Linux下cut命令用法详解
Linux下cut命令用法详解
原创:frozen_sucker(冰棍)
有时我们经常会遇到这样一些问题:有一页电话号码薄,上面按顺序规则地写着人名、家庭住址、电话、备注等,此时我们只想取出所有人的名字和其对应的电话号码,你有几种方法可以实现呢?
以下内容欢迎转载,但请保留作者名号及出处,谢谢!
原创:frozen_sucker
链接:http://blog.csdn.net/Frozen_fish/archive/2008/04/08/2260804.aspx
确实这种纵向定位的方式用常规办法难以实现,这时,cut就可以大显身手了。
What’s cut?
子曰:cut命令可以从一个文本文件或者文本流中提取文本列。
命令用法:
cut -b list [-n] [file ...]
cut -c list [file ...]
cut -f list [-d delim][-s][file ...]
l 上面的-b、-c、-f分别表示字节、字符、字段(即byte、character、field);
l list表示-b、-c、-f操作范围,-n常常表示具体数字;
l file表示的自然是要操作的文本文件的名称;
l delim(英文全写:delimiter)表示分隔符,默认情况下为TAB;
l -s表示不包括那些不含分隔符的行(这样有利于去掉注释和标题)
上面三种方式中,表示从指定的范围中提取字节(-b)、或字符(-c)、或字段(-f)。
范围的表示方法:
N |
只有第N项 |
N- |
从第N项一直到行尾 |
N-M |
从第N项到第M项(包括M) |
-M |
从一行的开始到第M项(包括M) |
- |
从一行的开始到结束的所有项 |
下面是实例,先以较简单的“命令用法”中提及的第二条开始讲起:

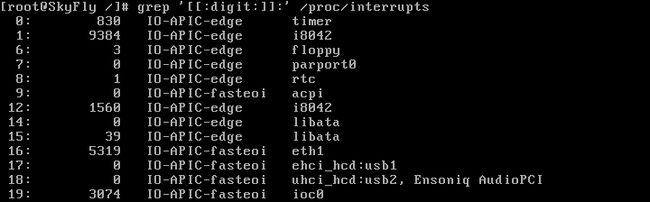
interrupts文件中的字符排列非常齐整,正适合我们切豆腐。
但这里我们只对两个数字列感兴趣,用法如下:

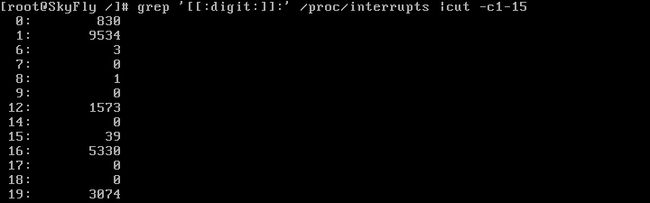
里面还有一些不需要的内容,精减一下:
关于正则表达式的使用,请自行查阅相关资料。
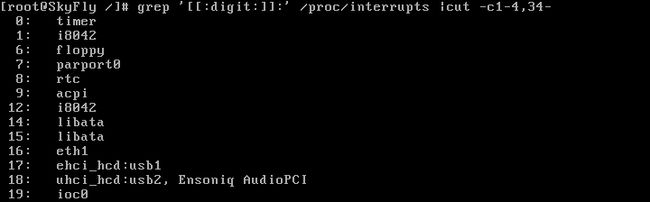
合到一起:
哇,果然够帅!!
不相邻列的截选又应该如何做呢?
这种方式需要事先确定占多少个字符位置,不仅麻烦,而且容易出错。
下面的问题该怎么去做?
这就是第二讲:使用cut –f提取文本中的字段。
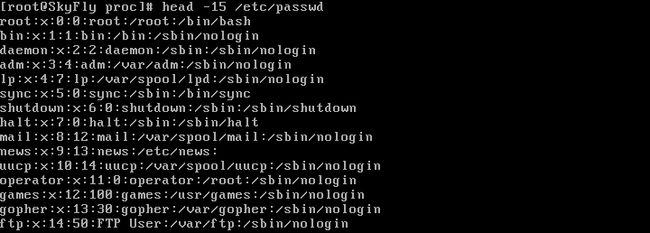
cut –c主要是用来在固定字符位置或个数的文本文件中提取,对于上面的例子就显得无能为力了。仔细观察,发现passwd文件有个规律,就是以冒号来区分不同的段的文本,于是。。。
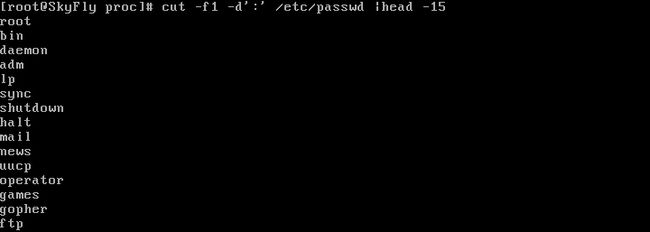
怎么样,好玩吧~!
继续,创建一个文本文件,名为a.txt,名字有点土,凑合着用吧。

A1、B1、C1所代表的行字符之间均以TAB分隔,D1却是以空格来分开的。

看到-s的作用了吗?(因为第一行不含有任何TAB字符,所以直接被剔除了),而最后一行(即D1行),是以空格区分间距,所以也不合要求。

多了个参数,这个我没讲,只要你的智商比范伟高一点点,就肯定能猜出来啦。^_^
好了,下面是最后一个用法的讲解了:

因为虚拟终端下无法显示汉字,所以我只好回到图形下,截图就成这个白不垃圾的样子啦,忍忍吧,就快讲完了。
在这个文件中,每个汉字都是用半角空格分隔的。

用cut –c已经成功了,下面试试cut –b怎么样?

没有反应,why?
原因在于汉字本身是双字节的,cut –c把汉字“我”当成一个字符来处理,而cut –b是以字节来处理,把“我”拆成了两个字节,结果是字符被“切成两半”,因此无法正常显示。
原因找到了,要怎么办才好呢?

耶!!!搞定。
OK,all is done。就到这里吧,休息,休息。。。
原链接:http://blog.csdn.net/Frozen_fish/article/details/2260804