letswave教程:脑电数据的时频分析/组平均与统计分析
letswave教程:脑电数据的时频分析/组平均与统计分析
- 1 相关概念
- 2 单被试分析
- 2.1 时频分析
- 2.1.1 连续小波变换
- 2.1.2 基准线校正
- 2.1.3 查看结果
- 3 组分析
- 3.1 总体平均
- 3.1.1 降低采样率
- 3.1.2 重命名
- 3.1.3 数据集复制和合并
- 3.1.4 平均
- 3.1.5 查看结果
- 3.2 统计分析
- 3.2.1 假设驱动
- 3.2.2 数据驱动
- 3.2.2.1 逐点T检验
- 3.2.2.2 基于群集的置换测试


Hello,
这里是行上行下,我是喵君姐姐~
上一期,我们学习了如何用Letswave进行数据的预处理和ERP分析,包括letswave7的安装、数据集导入;预处理中常用的几种降噪方法;ICA分解;ERP分析。
这一期,我们就来教大家学习如何用Letswave对单个主题进行时频分析以及对多个主题进行平均和统计分析。
下一期,将进行图形生成和脚本处理,还请持续关注我们,敬请期待哟~
1 相关概念
首先,我们接着上一期内容继续对单主题进行分析。时频分析描述了非平稳EEG信号随时间增加在频域上的变化。Letswave7提供了两种时频分析方法,分别是STFT(短时傅立叶变换)和CWT(连续小波变换)。
STFT的原理是:把整个时域过程分解成无数个等长的小过程,每个小过程近似平稳,再进行傅里叶变换,便可得到某个时间点出现的频率。
CWT的原理是:将傅里叶变换中无限长的三角函数基换成有限长的会衰减的小波基。这样不仅能够获取频率,还可以定位到时间。
具体连续小波变换和短时傅里叶变换的区别,请见:傅里叶分析和小波分析的通俗含义。
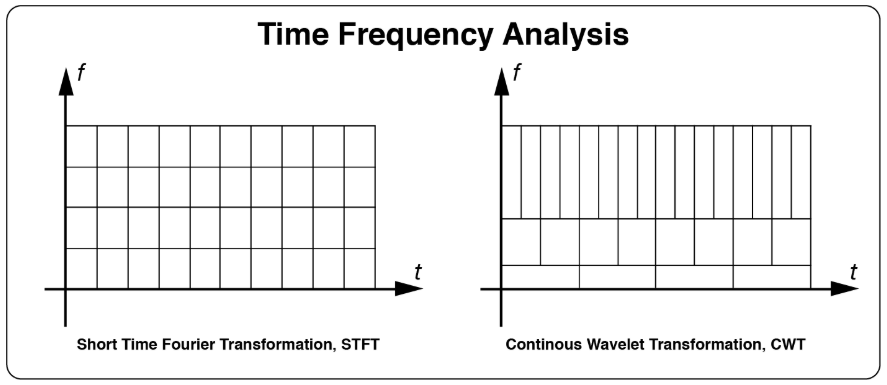
通常,我们可以在时域平均之前或之后进行时频分析。对于在时域平均之前的时频分解,可以观察到非锁相活动,但信号会产生更多的噪声。时域平均后的时频分解通常具有较好的信号噪声比,但会丢失非锁相活动。
2 单被试分析
2.1 时频分析
2.1.1 连续小波变换
在这里,我们将展示在时域平均之前,使用CWT进行时频分析。
首先,选择数据集 “bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093” 和 “bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093”,然后在菜单中单击"Plugins-> my_tfa-> Averaged CWT"。
其次,将dafault参数设置保留在批处理模块中,然后单击批处理模块底部的 “Run” 按钮以进行时频分析。

最后,名称为 “avg cwt bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093” 和 “avg cwt bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093” 的两个新数据集将出现在管理器模块的数据列表中。

由于时频分析非常耗时,并且还需要较大的存储空间,因此内存较小的计算机很容易出现“内存不足”的错误。因此,上述步骤实际上是将时频分析和求平均的步骤结合在一起,以节省存储空间。
2.1.2 基准线校正
在进行时频分析之后,我们还需要对时频域进行基线校正。
首先,选择数据集 "avg cwt bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093 ” 和 “ avg cwt bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093”,然后在菜单中单击 “Process- >Baseline corrections->Baseline correction ”。

