Selenium进阶教程(新版)
多练习&一步一个脚印
- Testerhome 一套登陆行为
- 串联api和语法行为 断言,基础api,写入文件断言的必要和非必要条件用util/log.py
- ps:当然实际代码要抽象->业务块代码精简
- 练习一 get(url) 套入log.py
断言相等性 driver.title 测试场景断言相等性 driver.current_url
<非必要条件>判断网页源码 尺寸大小 不高于60kb 如果不满足写入文件 /test/size.txt
判断前往登录元素是否可以点击断言相等性 登录元素文本正确
有标签,该元素有文本
- 练习二 登录field并且登录
断言相等性 driver.title 测试场景
back()回退上个页面 断言相等性 driver.title 测试场景forward()上个页面前进 到达当前页面 断言不相等性NotEqual driver.title 测试场景
定位id 数据驱动输入ini文件里的内容账号,密码,勾选状态60天get_attribute拿到input单元格输出的内容判断尺寸
断言返回数据类型 勾选框.size
断言不相等性 driver.current_url 测试场景 get_cookies 然后提取关键的name和value
- 练习三 判断登录后并且退出
登录后断言 通过提示信息new元素来 判断测试场景一步步拿到推出按钮
登录后退出
断言包含In topics 比较稳当的写法

单元测试框架(反推)
TextTextRunner() 入参 函数内调用其它参数 进行反推
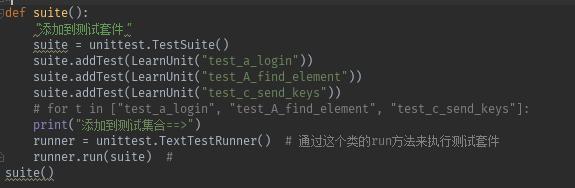
字符串列表,遍历
测试条件->测试集合->执行测试集合
def main():
unittest.main()
if __name__ == '__main__':
main()
执行部分测试用例
if __name__ == '__main__':
def suite():
"添加到测试套件"
suite = unittest.TestSuite()
suite.addTest(LoginDouban("test_login"))
suite.addTest(LoginDouban("test_login2"))
print ("添加到测试集合=====>")
runner = unittest.TextTestRunner()
runner.run(suite)
suite()
单元测试 跳过
@unittest.skip(“跳过的原因”)
@unittest.skipif(“条件”,”跳过的原因”) 条件True跳过
@unittest.skipUnless(“条件”,”跳过的原因”) 条件False跳过
设计模式
本次课程使用到的设计模式
- 简化设计范围,高复用,合理权责划分
- 包之间的传递顺序
- 不同模块(包)全局变量 类成员变量 类成员方法 构造函数
- 公共import库
项目工具类展开
project名
util(工具类模块)
init.py <--提升文件夹到模块
ClientSelenium.py (selenium工具类)
Base.py(工具的基础类)
ParserConfig.py (数据驱动读取INI配置的类)
Err.py (异常类延伸)
ReadOpenData.py(数据驱动读取excel)
Func_mail.py
log.py
传递继承:先有工具类
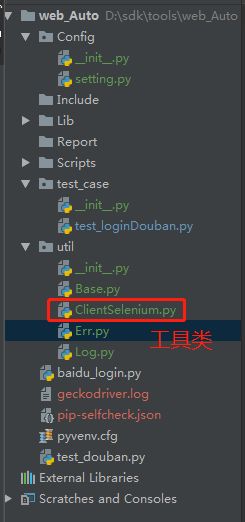
跟webdriver API 高级封装相关信息,让API更稳定
Base中内容与webdriver无关内容: Base继承超类
from util.ParserConfig import ParserConfig
pc =ParserConfig("D:\selenium_uses\Conf\config.ini") #读取对应配置
class Base(object): #拉起时使用
def chrome_path(self):
"谷歌的浏览器驱动"
#读取驱动
return pc.get_option_value("Driver", "chrome") #把driver目录拷贝到一级目录下。
def firefox_path(self):
"火狐的浏览器驱动"
return pc.get_option_value("Driver", "firefox")
from Conf.setting import * #导入Conf.setting 全部内容
BaseDir ="D:\\sdk\\tools\\web_Auto\\Report" #从setting 文件导入拼接
class TimeUtil(object):
def set_date(self): #固定写法
now = datetime.datetime.now() #内置库,通过Conf.setting导入
return "{0}-{1}-{2}".format(now.year, now.month, now.day)
def set_time(self):#固定写法
return time.strftime("%H-%M")
def get_report_path(self): #核心函数,报告的拼接
"格式月日/单位时间格式的.html,只用到time"
nowtime = time.localtime() #转换为可读的
dir_date = time.strftime('-%Y%m%d', nowtime) #格式化 Report-年月日
if not os.path.exists(BaseDir + dir_date): #="E:\selenium_uses\\Report-年月日" 文件夹
os.mkdir(BaseDir + dir_date)
#print("路径===》",BaseDir + dir_date)
day_file = time.strftime('%H%M%S', nowtime)
return BaseDir + dir_date + '\\' + 'Report-' + day_file + '.html'Log.py
_logger = logger('WebTest') #复写
PageObject模式
工具类 ---> #页面区域 ----> TestCase #页面变动,导致testCase不可用
工具类 ---> TestCase ---> 以页面为单位 只做一个页面的事情每个文件夹的功能独立
48:00
数据驱动
- 模块后缀导入 .py 回顾如何导入
- PATH os路径技巧和拼接+功能文件夹/drivers/
- * ini 历史悠久的配置 section和所有option 8.18号
- *excel openpyxl
Json,Xml,Yaml -让电脑可以读的数据序列化
49:00
excel openpyxl
ReadOpenData.py
from openpyxl import load_workbook
#实例化后读取ReadOpenData即可
class ReadOpenData:
#不需要传参和入参
"""
读取excel表结构
"""
def __init__(self):
"Constructor of the object"
# 读取文件的绝对路径,将文件转换为构造函数的成员变量
self.workbook = load_workbook(r"D:\trx\selenium_uses\test_data\data.xlsx")
def get_sheet(self):
"读取sheet部分"
return self.workbook.sheetnames[0] #对应sheet列表;可value对应sheet名称,value("sheet1")
def get_cell_dire(self,row,col): #从A0开始,看不到;从1开始
"""
通过坐标直接读取单元格
:param row: int
:param col: int
:return: 对应row & col 的 cell
"""
row+=1
col+=1
return self.workbook.active.cell(row, col).value
def get_rows(self,row): #以读行的形式进行,此函数包装在 get_cell_by_row()函数中
"""
读取某一行数据
:param row: int
:return:包含这一行数据的list class:openpyxl.cell
"""
values = []
cells = list(self.workbook.active.iter_rows())[row]
for cell in cells:
values.append(cell.value)
return values #[v1,v2,v3]
