Tensorflow:EEG上CNN的一次实验
一次失败的CNN实现
- 前言
- 简介
- 数据
- CNN网络
- 模型调整
- 减少过拟合的尝试
- 与全连接网络比较
- 与SVM网络比较
- 模型运用到其他分类标准
- 结果分析
- 代码
- CNN网络代码
- 交叉验证代码
- FC网络代码
- SVM网络代码
前言
- 这是一次较为“失败”的分类器尝试,在本次报告中尝试实现了CNN模型对EEG图像进行学习,进行了大量调参的尝试,并在二分类问题上与其他简单模型进行比较
- 使用python tensorflow(vision=1.13.0)
- 最好的试验中测试集的准确率超过80%,但是由于测试集的选取原因这个数字没有很好的说服力,并不能说明在那个参数下模型有很好的泛化能力(见正则化)
- 虽然结果并不好,但在大量的学习中对机器学习的基本框架和如何调整参数有个更好的理解,本次报告中的CNN及其他网络也能很好地移植到其他问题当中
简介
数据
- 由于EEG的五个电极的数据存在一定的相关性,因此考虑用CNN模型来保持一定的结构。由于数据集中的EEG图较小,我们考虑将每个160为数据转化为5x32的数据进行卷积操作。
CNN网络
- 原因
- 相关的学术研究中也有用CNN对EEG数据进行学习的研究,但他的数据集,每个数据的维度均比我们大,也有尝试用3维CNN网络训练EEG数据的成功例子
- 先对DEEP库愉悦度进行学习(二分类)
- 网络结构
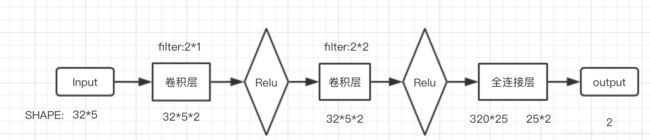
选择模型参数较小的原因是数据量小,实验结果表明可能过拟合。 - 使用的库
//使用的库
import tensorflow as tf #机器学习库
import numpy as np #python基本库
from matplotlib.pyplot import * #画图
import random #用于添加噪声
- 数据处理
对数据进行中心化和标准化,减少极端数据的影响,提高模型的泛化能力
// data 中心化和标准化
def MaxMinNormalization(x):
x=np.transpose(x)
return np.transpose(np.array([(x[i] - np.average(x[i]))/np.std(x[i]) for i in range(x.shape[0])]))
train_data=MaxMinNormalization(train_data)
模型调整
我们将前1000个作为训练集,后216个作为测试集进行训练来粗略地确定一些参数
- 损失函数选择
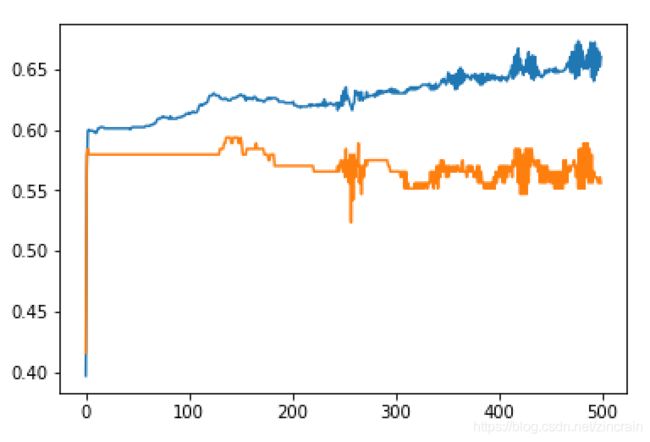
我们在均方误差和交叉熵中选择,在梯度下降的情况下训练1000次。(优化器Adam)
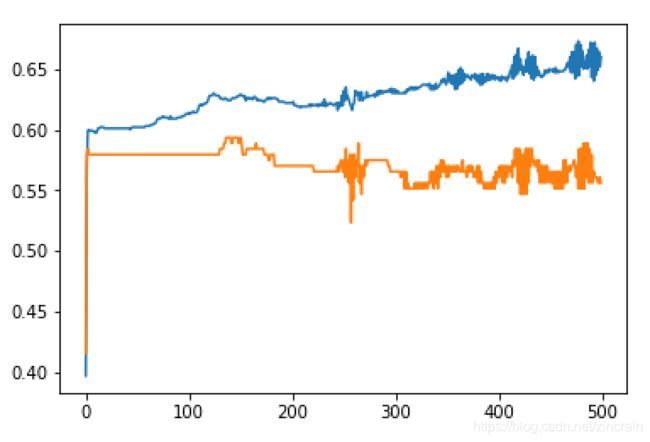 均方误差 均方误差
|
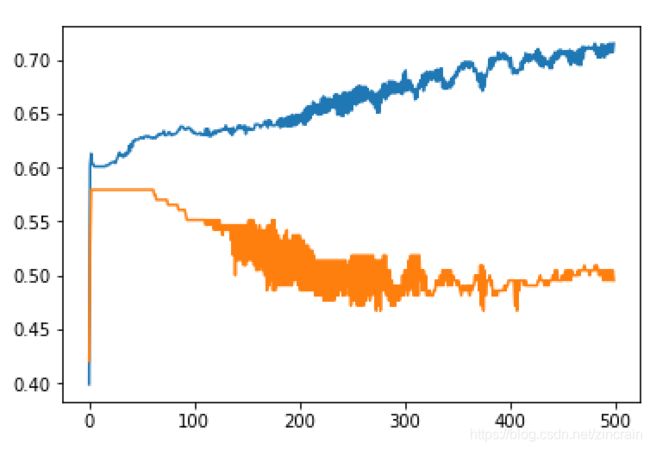 交叉熵 交叉熵
|
可以看出交叉熵的收敛速度要快于均方误差,虽然交叉熵更容易遇到过拟合问题,在测试集上准确率下降。但考虑到计算能力及大量尝试发现两者并无在调好参数后并无太大差别,最后测试中我们选择用交叉熵来加快学习。
- 优化器和学习率选择:
Tensorflow中提供了很多优化器的算法,我们选择了一些优化器进行测试,针对学习率1.0 0.1 0.01……中取最好的结果,由于时间和的计算能力的限制,我们每个只训练500次,选取一开始收敛最快的算法(学习率过小会训练缓慢,过大会导致最后震荡不收敛,我们选择较大的学习率但又控制最后的震荡幅度)
 梯度下降 梯度下降
|
 Adam Adam
|
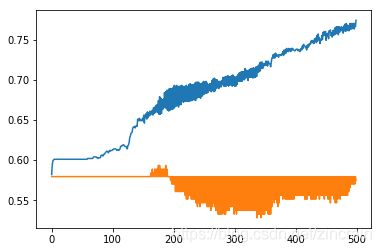 AdagradOptimizer AdagradOptimizer
|
- 增加池化层:
h_pooli=max_pool_2x2(h_convi)
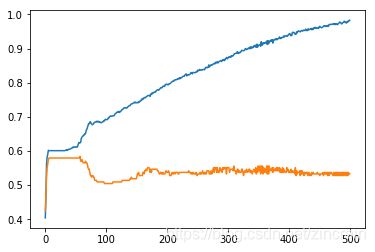
可以看出如果数据库的数据是良好的,那么我们认为我们的模型存在严重的过拟合问题(高方差),我们尝试用各种方法来减小方差
减少过拟合的尝试
- dropout
对于全连接层采取dropout方法,训练1000次
// 采用新tf中的keep_prob
keep_prob=tf.placeholder(tf.float32)
drop=1-keep_prob
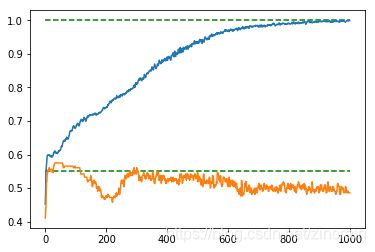 dropout=1.0 dropout=1.0
|
 dropout=0.75 dropout=0.75
|
 dropout=0.5 dropout=0.5
|
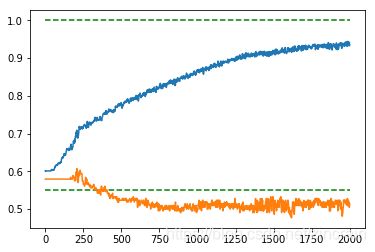 dropout=0.5 dropout=0.5
|
可以看出dropout在0.75左右的时候可以减少过拟合并保持较快的收敛效果
- 正则化
采取L2正则,取不同数量级的lambda,采用cross validation来选取最好的(dropout=0.75)将1216个数据分为8个组,每组152个,输出平均的训练集和测试集上的正确度。交叉验证的代码见后
// L2 regulation
