【Lucene&Solr】Solr实现全文检索
一、Solr是什么
Solr 是Apache下的一个顶级开源项目,采用Java开发,可以独立运行在Jetty、Tomcat等这些Servlet容器中,它是基于Lucene的全文搜索服务器。Lucene与Solr的区别如下:
- Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,但提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
- Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能
二、Solr的下载使用
官方下载地址:http://lucene.apache.org/
下载解压后如下:
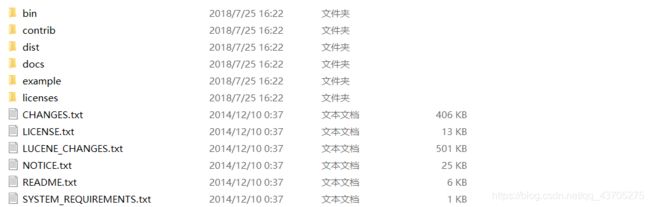
- bin:solr的运行脚本
- contrib:solr的一些贡献软件/插件,用于增强solr的功能。
- dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
- docs:solr的API文档
- example:solr工程的例子目录:
- example/solr:该目录是一个包含了默认配置信息的Solr的Core目录。
- example/multicore:该目录包含了在Solr的multicore中设置的多个Core目录。
- example/webapps:该目录中包括一个solr.war可作为solr的运行实例工程。
- licenses:solr相关的一些许可信息。
发布使用:
1、把solr项目拷贝到tomcat的项目目录:把\solr-4.10.3\dist\solr-4.10.3.war复制到apache-tomcat-xxx\webapps下。改名为solr.war,解压到当前文件夹并删除solr.war;
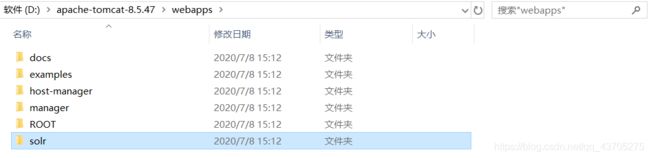
2、引入jar包:把\solr-4.10.3\example\lib\ext目录下的所有的jar包添加到solr工程中

3、配置solrHome:把\solr-4.10.3\example\solr文件夹复制到D:\solrHome路径下。collection1就是一个solrcore,一个solrcore相当于mysql中一个数据库。
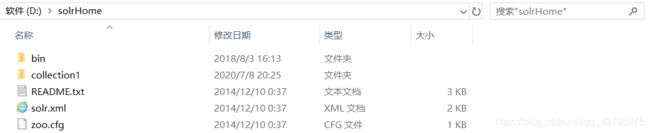
4、将solrHome的路径告诉Solr:配置solr项目的web.xml文件

5、重新启动tomcat,访问solr http://localhost:8080/solr即可使用Solr。
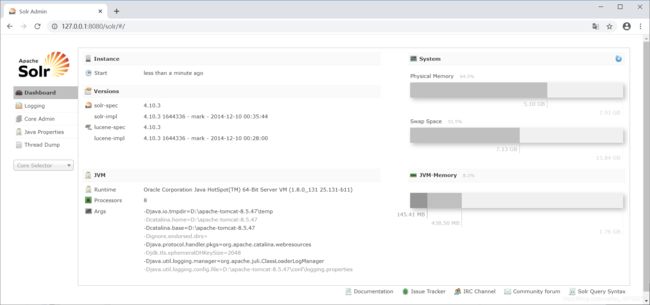
三、Solr界面说明
Dashboard:显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息;
Logging:Solr运行日志信息;
Core Admin:SolrCore的管理界面。Solr Core 是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个collection;
java properties:Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息;
Tread Dump:显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息;
Core selector:SolrCore选择器,默认为一个,若将D:\solrHome\collection1拷贝一分为D:\solrHome\collection2,则就有两个SolrCore了。选择一个SolrCore后会有如下选项(只列举几个):
- OverView:SolrCore信息概览;
- Analysis:通过此界面可以测试索引分析器和搜索分析器的执行情况;
- Dataimport:可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中;
- Document:通过此菜单可以创建索引、更新索引、删除索引等操作;
- Query:通过此菜单可以进行索引查询。
四、使用SolrJ管理索引库
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务:
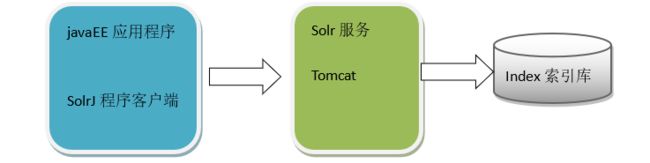
本例使用eclipse、jdk1.7、solr-4.10.3
1、创建Java工程,拷贝jar包
solrJ核心包solr-4.10.3\dist\solr-solrj-4.10.3.jar、
solrJ扩展包solr-4.10.3\dist\solrj-lib下的所有jar
solr的扩展包solr-4.10.3\example\lib\ext下的所有jar