def get_cell_by_row(self,row,col): #拿行后读列
"""
按行读取单元格
:param row: int
:param col: int
:return: str, 对应row & col 数据 class:openpyxl.cell
"""
return self.get_rows(row)[col]
52:00
WebDriver API组合
WebDriver API
- 思考文件夹和模块如何设计?如何利于扩展
- 下面讲述:webDriver 定位方式和API封装
- webDriver 对于网页基础操作加强封装(见下图)
ClientSelenium.py
# -*- coding: utf-8 -*-
'a practice of ...'
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC # 显示等待
from selenium.webdriver.support.ui import WebDriverWait # 显示等待
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys #键盘类
import time
from util.Base import Base
base = Base()
# 定位器字典 把value打包
locatorTypeDict = {
'xpath': By.XPATH,
'css': By.CSS_SELECTOR,
'id': By.ID,
'name': By.NAME,
'className': By.CLASS_NAME,
'tagName': By.TAG_NAME,
'link': By.LINK_TEXT,
'parLink': By.PARTIAL_LINK_TEXT
}
from selenium import webdriver
# 只开放了基础api的,定位器请自己学习封装完成作业,下节课在讲带保护的高级封装
class ClientSelenium(object):
"""通过封装把Page的行为压缩在这里"""
#执行超类,但不构造函数,只有拉起用到,但与初始内容冲突
def get_driver(self, driver, url):
#driver:如何驱动
"初始化浏览器和打开目标url"
if driver == 'firefox' or driver == 'Firefox' or driver == 'F' or driver == 'f':
# exe_path = base.firefox_path()#第二个功能是包裹在第一个功能下面的
self.driver = webdriver.Firefox()
elif driver == 'Chrome' or driver == 'chrome' or driver == 'Ch' or driver == 'ch':
# exe_path = base.chrome_path()
self.driver = webdriver.Chrome()
print("拉起浏览器成功")
else:
print("输入在预期以外")
self.driver.get(url) # 区域3
return self.driver
def start(self, url, _url):
"""
不拉起浏览器打开网页
:param url: 打开网页
:param _url: 期望网页
:return:
"""
self.driver.get(url)
self._get_current_url(_url) #直接打开url,判断在url页面再去执行页面上的操作
def assert_title(self, titleText):
"""
页面标题上是否包含关键字,支持传入多个参数
:param titleStr: 关键字
:param args: 支持传入多个参数
:return:布尔
"""
try:
assert titleText in self.driver.title, \
"在title里没有找到%s" % titleText
print("加载网页正确") # 业务self.assertTrue()
return True
except Exception as error:
print(format(error))
return False
def assert_source(self, sources):
"""
网页源码是否包含关键字 做业务判断
:param sources: list [arg1,arg2...]
:return:
"""
for source in sources: # 关键字驱动有可能包含多个参数
try:
assert source in self.driver.page_source, \
"在page_source里没有找到%s" % source
print("判断 %s 包含在page_source" % source)
except AssertionError as error: # 断言表达式
print(format(error))
except Exception as error:
print(format(error))
time_wait = 2
def time_sleep(self, time_wait):
"""
强制等待默认为2秒
:param time_wait:
:return:
"""
if time_wait <= 0:
time.sleep(time_wait)
else:
print("等待%ss" % time_wait)
time.sleep(time_wait)
def max_size(self):
"""
放大浏览器最大化 需要先拉起浏览器
:return:
"""
time.sleep(0.5) # 切换展示
self.driver.maximize_window()
def set_size(self, width=800, height=600):
"""
先打印浏览器尺寸,设置浏览器到尺寸
:param width: 宽
:param height: 高
:return:
"""
self.driver.set_window_size(width, height, windowHandle="current") # 当前句柄
print("尺寸设置成功")
def _get_current_url(self, _url):
try:
assert _url == self.driver.current_url #不是继承的超类,只进行基础断言
except Exception as error:
print(format(error))
def F5(self, _url):
"""
刷新后验证网页正确 now_url覆写使用
:return:
"""
self.driver.refresh()
print("刷新正确")
self._get_current_url(_url) # 刷新后判断当前网页
def back(self, _url, time_wait=4):
"""
后退到之前的页面(等同浏览器上按回退按钮)
条件:先需要有前后打开的2个页面
:param _url:形参是验证当前页面
:param time_wait:属于time_sleep方法
:return:
"""
self.time_sleep(time_wait)
self.driver.back()
self._get_current_url(_url)
print("back网页成功")
def forward(self, _url, time_wait=4):
"""
配合浏览器回退使用,回到之前的页面
:param _url:形参是验证当前页面
:param time_wait:属于time_sleep方法
:return:
"""
self.time_sleep(time_wait)
self.driver.forward()
self._get_current_url(_url)
print("forward网页成功")
def quit(self):
"""关闭浏览器
:return:
"""
self.time_sleep(self.time_wait) # 展示最后一条case
self.driver.quit()
# print("关闭浏览器",self.driver.current_window_handle)
def get_element(self, locator):
'''
非显式等待
driver.get_element("css=>#el")
'''
if "=>" not in locator:
raise NameError("Positioning syntax errors, lack of '=>'.")
