基于谱减法的音频信号噪声抑制算法实现理论知识学习总结
一、内容
1. 音频信号噪声抑制原理
2. 谱减法的原理和相关算法
3. WAV音频文件的格式
二、音频信号噪声抑制原理
2.1语音和噪声
1、冲激噪声
冲激噪声的时域波形是类似于冲激函数那样的窄脉冲,常见的消除冲激噪声的方式有两种:
(1)对带噪语音信号的幅值求均值,将该均值作为判断的标准,超过该标准的视作噪声,在时域将其滤除。
(2)当噪声不太密集的时候,可以通过某些点内插的方法避开或者平滑掉冲激点,从而从语音信号中去掉冲击噪声。
2、周期噪声
常见的噪声是50Hz的交流电产生的周期噪声。在频谱图上展现为离散的窄谱。可以采用陷波器将其去除掉。
3、宽带噪声
说话时同时伴随着呼吸引起的噪声、随机噪声源产生的噪声以及量化噪声等都可视为宽带噪声。宽带噪声的特点是噪声频谱遍布于整个语音信号频谱中,一般采用非线性方法滤除。
4、语音干扰
干扰语音和待传语音信号同时在一个信道中传输所造成的语音干扰。区别有用语音和干扰语音的基本方法是利用其基音差别。一般情况下两种语音的基音不同,也不成整数倍,因此可以用梳妆滤波器提取基音和各谐波。
2.2 噪声抑制原理
1、干扰相减降噪技术
为了降低信号在传输过程中的噪声,改善语音传输质量,大多会采用三种通用的语音增强方法。首先是干扰相减法,即通过减掉噪声频谱来抑制噪声;其次是谐波频率抑制法,即利用语音增强的方法来完成减噪,基于噪声的周期性原理,利用谐波噪声的自适应梳状滤波实施基频跟踪来完成降噪;第三是利用声码器再合成法,它利用迭代法,在语音建模的基础上,估计模型参数,用描述语音信号的方法再重新合成无噪声信号。
单通道语音增强系统必须在无语音期间,也就是在只有背景噪声存在时估计噪声的特性。通过语音启动检测器(VAD)采集有效的语音源和噪音源,然后利用噪声相减算法实现降噪。基于声音语音的周期性,时域自适应噪声抵消法可以通过产生参考信号而加以利用。其中,参考信号是延迟主信号一个周期形成的,需要有复杂的间距估计算法。在语音帧内利用FFT,用估计的噪声幅值频谱相减,并逆变换这个相减后的频谱幅值,再利用原始噪音的相位,求出有噪音短时幅值和相位频谱。增强步骤一帧接一帧地完成。此方法先把污染的语音利用带通滤波器组分解成不同的频率组,随后每个分波段的噪声功率在无语音期间被估计出来。通过利用衰减因子可以获得噪声抑制,其中衰减因子相对应于每个分波段估计噪声功率比上的瞬时信号功率。
2、谱相减降噪技术
目前,多数的通信减噪都是使用DSP来完成的,主要是使用FFT降低噪声。其中,频谱相减提供了有效的计算方法,通过从有噪声语音谱中减去噪声频谱,即增强了语音,又降低了噪声。有噪声语音被分段,并且被设置窗口,每个数据窗口的FFT均被执行,并且幅值频谱被计算出来。VAD用来检测输入的语音信号。在非语音段,噪声频谱将会被估计出来,并存入缓存区,再通过算法使得缓冲器内的数据衰减,从而使噪声减小。在非语音期间,有两种方法产生输出:用固定因子衰减输出或设置输出为0。在非语音帧期间具有某种残余噪声(舒适噪声),可输出比较高的语音质量,原因是在语音帧期间,噪声局部地被语音屏蔽,它的幅值将会在非语音段上被存在的相同量值的噪声所平衡。在语音段上设置输出为0,具有放大噪声的效果,因此在非语音期间,最好通过固定因子衰减噪声。幅值与语音段上可觉察的噪声特性,以及噪声段上可觉察的噪声之间必须保持平衡,所以不希望的音响效果,如嗡嗡声、咔嗒声、抖动声、语音信号的模糊不清等,均可以避免。
在描述算法之前,先设置一些参数,并做数据分析。首先假设背景噪声是平稳的,并且在语音段内,使其希望幅值频谱出现在不变的语音段之前。如果环境是变化的,则在语音帧开始之前,有足够的时间去估计背景噪声的新幅值频谱。对于缓慢变化的噪声算法,需要根据VAD参数确定语音是否已经终止,同时估计新的噪声影响,然后利用频谱相减法,就可以使得噪声明显下降。
三、谱减法
3.1谱减法原理
