解析Linux中的VFS文件系统
Vfs文件系统详解
前言:
本文基于linux kernel 3.14.17来讨论VFS机制,以及内核对VFS的支持,试图从源代码的角度来理解,所以在阅读本文之前需要读者对linuxVFS的基本的数据结构有所了解,(super_block、inode、dentry、vfsmount等)。
一、VFS的概念
VFS是Linux中的一个虚拟文件文件系统,也称为虚拟文件系统交换层(Virtual Filesystem Switch)。它为应用程序员提供一层抽象,屏蔽底层各种文件系统的差异。如下图所示:
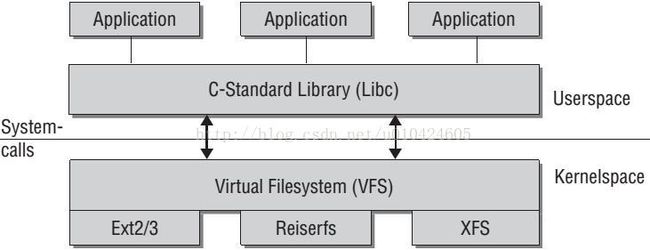
不同的文件系统,如Ext2/3、XFS、FAT32等,具有不同的结构,假如用户调用open等文件IO函数去打开文件,具体的实现会非常不同。为了屏蔽这种差异,Linux引入了VFS的概念。相当于是Linux自建了一个新的贮存在内存中的文件系统。所有其他文件系统都需要先转换成VFS的结构才能为用户所调用。
二、VFS 概述
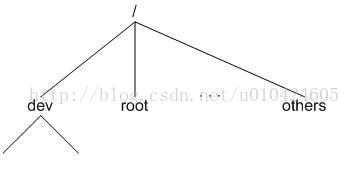
VFS 是一种软件机制,也许称它为 Linux 的文件系统管理者更确切点,与它相关的数据结构只存在于物理内存当中。所以在每次系统初始化期间,Linux 都首先要在内存当中构造一棵 VFS 的目录树(在 Linux 的源代码里称之为 namespace),实际上便是在内存中建立相应的数据结构。VFS 目录树在 Linux 的文件系统模块中是个很重要的概念,希望读者不要将其与实际文件系统目录树混淆,在笔者看来,VFS 中的各目录其主要用途是用来提供实际文件系统的挂载点,当然在 VFS 中也会涉及到文件级的操作,本文不阐述这种情况。下文提到目录树或目录,如果不特别说明,均指 VFS 的目录树或目录。图 1 是一种可能的目录树在内存中的影像:
图 1:VFS 目录树结构
三、rootfs目录树的建立
在众多的实际文件系统中,之所以单独介绍 rootfs 文件系统的注册过程,实在是因为该文件系统 VFS 的关系太过密切,如果说 ext2/ext3 是 Linux 的本土文件系统,那么 rootfs 文件系统则是 VFS 存在的基础。
1、文件系统的注册
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
BUG_ON(strchr(fs->name, '.'));
if (fs->next)
return -EBUSY;
write_lock(&file_systems_lock);
p = find_filesystem(fs->name, strlen(fs->name));
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}static struct file_system_type **find_filesystem(const char *name, unsigned len)
{
struct file_system_type **p;
for (p=&file_systems; *p; p=&(*p)->next)
if (strlen((*p)->name) == len &&
strncmp((*p)->name, name, len) == 0)
break;
return p;
}2、文件系统的挂载
本节阐述 Linux 在初始化阶段是如何建立根结点的,即 "/"目录。这其中会包括挂载 rootfs 文件系统到根目录 "/" 的具体过程。构造根目录的代码是在 init_mount_tree() 函数 (fs\namespace.c) 中。
文件系统类型
struct file_system_type {
const char *name;
int fs_flags;
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
struct hlist_head fs_supers;
};
这里只截取了关键的成员变量 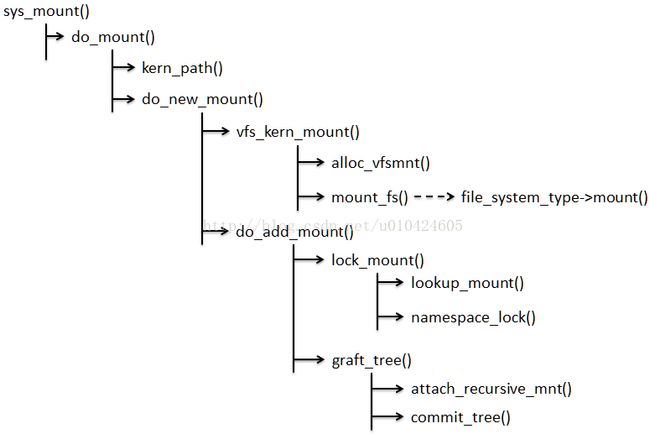
内核通过sys_mount来挂载文件系统,其中关键函数是vfs_kern_mount()和graft_tree(),前者申请了一个挂载示例vfsmount,并调用要挂载的文件系统的mount()函数来申请对应的超级块、dentry和inode节点填充必要的字段和文件系统信息。下面我们以rootfs的挂载来详细阐述这一过程。