by = locator.split("=>")[0]
value = locator.split("=>")[1]
if by == "id":
element = self.driver.find_element_by_id(value)
elif by == "name":
element = self.driver.find_element_by_name(value)
elif by == "class":
element = self.driver.find_element_by_class_name(value)
elif by == "link_text":
element = self.driver.find_element_by_link_text(value)
elif by == "xpath":
element = self.driver.find_element_by_xpath(value)
elif by == "css":
element = self.driver.find_element_by_css_selector(value)
elif by == "tag_name":
element = self.driver.find_element_by_tag_name(value)
else:
raise NameError(
"不在选择范围内,'id','name','class','link_text','xpath','css','tag'.")
return element
def get_element_wait(self, locator, timeout=12, poll=0.5):
'''
单个元素的显式等待,接收参数更少(可以不直接使用)
driver.element_wait("css=>#el", 10)
:param xpath:
:param poll:不填写则默认0.5秒
:param timeout:默认12秒
'''
if "=>" not in locator:
raise NameError("Positioning syntax errors")
# #main > div.row > div.sidebar.col-md-3 > div:nth-child(1) > div > a
# by=>value
#
by = locator.split("=>")[0] #以==>分别切割 左边
value = locator.split("=>")[1] #分别切割 右边
if by == "id":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.ID, value)))
elif by == "name":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.NAME, value)))
elif by == "class":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.CLASS_NAME, value)))
elif by == "link_text":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.LINK_TEXT, value)))
elif by == "xpath":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.XPATH, value)))
elif by == "css":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.CSS_SELECTOR, value)))
elif by == "tag":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.TAG_NAME, value)))
else:
raise NameError(
"不在选择范围内,'id','name','class','link_text','xpaht','css','tag'.")
return element
def get_elements_wait(self, locator, timeout=12, poll=0.5):
'''
多个元素的显式等待,接收参数更少(可以不直接使用)
driver.element_wait("css=>#el", 10)
:param xpath:
:param poll:不填写则默认0.5秒
:param timeout:默认12秒
'''
if "=>" not in locator:
raise NameError("Positioning syntax errors")
# #main > div.row > div.sidebar.col-md-3 > div:nth-child(1) > div > a
# by=>value
#
by = locator.split("=>")[0]
value = locator.split("=>")[1]
if by == "id":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_all_elements_located((By.ID, value)))
elif by == "name":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_all_elements_located((By.NAME, value)))
elif by == "class":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, value)))
elif by == "link_text":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_all_elements_located((By.LINK_TEXT, value)))
elif by == "xpath":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_all_elements_located((By.XPATH, value)))
elif by == "css":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, value)))
else:
raise NameError(
"不在选择范围内,'id','name','class','link_text','xpaht','css'.")
return element
def get_window_handle(self):
"""
网页句柄
:param num:
:return:
"""
handles = self.driver.window_handles
#self.driver.switch_to.window(handles[num])
return handles
def leave_frame(self):
"""
将焦点切换到默认框架(iframe)
"""
self.driver.switch_to.default_content()
def submit(self, locator):
"""
提交
driver.submit("xpath=>value")
"""
self.time_sleep(self.time_wait)
self.get_element_wait(locator) # 显式等待
self.get_element(locator).submit() # 当显示等待触发后在提交
print('确认元素%s后提交了' % locator)
def get_windows_img(self, file_path):
"""
截图
file_path:自己拼接
driver.get_windows_img("绝对路径/testcase名称.jpg")
"""
self.time_sleep(3)
self.driver.get_screenshot_as_file(file_path)
print('获得截图.')
