scarpy 整合 djangoitem,摆脱保存数据时SQL报错的困扰
这里有一个官方的链接,虽然说的并不完整,但是思路讲解的还是很不错的:https://pypi.python.org/pypi/scrapy-djangoitem/1.1.1
这里我做了一个小案例,会一步步从头进行整合,再次熟悉整个流程。为了达到更好的效果,有些变量名包含近似的含义,方便理解思路,而有的变量名完全没有意义,便于展示不同类与方法之间的指向关系。
这篇博客从以下几个部分阐述:
- 基本环境安装
- 思路简介
- 在django上的操作
- 在scrapy上的操作
- 案例源码
一 基本环境安装
我是ubuntu17.04,python3.5的实验环境
- pip install django
- pip install scrapy
- pip install pymysql#用来连接mysql数据库python2中为mysqldb,python3中是pymysql
- pip install mysqlclient
- pip install scrapy_djangoitem # 用来连接django与scrapy
二 思路简介
爬虫的核心还是要靠scrapy,因此django只是提供一个保存数据库的方法(django中叫做model),所以我们需要做的就是:
- 在django上搭建一个model,让所有需要保存的数据通过这个model,依靠django框架完成保存
- 在scrapy上写一个爬虫,得到数据源,然后传递到这个model中
三 在django上的操作
确保环境搭建需要安装的模块都安装完毕后继续进行 ~
这里建议新建一个空文件夹,方便一步步熟悉整个流程。这里我新建了一个空文件夹:scrapy_django_testPro
1.在命令行中cd到这个空文件下,然后:
django-admin startproject mydjango
如果是pycharm的编辑器,把最外面的mydjango标记为资源文件:(右键,下面有一个mark directory as 然后选source root)
这样就新建了一个django的项目,名字是mydjango 。总的来数在django上只需要完成两部操作:配置在mysql中保存的位置,还有新建一个model
2.配置mysql
在这个位置找到settings.py文件,打开:
然后找到这段话:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}替换掉,具体的配置根据自己的情况来:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 使用mysql进行数据存储
'NAME': 'scrapy_django_testPro', # 数据库的名称
'USER': 'root', # 用户名
'PASSWORD': 'rootpwd', # 密码
'HOST': '127.0.0.1', # 数据库地址
'PORT': '3306' # 端口
}
}完成度django部分 50 %
3.新建model
想要新建model,需要先建立一个app,然后依靠app来建model:
》新建 app
1.首先进入这个项目中:
cd mydjango/
然后建立app:为了便于区分,我叫它 save_app,用以表示是做存储的app:
python manage.py startapp save_app
2.在刚才的setting文件中找到这一栏:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]在这里面添加上咱们的app,修改为:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'save_app',
]》新建model:
1.打开save_app的文件夹,打开models.py文件
添加如下代码:
class My_save_model(models.Model):
con1 = models.CharField(max_length=255)
con2 = models.CharField(max_length=255)之后的数据交给model就好,它会在django的框架中找到mysql的配置,进行保存。
2.在当前目录(目录文件中包含有manage.py)的命令行中,输入如下命令:
python manage.py makemigrations
python manage.py migrate
这时,可以通过mysql可视化的工具看到这里多了N张表,但是最重要的是这里有一张表,叫做:save_app_my_save_model(django的数据表会自动命名为:app名_model名)
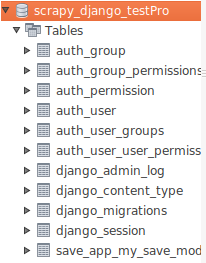
完成这步,django这部分就结束了,之后就是scrapy的操作了。
四 在scrapy上的操作
scrapy上总的来说有五步:
- item.py编写,把django中的models延伸到scrapy中来
- pipeline.py编写,告诉django保存item中的数据
- settings.py配置,使整个“后勤”生效
- 爬虫类编写,获取数据源
- 使我们可以在编辑器中调试这个整合过的项目
实际编写的逻辑和爬虫真正执行的逻辑是反着来的。
1.item.py的编写
首先我们需要先建立一个爬虫项目,将命令行所在的位置移动到scrapy_django_testPro 这个根目录下,执行下面的命令就可以了:
cd .. # 返回上一级目录
scrapy startproject myscrapy # 创建爬虫项目,名字是:myscrapy
然后把最外层的myscrapy标记为sourc root(如果是pycharm)
连续点开两个myscrapy文件后,我们可以看到这样子的目录:
点开这个items.py文件,可以看到有一个MyscrapyItem的模板
我们修改这个模板,为:
from scrapy_djangoitem import DjangoItem
from save_app.models import My_save_model
class MyscrapyItem(DjangoItem):
django_model = My_save_model # 注意这里不要有小括号,因为我们不是调用方法,而只是单纯的把函数名传递过去这里,我们更换了继承的类,同时通过这个scrapy的items.py导入了django中的app的model,完成了两个框架间的关联
2.pipeline.py编写,告诉django保存item中的数据
只需要添加一句话就行,在原有的MyscrapyPipeline的基础上改为:
class MyscrapyPipeline(object):
def process_item(self, item, spider):
item.save()
return item
这样就可以了,这个pipeline会在一组数据都有序的填充到item之后得到执行,执行save()方法就可以加入到mysql中了。
3.settings.py配置,使整个“后勤”生效
》第一个:
ROBOTSTXT_OBEY = False # 默认会是True,自信的改了它,hahaha
》第二个:默认会被注释掉,只需要取消注释即可
ITEM_PIPELINES = {
'myscrapy.pipelines.MyscrapyPipeline': 300,
}》在最上方添加环境变量:
import sys
import os
import django
BASE_DIR = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))
PRO_ROOT = os.path.dirname(BASE_DIR) # 两个项目共同的根目录
sys.path.append(os.path.join(PRO_ROOT, 'myscrapy'))
sys.path.append(os.path.join(BASE_DIR, 'myscrapy'))
os.environ['DJANGO_SETTINGS_MODULE'] = 'mydjango.settings'
django.setup()
4.爬虫类编写,获取数据源
这里我使用网上down来的:
在spiders文件夹下新建Myspider文件,然后粘贴下面的爬虫代码
import scrapy
from myscrapy.items import MyscrapyItem
class Myspider(scrapy.Spider):
name = "myspider_haha"
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
item = MyscrapyItem()
item['con1'] = quote.css('span.text::text').extract_first()
item['con2'] = quote.xpath('span/small/text()').extract_first()
yield item # 从这里发送出去的 item
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
5.使我们可以在编辑器中调试这个整合过的项目
需要新建一个main.py文件,注意下图的位置:
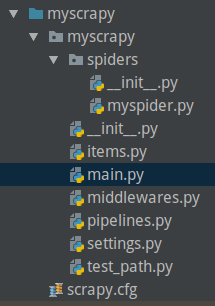
注意图中的位置,新建一个main.py文件,添加如下代码:
import sys
import os
from scrapy.cmdline import execute
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "myspider_haha"]) # 这句代码会执行爬虫类中 name = "myspider_haha"的类
然后在代码中哪里不懂的地方加上断点,对着这个类右键调试运行,就OK了
五 案例源码:
我已经推到github上了:
https://github.com/demeen68/scrapy_django_testPro