谱相减方法是基于人的感觉特性,即语音信号的短时幅度比短时相位更容易对人的听觉系统产生影响,从而对语音短时幅度谱进行估计,适用于受加性噪声污染的语音。
处理宽带噪声的最通用技术是谱相减法,即从带噪语音估值中减去噪声频谱估值,从而得到纯净语音的频谱。由于人耳对语音频谱分量的相位不敏感,因而这种方法主要针对短时幅度谱。所谓“谱相减” 就是从输入信号的幅度谱中减去估计得来的噪声平均幅度谱,其效果相当于在变换域对带噪信号进行了某种均衡化处理。相对于其它方法,谱相减法引入的约束条件最少,物理意义最直接,运算量小,而且经过改进后效果也较好。
传统的谱减法即在频域将带噪语音的功率谱减去噪声的功率谱,得到语音的功率谱估计, 开方后就得到语音幅度估计,将其相位恢复后再采用逆傅立叶变换恢复时域信号。考虑到人耳对相位的感觉不灵敏,相位恢复时所采用的相位是带噪语音的相位信息。
3.2基本谱减法算法
基本谱减算法的思想是假设在加性噪声与短时平稳的语音信号相互独立的条件下,从带噪语音的功率谱中减去噪声功率谱,从而得到较为纯净的语音频谱。
如果设s(t)为纯净语音信号,n(t)为噪声信号,y(t)为带噪语音信号,则有:
![]() (1)
(1)
用Y(w)、S(w)、N(w)分别表示y(t)、s(t)、n(t)的傅里叶变换,则可得:
![]() (2)
(2)
由此可得:
![]() (3)
(3)
由上式可得:
![]() (4)
(4)
由于s(t)和n(t)独立,所以S(w)与N(w)也独立。而N(w)为零均值的高斯分布,故![]() 等于0。所以有:
等于0。所以有:
![]() (5)
(5)
对一个分析帧内的短时平稳过程,有:
![]() (6)
(6)
由于平稳噪声的功率谱在发音前和发音期间可以认为基本没有变化,这样可以通过发音前的所谓“寂静段”(认为在这一段里没有语音只有噪声,一般为带噪语音的前3~4帧)来估计噪声的功率谱![]() ,从而有:
,从而有:
![]() (7)
(7)
由此得到原始语音的估计值:
![]() (8)
(8)
根据人耳对相位变化不敏感这一特点,可以用原带噪语音信号y(t)的相位谱来代替估计之后的语音信号的相位谱,从而可以得到降噪后的语音时域信号。基本谱减算法的原理图如图3.2.1所示。
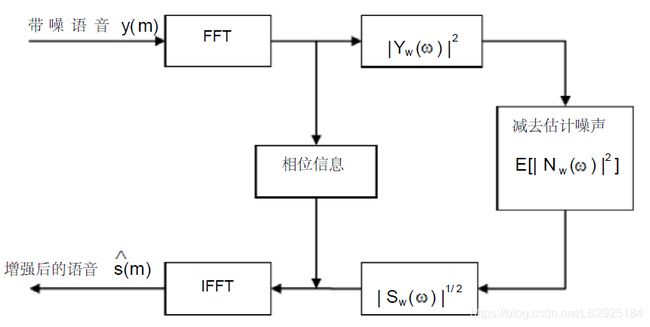
图3.2.1 谱减法的算法流程图
3.3 几种改进型谱减法算法
(1)非线性谱减
Berouti等人提出的谱减算法,假设了噪声对所有的频谱分量都有同等的影响,继而只用了一个过减因子来减去对噪声的过估计。现实世界中的噪声并非如此,这意味着可以用一个频率相关的减法因子来处理不同类型的噪声。
(2)多带谱减法
在多带算法中,将语音频谱划分为N个互不重叠的子带,谱减法在每个子带独立运行。将语音信号分为多个子带信号的过程可以通过在时域使用带通滤波器来进行,或者在频域使用适当的窗。通常会采用后一种办法,因为实现起来有更小的运算量。
多带谱减与非线性谱减的主要区别在于对过减因子的估计。多带算法针对频带估计减法因子,而非线性谱减算法针对每一个频点,导致频点上的信噪比可能有很大变化。这种剧烈变化是谱减法中所遇到的语音失真(音乐噪声)的原因之一。相反,子带信噪比变化则不会特别剧烈。
(3)MMSE谱减算法
上面的方法中,谱减参数alpha和beta通过实验确定,无论如何都不会是最优的选择。MMSE谱减法能够在均方意义下最优地选择谱减参数。
(4)扩展谱减法
基于自适应维纳滤波与谱减原理的结合。维纳滤波用于估计噪声谱,然后从带噪语音信号中减去该噪声谱。
(5)自适应增益平均的谱减
谱减法中导致音乐噪声的两个因素在于谱估计的大范围变化以及增益函数的不同。对于第一个问题,Gustafsson等人建议将分析帧划分为更换小的子帧以得到更低分辨率的频谱。子帧频谱通过连续平均以减小频谱的波动。对于第二个问题Gustafsson等人提出使用自适应指数平均,在时间上对增益函数做平滑。此外,为了避免因使用零相位增益函数导致的非因果滤波问题,Gustafsson等人建议在增益函数中引入线性相位。