def js_execute(self, script, *args):
"""
执行js脚本 *args为不定长 元祖
使用方法:
driver.js("window.scrollTo(200,1000);")
"""
self.driver.execute_script(script, *args)
print('Execute script: %s' % (script))
def check_element(self, locator, text):
"""
定位检查后在输出
:Usage:
driver.type("xpath=>//*[@id='el']", "selenium")
"""
self.get_element(locator) #
el = self.get_element_wait(locator) # 双保险
try:
time.sleep(1)
el.clear()
except:
print('clear failed is %s' % locator)
el.send_keys(text)
time.sleep(1)
print('check 元素%s is %s' % (text, locator))
def click_element(self, locator=None):
"""
点击页面元素
driver.clickinfo("xpath=>//*[@id='el']")
"""
if locator: # 定义了None
self.get_element_wait(locator)
el = self.get_element(locator)
el.click()
print("已选择对象:", locator)
# locator=None
# return locator
else:
# .click()单击
ActionChains(self.driver).click().perform() # 不会立即执行 按顺序位
def send_keys_(self, locator, context):
'''
输入内容
:param pattern: 元素定位方法,id,name等
:param position: 定位元素的value
:param context: 要输入的内容
:return:
'''
try:
element = self.clear_(locator)
if element:
element.send_keys(context)
return element
except Exception as error:
print(error)
def get_window_handle(self):
"""
返回当前网页句柄
:return:
"""
return self.driver.current_window_handle
def click_partial(self, text):
"""
可以局部也可以全局
driver.click_text("新闻")
"""
self.time_sleep(self.time_wait)
self.driver.find_element_by_partial_link_text(text).click()
print('打开%s link' % text)
def clear_(self, locator):
'''
清空元素内容
:param pattern: 元素定位方法, id, name等
:param position: 定位元素的value
:return:
'''
try:
element = self.get_element(locator)
if element:
# print(element.text)
element.click() #
# element.clear()
return element
except Exception as error:
print(error)
def double_click(self, locator):
"""
双击元素
driver.double_click("xpath=>")
"""
a = self.get_element_wait(locator)
el = self.get_element(locator)
ActionChains(self.driver).double_click(el).perform()
print('双击元素:', locator)
def get_attribute(self, xpath, value):
"""
拿到元素 可以结合之前代码查看
driver.get_attribute("xpath=>定位器", "type")
"""
self.time_sleep(self.time_wait)
self.get_element_wait(xpath)
ele = self.get_element(xpath)
attr_value = ele.get_attribute(value) # get_attribute是API attr元素el的属性
if attr_value:
print('attribute_value %s is: %s' % (value, attr_value))
return attr_value
else:
print('not found attribute_value: %s' % value)
return None # 布尔
def get_link_text(self, locator):
'''
获取元素内容 注意并不是所有的元素都会有text
driver.get_link_text("link=>value")
:param pattern: 鼓励只用超文本的
:param position: 定位元素的value
:return:
'''
try:
element = self.get_element(locator) # locator写法在里面了
# t = element.get_attribute('value')
text = element.text
return text
except Exception as error:
print(error)
def switch_frame(self,locatValue=None):
"""
:param locatValue: 框架元素
:return:
"""
if locatValue:
self.driver.switch_to.frame(locatValue)
def frame_to_switch(self,target, locatValue, timeout=10):
"""
显式等待,判断是否需要切换到frame
:param driver:其他函数的
:param targetType:用字典的
:param locatorValue:
:return:
"""
wait = WebDriverWait(self.driver, timeout)#这样填充
try:
wait.until(EC.frame_to_be_available_and_switch_to_it
((locatorTypeDict[target.lower()], locatValue)))
print("frame存在,切换成功")
except Exception as error:
print(format(error))
def switch_accept_alert(self):
"""
确认弹出窗体
driver.accept_alert()
"""
self.driver.switch_to.alert.accept()
def dismiss_alert(self):
"""
关闭弹出窗体 拒绝
driver.dismiss_alert()
"""
self.driver.switch_to.alert.dismiss()
测试demo
from util.ClientSelenium import *
import unittest
client = ClientSelenium()
class TestDemo(unittest.TestCase):
@classmethod
def setUpClass(cls):
client.get_driver("Ch","https://www.baidu.com")
time.sleep(2)
@classmethod
def tearDownClass(cls):
client.quit()
def test_login(self):
client.start("https://map.baidu.com/","https://www.baidu.com")
if __name__ == '__main__':
unittest.main()
pageObject模式
- 设计意图 util/ClientElement.py
- 启动封装 get_driver() 思考返回
- 定位器封装
- 显示等待 get_element_wait 无显示等待 get_element
- 双重保险click_element()
- 定位&输入 check_element()
- 截图 get_windows_img()
- 浏览器滑动 js_execute()
- 无显示等待 get_element
- 双重保险 click_element()
显示等待
from selenium.webdriver.support import expected_conditions as EC # 显示等待
from selenium.webdriver.support.ui import WebDriverWait # 显示等待
from selenium.webdriver.common.by import By
def get_element_wait(self, locator, timeout=12, poll=0.5):
#locator 定位器 poll轮询时间,0.3-》0.1
'''
单个元素的显式等待,接收参数更少(可以不直接使用)
driver.element_wait("css=>#el", 10) 复写:一行拼装,不用写两个参数,10代表timeout为10
:param xpath:
:param poll:不填写则默认0.5秒
:param timeout:默认12秒
'''
if "=>" not in locator:
raise NameError("Positioning syntax errors")
# #main > div.row > div.sidebar.col-md-3 > div:nth-child(1) > div > a
# by=>value
#
by = locator.split("=>")[0] #以==>分别切割 左边
value = locator.split("=>")[1] #分别切割 右边
if by == "id":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.ID, value)))
elif by == "name":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.NAME, value)))
elif by == "class":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.CLASS_NAME, value)))
elif by == "link_text":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.LINK_TEXT, value)))
elif by == "xpath":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.XPATH, value)))
elif by == "css":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.CSS_SELECTOR, value)))
elif by == "tag":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.TAG_NAME, value)))
else:
raise NameError(
"不在选择范围内,'id','name','class','link_text','xpaht','css','tag'.")
