【Lucene&Solr】Lucene实现全文检索
一、全文检索
- 对于结构化数据如MySQL表中的数据可以用SQL语句来查询,而对于非结构化数据如磁盘上的文件、网站的资源等就需要用到顺序扫描法或全文检索法。
- 但是顺序扫描法效率非常低,此时就需要全文检索法。
- 全文检索法是将非结构化数据中的一部分信息提取出来进行组织使其变得有结构,提取的这部分信息称其为索引,根据索引快速定位到要查找的信息。
- 字典的拼音表和部首检字表就相当于字典的索引。
- 实现全文检索可以使用Lucene技术。Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,其流程如下:
- 创建索引:①获得文档(磁盘文件、网站资源等);②构建文档对象(Document,包括许多域Field,如file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容等);③分析文档(分词);④创建索引(将索引创建后添加进索引库)
- 索引搜索:创建查询–执行查询–渲染结果
- 创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
- 根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引所链接的文档。比如搜索语法为“fileName:lucene”表示搜索出fileName域中包含Lucene的文档。
二、Lucene下载配置
官方网站:http://lucene.apache.org/
此处使用Eclipse、jdk1.7和Lucene4.10.3
创建一个java工程,并导入jar包:
- 核心包:lucene-core-4.10.3.jar
- 查询内容分词:lucene-queryparser-4.10.3.jar
- IO包:commons-io-2.4.jar
- 通用分词器:lucene-analyzers-common-4.10.3.jar ,但是通用的分词器对于中文的不太友好,在许多分词器中IK-analyzer是相对较好的一个,并且可以自己配置扩展词典与停用词典。因此我们导入IK-analyzer的jar包:IKAnalyzer2012FF_u1.jar。将其需要三个配置文件添加到名为“config”的sourceFolder中,如下:
- IKAnalyzer.cfg.xml:该文件会被加载,用于指明用户配置的扩展词典与停用词典
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">ext.dic;entry>
<entry key="ext_stopwords">stopword.dic;entry>
properties>
- ext.dic:扩展词典,原本不会被分为一个词的下列词汇现在会被分为一个词
路人甲
炮灰乙
加利敦大学
...
- stopword.dic:停用词典,没有索引价值的字词
的
了
是
额
a
an
and
are
as
at
be
本例演示将某磁盘路径的所有文件创建索引存储到指定位置,查询指定文档时不再从原路径下逐个查找,而是利用索引库查询从而快速定位指定文档。
三、Java代码创建索引
package cn.jpc;
import java.io.File;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class IndexWriterTest {
public static void main(String[] args) throws Exception {
// 指定索引库存放的路径
Directory directory = FSDirectory.open(new File("F:\\pandownlaod\\index"));
// 索引库还可以存放到内存中
// Directory directory = new RAMDirectory();
// 创建一个IKAnalyzer分析器
Analyzer analyzer = new IKAnalyzer();
// 创建IndexWriterConfig对象
// 第一个参数: Lucene的版本信息,可以选择对应的lucene版本也可以使用LATEST
// 第二根参数:分析器对象
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
// 创建IndexWriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 原始文档的路径
File dir = new File("F:\\pandownlaod\\需要创建索引的资料");
for (File f : dir.listFiles()) {
// 文件名
String fileName = f.getName();
// 文件内容
String fileContent = FileUtils.readFileToString(f);
// 文件路径
String filePath = f.getPath();
// 文件的大小
long fileSize = FileUtils.sizeOf(f);
// 创建文件名域
// 第一个参数:域的名称
// 第二个参数:域的内容
// 第三个参数:是否存储
Field fileNameField = new TextField("filename", fileName, Store.YES);
// 文件内容域
Field fileContentField = new TextField("content", fileContent, Store.YES);
// 文件路径域(不分析、不索引、只存储)
Field filePathField = new StoredField("path", filePath);
// 文件大小域
Field fileSizeField = new LongField("size", fileSize, Store.YES);
// 创建document对象
Document document = new Document();
document.add(fileNameField);
document.add(fileContentField);
