论文阅读SPCNet-Scene Text Detection with Supervised Pyramid Context Network
论文名称: Scene Text Detection with Supervised Pyramid Context Network
论文原文:原文链接
一句话
SPCNet是一个曲文检测算法,采用Instance-segmentation的思路,在MaskR-CNN的基础上,提出并添加了一个全局文本分割分支,完成曲文检测。
创新点
1)针对误检的问题,提出了TCM模块和Re-Score机制;
False positive(FP)误检:把一些非文本检测为文本,

2)SPCNet可以灵活地检测各种形状的文本。
采取Mask R-CNN作为基础结构,利用实例分割来检测各种形状的文本
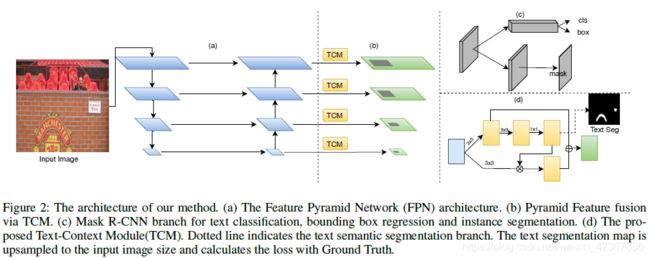
框架
我们的网络由五部分组成:特征金字塔网络(FPN),区域提议网络(RPN),R-CNN分支,Mask预测分支和全局文本分割预测分支。
流程
第一步:本文的骨干网络为Res-Net50,并建立一个4层的特征金字塔网络;
第二步:在每一层上进行全局文本分割分支和Mask分支的操作;
第三步:以第二层为例,将特征图输入到TCM,在Pyramid AttentionModule(PAM)注意力子模块得到输出像素级文本/非文本区域文本分割图(text seg),在Pyramid Fusion Module(PFM)特征融合子模块得到融合了检测特征与深度监督语义特征的特征图;
第四步:进入Mask分支,通过Roi-Align,将PRN所得到的proposal的大小分别调整为7×7进入R-CNN分支和14×14进入Mask预测分支,从而完成文本/非文本分类,bounding box回归和实例分割;
第五步:(后处理)把每一个文本实例投影到全局文本分割图上,利用Re-Score模块融合分类分数(CS)和实例得分(IS)为所有预测的文本实例重新评分,得到每个文本实例的融合分数;利用得到的mask来得到最后的检测结果(minAreaRect)
Mask R-CNN算法步骤复习
Mask R-CNN详解链接
首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
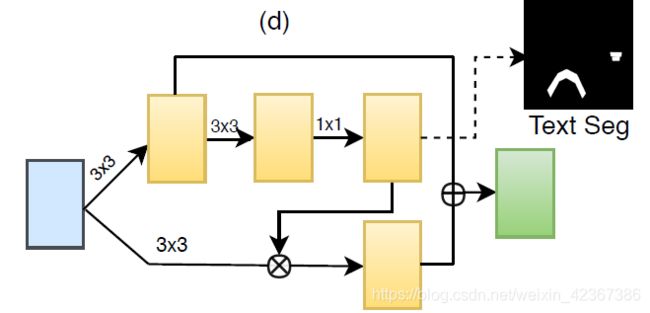
关键模块一:Text Context Module(TCM)文本上下文模块
我们的文本上下文模块(TCM)由两个子模块组成:Pyramid Attention Module(PAM)和Pyramid Fusion Module(PFM)。 将特征图输入TCM,从而输出文本分割图。
Pyramid Attention Module(PAM)注意力模块
我们还在FPN从stage2到stage5之后添加了一个全局文本分割分支。 它为每个FPN层生成像素级文本/非文本区域的特征图。 注意模块和融合模块共享一个名为文本上下文模块即TCM的分支,包括两个3×3卷积层和一个1×1卷积层。 输出特征图包括两个通道,即文本/非文本图。 我们增强显着性图并使用它来激活特征图上的文本区域。
具体来说,以stage2为例,给出512×512的输入样本,特征图S2∈R128×128×256。 特征图的生成如下:

从而得到文本分割图

点乘操作:特征图的对应像素值相乘
Pyramid Fusion Module(PFM)特征融合模块
PFM将检测特征与深度监督语义特征相结合,使网络更具辨别性,从而将文本与非文本区分开来。
具体地,语义分割从单个像素的角度检查文本,并通过组合周围像素的信息来确定文本区域,并且检测通过ROI对文本区域进行分类。 两个分支之间存在天然的互补关系。
在文本上下文模块的第一个3×3卷积层之后,我们得到全局文本分割的特征图(GTF)。这些特征捕获补充信息,如上下文,背景和文本的语义分割。
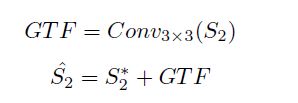
相加操作:特征图的对应像素值相加
关键模块二:Re-Score Mechanism
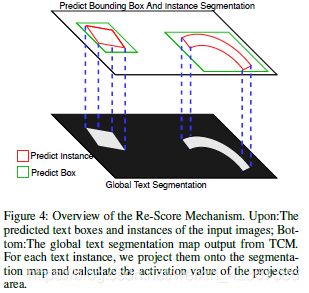
文本实例的融合分数由两部分组成:分类分数(CS)和实例得分(IS);其中CS由Mask R-CNN分类分支直接获得,IS是全局文本分割图上文本实例的值。
例如:第i个实例的分类得分是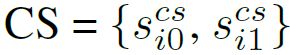
实例得分是
![]()
把每一个文本实例投影到文本分割图上,文本分割图上第i个实例的像素值的集合为![]()
pi的均值如下

则它的融合分数是
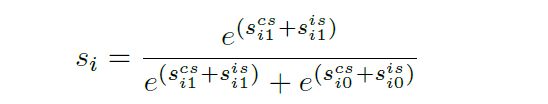
标签生成

我们将多边形内的像素视为文本,将多边形外的像素视为非文本,然后我们得到文本区域的实例。多边形的最小边界水平矩形将被视为边界框。
损失函数
采取多任务损失函数,在Mask R-CNN的损失函数基础上,添加了全局文本分割损失。

L-gts是Softmax损失,用来优化全局文本分割损失,p是网络的预测输出。

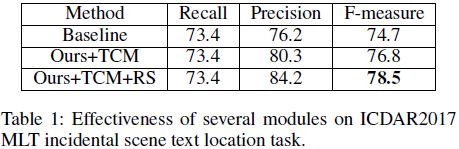
实验结果
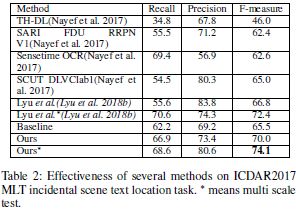
自身对比试验
证明TCM和Re-Score有效性
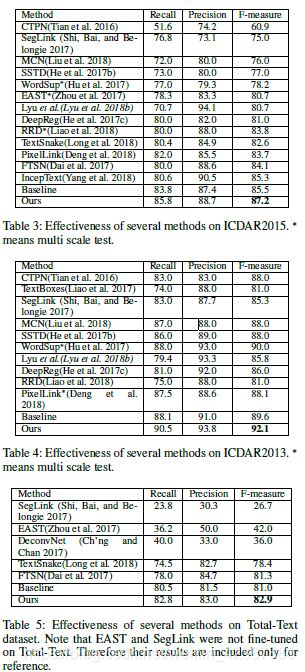
与现有算法的对比
在数据集SynthText、ICDAR2017MLT、ICDAR2015、ICDAR2013、Total-Text上进行实验