return element
TestDemo
from util.ClientSelenium import *
import unittest
client = ClientSelenium()
class TestDemo(unittest.TestCase):
@classmethod
def setUpClass(cls):
client.get_driver("Ch","https://www.baidu.com")
time.sleep(2)
@classmethod
def tearDownClass(cls):
client.quit()
def test_login(self):
client.start("https://map.baidu.com/","https://www.baidu.com")
client.get_element_wait("css=>#user-center > div.avatar-abstract").click()
time.sleep (2)
if __name__ == '__main__':
unittest.main()
click_element()
def click_element(self, locator=None):
"""
点击页面元素
driver.clickinfo("xpath=>//*[@id='el']")
"""
if locator: # 定义了None
self.get_element_wait(locator) #显示等待,不能获取元素,非显示等待
el = self.get_element(locator) #双重判断
el.click()
print("已选择对象:", locator)
# locator=None
# return locator
else:
# .click()单击
ActionChains(self.driver).click().perform() # 不会立即执行 按顺序位 单击或双击
from util.ClientSelenium import *
import unittest
client = ClientSelenium()
class TestDemo(unittest.TestCase):
@classmethod
def setUpClass(cls):
client.get_driver("Ch","https://www.baidu.com")
time.sleep(2)
@classmethod
def tearDownClass(cls):
client.quit()
def test_login(self):
client.start("https://map.baidu.com/","https://www.baidu.com")
client.click_element("css=>#user-center > div.avatar-abstract")
time.sleep (2)
if __name__ == '__main__':
unittest.main()
显示等待-》 延迟元素
非显示等待-》非延迟元素 对象.click()
定位&输入 check_element()
截图 get_windows_img()
浏览器滑动 js_execute()
无显示等待 get_element
def send_keys_(self, locator, context):
'''
输入内容
:param pattern: 元素定位方法,id,name等
:param position: 定位元素的value
:param context: 要输入的内容
:return:
'''
try:
element = self.clear_(locator)
if element:
element.send_keys(context)
return element
except Exception as error:
print(error)
封装:同一种功能有两三种方法,因时因地而用
demo
from util.ClientSelenium import *
import unittest
client = ClientSelenium()
class TestDemo(unittest.TestCase):
@classmethod
def setUpClass(cls):
client.get_driver("Ch","https://www.baidu.com")
time.sleep(2)
@classmethod
def tearDownClass(cls):
client.quit()
def test_login(self):
client.start("https://map.baidu.com/","https://www.baidu.com")
# client.click_element("id=>sole-input")
time.sleep(2)
def test_send_keys(self):
client.send_keys_("id=>sole-input","清河派出所")
client.click_element("id=>search-button")
time.sleep(2)
if __name__ == '__main__':
unittest.main()
1:39:14
暂时没看明白
自己创建logs文件夹
实例化的时候需要修改项目名称,否则日志打印两次
https://blog.csdn.net/sily_z/article/details/81032529
保存在util文件夹 log.py
#! python3
# -*- coding: utf-8 -*-
'a practice of ...'
import logging
import time
import os
path = os.path.abspath(os.path.dirname(__file__))
log_path = '/../logs/' #抽象到其他文件内
def create_file(name='WebTest', timestamp=True):
'''
创建文件,并且返回路径和时间
:param path: 路径
:param name: 文件名
:param timestamp: 格式化时间
:return: 文件路径
'''
path = os.path.abspath(os.path.dirname(__file__))
if timestamp:
time_stamp = time.strftime("%Y%m%d_%H%M", time.localtime())
# 返回类似于'{name}_{年月日}_{日期}.log'的文件名称
name = '%s_%s.log' % (name, time_stamp)
# 返回路径的格式拼接
full_path = os.path.join(path + log_path, name)
# exists判断full_path是否存在,如果没有就写入
if not os.path.exists(full_path):
# 创建一个空的文件
f = open(full_path, 'w+',encoding="utf-8")
f.close()
return full_path
def logger(name, level=logging.DEBUG, status=3):
'''
获取一个操作日志的记录器
:param name: 记录器名称
:param level: debug等级
:return: 记录器
'''
# 获得一个记录器
_logger = logging.getLogger(str(name))
# 设置等级
_logger.setLevel(logging.DEBUG)
# 文件输出在文件上
fh = logging.FileHandler(create_file())
fh.setLevel(level)
# 创建一个格式化对象,用于将日志记录转化为指定格式的字符串
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(lineno)s - %(message)s')
# 为指定程序设置格式化
fh.setFormatter(formatter)
# 分别和status按位与运算,将指定的处理程序添加到记录器_logger中
_logger.addHandler(fh)
return _logger
_logger = logger('WebTest')
def close_logger():
h_list = _logger.handlers
for h in h_list:
_logger.removeHandler(h)
# print(_logger.handlers)
# close_logger()
# print(_logger.handlers)
from util.ClientSelenium import *
import unittest
from util import log
_logger = log.logger('LoginTesterHome')
client = ClientSelenium()
class TestDemo(unittest.TestCase):
@classmethod
def setUpClass(cls):
client.get_driver("Ch","https://www.baidu.com")
time.sleep(2)
log._logger.info("启动浏览器成功")
@classmethod
def tearDownClass(cls):
client.quit()
def test_login(self):
client.start("https://map.baidu.com/","https://www.baidu.com")
# client.click_element("id=>sole-input")
time.sleep(2)
log._logger.info("成功切换到百度地图")
def test_send_keys(self):
client.send_keys_("id=>sole-input","清河派出所")
client.click_element("id=>search-button")
time.sleep(2)
log._logger.info("成功搜索到百度地图")
if __name__ == '__main__':
unittest.main()
01:43:54
截图 有点低级
def get_windows_img(self, file_path):
"""
截图
file_path:自己拼接
driver.get_windows_img("绝对路径/testcase名称.jpg")
"""
self.time_sleep(3)
self.driver.get_screenshot_as_file(file_path)
print('获得截图.')对API的拼接叫封装,更好用的
1:47:30
双击
def double_click(self, locator):
"""
双击元素
driver.double_click("xpath=>")
"""
a = self.get_element_wait(locator) #显示等待
el = self.get_element(locator) #非显示等待
ActionChains(self.driver).double_click(el).perform()
print('双击元素:', locator)
