solr-in-action-ch4-Configuring Solr
Solr主要的三个XML配置文件:
solr.xml: solr 日志、shard、solrcould等配置
solrconfig.xml: 某个solr core的配置
schema.xml:某个solr core的索引结构的配置,包括field 和field类型
这一章主要介绍solrconfig.xml, 某个solr core的配置。
1、Core的发现过程
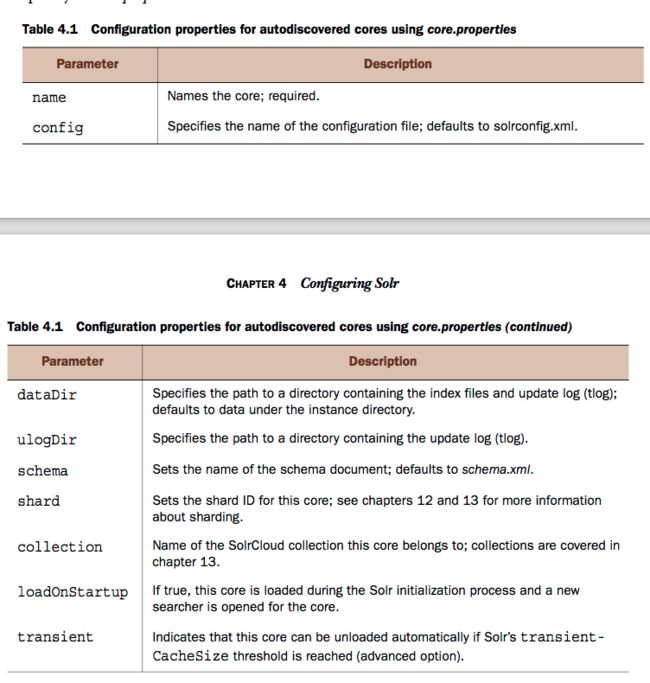
扫描启动某个core的过程是这样的:Solr web服务器根据配置的java System Property(solr.solr.home),找到solr的home路径,然后solr会扫描这个home路径下面的包含有core.properties的子目录。core.properties定义了core的名称、以及其他一些配置信息(非必须,一般现在都在之类仅仅定义name=your_collection_name),其他一些参数如下左图。一旦solr发现了这个core之后就会到这个目录下面的conf目录下找到solrconfig.xml来开始初始化这个core。

Overview of solrconfig.xml
solrconfig.xml中有大量类似

arr:即array的缩写,表示一个数组,name即表示这个数组参数的变量名
lst即list的缩写,但注意它里面存放的是key-value键值对
bool表示一个boolean类型的变量,name表示boolean变量名,
同理还有int,long,float,str等等
Str即string的缩写,唯一要注意的是arr下的str子元素是没有name属性的,而list下的str元素是有name属性的
2、Query request handling
2.1、Request-handling overview
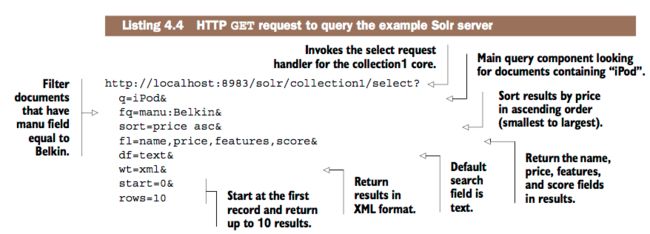
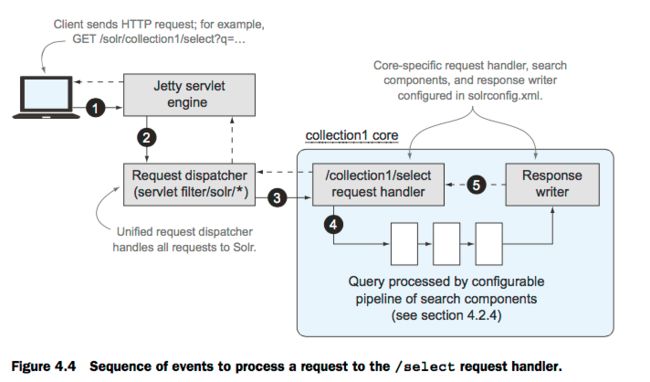
Solr 查询请求的处理过程:
1、Client(浏览器或者solrj客户端)发送查询请求到solr服务器
2、Jetty(或者tomcat等其他的web服务器)会将/solr的请求路由到solr统一的request dispatcher,dispatcher会根据/collection1找到对应的core,并找到这个core的solrconfig.xml中定义的处理请求的 request handle
3、request handler 使用各个组件串行的处理这个请求
4、处理完成后,Reponse writer组件会将结果处理成某个格式(xml、json等等)并返回client,默认是返回xml格式。
2.2、search handler
request handler主要有两类search handler和update handler,search handler负责处理查询请求、update handler用来更新索引的请求,这里主要介绍一下search handler,update handler 下一章介绍。下图是solrconfig.xml中/select request handler的定义。

ps:solrconfig.xml文件中定义的solr.开头的class(如这里的solr.SearchHandler),都会对应于solr core java package:
"analysis.", "schema.", "handler.", "search.", "update.", "core.", "request.", "update.processor.", "util.", "spelling.", "handler.component.", or"handler.dataimport." 。这里的SearchHandler对应于
org.apache.solr.handler.component.SearchHandler 。
一个Search handler可以定义一下几个处理阶段:
1.请求参数处理
添加请求中没有的默认查询参数
覆盖修改请求的参数值
添加额外的参数
2.search first-components(可选)
3.search process components
4.search last-components (可选)

