")
time.sleep(300)
def process_soup(self, driver, soup):
mailList = soup.find_all(attrs={"sign": "letter"})
print(mailList)
for m in mailList:
id = str(m.attrs['id'])
long_text = str(m.attrs['aria-label'])
# 标题
title_string = str(long_text.split('发件人 :')[0].strip())+str(long_text.split('发件人 :')[1].split('时间:')[0].strip())+str(long_text.split('发件人 :')[1].split('时间:')[1].strip())
print("title_string:",title_string)
print("id:", id)
print("-" * 30,"process_soup","-" * 30)
self.getOneInfo(driver, id)
def getOneInfo(self, driver, id):
driver.find_element_by_xpath('//*[@id="' + id + '"]').click()
time.sleep(1)
iframe = driver.find_elements_by_tag_name("iframe")[3]
driver.switch_to.frame(iframe)
# parent = driver.find_element_by_xpath('//*[@id="netease_mail_footer_style"]')
driver.find_element_by_xpath('/html/body')
html = driver.page_source
print(html)
print("------"*100)
print(self.processOneInfo(html))
time.sleep(2)
driver.switch_to.default_content()
time.sleep(2)
driver.find_element_by_tag_name('div div span').click()
time.sleep(2)
def processOneInfo(self, html):
p_string = ""
print("*"*300)
soup = BeautifulSoup(html, "html.parser")
mailList = soup.find_all("div")
for m in mailList:
print(m.string)
p_string += str(m.string)+"\n"
self.writeIntoWord(p_string)
return "write to word success"
def writeIntoWord(self,p_string):
document = Document('E:\\python_file\\web_spider\\demo.docx')
if p_string != None:
document.add_paragraph(p_string)
document.add_paragraph("\n")
document.save('E:\\python_file\\web_spider\\demo.docx')
参考文档:
python-docx中文文档: https://python-docx.readthedocs.io/en/latest/index.html#user-guide
BeautifulSoup文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#id13
Selenium文档:https://selenium-python-zh.readthedocs.io/en/latest/locating-elements.html
后期bug:
1.解决分页获取问题
2.driver没有更新问题(写入的都是收件箱列表第一个邮箱的内容)