def get_link_text(self, locator):
'''
获取元素内容 注意并不是所有的元素都会有text
driver.get_link_text("link=>value")
:param pattern: 鼓励只用超文本的
:param position: 定位元素的value
:return:
'''
try:
element = self.get_element(locator) # locator写法在里面了
# t = element.get_attribute('value')
text = element.text
return text
except Exception as error:
print(error)
def wait_find_Elemnt(self, driver, targetType, locatorValue, timeout=10):
try:
element = WebDriverWait(driver, timeout).until(
lambda x: x.find_element(by=targetType, value=locatorValue)
)
return element
except Exception as err:
print(format(err))
01:52:29
浏览器滑动 js_execute()
def js_execute(self, script, *args):
"""
执行js脚本 *args为不定长 元祖 **args代表字典
使用方法:
driver.js("window.scrollTo(200,1000);") #比例,不同浏览器不同
"""
self.driver.execute_script(script, *args)
print('Execute script: %s' % (script))
API web操作(选学)
- 输入 send_keys(*value) 包含文本和映射的键盘键
from selenium.webdriver.common.keys import Keys 键盘 键包
引入ActionChains类
from selenium.webdriver.common.action_chains import ActionChains perform():执行所有 中存储的行为
双击 double_click(element) 在ClientSelenium里面有封装
鼠标悬停在一个元素上 move_to_element()
1:56:21
Web Driver API
思考如何设计?如何利于扩展
下面讲述:webDriver定位方式和API封装
webDriver 对于网页基础走咗加强封装
利用率越小的越利于扩展
time_wait = 2 #类变量
def time_sleep(self, time_wait):
"""
强制等待默认为2秒
:param time_wait:
:return:
"""
if time_wait <= 0:
time.sleep(time_wait)
else:
print("等待%ss" % time_wait)
time.sleep(time_wait)
实操项目建立
- 工程创建
- 工具类 (日志,截图,等等)
- 日志,报告类
- 文件格式,存储路径
- Run函数
- 可执行文件夹 -测试用例 功能实现
- Run函数
- 最后用Tree编写txt
4:00
截图
需要创建文件夹,并添加路径,文件类型 调用函数,D:\sdk\tools\web_Auto\pic\login.jpg
demo
from util.ClientSelenium import *
import unittest
from util import log
_logger = log.logger('LoginTesterHome')
client = ClientSelenium()
class TestDemo(unittest.TestCase):
@classmethod
def setUpClass(cls):
client.get_driver("Ch","https://www.baidu.com")
time.sleep(2)
log._logger.info("启动浏览器成功")
@classmethod
def tearDownClass(cls):
client.quit()
def test_login(self):
client.start("https://map.baidu.com/","https://www.baidu.com")
# client.click_element("id=>sole-input")
time.sleep(2)
def test_send_keys(self):
client.send_keys_("id=>sole-input","清河派出所")
client.click_element("id=>search-button")
client.get_windows_img (r"D:\sdk\tools\web_Auto\pic\login.jpg")
time.sleep(2)
if __name__ == '__main__':
unittest.main()9:58
可执行文件
run.py
# -*- coding: utf-8 -*-
'a practice of ...'
"入口函数文件"
try:
from Conf.setting import * #setting.py 此处不要写函数 不要写路径拼接
from util import ReadOpenData, HTMLTestRunner, ClientSelenium
from util.Base import TimeUtil
except ImportError as error:
raise error
#入口函数简结
if __name__ == '__main__':
t_util = TimeUtil() #实例化处理Base TimeUtil
suite = unittest.defaultTestLoader.discover(TestDir,pattern='test_*.py') #
TimeUtil --- Base
class TimeUtil(object):
def set_date(self): #固定写法
now = datetime.datetime.now()
return "{0}-{1}-{2}".format(now.year, now.month, now.day)
def set_time(self):#固定写法
return time.strftime("%H-%M")
def get_report_path(self): #核心函数
"格式月日/单位时间格式的.html,只用到time"
nowtime = time.localtime() #转换为可读的
dir_date = time.strftime('-%Y%m%d', nowtime) #格式化 Report-年月日
if not os.path.exists(BaseDir + dir_date): #="E:\selenium_uses\\Report-年月日" 文件夹
os.mkdir(BaseDir + dir_date)
#print("路径===》",BaseDir + dir_date)
day_file = time.strftime('%H%M%S', nowtime)
return BaseDir + dir_date + '\\' + 'Report-' + day_file + '.html'
js滚动条 或 确认
敲一遍clientSelenium.py
# -*- coding: utf-8 -*-
'a practice of ...'
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions as EC # 显示等待
from selenium.webdriver.support.ui import WebDriverWait # 显示等待
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys #键盘类
import time
from util.Base import Base
base = Base()
# 定位器字典 把value打包
locatorTypeDict = {
'xpath': By.XPATH,
'css': By.CSS_SELECTOR,
'id': By.ID,
'name': By.NAME,
'className': By.CLASS_NAME,
'tagName': By.TAG_NAME,
'link': By.LINK_TEXT,
'parLink': By.PARTIAL_LINK_TEXT
}
from selenium import webdriver
# 只开放了基础api的,定位器请自己学习封装完成作业,下节课在讲带保护的高级封装
class ClientSelenium(object):
"""通过封装把Page的行为压缩在这里"""
#执行超类,但不构造函数,只有拉起用到,但与初始内容冲突
def get_driver(self, driver, url):
#driver:如何驱动
"初始化浏览器和打开目标url"
if driver == 'firefox' or driver == 'Firefox' or driver == 'F' or driver == 'f':
# exe_path = base.firefox_path()#第二个功能是包裹在第一个功能下面的
self.driver = webdriver.Firefox()
elif driver == 'Chrome' or driver == 'chrome' or driver == 'Ch' or driver == 'ch':
# exe_path = base.chrome_path()
self.driver = webdriver.Chrome()
print("拉起浏览器成功")
else:
print("输入在预期以外")
self.driver.get(url) # 区域3
return self.driver
def start(self, url, _url):
"""
不拉起浏览器打开网页
:param url: 打开网页
:param _url: 期望网页
:return:
"""
self.driver.get(url)
self._get_current_url(_url) #直接打开url,判断在url页面再去执行页面上的操作
def assert_title(self, titleText):
"""
页面标题上是否包含关键字,支持传入多个参数
:param titleStr: 关键字
:param args: 支持传入多个参数
:return:布尔
"""
try:
assert titleText in self.driver.title, \
"在title里没有找到%s" % titleText
print("加载网页正确") # 业务self.assertTrue()
return True
except Exception as error:
print(format(error))
return False
def assert_source(self, sources):
"""
网页源码是否包含关键字 做业务判断
:param sources: list [arg1,arg2...]