其次,建议在时频域中缩小基线校正的间隔。因此,我们将基准设置为 -0.75 到 -0.25s 。在时频域中,可以使用几种方法(例如减法,ER百分比,除法和 z分数)作为基线校正。在这里,我们使用默认方法减法。单击批处理模块底部的 “Run” 按钮以进行基线校正。

最后,名称为 “bl avg cwt bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093” 和 “bl avg cwt bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093” 的两个新数据集将出现在管理器模块的数据列表中。

2.1.3 查看结果
首先, 选择数据集 “bl avg cwt bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093” 和 “bl avg cwt bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093”。单击右键菜单中的View,我们可以在多视图器中查看波形的时频域结果。
其次,同时选择两个数据集,选择通道Pz,并将颜色范围设置为 -10 至 10;打开topograph并将cursor设置为x = 0.35,y = 3,我们可以观察到topograph上的锁相P300活动。
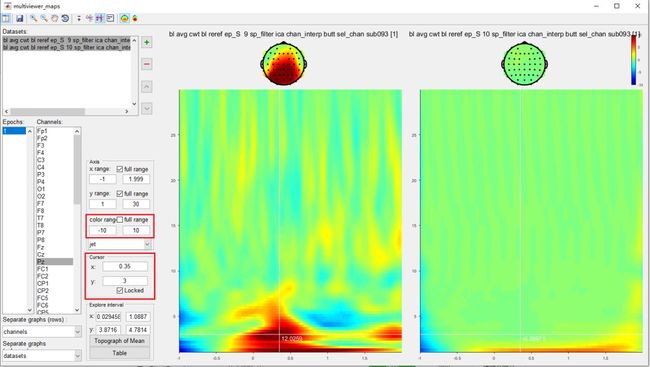
另外,将cursor设置为x = 1,y = 4,可以观察到事件相关去同步(ERD)活动,这是非锁相响应。
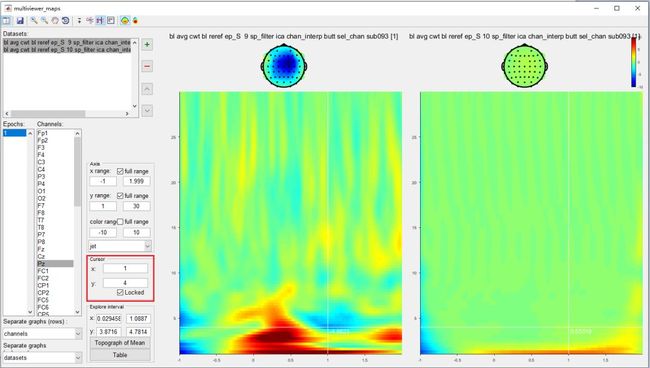
到目前为止,我们已经完成了分析单个被试时频分析的教程。
3 组分析
3.1 总体平均
3.1.1 降低采样率
考虑到要上传和下载的示例数据集的大小,我们将数据集的采样范围从1000Hz降至250Hz。
首先,选择数据集 “ avg bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093 ” 和 “ avg bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093 ” ,然后选择 “ Edit->Resample Signals->Downsample signals(integer radio)” 。

其次,在批处理模块中,将向下采样率设置为4。单击按钮 “Run” 以进行向下采样。
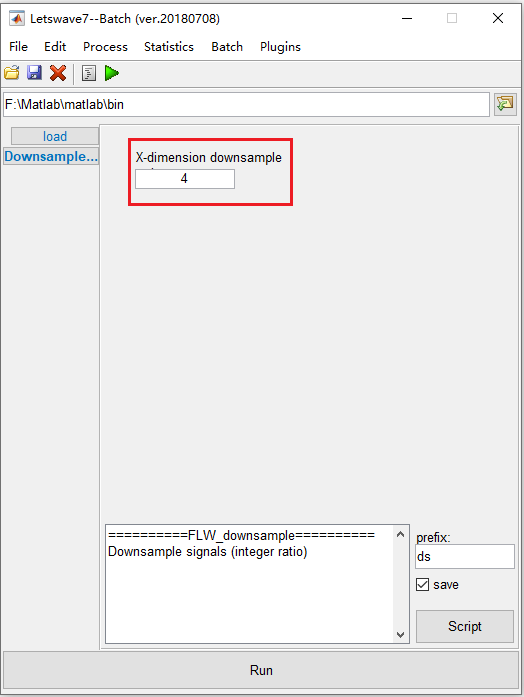
最后,名称为 “ds avg bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093” 和 “ds avg bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093” 的两个新数据集将出现在管理器模块的数据列表中。
3.1.2 重命名
在单个被试的分析中,对于每个步骤,将使用前缀生成新的数据集。虽然包含了基本信息,但名称过于冗长。因此,在进行组分析之前,我们需要重命名数据集。
首先,选择数据集 “ ds avg bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093 ”,在右键单击的菜单中按 Rename。将数据集 “ ds avg bl reref ep_S 9 sp_filter ica chan_interp butt sel_chan sub093 ” 重命名为 “ Sub093 P300 target ”。