graft_tree() 函数要做的事情便是将 do_kern_mount() 函数返回的一 struct vfsmount 类型的变量加入到安装系统链表中,同时 graft_tree() 还要将新分配的 struct vfsmount 类型的变量加入到一个hash表中,其目的我们将会在以后看到。
图2:linux内核建立rootfs目录树流程:

首先,init_mount_tree() 函数会调用 vfs_kern_mount("rootfs", 0, "rootfs", NULL) 来挂载前面已经注册了的 rootfs 文件系统。get_fs_type这个函数用来获取之前注册的rootfs文件系统。这个函数内部会创建我们最关心也是最关键的根目录(在 Linux 中,目录对应的数据结构是 struct dentry)。
在这个场景里,vfs_kern_mount() 做的工作主要是:
1)调用 alloc_vfsmnt() 函数在内存里申请了一块该类型的内存空间(struct vfsmount *mnt),并初始化其部分成员变量。
2) 调用 alloc_super() 函数在内存中分配一个超级块结构 (struct super_block) sb,调用ramfs_fill_super()初始化其部分成员变量,将成员 s_instances 插入到 rootfs 文件系统类型结构中的 fs_supers 指向的双向链表中。
3) ramfs_fill_super调用ramfs_get_inode()在内存中分配了一个 inode 结构 (struct inode) inode,并初始化其部分成员变量,其中比较重要的有 i_op、i_fop 和 i_sb:
ramfs_get_inode():
ramfs_get_inode(sb,...) ---> new_inode(sb) ---> new_inode_pseudo(sb) ---> alloc_inode(sb) ---> inode_init_always(sb, inode) ---> inode->i_sb = sb;
4)ramfs_fill_super调用d_make_root(inode)函数在内存中分配了一个dentry结构体,该结构体的成员d_name.name以“/”命名,并且将该dentry的d_sb和d_inode分别指向之前建立的超级块和inode节点。
这使得将来通过文件系统调用对 VFS 发起的文件操作等指令将被 rootfs 文件系统中相应的函数接口所接管。
图3:
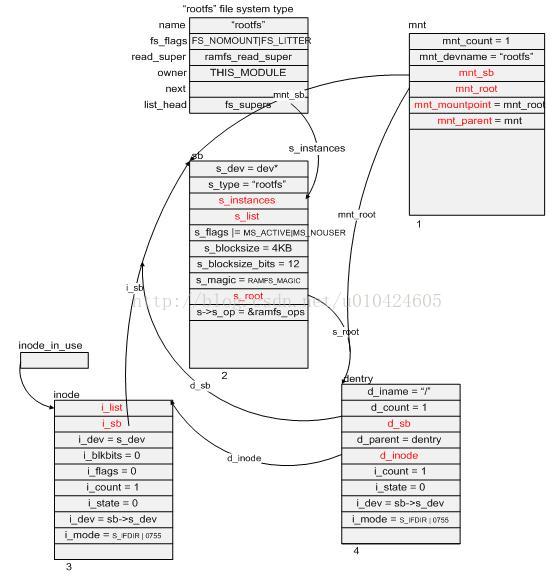
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
}; 注:以上结构体内容在新版本的内核中已经发生了变化,但是各个结构体之间的关系还和以前一样,所以上图只代表各结构体之间的关系。
5)将 mnt 中的 mnt_sb 指针指向 sb,mnt_root 指针指向 dentry。
这样,当 vfs_kern_mount() 函数返回时,以上分配出来的各数据结构和 rootfs 文件系统的关系将如上图 3 所示。图中 mnt、sb、inode、dentry 结构块下方的数字表示它们在内存里被分配的先后顺序。限于篇幅的原因,各结构中只给出了部分成员变量,读者可以对照源代码根据图中所示按图索骥,以加深理解。
最后,init_mount_tree() 函数会为系统最开始的进程(即 init_task 进程)准备它的进程数据块中的namespace 域,主要目的是将 do_kern_mount() 函数中建立的 mnt 和 dentry 信息记录在了 init_task 进程的进程数据块中,这样所有以后从 init_task 进程 fork 出来的进程也都先天地继承了这一信息,为进程建立 namespace 的主要代码如下:
static void __init init_mount_tree(void)
{
struct vfsmount *mnt;
struct mnt_namespace *ns;
struct path root;
struct file_system_type *type;
type = get_fs_type("rootfs");
if (!type)
panic("Can't find rootfs type");
