text to image(五):《StackGAN++》
继续介绍文本生成图像的相关工作,本文给出的是ICCV 2017 的文章《StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks》
论文地址:https://arxiv.org/abs/1710.10916
源码地址:https://github.com/hanzhanggit/StackGAN-v2
一、 相关工作
对GAN的相关理解:https://blog.csdn.net/zlrai5895/article/details/80648898
前作StackGAN的工作:http://blog.csdn.net/zlrai5895/article/details/81292167
二、 基本思想
与前作StackGAN相比,StackGAN v2有三点改进:
- 采用树状结构,多个生成器生成不同尺度的图像,每个尺度对应一个鉴别器。从而生成了多尺度fake images。
- 除了conditional loss,引入了unconditional loss。即不使用条件信息,直接使用服从标准正态分布的噪声z生成fake image的损失。
- 引入了color regulation,对生成的fake images 的色彩信息加以限制。
效果是提高了训练的稳定性,且提高了生成的图像质量。
三、 数据集
本次实验使用的数据集是加利福尼亚理工学院鸟类数据库-2011(CUB_200_2011)。
四、模型结构:
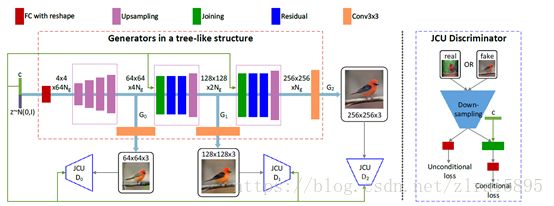
左侧是整体结构,右侧是使用的鉴别器模型。整个结构图还是比较清晰的。
可以看到图中有三个生成器和三个鉴别器。这里以batch_size=2为例进行解析并给出部分代码。
1、第一个生成器
ence经过预训练的编码器提取出text_embedding,和StackGAN中相同的处理得到c向量(可参考上文给出的StackGAN的博客)。c向量和z向量连接输入fully connected 层并reshape,经过一系列上采样层,得到64*64的fake_img1。
部分代码如下:
self.fake_imgs, self.mu, self.logvar =self.netG(noise, self.txt_embedding)
#输入z(#[2,100])和text_embedding([2,1024])if cfg.TREE.BRANCH_NUM > 0: #树状
h_code1 = self.h_net1(z_code, c_code)
#输入z:[2,100] c_code:[2,128] 输出:#[2,64,64,64]
fake_img1 = self.img_net1(h_code1)
#fake_img1:[2,3,64,64] 3*3卷积这样就是生成了64*64的图片。self.h_net1涉及到的部分代码:
def forward(self, z_code, c_code=None):
if cfg.GAN.B_CONDITION and c_code is not None:
in_code = torch.cat((c_code, z_code), 1)
#连接 输入c_code:[2,128] z_code:[2,100] 输出in_code:[2,228]
else:
in_code = z_code
# state size 16ngf x 4 x 4
out_code = self.fc(in_code)#全连接层 in_code:[2,228] out_code:[2,16384]
out_code = out_code.view(-1, self.gf_dim, 4, 4)# 输出:[2,1024,4,4]
# state size 8ngf x 8 x 8
out_code = self.upsample1(out_code) #输出:[2,512,8,8]
# state size 4ngf x 16 x 16
out_code = self.upsample2(out_code) #输出:[2,256,16,16]
# state size 2ngf x 32 x 32
out_code = self.upsample3(out_code) #输出:[2,128,32,32]
# state size ngf x 64 x 64
out_code = self.upsample4(out_code) #输出:[2,64,64,64]
return out_code2、第2和第3个生成器
两个生成器比较类似,在此只介绍第2个。它接收上一个生成器生成的fake image和text_embedding 生成的c向量。
部分代码如下:
def forward(self, h_code, c_code): #这里以第一个NEXT_STAGE_G的数据为例
s_size = h_code.size(2)#h_code:[2,64,64,64]
c_code = c_code.view(-1, self.ef_dim, 1, 1) #c_code:[2,128,1,1]
c_code = c_code.repeat(1, 1, s_size, s_size)# c_code:[2,128,64,64]
# state size (ngf+egf) x in_size x in_size
h_c_code = torch.cat((c_code, h_code), 1)#级联 h_c_code:[2,192,64,64]
# state size ngf x in_size x in_size
out_code = self.jointConv(h_c_code) #out_code:[2,64,64,64] 主要是卷积和归一化
out_code = self.residual(out_code) #out_code :[2,64,64,64]
# state size ngf/2 x 2in_size x 2in_size
out_code = self.upsample(out_code) #out_code :[2,32,128,128]
return out_code
第3个生成器与其类似。
3、鉴别器