同样,将数据集 “ avg bl reref ep_S 10 sp_filter ica chan_interp butt sel_chan sub093 ” 重命名为 “ Sub093 P300 nontarget ”。
3.1.3 数据集复制和合并
对于组分析,我们需要将时域分析结果复制到新文件夹中。例如,文件夹rawdata2中的数据集是所有93个被试的时域分析结果。解压缩 rawdata2.zip 文件,在93 * 2文件中有93个数据集。
在单个被试的分析中,结果是针对目标和非目标时期的所有试次的平均值。对于组分析,我们首先需要将93个被试的数据集合并为一个数据集,其中新数据集中的每个被试都被视为一个epoch。
首先,在管理器模块左侧的Include列表框中选择标签 “ nontarget ”,然后在管理器模块右侧的数据集列表框中选择所有数据集。选择 “Edit->Arrange signals->Merge dataset epochs,channels,indexes”。

其次,将默认设置保留在批处理模块中,然后单击 “ Run ” 按钮以在非目标条件下合并所有选定的数据集。
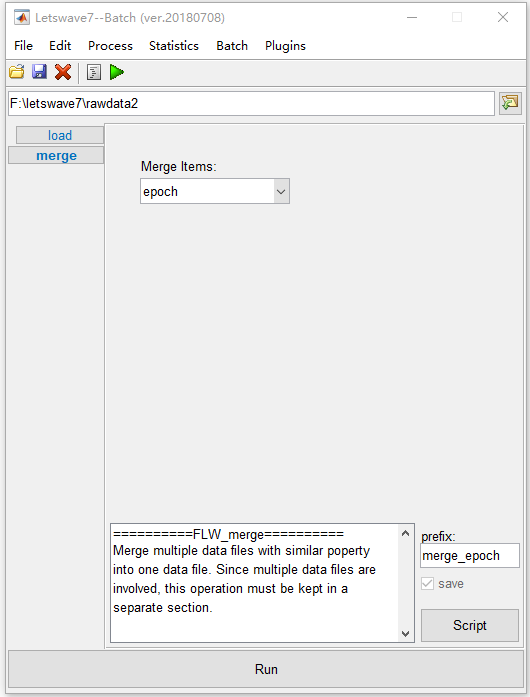
以同样的方式,我们可以在目标条件下合并所有数据集,从管理器模块左侧的Include列表框中选择标签 “ target ” 。
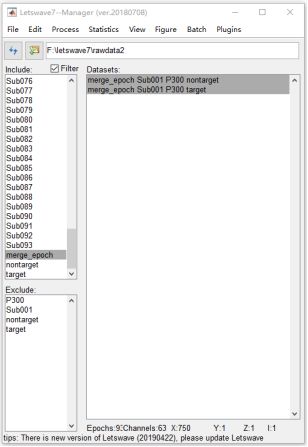
最后,产生两个新的数据集, “ merge_epoch Sub001 P300 nontarget ” 和 “ merge_epoch Sub001 P300 target ”,每个都有93个epoch,其中包含93个被试在“ target”和“ nontarget”条件下的时域分析结果。
3.1.4 平均
首先,在管理器模块左侧的Include列表框中选择标签 “ merge_epoch ”,然后在管理器模块右侧的数据集列表框中选择所有数据集。与单个被试的平均操作类似,选择 “Process->Average->Compute average,std,median across epochs”。
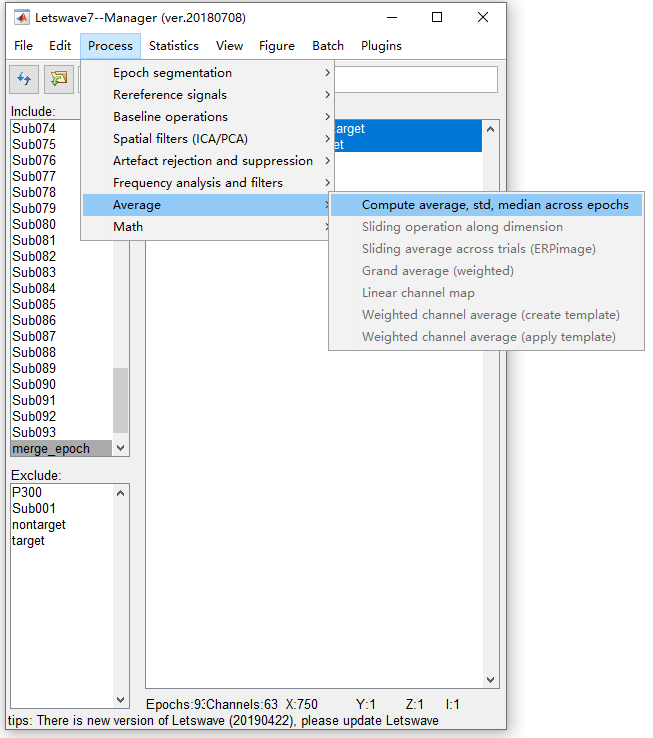
其次,将默认设置保留在批处理模块中,然后单击 “ Run ” 按钮以对两个数据集中的所有epoch进行平均,这实际上是在目标和非目标条件下对所有主题进行的总和。
最后,两个名为 “ avg merge_epoch Sub001 P300 nontarget ” 和 “ avg merge_epoch Sub001 P300 target ” 的新数据集”将出现在管理器模块的数据列表中。