mnt = vfs_kern_mount(type, 0, "rootfs", NULL);
put_filesystem(type);
if (IS_ERR(mnt))
panic("Can't create rootfs");
ns = create_mnt_ns(mnt);
if (IS_ERR(ns))
panic("Can't allocate initial namespace");
init_task.nsproxy->mnt_ns = ns;
get_mnt_ns(ns);
root.mnt = mnt;
root.dentry = mnt->mnt_root;
set_fs_pwd(current->fs, &root);
set_fs_root(current->fs, &root);
}该段代码的最后两行便是将 vfs_kern_mount() 函数中建立的 mnt 和 dentry 信息记录在了当前进程的 fs结构中。
以上讲了一大堆数据结构的来历,其实最终目的不过是要在内存中建立一颗 VFS 目录树而已,更确切地说, vfs_mount_tree() 这个函数为 VFS 建立了根目录 "/",而一旦有了根,那么这棵数就可以发展壮大,比如可以通过系统调用 sys_mkdir 在这棵树上建立新的叶子节点等,所以系统设计者又将 rootfs 文件系统挂载到了这棵树的根目录上。从另一个角度而言,因为 VFS 本身就是内存中的一个数据对象,所以在其上的操作仅限于内存,那也是非常合乎逻辑的事。在接下来的章节中,我们会用一个具体的例子来讨论如何利用 rootfs所提供的函树为 VFS 增加一个新的目录节点。
四、VFS 下目录的建立
为了更好地理解 VFS,下面我们用一个实际例子来看看 Linux 是如何在 VFS 的根目录下建立一个新的目录 "/dev" 的。Linux 下用系统调用 sys_mkdir 来在 VFS 目录树中增加新的节点。同时为配合路径搜索,引入了下面一个数据结构:
struct nameidata {
struct path path;
struct qstr last;
struct path root;
struct inode *inode; /* path.dentry.d_inode */
unsigned int flags;
unsigned seq, m_seq;
int last_type;
unsigned depth;
char *saved_names[MAX_NESTED_LINKS + 1]; 这个数据结构在路径搜索的过程中用来记录相关信息,起着类似"路标"的作用。
其中path用来记录在查找目录时所遍历的目录对象,存放在path.dentry中,root中存放的是查找目的目录的根目录,这里用来记录是绝对路径还是相对路径。mnt的作用接下来再讨论。last_type的取值有LAST_NORM, LAST_ROOT, LAST_DOT, LAST_DOTDOT, LAST_BIND等几种,其定义在include/linux/namei.h中。
图四:sys_mkdir流程图

大体流程是
1)调用do_path_lookup(),查找文件夹,path_init()初始化nameidata对象的root和path字段,分别用来表示当前查找路径的根目录和当前查找的目录,这里根据路径的不同而被初始化为“/”或者“.”。比如查找路径“/dev”则初始化为“/”。接着link_path_walk()函数用来遍历中间目录,直到需要查找的目录,上图省略了链接文件的情况。最后complete_walk()函数结束后就将nameidata的path、root、和last_type等字段填充完毕,其中path存放的是父目录。
2)调用lookup_hash()来在dentry_hashtable散列表中查找该目录,如果没有则调用d_alloc()函数创建该dentry对象,并初始化其超级块信息和操作方法,并将其插dentryhash表中。
3)笔者在新内核中暂未发现sys_mkdir对inode的创建即对所创建的dentry->d_inode成员的填充。姑且认为在新内核中创建文件夹时并不会创建inode对象,只有到对该文件夹操作的时候才会为其分配inode结点,欢迎各位朋友指正其中的错误。
到这里我们的虚拟文件系统的一颗根目录“/”和一个叶子目录“/dev”就已经创建成功了,同样内核还会创建几个重要的目录如“/root”目录用来挂载真实的文件系统。
五、挂载根文件系统
可能有人会问,为什么不直接把真实的文件系统配置为根文件系统?