tf.contrib.layers.l2_regularizer(lambda)(W)
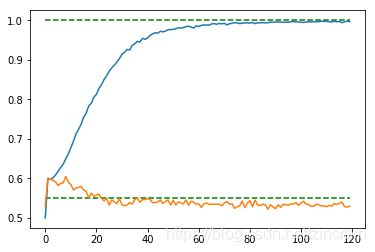 lambda=.01(x=train_step/25) lambda=.01(x=train_step/25)
|
 lambda=.015(x=train_step/25) lambda=.015(x=train_step/25)
|
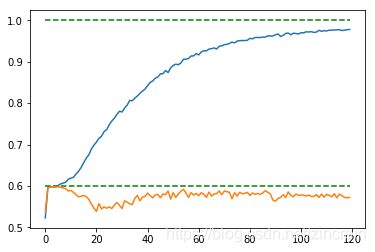 lambda=.02(x=train_step/25) lambda=.02(x=train_step/25)
|
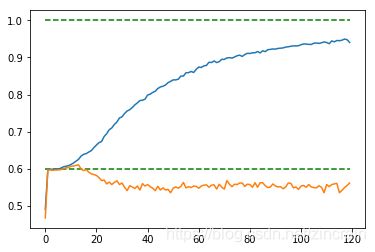 lambda=.25(x=train_step/25) lambda=.25(x=train_step/25)
|
 lambda=.03(x=train_step/25) lambda=.03(x=train_step/25)
|
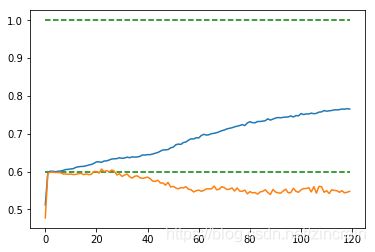 lambda=.035(x=train_step/25) lambda=.035(x=train_step/25)
|
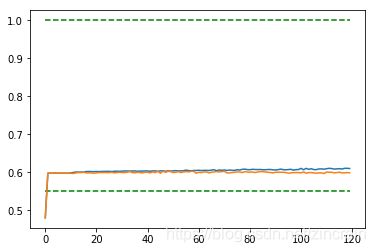 lambda=.05(x=train_step/25) lambda=.05(x=train_step/25)
|
- 最后我们加上千分之2的正态噪声,进行训练
//add noise
rand=np.random.randint(0,high=1000, size=500)
noise=np.random.normal(0,1/500,[1216,160])
train_data_noised=np.add(train_data,noise)
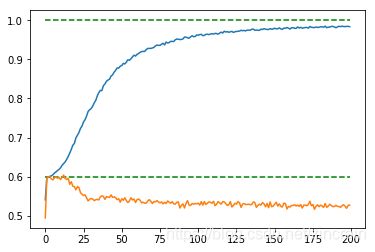 交叉验证 交叉验证
|
 最好的 最好的
|
 最差的 最差的
|
可见不同的验证集所需要的参数相差较大,这可能是因为我们没有对样本做最佳的预处理(按人平均没有更好的效果),或许在某些分类情况下能很较好地学习,但在平均意义下这个模型不能很好地预测该二分类问题
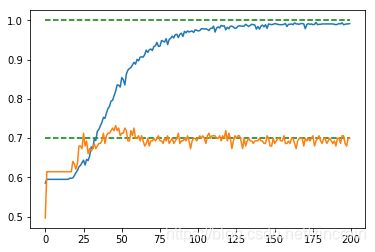
与全连接网络比较
-
全连接网络
我们使用两个隐层的四层全连接网络与我们的模型进行比较,隐层的节点个数通过 n i = n i − 1 ∗ n i + 1 n_{i}=\sqrt{n_{i-1}*n_{i+1}} ni=ni−1∗ni+1来确定(一个简单的确定较好的节点个数的方法) -
故第一个隐层36个节点,第二个隐层9个节点

总体来说CNN的效果比全连接稍好,
全连接的正则化较难调整
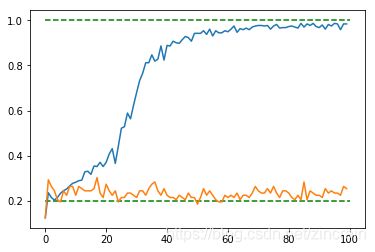
与SVM网络比较
- 由于数据相近,及时在某一数据分类下用SVM获得较好的拟合,一旦改变数据分割,在测试集上的准确度也会快速下降。
- 代码见下节
模型运用到其他分类标准
对MAHNOB-HCI库中的EEG_emotion_category进行9分类
运用CNN代码简单地更改参数即可
//生成label集合
def switch(var):
return{
0.0:np.eye(9)[0],
1.0:np.eye(9)[1],
2.0:np.eye(9)[2],
3.0:np.eye(9)[3],
4.0:np.eye(9)[4],
5.0:np.eye(9)[5],
6.0:np.eye(9)[6],
11.0:np.eye(9)[7],
12.0:np.eye(9)[8],
}.get(var,'error')
train_label=np.array([])
for i in range(533):
train_label=np.append(train_label,switch(label[i]),axis=0)
train_label=train_label.reshape([-1,9])
结果分析
- 整体的训练效果不佳,原因可能有三
- CNN计算开销过大,确定交叉验证非常粗糙,并且其余多个变量之间基本是单一改变确定的,因此若调参时间较长可一定程度上提高准确率
- 缺乏EEG相关知识和数据库的了解,可能缺少对数据的处理或是随机的裁剪
- 从训练结果可知若是大量增加训练集合可能会有更好的效果,尤其是在数据较小的时候,并不是非常适合采用CNN,相反采用GANS等模型可能结果更好
代码
CNN网络代码
// CNN network
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 2 17:14:27 2019
@author: rain
"""
import tensorflow as tf
import numpy as np
from matplotlib.pyplot import *
import random
#读取数据
#data
train_data=np.loadtxt("/Users/rain/Downloads/EEG/DEAP/EEG_feature.txt")
#label
train_label=np.loadtxt("/Users/rain/Downloads/EEG/DEAP/valence_arousal_label.txt")