3.1.5 查看结果
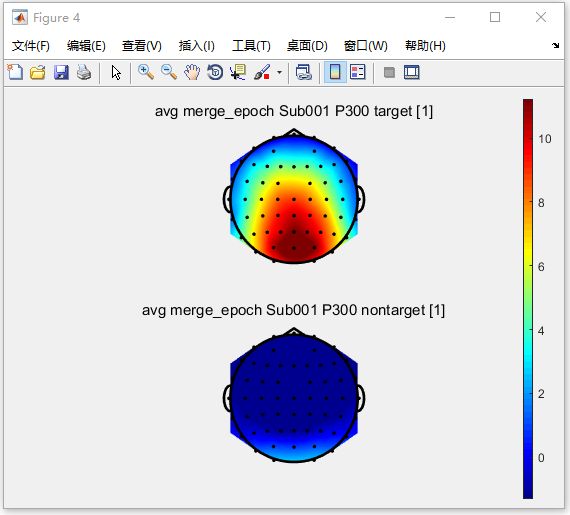
首先,要查看总体平均值的结果,请选择两个数据集 “ avg merge_epoch Sub001 P300 nontarget ” 和 “ avg merge_epoch Sub001 P300 target ”,然后在右键菜单中单击 View。

其次,在波形的多画面查看器中,选择通道Pz,以与单个主题相同的顺序查看结果,我们需要更改数据集的顺序。选择数据集 “ avg merge_epoch Sub001 P300 target ”,然后单击 “dataset” 按钮。