2.3、search components
2.3.1 QUERY COMPONENT
query处理的核心,通过active searcher 解析和执行查询。查询解析是通过参数控制的defType(如edismax,dismax)。query 组件查询初匹配查询参数的doc,这些doc可以被后续的组件继续处理。query组件是默认开启的,后续其他的组件需要在查询参数里显示的指定。
2.3.2 FACET COMPONENT
solr将以导航为目的的查询结果称为facet. 它并不会修改查询结果信息, 只是在查询结果上根据分类添加了count信息, 然后用户根据count信息做进一步的查询, 比如淘宝的查询列表中, 上面会表示不同的类目相关查询结果的数量,,后续会详细介绍
2.3.3 MORE LIKE THIS COMPONENT
如果启用这个组件,会搜索出和查询结果相似的doc,后续会详细介绍
2.3.4 HIGHLIGHT COMPONENT
如果启用这个组件,会高亮显示匹配的文本,后续会详细介绍
2.3.5 STATS COMPONENT
统计组件,如果启用,可以统计指定数字field的统计信息,如最小值、最大值、总和、平均值...等等统计信息,具体可以看下面的实例。

2.3.6、DEBUG COMPONENT
开启debug组件,可以看到solr 打分的详情,有助于排查一些诸如排序错误的问题。开启debug组件只用在请求参数增加debugQuery=true就可以了。
2.3.7 ADDING SPELLCHECK AS A LAST-COMPONENT
后续再介绍
3、Managing searchers
solrconfig.xml中
3.1 New searcher overview
searcher是solr处理query的组件,solr中只有一个active 的searher。这个active searcher 拥有所有lucene索引的只读快照,如果提交一个新的doc到solr,这个doc在当前这个searcher中是不可见的。那么如何才能使得新提交的doc可见呢?solr的解决方案是关闭当前的searcher,新开一个searcher,新的searcher拥有新提交的doc的索引的只读快照。这就是solr commit的需要做的一部分工作(每个commit都要new 一个searcher)。
当进行一次commit之后,在旧的searcher上还有未执行完的查询,所以旧searcher的销毁是在其上面搜有查询执行完才执行的。销毁旧的searcher的时,其上面所有的缓存也都会被删除(因为原有的缓存都是基于旧的索引快照的,commit之后索引是有更新的,所以旧的缓存也应该是要失效的)。
而生成新的searcher需要执行一些计算(如重新计算缓存),所以生成新的searcher是代价比较耗时的操作。为了不对用户的查询产生影响,solr采用的后台生成新的searcher的方式,当新的searcher就绪之前,旧的searcher一直是提供查询的,直到新的searcher 预热完毕。

3.2、Warming a new searcher
预热新的searcher有两种方式:通过旧的cache自动预热新的cache、执行cache预热的查询。下一节会详细介绍自动预热。
这里先看一下执行cache预热的查询的配置。通过配置一个listener,当newSeacher事件发生时,会执行queries里面的查询用来预热缓存。配置成预热的query一般都是应用最频繁的查询,配置queries不能过多,过多会造成预热的时间太久,耗费太多服务器的资源。

这种预热方式方式一个很有用的场景是solr服务启动first searcher的预热,配置first searcher的预热,只需要将上面的event="firstSeacher"就行了。solr判断事件是firstSeacher是根据当前Seacher是否是null判断的,如果当前seacher是null则为firstSearcher。
searcher预热还有两个重要的配置标签useColdSearcher和maxWarmingSearchers
<useColdSearcher>falseuseColdSearcher>,当配置为true的时候,不等新的searcher预热完毕就直接使用,而配置为false的时候,就是等到新的searcher预热完才会使用
<maxWarmingSearchers>2maxWarmingSearchers>, 配置同时预热的searcher数量,如果searcher预热的时间过长,commit又比较频繁的话,会导致同时有多个searcher在预热。如果同时预热的数量超过配置的参数,之后的commit就会报错,如果经常出现报错,就需要考虑是否这个值设置的不合理或者预热时间过长。solr默认配置的是2。
4、cache management
4.1、cache fundamentals
- cache 大小
- 命中率与缓存踢除
- 缓存失效
- cache预热
4.2、filter cache
4.3、Query result cache
4.4、Document cache
4.5、Field value cache
5、Summary
上面只是介绍了solrconfig.xml的一部分常用的配置,solrconfig.xml里面有大量的详细注释,可以通过查看solrconfig.xml 的配置文件的了解其他的一些配置,如配置返回格式、如何定义一个新的search handler、生产环境调优等。