train_label=np.transpose(train_label)
#将label转换成类别矩阵
train_label=np.transpose([2 - train_label[1],train_label[1] - 1])
#data 中心化
def MaxMinNormalization(x):
x=np.transpose(x)
return np.transpose(np.array([(x[i] - np.average(x[i]))/np.std(x[i]) for i in range(x.shape[0])]))
train_data=MaxMinNormalization(train_data)
#
learning_rate=1e-3
n_input=160
n_classes=2
#占位符
x_=tf.placeholder(tf.float32,[None,n_input])
y_=tf.placeholder(tf.float32,[None,n_classes])
x=tf.reshape(x_, [-1,32,5,1])
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev = 0.2)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1],padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize = [1,2,2, 1],strides = [1,1,1, 1], padding='SAME')
keep_prob=tf.placeholder(tf.float32)
#建立网络
#卷积层1
W_conv1=weight_variable([2,2,1,2])
b_conv1=bias_variable([2])
h_conv1=tf.nn.relu(conv2d(x,W_conv1)+b_conv1)
h_pool1=max_pool_2x2(h_conv1)
#卷积层2
W_conv2 = weight_variable([2,2,2,2])
b_conv2 = bias_variable([2])
h_conv2 = tf.nn.relu(conv2d(h_conv1,W_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#全连接层
W_fc1 = weight_variable([2*32*5,25])
b_fc1 = bias_variable([25])
h_pool2_flat=tf.reshape(h_conv2, [-1,2*32*5])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1)
h_fc1_dropout=tf.nn.dropout(h_fc1,rate=1-keep_prob)
#输出层
W_fc2=weight_variable([25,n_classes])
b_fc2=bias_variable([n_classes])
y_conv=tf.matmul(h_fc1_dropout, W_fc2) + b_fc2
#训练和评估#
#均方误差MSE
#loss=tf.reduce_mean(tf.square(y_conv-y_))
#tf.contrib.layers.l2_regularizer(.001)(tf.concat([tf.reshape(W_conv1,[1,-1]),tf.reshape(W_conv2,[1,-1]),tf.reshape(W_fc1,[1,-1]),tf.reshape(W_fc2,[1,-1])],1))
#交叉熵
loss= tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
#优化器
#train_step=tf.train.GradientDescentOptimizer(.1).minimize(loss)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
#train_step = tf.train.AdadeltaOptimizer(1).minimize(loss)
#准确度
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y_,1),tf.argmax(y_conv,1)),tf.float32))
#训练
with tf.Session() as sess:
tf.global_variables_initializer().run()
train_accuracy_all=[]
test_accuracy_all=[]
train_loss_all=[]
test_loss_all=[]
#rand=random.sample(range(1216),215)
for i in range(2000):
train_loss=loss.eval(feed_dict={x_:train_data[0:1000],y_:train_label[0:1000],keep_prob:1.})