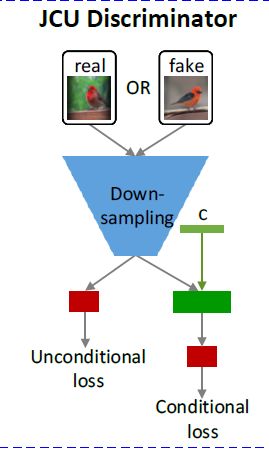
总损失是三个鉴别器的累加。
for i in range(self.num_Ds):
errD = self.train_Dnet(i, count)
errD_total += errD源码对不同尺寸的鉴别器定义了不同的类(D_NET64、D_NET128、D_NET256),结构上大同小异,这里只给出D_NET64进行说明。
if cfg.TREE.BRANCH_NUM > 0:
netsD.append(D_NET64()) # netsD包含了对64*64 128*128 256*256的图像的鉴别器
if cfg.TREE.BRANCH_NUM > 1:
netsD.append(D_NET128())
if cfg.TREE.BRANCH_NUM > 2:
netsD.append(D_NET256())
if cfg.TREE.BRANCH_NUM > 3:
netsD.append(D_NET512())
if cfg.TREE.BRANCH_NUM > 4:
netsD.append(D_NET1024()) def forward(self, x_var, c_code=None):
x_code = self.img_code_s16(x_var)#x_var:[2,3,64,64] x_code:[2,512,4,4]
if cfg.GAN.B_CONDITION and c_code is not None:
c_code = c_code.view(-1, self.ef_dim, 1, 1)#输入c_code:[2,128] 输出c_code:[2,128,1,1]
c_code = c_code.repeat(1, 1, 4, 4)#c_code:[2,128,4,4]
# state size (ngf+egf) x 4 x 4
h_c_code = torch.cat((c_code, x_code), 1)# 输出h_c_code:[2,640,4,4]
# state size ngf x in_size x in_size
h_c_code = self.jointConv(h_c_code)#输出h_c_code:[2,512,4,4]
else:
h_c_code = x_code
output = self.logits(h_c_code)#4*4的卷积 output:[2,1,1,1]
if cfg.GAN.B_CONDITION:
out_uncond = self.uncond_logits(x_code)
return [output.view(-1), out_uncond.view(-1)]# [2] [2]
else:
return [output.view(-1)]鉴别器接收64*64的图片和c向量,最终返回一个包含两个元素的列表。这两个元素分别是使用c信息时的预测结果(output)和不使用c信息时的预测结果(out_uncond)。其他的鉴别器与之类似
输入real_image,会得到real_logits[0](使用c 向量),real_logits[1](不用c向量) 对应的真实标签为real_labels
输入wrong_image,会得到wrong_logits[0](使用c 向量),wrong_logits[1](不用c向量)对应的标签为fake_labels
输入fake_image,会得到fake_logits[0](使用c 向量),fake_logits[1](不用c向量)对应的标签为fake_labels
五、训练
在StackGAN时有讲到,在训练期间,鉴别器将真实图片+对应的text_bedding作为正样本对。负样本对包括两种:真实的图片+不配套的text_bedding、生成的图片+对应的text_bedding。
在此计算损失时候同理,损失包括了三部分。每一部分又包括conditional和unconditional两部分。
real_logits = netD(real_imgs, mu.detach())#real_imgs:[2,3,18,18] mu:[2,128] 输出:[2] [2]
wrong_logits = netD(wrong_imgs, mu.detach()) #wrong_imgs:[2,3,18,18] mu:[2,128] 输出:[2] [2]
fake_logits = netD(fake_imgs.detach(), mu.detach()) #fake_imgs:[2,3,18,18] mu:[2,128] 输出:[2] [2]
#
errD_real = criterion(real_logits[0], real_labels)
errD_wrong = criterion(wrong_logits[0], fake_labels)
errD_fake = criterion(fake_logits[0], fake_labels)
if len(real_logits) > 1 and cfg.TRAIN.COEFF.UNCOND_LOSS > 0:
errD_real_uncond = cfg.TRAIN.COEFF.UNCOND_LOSS * \
criterion(real_logits[1], real_labels)
errD_wrong_uncond = cfg.TRAIN.COEFF.UNCOND_LOSS * \
criterion(wrong_logits[1], real_labels)
errD_fake_uncond = cfg.TRAIN.COEFF.UNCOND_LOSS * \
criterion(fake_logits[1], fake_labels)
#
errD_real = errD_real + errD_real_uncond
errD_wrong = errD_wrong + errD_wrong_uncond
errD_fake = errD_fake + errD_fake_uncond
#
errD = errD_real + errD_wrong + errD_fake #real+wrong+fake 每一部分由两部分组成
else:
errD = errD_real + 0.5 * (errD_wrong + errD_fake)