:return:
"""
for source in sources: # 关键字驱动有可能包含多个参数
try:
assert source in self.driver.page_source, \
"在page_source里没有找到%s" % source
print("判断 %s 包含在page_source" % source)
except AssertionError as error: # 断言表达式
print(format(error))
except Exception as error:
print(format(error))
time_wait = 2
def time_sleep(self, time_wait):
"""
强制等待默认为2秒
:param time_wait:
:return:
"""
if time_wait <= 0:
time.sleep(time_wait)
else:
print("等待%ss" % time_wait)
time.sleep(time_wait)
def max_size(self):
"""
放大浏览器最大化 需要先拉起浏览器
:return:
"""
time.sleep(0.5) # 切换展示
self.driver.maximize_window()
def set_size(self, width=800, height=600):
"""
先打印浏览器尺寸,设置浏览器到尺寸
:param width: 宽
:param height: 高
:return:
"""
self.driver.set_window_size(width, height, windowHandle="current") # 当前句柄
print("尺寸设置成功")
def _get_current_url(self, _url):
try:
assert _url == self.driver.current_url #不是继承的超类,只进行基础断言
except Exception as error:
print(format(error))
def F5(self, _url):
"""
刷新后验证网页正确 now_url覆写使用
:return:
"""
self.driver.refresh()
print("刷新正确")
self._get_current_url(_url) # 刷新后判断当前网页
def back(self, _url, time_wait=4):
"""
后退到之前的页面(等同浏览器上按回退按钮)
条件:先需要有前后打开的2个页面
:param _url:形参是验证当前页面
:param time_wait:属于time_sleep方法
:return:
"""
self.time_sleep(time_wait)
self.driver.back()
self._get_current_url(_url)
print("back网页成功")
def forward(self, _url, time_wait=4):
"""
配合浏览器回退使用,回到之前的页面
:param _url:形参是验证当前页面
:param time_wait:属于time_sleep方法
:return:
"""
self.time_sleep(time_wait)
self.driver.forward()
self._get_current_url(_url)
print("forward网页成功")
def quit(self):
"""关闭浏览器
:return:
"""
self.time_sleep(self.time_wait) # 展示最后一条case
self.driver.quit()
# print("关闭浏览器",self.driver.current_window_handle)
def get_element(self, locator):
'''
非显式等待
driver.get_element("css=>#el")
'''
if "=>" not in locator:
raise NameError("Positioning syntax errors, lack of '=>'.")
by = locator.split("=>")[0]
value = locator.split("=>")[1]
if by == "id":
element = self.driver.find_element_by_id(value)
elif by == "name":
element = self.driver.find_element_by_name(value)
elif by == "class":
element = self.driver.find_element_by_class_name(value)
elif by == "link_text":
element = self.driver.find_element_by_link_text(value)
elif by == "xpath":
element = self.driver.find_element_by_xpath(value)
elif by == "css":
element = self.driver.find_element_by_css_selector(value)
elif by == "tag_name":
element = self.driver.find_element_by_tag_name(value)
else:
raise NameError(
"不在选择范围内,'id','name','class','link_text','xpath','css','tag'.")
return element
def get_element_wait(self, locator, timeout=12, poll=0.5):
#locator 定位器 poll轮询时间,0.3-》0.1
'''
单个元素的显式等待,接收参数更少(可以不直接使用)
driver.element_wait("css=>#el", 10) 复写:一行拼装,不用写两个参数,10代表timeout为10
:param xpath:
:param poll:不填写则默认0.5秒
:param timeout:默认12秒
'''
if "=>" not in locator:
raise NameError("Positioning syntax errors")
# #main > div.row > div.sidebar.col-md-3 > div:nth-child(1) > div > a
# by=>value
#
by = locator.split("=>")[0] #以==>分别切割 左边
value = locator.split("=>")[1] #分别切割 右边
if by == "id":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.ID, value)))
elif by == "name":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.NAME, value)))
elif by == "class":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.CLASS_NAME, value)))
elif by == "link_text":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.LINK_TEXT, value)))
elif by == "xpath":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_element_located((By.XPATH, value)))
elif by == "css":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.CSS_SELECTOR, value)))
elif by == "tag":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_element_located((By.TAG_NAME, value)))
else:
raise NameError(
"不在选择范围内,'id','name','class','link_text','xpaht','css','tag'.")
return element
def get_elements_wait(self, locator, timeout=12, poll=0.5):
'''
多个元素的显式等待,接收参数更少(可以不直接使用)
driver.element_wait("css=>#el", 10)
:param xpath:
:param poll:不填写则默认0.5秒
:param timeout:默认12秒
'''
if "=>" not in locator:
raise NameError("Positioning syntax errors")
# #main > div.row > div.sidebar.col-md-3 > div:nth-child(1) > div > a
# by=>value
#
by = locator.split("=>")[0]
value = locator.split("=>")[1]
if by == "id":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_all_elements_located((By.ID, value)))
elif by == "name":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_all_elements_located((By.NAME, value)))
elif by == "class":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, value)))
elif by == "link_text":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_all_elements_located((By.LINK_TEXT, value)))
elif by == "xpath":
element = WebDriverWait(self.driver, timeout, poll).until(EC.presence_of_all_elements_located((By.XPATH, value)))
elif by == "css":
element = WebDriverWait(self.driver, timeout, poll).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, value)))
else:
raise NameError(
"不在选择范围内,'id','name','class','link_text','xpaht','css'.")