train_accuracy=accuracy.eval(feed_dict={x_:train_data[0:1000],y_:train_label[0:1000],keep_prob:1.})
train_accuracy_all.append(train_accuracy)
train_loss_all.append(train_loss)
test_loss=loss.eval(feed_dict={x_:train_data[1001:1215],y_:train_label[1001:1215],keep_prob:1.})
test_accuracy=accuracy.eval(feed_dict={x_:train_data[1001:1215],y_:train_label[1001:1215],keep_prob:1.})
test_accuracy_all.append(test_accuracy)
test_loss_all.append(test_loss)
if(i%25==0):
print(i)
# print('setp {},the train accuracy: {},the train MSE: {}'.format(i,train_accuracy,train_loss))
# print('setp {},the test accuracy: {},the test MSE: {}'.format(i,test_accuracy,test_loss))
#rand=np.random.randint(0,high=1000, size=500)
#add noise
#noise=np.random.normal(0,1/500,[1216,160])
#train_data_noised=np.add(train_data,noise)
train_step.run(feed_dict = {x_:train_data[0:1000],y_:train_label[0:1000],keep_prob:.25})
plot(train_accuracy_all)
plot(test_accuracy_all)
hlines(0.55,0,i,colors='green',linestyles="dashed")
hlines(1.0,0,i,colors='green',linestyles="dashed")
交叉验证代码
//cross validation
for j in range(8):
with tf.Session() as sess:
tf.global_variables_initializer().run()
train_accuracy_all=[]
test_accuracy_all=[]
train_loss_all=[]
test_loss_all=[]
#数据分块
train_data_s=np.append(train_data[:152*j],train_data[152*j+152:],0)
train_label_s=np.append(train_label[:152*j],train_label[152*j+152:],0)
if(j==0):
test_data=train_data[:152*j+152]
test_label=train_label[:152*j+152]
else:
test_data=train_data[152*j-1:152*j+152]
test_label=train_label[152*j-1:152*j+152]
for i in range(3000):
if(i%25==0):
train_loss=loss.eval(feed_dict={x_:train_data_s,y_:train_label_s,keep_prob:1.})
train_accuracy=accuracy.eval(feed_dict={x_:train_data_s,y_:train_label_s,keep_prob:1.})
train_accuracy_all.append(train_accuracy)
train_loss_all.append(train_loss)
test_loss=loss.eval(feed_dict={x_:test_data,y_:test_label,keep_prob:1.})
test_accuracy=accuracy.eval(feed_dict={x_:test_data,y_:test_label,keep_prob:1.})
test_accuracy_all.append(test_accuracy)
test_loss_all.append(test_loss)
if(i%200==0):
print('setp {},the train accuracy: {},the train MSE: {}'.format(i,train_accuracy,train_loss))
print('setp {},the test accuracy: {},the test MSE: {}'.format(i,test_accuracy,test_loss))
train_step.run(feed_dict = {x_:train_data_s,y_:train_label_s,keep_prob:.75})