接着,选择两个数据集,然后启用工具栏中的 enable interval selection 按钮。选择 0.2 至 0.7s 的间隔参数。
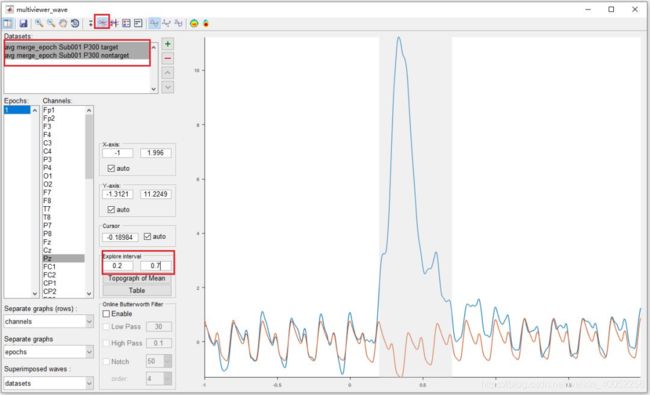
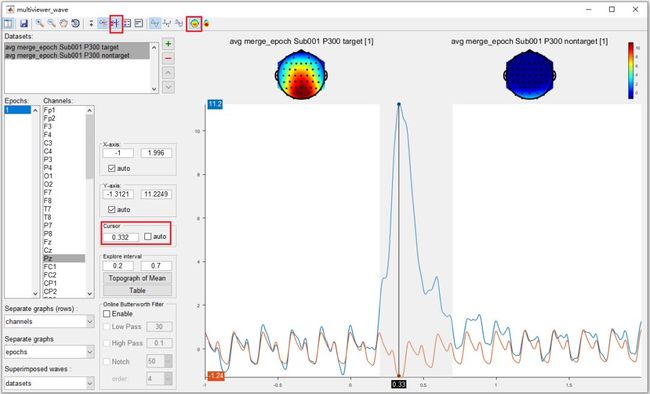
然后,单击 “ Table ” 按钮,弹出用于统计最大值、最小值和平均值的表格,其中我们发现P300的峰值为11.22 µV,发生时间在332ms。

最后,在工具栏中将 cursor 位置设置为0.332。打开topograph。在目标和非目标条件下,P300的峰值时间点都可以看到P300实验的总体平均分布。
3.2 统计分析
有两种进行统计推断的方法,分别是假设驱动和数据驱动。
通常在P300分析中使用假设驱动,我们根据对数据的观察或先前的经验提出一个假设,例如假设从预定间隔0.2到0.7s的ERP的最大值或平均值在目标和非目标条件之间有所不同。
因此,我们将进行特定数量的t检验或ANOVA来检验该假设。假设驱动是基于EEG分析探索神经心理学机制的有效方法。但是,在假设驱动的方法中,结果在很大程度上取决于研究人员的主观经验。
数据驱动通过比较详尽的时间、频率和空间点上的ERP,为EEG分析提供了更为客观的方法。此外,逐点分析可以准确说明发生效果的时间和地点。但是,随着数据驱动中假设检验数量的急剧增加,我们必须面对多重比较问题中的 Family-Wise错误率(FWER)。
3.2.1 假设驱动
在本文中,我们通过以下假设显示了统计推断:
在目标条件和非目标条件下,ERP在通道Pz处从预定间隔0.2到0.7s的最大值或平均值会有所不同。( PS: 常常根据波形图选时间窗口,地形图选点,以及前人文献共同参考)
对93名受试者进行配对样本t检验。因此,对于目标和非目标条件,我们首先需要在通道Pz的0.2s至0.7s区间内获取最大值和平均值。
首先, 选择数据集 “merge_epoch Sub001 P300 nontarget ” 和 “ merge_epoch Sub001 P300 target ”,然后单击右键菜单中的View。
其次,在多画面的波形中,选择数据集 “merge_epoch Sub001 P300 target” 和通道的 Pz ,设置叠加波为 epochs,打开 enable interval selection,设定Explore interval为0.2至0.7s。

接着,按下 “Table” 按钮,我们可以在表格中获得最大值和平均值的统计信息,并将这些数据复制到外部软件(例如Excel或SPSS),以进行以下统计分析。
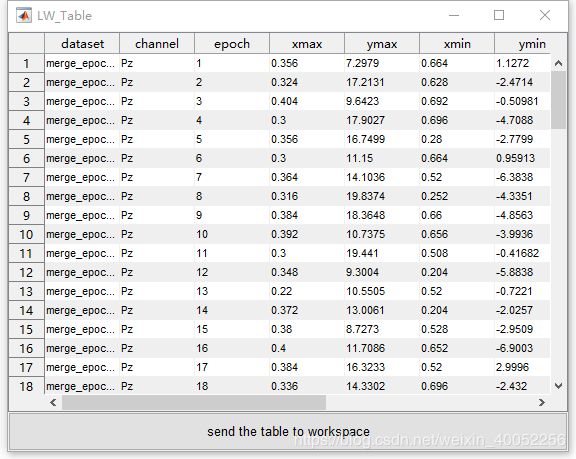
同样,选择数据集 “ merge_epoch Sub001 P300 nontarget ”,然后按 “Table” 按钮,在另一个数据集上拾取相同的值,并将其复制到外部软件。