document.add(filePathField);
document.add(fileSizeField);
// 创建索引,并写入索引库
indexWriter.addDocument(document);
}
// 关闭indexwriter
indexWriter.close();
}
}
运行该程序,即可在指定的索引存储位置生成索引。
四、Java代码添加索引
package cn.jpc;
import java.io.File;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class AddIndex {
public static void main(String[] args) throws Exception {
// 索引库存放路径
Directory directory = FSDirectory.open(new File("F:\\pandownlaod\\index"));
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建一个indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 创建一个Document对象
Document document = new Document();
// 向document对象中添加域。
// 不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "新添加的文档", Store.YES));
document.add(new TextField("content", "新添加的文档的内容", Store.NO));
document.add(new TextField("content", "新添加的文档的内容第二个content", Store.YES));
document.add(new TextField("content1", "新添加的文档的内容要能看到", Store.YES));
// 添加文档到索引库
indexWriter.addDocument(document);
// 关闭indexwriter
indexWriter.close();
}
}
五、Java代码查询索引
package cn.jpc;
import java.io.File;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class IndexReaderTest {
public static void main(String[] args) throws Exception {
// 指定索引库存放的路径
Directory directory = FSDirectory.open(new File("F:\\pandownlaod\\index"));
// 创建indexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
// 创建indexsearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 1、TermQuery查询:指定要查询的域和要查询的关键词
// Query query = new TermQuery(new Term("filename", "spring"));
// 2、MatchAllDocsQuery查询:查询索引目录中的所有文档
// Query query = new MatchAllDocsQuery();
// 3、NumericRangeQuery查询:可以根据数值范围查询
// Query query = NumericRangeQuery.newLongRange("size", 100l, 1000l, true, false);
// 4、BooleanQuery查询:可以组合查询条件
// BooleanQuery query = new BooleanQuery();
// Query query1 = new TermQuery(new Term("filename", "spring"));
// Query query2 = new TermQuery(new Term("content", "apache"));
// query.add(query1, Occur.MUST);
// query.add(query2, Occur.MUST);
// 5、queryparser查询:根据一句话查找,对该句话分词
// QueryParser queryParser = new QueryParser("content",new IKAnalyzer());
// Query query = queryParser.parse("Lucene是java开发的");
// 可以指定默认搜索的域是多个
String[] fields = { "filename", "content" };
// 创建一个MulitFiledQueryParser对象
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());
Query query = queryParser.parse("java和apache");
// 执行查询
System.out.println(query);
// 第一个参数是查询对象,第二个参数是查询结果返回的最大值
TopDocs topDocs = indexSearcher.search(query, 10);
// 查询结果的总条数
System.out.println("查询结果的总条数:" + topDocs.totalHits);
// 遍历查询结果
// topDocs.scoreDocs存储了document对象的id
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
// scoreDoc.doc属性就是document对象的id
// 根据document的id找到document对象
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("filename"));