if(j==0):
train_accuracy_all_v=np.copy(train_accuracy_all,order='C')
test_accuracy_all_v=np.copy(test_accuracy_all,order='C')
else:
train_accuracy_all_v=np.vstack([train_accuracy_all_v,train_accuracy_all])
test_accuracy_all_v=np.vstack([test_accuracy_all_v,test_accuracy_all])
plot_tarin=np.array([])
plot_test=np.array([])
train_accuracy_all_v=np.transpose(train_accuracy_all_v)
test_accuracy_all_v=np.transpose(test_accuracy_all_v)
for i in range(train_accuracy_all_v.shape[0]):
plot_tarin=np.append(plot_tarin,np.mean(train_accuracy_all_v[i]))
plot_test=np.append(plot_test,np.mean(test_accuracy_all_v[i]))
plot(plot_tarin)
plot(plot_test)
hlines(0.55,0,i,colors='green',linestyles="dashed")
hlines(1.0,0,i,colors='green',linestyles="dashed")
FC网络代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 5 23:08:39 2019
@author: rain
"""
import tensorflow as tf
import numpy as np
from matplotlib.pyplot import *
import random
#读取数据
#data
train_data=np.loadtxt("/Users/rain/Downloads/EEG/DEAP/EEG_feature.txt")
#label
train_label=np.loadtxt("/Users/rain/Downloads/EEG/DEAP/valence_arousal_label.txt")
train_label=np.transpose(train_label)
#将label转换成类别矩阵
train_label=np.transpose([2 - train_label[0],train_label[0] - 1])
#data 中心化
def MaxMinNormalization(x):
x=np.transpose(x)
return np.transpose(np.array([(x[i] - np.average(x[i]))/np.std(x[i]) for i in range(x.shape[0])]))
train_data=MaxMinNormalization(train_data)
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.2)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)
x_=tf.placeholder(tf.float32,[None,160])
y_=tf.placeholder(tf.float32,[None,2])
keep_prob=tf.placeholder(tf.float32)
learning_rate=tf.placeholder(tf.float32)
W_fc1 = weight_variable([160,36])
b_fc1 = bias_variable([36])
h_fc1=tf.nn.sigmoid(tf.matmul(x_,W_fc1)+b_fc1)
h_fc1_dropout=tf.nn.dropout(h_fc1,rate=1-keep_prob)
W_fc2 = weight_variable([36,9])
b_fc2 = bias_variable([9])
h_fc2=tf.nn.sigmoid(tf.matmul(h_fc1_dropout,W_fc2)+b_fc2)
h_fc2_dropout=tf.nn.dropout(h_fc2,rate=1-keep_prob)
W_fc3=weight_variable([9,2])
b_fc3=bias_variable([2])
y_out=tf.matmul(h_fc2_dropout,W_fc3)+b_fc3
#loss= tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_out))
loss=tf.reduce_mean(tf.square(y_out-y_))+tf.contrib.layers.l2_regularizer(.0002)(tf.concat([tf.reshape(W_fc1,[1,-1]),tf.reshape(W_fc2,[1,-1]),tf.reshape(W_fc3,[1,-1])],1))