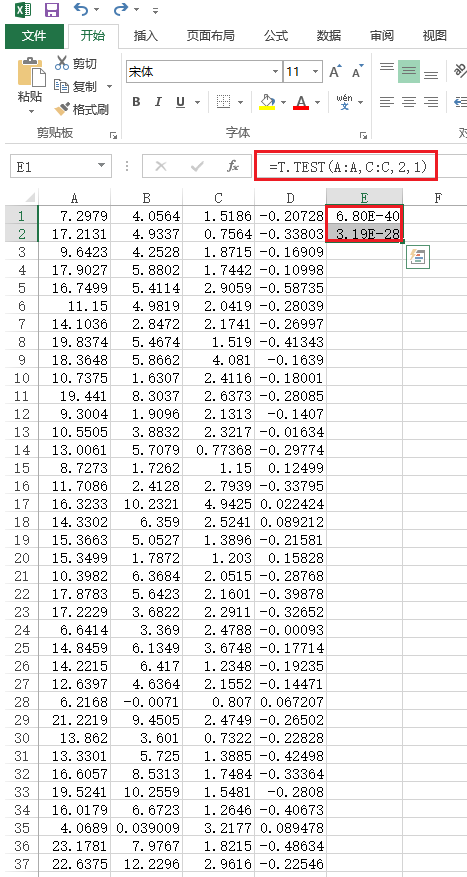
最后,我们可以进行统计推断。以软件Excel为例。将目标条件下的最大值和平均值复制到A和B列,将非目标条件下的最大值和平均值复制到C和D列。
在E1项中,输入 “ = T.TEST(A:A,C:C,2,1)” 表示配对样本t检验的最大值。结果p = 6.80 * 10 ^ -40表示,对于通道Pz上0.2至0.7 s间隔内的EEG信号最大值,目标和非目标条件之间存在显著差异。
类似地,在项E2中输入 “ = T.TEST(B:B,D:D,2,1)” ,以对平均值进行配对样本t检验。结果p = 3.2 * 10 ^ -28 表示对于通道Pz上0.2至0.7 s的EEG信号平均值,目标和非目标条件之间存在显著差异。
3.2.2 数据驱动
3.2.2.1 逐点T检验
对于数据驱动的测试,我们需要对每个时间通道点进行t检验,这将导致严重的多重比较问题。(PS: 不过这个也是一种可以快速找到时间窗的方法)
例如,首先,选择数据集 “ merge_epoch Sub001 P300 nontarget ” 和 “ merge_epoch Sub001 P300 target ”,然后单击 “ Process->Compare two datasets (paired sample/ two sample t-test)”。
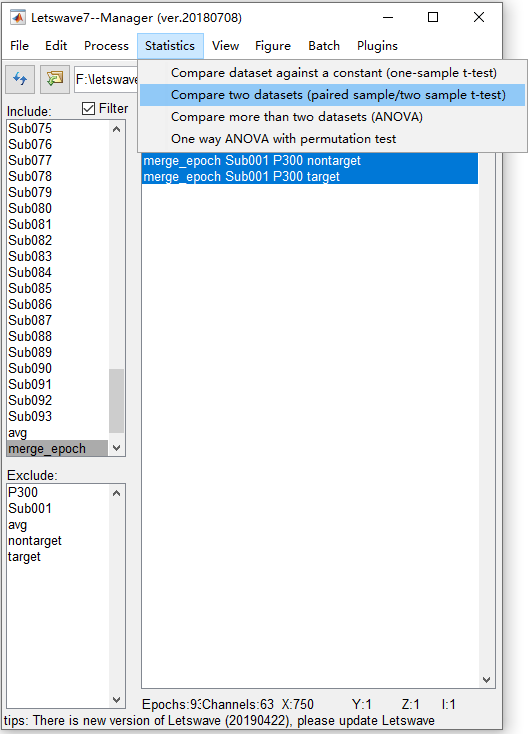
然后,将dafault设置保留在批处理模块中,单击 “Run” 按钮以在管理器模块中获取逐点ttest结果 “ ttest merge_epoch Sub001 P300 target ”。