// System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
}
// 关闭indexreader对象
indexReader.close();
}
}
六、Java代码修改索引
package cn.jpc;
import java.io.File;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class UpdateIndex {
public static void main(String[] args) throws Exception {
Directory directory = FSDirectory.open(new File("F:\\pandownlaod\\index"));
// Directory directory = new RAMDirectory();//保存索引到内存中 (内存索引库)
// Analyzer analyzer = new StandardAnalyzer();// 官方推荐
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 创建一个Document对象
Document document = new Document();
// 向document对象中添加域。
// 不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "需要更新的文档.txt", Store.YES));
document.add(new TextField("content",
"2013年11月18日 - Lucene 简介 Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。", Store.YES));
//将content域中有apache的所有文档替换成document
indexWriter.updateDocument(new Term("content", "apache"), document);
// 关闭indexWriter
indexWriter.close();
}
}
七、Java代码删除索引
package cn.jpc;
import java.io.File;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class DeleteIndex {
// 删除索引
public static void main(String[] args) throws Exception {
Directory directory = FSDirectory.open(new File("F:\\pandownlaod\\index"));
// Directory directory = new RAMDirectory();//保存索引到内存中 (内存索引库)
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 创建一个查询条件
Query query = new TermQuery(new Term("filename", "spring"));
// 1、根据查询条件删除
// indexWriter.deleteDocuments(query);
//2、删除全部
indexWriter.deleteAll();
// 关闭indexwriter
indexWriter.close();
}
}
八、Field域的属性
| Field类 | 数据类型 | Analyzed是否分析 | Indexed是否索引 | Stored是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等)。是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) | Long型 | Y | Y | Y或N | 这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格)是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field。不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
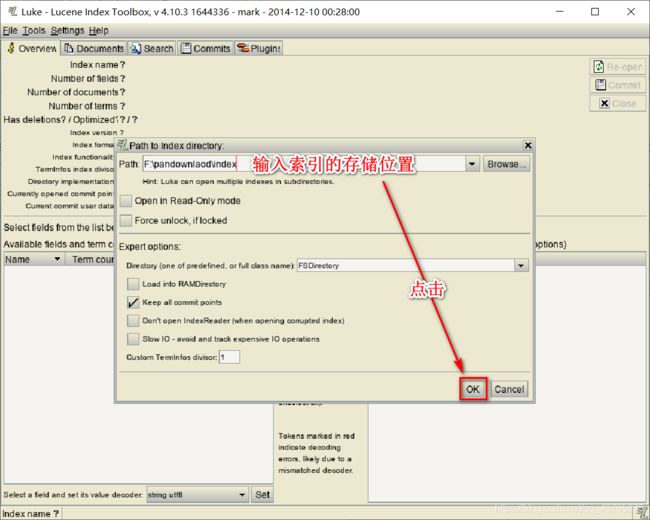
九、使用Luke工具查看索引
直接双击打开:lukeall-4.10.3.jar
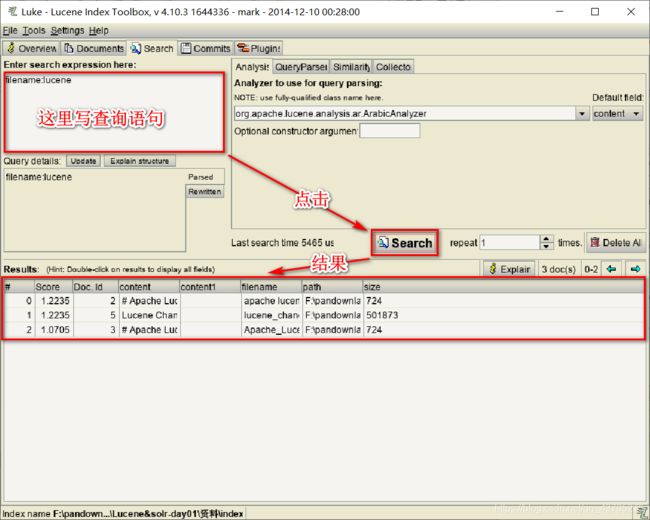
查询语句是有语法的:
1、基础的查询语法,关键词查询:
域名+“:”+搜索的关键字
- 例如:content:java
2、范围查询
域名+“:”+[最小值 TO 最大值]
- 例如:size:[1 TO 1000]
范围查询在lucene中不支持数值类型,支持字符串类型。在solr中支持数值类型。
3、组合条件查询
1)+条件1 +条件2:两个条件之间是并且的关系and
- 例如:+filename:apache +content:apache
2)+条件1 条件2:必须满足第一个条件,应该满足第二个条件
- 例如:+filename:apache content:apache
3)条件1 条件2:两个条件满足其一即可。
- 例如:filename:apache content:apache
4)-条件1 条件2:必须不满足条件1,要满足条件2
- 例如:-filename:apache content:apache
十、相关度打分—竞价排名
Lucene索引查询结果默认按照相关度排序,相关度排序是查询结果按照与查询关键字的相关性进行排序,越相关的越靠前。比如搜索“Lucene”关键字,与该关键字最相关的文章应该排在前边。
在索引时对某个文档的Field域设置加权值高,在搜索时匹配到这个Field就可能排在前边。lucene在执行搜索时对某个域进行加权,在进行组合域查询时,匹配到加权值高的域最后计算的相关度得分就高。
在Java代码中操作也很简单,只在将field添加进document之前调用setBoost()方法设置权重即可,例:field. setBoost(100f);