答案很简单,内核中没有根文件系统的设备驱动,如USB等存放根文件系统的设备驱动,而且即便你将根文件系统的设备驱动编译到内核中,此时它们还尚未加载,其实所有的Driver是由在后面的kernel_Init线程进行加载。所以需要CPIO Initrd、Initrd和RAMDisk Initrd。另外,我们的Root设备都是以设备文件的方式指定的,如果没有根文件系统,设备文件怎么可能存在呢?
从图2可以看出,内核在启动最后调用了rest_init()函数,该函数创建了第一个进程kernel_init()进程号为0,该函数首先调用了函数kernel_init_freeable(),该函数调用了do_basic_setup(),该函数如下:
static void __init do_basic_setup(void)
{
cpuset_init_smp();
usermodehelper_init();
shmem_init();
driver_init();
init_irq_proc();
do_ctors();
usermodehelper_enable();
do_initcalls();
random_int_secret_init();
}其中,do_initcalls()用来启动所有在__initcall_start和__initcall_end段的函数,而静态编译进内核的modules也会将其入口放置在这段区间里。跟根文件系统相关的初始化函数都会由rootfs_initcall()所引用。注意到有以下初始化函数:
rootfs_initcall(populate_rootfs);
static int __init populate_rootfs(void)
{
char *err = unpack_to_rootfs(__initramfs_start, __initramfs_size);
if (err)
panic("%s", err); /* Failed to decompress INTERNAL initramfs */
if (initrd_start) {
#ifdef CONFIG_BLK_DEV_RAM
int fd;
printk(KERN_INFO "Trying to unpack rootfs image as initramfs...\n");
err = unpack_to_rootfs((char *)initrd_start,
initrd_end - initrd_start);
if (!err) {
free_initrd();
goto done;
} else {
clean_rootfs();
unpack_to_rootfs(__initramfs_start, __initramfs_size);
}
printk(KERN_INFO "rootfs image is not initramfs (%s)"
"; looks like an initrd\n", err);
fd = sys_open("/initrd.image",
O_WRONLY|O_CREAT, 0700);
if (fd >= 0) {
sys_write(fd, (char *)initrd_start,
initrd_end - initrd_start);
sys_close(fd);
free_initrd();
}
done:
#else
printk(KERN_INFO "Unpacking initramfs...\n");
err = unpack_to_rootfs((char *)initrd_start,
initrd_end - initrd_start);
if (err)
printk(KERN_EMERG "Initramfs unpacking failed: %s\n", err);
free_initrd();
#endif
/*
* Try loading default modules from initramfs. This gives
* us a chance to load before device_initcalls.
*/
load_default_modules();
}
return 0;
}
rootfs_initcall(populate_rootfs);unpack_to_rootfs:顾名思义就是解压包,并将其释放至rootfs。它实际上有两个功能,一个是释放包,一个是查看包,看其是否属于cpio结构的包。功能选择是根据最后的一个参数来区分的.
在这个函数里,对应三种虚拟根文件系统的情况。其中一种是跟kernel融为一体的initramfs.在编译kernel的时候,通过链接脚本将其存放在__initramfs_start至__initramfs_end的区域。这种情况下,直接调用unpack_to_rootfs将其释放到根目录。(读者可以将/boot目录下的initrd.img文件解压查看)。
回到kernel_init_freeable()这个函数:

如果ramdisk_execute_command非空则执行该命令,该命令被赋值为“/init”。sys_access()的作用是判断根目录下是否有”init”这个文件,如果有的话就执行prepare_namespace()这个函数。这个函数实现了从虚拟“rootfs”向真实“rootfs”的转变。其具体流程如下:(这里的流程是简化了的,实际的流程比这个要复杂,这里只取其主线将大体流程提出来,方便理解)

有了前面章节三的基础,理解 Linux 下根文件系统的安装并不困难,因为不管怎么样,安装一个文件系统到 VFS 中某一安装点的过程原理毕竟都是一样的。这个过程大致是:首先要确定待安装的 ext2 文件系统的来源,其次是确定 ext2 文件系统在 VFS中的安装点,然后便是具体的安装过程。
关于第一问题,Linux 2.4.20 的内核另有一大堆的代码去解决,linux3.14.17并没有改变这一块的代码,限于篇幅,笔者不想在这里去具体说明这个过程,大概记住它是要解决到哪里去找要安装的文件系统的就可以了,这里我们不妨就认为要安装的根文件系统就来自于主硬盘的第一分区 hda1.