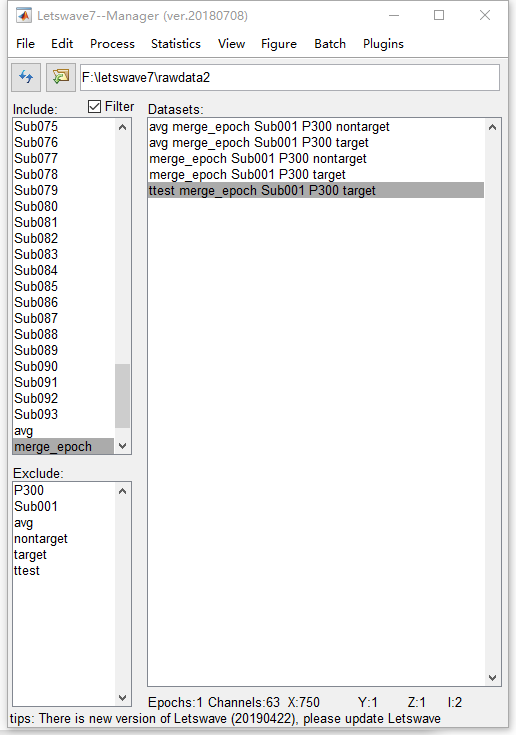
最后,单击右键菜单中的View在Pz通道上观看结果,我们将Index设置为p-value。由于我们将有效水平设置为α= 0.05,因此我们可以将Y轴设置为0到0.05,以观察p值小于0.05的间隔。
可以发现,除了大约0.2-0.7秒的主要簇以外,在其他时间间隔内甚至在刺激之前还存在几个簇。因此,显然FWER很高。由于测试中有750个时间点和63个通道,因此通过Bonferroni方法校正的α值为0.05 / 750/63 = 10 ^ -6。
3.2.2.2 基于群集的置换测试
基于以上结果,我们需要运用多重比较校正进行基于群集的置换测试。Letswave7提供了两种基于群集的置换测试的方法,即单传感器分析和多传感器分析。
单传感器分析
对于基于群集的置换测试,我们可以分别检测每个通道的群集。
首先,在逐点t检验中,选择数据集 “ merge_epoch Sub001 P300 nontarget ” 和 “ merge_epoch Sub001 P300 target ”,然后单击 “ Process->Compare two datasets (paired sample/ two sample t-test)”。
其次,为了获得更精确的结果,将置换数设置为20000,这将使计算变得很耗时。单击 “ Run ” 按钮,此过程需要10分钟以上的时间。
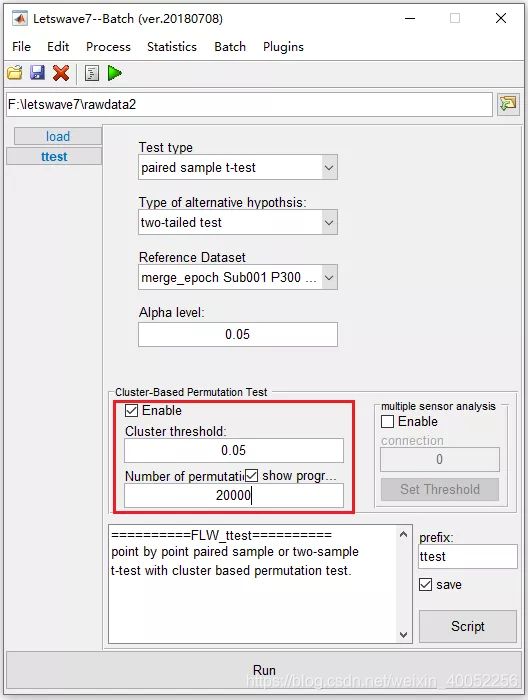
然后,结果将以相同的名称 “ ttest merge_epoch Sub001 P300 target ” 保存在数据集中。
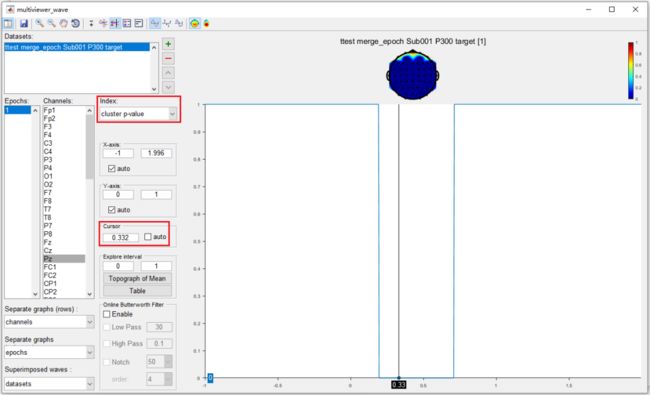
最后,通过单击右键菜单中的View,打开数据集 “ ttest merge_epoch Sub001 P300 target ” 。未校正的结果与逐点t检验中的结果完全相同。将Index设置为 “ cluster p-value ”,并将cursor设置为0.332,这是P300的峰值。
可以发现,在基于群集的置换测试之后,仅保留了通道Pz上的主群集,其他群集均被排除。
多传感器分析
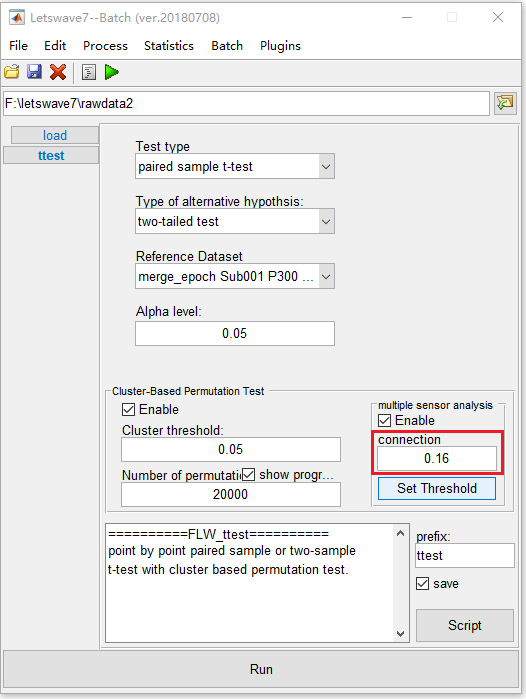
首先,选择数据集 “ merge_epoch Sub001 P300 nontarget ” 和 “ merge_epoch Sub001 P300 target ”,然后单击 “Process->Compare two datasets (paired sample/ two sample t-test)”。并将置换数设置为20000。
对于多传感器分析,我们将阈值设置为0.16。单击 “ Run ” 按钮,计算可能需要1个小时以上。
然后,具有相同名称 “ ttest merge_epoch Sub001 P300 target ” 的结果将覆盖原始数据集。