2、代码实现索引库的增删改查
package cn.jpc.solr;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import org.junit.Test;
public class SolrTest1 {
//增加文档
@Test
public void addDocument() throws Exception {
// 指定solr服务器
SolrServer solrServer = new HttpSolrServer("http://127.0.0.1:8080/solr/collection1");
// 创建文档对象
SolrInputDocument document = new SolrInputDocument();
// 像文档中添加域名和域值
document.addField("id", "a001");
document.addField("title", "使用solrJ添加的文档");
document.addField("content", "文档的内容");
document.addField("name", "商品名称");
// 把document对象添加进索引库中
solrServer.add(document);
// 提交
solrServer.commit();
}
// 删除文档,根据id删除
@Test
public void deleteDocumentByid() throws Exception {
// 创建连接
SolrServer solrServer = new HttpSolrServer("http://127.0.0.1:8080/solr/collection1");
// 根据id删除文档
solrServer.deleteById("a001");
// 提交修改
solrServer.commit();
}
// 根据查询条件删除文档
@Test
public void deleteDocumentByQuery() throws Exception {
// 创建连接
SolrServer solrServer = new HttpSolrServer("http://127.0.0.1:8080/solr/collection1");
// 根据查询条件删除文档
solrServer.deleteByQuery("*:*");
// 提交修改
solrServer.commit();
}
//修改索引:先按照id删除文档,再创建一个与被删除文档id相同的文档即可
// 查询索引
@Test
public void queryIndex() throws Exception {
// 创建连接
SolrServer solrServer = new HttpSolrServer("http://127.0.0.1:8080/solr/collection1");
// 创建一个query对象
SolrQuery query = new SolrQuery();
// 设置查询条件
query.setQuery("*:*");
// 执行查询
QueryResponse queryResponse = solrServer.query(query);
// 取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
// 共查询到商品数量
System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());
// 遍历查询的结果
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
System.out.println(solrDocument.get("name"));
System.out.println(solrDocument.get("content"));
System.out.println(solrDocument.get("title"));
}
}
}
3、数据表配置文件Schema.xml介绍
schema.xml在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
FieldType域类型定义:
- name:是这个FieldType的名称
- class:是Solr提供的包solr.TextField,solr.TextField 允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
- positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
Field定义:
- 在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
uniqueKey:
- Solr中默认定义唯一主键key为id域,如下图所示,Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键,注意在创建索引时必须指定唯一约束。
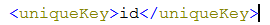
copyField复制域: - copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索。比如,输入关键字搜索title标题和content内容,则自定义title、content、text的域和copyField:

<copyField source="title" dest="text"/> <copyField source="content" dest="text"/> - 如此一来,查询“text:java”时就相当于在title域和content域中查询带有Java的文档。
dynamicField动态字段:
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
4、在Schema.xml中配置中文分词器
- 首先要把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下;
- 其次复制IKAnalyzer的配置文件和自定义词典和停用词词典到solr的classpath下;
- 然后在schema.xml中配置:
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> fieldType> <field name="title_ik" type="text_ik" indexed="true" stored="true" /> <field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/> - 最后重启tomcat。
五、为数据库某个表创建索引
1、导入dataimport插件的jar包与数据库驱动包