#train_step=tf.train.GradientDescentOptimizer(.8).minimize(loss)
train_step = tf.train.AdamOptimizer(1e-3).minimize(loss)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y_,1),tf.argmax(y_out,1)),tf.float32))
with tf.Session() as sess:
tf.global_variables_initializer().run()
train_accuracy_all=[]
test_accuracy_all=[]
for i in range(20000):
if(i%150==0):
train_loss=loss.eval(feed_dict={x_:train_data[0:1000],y_:train_label[0:1000],keep_prob:1.})
train_accuracy=accuracy.eval(feed_dict={x_:train_data[0:1000],y_:train_label[0:1000],keep_prob:1.})
print('setp {},the train accuracy: {},the train MSE: {}'.format(i,train_accuracy,train_loss))
train_accuracy_all.append(train_accuracy)
#test_loss=loss.eval(feed_dict={x_:train_data[1001:1215],y_:train_label[1001:1215],keep_prob:1.})
test_accuracy=accuracy.eval(feed_dict={x_:train_data[1001:1215],y_:train_label[1001:1215],keep_prob:1.})
test_accuracy_all.append(test_accuracy)
#print('setp {},the test accuracy: {},,the test MSE: {}'.format(i,test_accuracy,test_loss))
noise=np.random.normal(0,1/1000,[1216,160])
train_data_noised=np.add(train_data,noise)
train_step.run(feed_dict = {x_:train_data_noised[0:1000],y_:train_label[0:1000],keep_prob:.8})
plot(train_accuracy_all)
plot(test_accuracy_all)
hlines(0.6,0,i/150,colors='green',linestyles="dashed")
hlines(1.0,0,i/150,colors='green',linestyles="dashed")
SVM网络代码
import tensorflow as tf
import numpy as np
from matplotlib.pyplot import *
import random
import time
#读取数据
#data
train_data=np.loadtxt("/Users/rain/Downloads/EEG/DEAP/EEG_feature.txt")
#label
train_label=np.loadtxt("/Users/rain/Downloads/EEG/DEAP/valence_arousal_label.txt")
train_label=np.transpose(train_label)
#将label转换成类别矩阵
train_label=np.reshape((2*train_label-3.0)[0],[-1,1])
# 初始化feedin
x_ = tf.placeholder(shape=[None, 160], dtype=tf.float32)
y_ = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# 创建变量
A = tf.Variable(tf.random_normal(shape=[160, 1]))
b = tf.Variable(tf.random_normal(shape=[1, 1]))
# 定义线性模型
model_output = tf.subtract(tf.matmul(x_, A), b)
# Declare vector L2 'norm' function squared
l2_norm = tf.reduce_sum(tf.square(A))
# Loss = max(0, 1-pred*actual) + alpha * L2_norm(A)^2
alpha = tf.constant([0.0])
classification_term = tf.reduce_mean(tf.maximum(0., tf.subtract(1., tf.multiply(model_output, y_))))