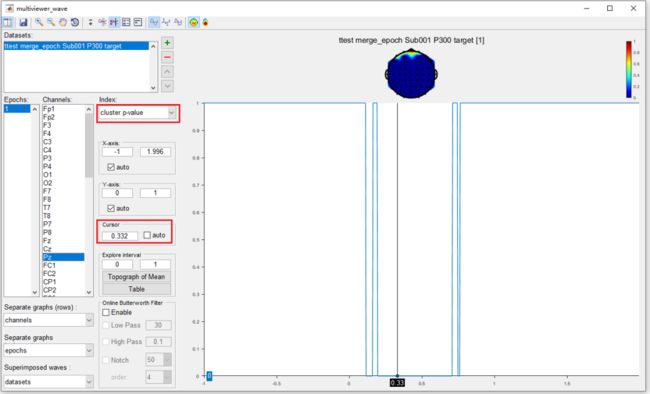
最后,用相同的方法在单传感器分析中观察结果。可以发现,在信道Pz上保留了更多的时间间隔。这是因为在时空联合域中,它们被视为同一群集。
总结:到目前为止,我们已经展示了从数据导入,单个被试和组的ERP以及时频分析,最后到统计分析的整个过程。
PS: 本文首发于公众号 行上行下 ,公众号后台回复 “Letswave” 可获得安装包、原文教程以及其他资料等内容。
在接下来的一期中,我们将介绍图形生成和脚本处理,希望您能够持续关注,感谢你的支持哟~