return element
def get_window_handle(self):
"""
网页句柄
:param num:
:return:
"""
handles = self.driver.window_handles
#self.driver.switch_to.window(handles[num])
return handles
def leave_frame(self):
"""
将焦点切换到默认框架(iframe)
"""
self.driver.switch_to.default_content()
def submit(self, locator):
"""
提交
driver.submit("xpath=>value")
"""
self.time_sleep(self.time_wait)
self.get_element_wait(locator) # 显式等待
self.get_element(locator).submit() # 当显示等待触发后在提交
print('确认元素%s后提交了' % locator)
def get_windows_img(self, file_path):
"""
截图
file_path:自己拼接
driver.get_windows_img("绝对路径/testcase名称.jpg")
"""
self.time_sleep(3)
self.driver.get_screenshot_as_file(file_path)
print('获得截图.')
def js_execute(self, script, *args):
"""
执行js脚本 *args为不定长 元祖
使用方法:
driver.js("window.scrollTo(200,1000);")
"""
self.driver.execute_script(script, *args)
print('Execute script: %s' % (script))
def check_element(self, locator, text):
"""
定位检查后在输出
:Usage:
driver.type("xpath=>//*[@id='el']", "selenium")
"""
self.get_element(locator) #
el = self.get_element_wait(locator) # 双保险
try:
time.sleep(1)
el.clear()
except:
print('clear failed is %s' % locator)
el.send_keys(text)
time.sleep(1)
print('check 元素%s is %s' % (text, locator))
def click_element(self, locator=None):
"""
点击页面元素
driver.clickinfo("xpath=>//*[@id='el']")
"""
if locator: # 定义了None
self.get_element_wait(locator)
el = self.get_element(locator)
el.click()
print("已选择对象:", locator)
# locator=None
# return locator
else:
# .click()单击
ActionChains(self.driver).click().perform() # 不会立即执行 按顺序位
def send_keys_(self, locator, context):
'''
输入内容
:param pattern: 元素定位方法,id,name等
:param position: 定位元素的value
:param context: 要输入的内容
:return:
'''
try:
element = self.clear_(locator)
if element:
element.send_keys(context)
return element
except Exception as error:
print(error)
def get_window_handle(self):
"""
返回当前网页句柄
:return:
"""
return self.driver.current_window_handle
def click_partial(self, text):
"""
可以局部也可以全局
driver.click_text("新闻")
"""
self.time_sleep(self.time_wait)
self.driver.find_element_by_partial_link_text(text).click()
print('打开%s link' % text)
def clear_(self, locator):
'''
清空元素内容
:param pattern: 元素定位方法, id, name等
:param position: 定位元素的value
:return:
'''
try:
element = self.get_element(locator)
if element:
# print(element.text)
element.click() #
# element.clear()
return element
except Exception as error:
print(error)
def double_click(self, locator):
"""
双击元素
driver.double_click("xpath=>")
"""
a = self.get_element_wait(locator) #显示等待
el = self.get_element(locator) #非显示等待
ActionChains(self.driver).double_click(el).perform()
print('双击元素:', locator)
def get_attribute(self, xpath, value):
"""
拿到元素 可以结合之前代码查看
driver.get_attribute("xpath=>定位器", "type")
"""
self.time_sleep(self.time_wait)
self.get_element_wait(xpath)
ele = self.get_element(xpath)
attr_value = ele.get_attribute(value) # get_attribute是API attr元素el的属性
if attr_value:
print('attribute_value %s is: %s' % (value, attr_value))
return attr_value
else:
print('not found attribute_value: %s' % value)
return None # 布尔
def get_link_text(self, locator):
'''
获取元素内容 注意并不是所有的元素都会有text
driver.get_link_text("link=>value")
:param pattern: 鼓励只用超文本的
:param position: 定位元素的value
:return:
'''
try:
element = self.get_element(locator) # locator写法在里面了
# t = element.get_attribute('value')
text = element.text
return text
except Exception as error:
print(error)
def switch_frame(self,locatValue=None):
"""
:param locatValue: 框架元素
:return:
"""
if locatValue:
self.driver.switch_to.frame(locatValue)
def frame_to_switch(self,target, locatValue, timeout=10):
"""
显式等待,判断是否需要切换到frame
:param driver:其他函数的
:param targetType:用字典的
:param locatorValue:
:return:
"""
wait = WebDriverWait(self.driver, timeout)#这样填充
try:
wait.until(EC.frame_to_be_available_and_switch_to_it
((locatorTypeDict[target.lower()], locatValue)))
print("frame存在,切换成功")
except Exception as error:
print(format(error))
def switch_accept_alert(self):
"""
确认弹出窗体
driver.accept_alert()
"""
self.driver.switch_to.alert.accept()
def dismiss_alert(self):
"""
关闭弹出窗体 拒绝
driver.dismiss_alert()
"""
self.driver.switch_to.alert.dismiss()
def wait_find_Elemnt(self, driver, targetType, locatorValue, timeout=10):
try:
element = WebDriverWait(driver, timeout).until(
lambda x: x.find_element(by=targetType, value=locatorValue)
)
return element
except Exception as err:
print(format(err))