loss = tf.add(classification_term, tf.multiply(alpha,l2_norm))
accuracy=tf.reduce_mean(abs(model_output/np.abs(model_output)+y_)/2)
my_opt = tf.train.GradientDescentOptimizer(0.0001)
train_step = my_opt.minimize(loss)
for j in range(1):
with tf.Session() as sess:
tf.global_variables_initializer().run()
train_accuracy_all=[]
test_accuracy_all=[]
train_loss_all=[]
test_loss_all=[]
train_data_s=np.append(train_data[:152*j],train_data[152*j+152:],0)
train_label_s=np.append(train_label[:152*j],train_label[152*j+152:],0)
if(j==0):
test_data=train_data[:152*j+152]
test_label=train_label[:152*j+152]
else:
test_data=train_data[152*j-1:152*j+152]
test_label=train_label[152*j-1:152*j+152]
for i in range(100):
if(i%1==0):
y=y_.eval(feed_dict={x_:train_data_s,y_:train_label_s})
out=model_output.eval(feed_dict={x_:train_data_s,y_:train_label_s})
train_accuracy=accuracy.eval(feed_dict={x_:train_data_s,y_:train_label_s})
train_accuracy_all.append(train_accuracy)
#train_loss_all.append(train_loss)
test_accuracy=accuracy.eval(feed_dict={x_:test_data,y_:test_label})
test_accuracy_all.append(test_accuracy)
#test_loss_all.append(test_loss)
if(i%1==0):
train_loss=loss.eval(feed_dict={x_:train_data_s,y_:train_label_s})
test_loss=loss.eval(feed_dict={x_:test_data,y_:test_label})
print('setp {},the train accuracy: {},the train MSE: {}'.format(i,train_accuracy,train_loss))
print('setp {},the test accuracy: {},the test MSE: {}'.format(i,test_accuracy,test_loss))
train_step.run(feed_dict = {x_:train_data_s,y_:train_label_s})
if(j==0):
train_accuracy_all_v=np.copy(train_accuracy_all,order='C')
test_accuracy_all_v=np.copy(test_accuracy_all,order='C')
else:
train_accuracy_all_v=np.vstack([train_accuracy_all_v,train_accuracy_all])
test_accuracy_all_v=np.vstack([test_accuracy_all_v,test_accuracy_all])
plot_tarin=np.array([])
plot_test=np.array([])
train_accuracy_all_v=np.transpose(train_accuracy_all_v)
test_accuracy_all_v=np.transpose(test_accuracy_all_v)
for i in range(train_accuracy_all_v.shape[0]):
plot_tarin=np.append(plot_tarin,np.mean(train_accuracy_all_v[i]))
plot_test=np.append(plot_test,np.mean(test_accuracy_all_v[i]))
plot(plot_tarin)
plot(plot_test)
hlines(0.7,0,i,colors='green',linestyles="dashed")
hlines(1.0,0,i,colors='green',linestyles="dashed")