关于第二个问题,Linux 2.4.20 的内核把来自于 hda1 上 ext2 文件系统安装到了 VFS 目录树中的"/root" 目录上。
在 Linux 下,设定一个进程的当前工作目录是通过系统调用 sys_chdir() 进行的。初始化期间,Linux 在将 hda1 上的 ext2 文件系统安装到了 "/root" 上后,通过调用 sys_chdir("/root") 将当前进程,也就是 init_task 进程的当前工作目录(pwd)设定为 ext2 文件系统的根目录。记住此时 init_task进程的根目录仍然是图 3 中的 dentry,也就是 VFS 树的根目录,这显然是不行的,因为以后 Linux 世界中的所有进程都由这个 init_task 进程派生出来,无一例外地要继承该进程的根目录,如果是这样,意味着用户进程从根目录搜索某一目录时,实际上是从 VFS 的根目录开始的,而事实上却是从 ext2 的根文件开始搜索的。这个矛盾的解决是靠了在调用完 mount_root() 函数后,系统调用的下面两个函数:
sys_mount(".", "/", NULL, MS_MOVE, NULL);
sys_chroot(".");
自此我们在用户态所看到的根目录”/”就是实际的文件系统的根目录了。
看到这里读者以为就大功告成了?
下面做一个测试:该段代码在上面提到的kernel_init_freeable()的最后部分。
上文提到过在populate_rootfs()函数中已经将initramfs解压到了之前由vfs建立的虚拟的“/”目录中,而sys_access()的作用就是判断“/”目录中有没有ramdisk_execute_command所指定的文件,如果有则返回0,反之则不为0。于是在两处打印调试信息和ramdisk_execute_command的值,经过编译安装内核成功启动系统后查看系统的输出日志。
![]()

重新编译内核并安装启动后:syslog日志里面并没有”asion1”的字样输出,而有“asion”,且ramdisk_execute_command为空,因此,该值被赋值为“/init”,而prepare_namespace()函数并没有被执行。这是因为initrd.img归档文件被解压到rootfs,其中存在了/init文件,如果存在该文件则不会执行prepare_namespace()函数,kernel_init_freeable()函数退出。
如果读者有兴趣可以将/boot目录下的initrd.img文件解压来看看当中是否有init文件,并看看它到底做了什么。
static int __ref kernel_init(void *unused)
{
int ret;
kernel_init_freeable();
/* need to finish all async __init code before freeing the memory */
async_synchronize_full();
free_initmem();
mark_rodata_ro();
system_state = SYSTEM_RUNNING;
numa_default_policy();
flush_delayed_fput();
if (ramdisk_execute_command) {
ret = run_init_process(ramdisk_execute_command);
if (!ret)
return 0;
pr_err("Failed to execute %s (error %d)\n",
ramdisk_execute_command, ret);
}接下来会执行ret = run_init_process(ramdisk_execute_command);这里的ramdisk_execute_command=“/init”,而run_init_process在调用相应程序运行的时候,用的是kernel_execve。也就是说调用进程会替换当前进程。即如果文件“/init”存在则不会返回了。那么init这个命令就取代了头号进程kernel_init()而成为系统的第一个进程。
init执行完成之后内核就已经启动系,那么虚拟rootfs到底再什么时候变成真实的文件系统的呢?
答案可以在linux内核源代码的文档里找到:Documentation/early-userspace/README

第c)点说使用initramfs,函数prepare_namespaec()被跳过而没有执行,“/init”一定会被执行,它做了prepare_namespace()所做的所有工作,这就是为什么前文要花功夫来讲这个函数的原因,因为这个函数实现了从虚拟rootfs到真实rootfs的转变。
现在的linux内核都是采用initramfs的方式来加载文件系统的。从文档中可以看出/init做了以上prepare_namespace()的所有工作。读者有兴趣可以将/init脚本拿过来研究。
最后我们用mount查看一下,“/”目录的文件系统是ext4。
参考资料:http://www.ibm.com/developerworks/cn/linux/l-vfs/