2、配置solrconfig.mxl文件,添加一个requestHandler
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xmlstr>
lst>
requestHandler>
3、配置data-config.xml文件
在collection1\conf\目录下创建一个文件data-config.xml,内容如下:
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/lucene"
user="root"
password="1234"/>
<document>
<entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products ">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
entity>
document>
dataConfig>
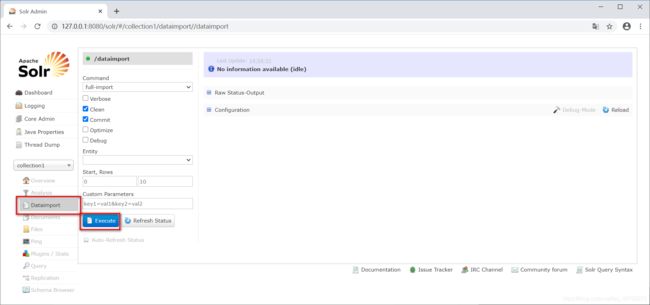
4、重启tomcat后,在Solr页面DataImport选项卡中点击“Execute”
六、Solr页面查询
1、q:查询字符串,例:filename:java,如果查询所有使用*:*。
2、fq:(filter query)过虑查询,作用:在q查询符合结果中同时是fq查询符合的。
3、sort:排序,例:price desc。
4、start:分页,指定从哪条记录开始。
5、rows:分页,指定每页显示几条数据。
6、fl:(filed list)指定返回哪些域的内容,用逗号或空格分隔多个。
7、df:(default filed)指定默认从哪个域中查询。
8、wt:(writer type)指定输出格式,可以有 xml, json, php, phps等。
9、hl:(highlight)是否高亮 ,设置高亮Field,设置格式前缀和后缀,例:

七、Java代码查询
package cn.jpc.solr;
import java.util.List;
import java.util.Map;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrQuery.ORDER;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
public class SolrTest2 {
public static void main(String[] args) throws Exception {
// 创建连接
SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr");
// 创建一个query对象
SolrQuery query = new SolrQuery();
// 设置查询条件
query.setQuery("花儿朵朵");
// 过滤条件
query.setFilterQueries("product_price:[0 TO 20]");
// 排序条件
query.setSort("product_price", ORDER.asc);
// 分页处理
query.setStart(0);
query.setRows(10);
// 结果中域的列表
query.setFields("id", "product_name", "product_price", "product_catalog_name", "product_picture");
// 设置默认搜索域
query.set("df", "product_keywords");
// 高亮显示
query.setHighlight(true);
// 高亮显示的域
query.addHighlightField("product_name");
// 高亮显示的前缀
query.setHighlightSimplePre("");
// 高亮显示的后缀
query.setHighlightSimplePost("");
// 执行查询
QueryResponse queryResponse = solrServer.query(query);
// 获取查询结果
SolrDocumentList solrDocumentList = queryResponse.getResults();
// 共查询到商品数量
System.out.println("共查询到商品数量:" + solrDocumentList.getNumFound());
// 遍历查询的结果
for (SolrDocument solrDocument : solrDocumentList) {
System.out.println(solrDocument.get("id"));
// 取高亮显示
String productName = "";
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
List<String> list = highlighting.get(solrDocument.get("id")).get("product_name");
// 判断是否有高亮内容
if (null != list) {
productName = list.get(0);
} else {
productName = (String) solrDocument.get("product_name");
}
System.out.println(productName);
System.out.println(solrDocument.get("product_price"));
System.out.println(solrDocument.get("product_catalog_name"));
System.out.println(solrDocument.get("product_picture"));
System.out.println("%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%");
}
}
}