(6)基于感知特性的谱减
前面提到的方法,谱减参数要么是通过实验计算短时信噪比得到,要么是通过最优均方误差得到,均没有考虑听觉系统的特性,该算法的主要目的是使残余噪声在听觉上难以被察觉。利用了人类听觉系统改进系统的可懂度(即人耳的掩蔽效应)。
四、WAV音频文件
4.1 WAV文件格式概述
WAV文件是计算机领域最常用的数字化声音文件格式之一,它是微软专门为Windows系统定义的波形文件格式(Waveform Audio),由于其扩展名为"*.wav"。
WAV是录音时用的标准的WINDOWS文件格式,文件的扩展名为“WAV”,数据本身的格式为PCM或压缩型。
WAV文件格式是一种由微软和IBM联合开发的用于音频数字存储的标准,它采用RIFF文件格式结构,非常接近于AIFF和IFF格式。符合PIFF Resource Interchange File Format规范。所有的WAV都有一个文件头,这个文件头音频流的编码参数。
WAV对音频流的编码没有硬性规定,除了PCM之外,还有几乎所有支持ACM规范的编码都可以为WAV的音频流进行编码。
多媒体应用中使用了多种数据,包括位图、音频数据、视频数据以及外围设备控制信息等。RIFF为存储这些类型的数据提供了一种方法,RIFF文件所包含的数据类型由该文件的扩展名来标识,能以RIFF文件存储的数据包括:
音频视频交错格式数据(.AVI) 、波形格式数据(.WAV) 、位图格式数据(.RDI) 、MIDI格式数据(.RMI) 、调色板格式(.PAL) 、多媒体电影(.RMN) 、动画光标(.ANI) 、其它RIFF文件(.BND)。
wave文件有很多不同的压缩格式,所以,正确而详细地了解各种WAVE文件的内部结构是成功完成压缩和解压缩的基础,也是生成特有音频压缩格式文件的前提。
最基本的WAVE文件是PCM(脉冲编码调制)格式的,这种文件直接存储采样的声音数据没有经过任何的压缩,是声卡直接支持的数据格式,要让声卡正确播放其它被压缩的声音数据,就应该先把压缩的数据解压缩成PCM格式,然后再让声卡来播放。
4.2 Wav文件的内部结构
WAVE文件是以RIFF(Resource Interchange File Format,"资源交互文件格式")格式来组织内部结构的。
RIFF文件结构可以看作是树状结构,其基本构成是称为"块"(Chunk)的单元,最顶端是一个“RIFF”块,下面的每个块有“类型块标识(可选)”、“标志符”、“数据大小”及“数据”等项所组成。块的结构如表4.2.1所示:
表4.2.1 基本chunk内部结构
名称 |
size |
备注 |
块标志符 |
4 |
4个小写字符(如 "fmt ", "fact", "data" 等) |
数据大小 |
4 |
DWORD类型,表示后接数据的大小(N Bytes) |
数据 |
N |
本块中正式数据部分 |
上面说到的“类型块标识”只在部分chunk中用到,如 "WAVE" chunk中,这时表示下面嵌套有别的chunk。
当使用了 "类型块标识" 时,该chunk就没有别的项(如块标志符,数据大小等),它只作为文件读取时的一个标识。先找到这个“类型块标识”,再以它为起点读取它下面嵌套的其它chunk。
每个文件最前端写入的是RIFF块,每个文件只有一个RIFF块。从 Wave文件格式详细说明 中可以看到这一点。
非PCM格式的文件会至少多加入一个 "fact" 块,它用来记录数据(注意是数据而不是文件)解压缩后的大小。这个 "fact" 块一般加在 "data" 块的前面。
WAVE文件是由若干个Chunk组成的。按照在文件中的出现位置包括:RIFF WAVE Chunk, Format Chunk, Fact Chunk(可选), Data Chunk。
五、总结
通过本次理论知识的学习,搜集和查阅了大量与谱减法和音频噪声抑制的有关的资料,不仅提高了自己快速查找资料的能力,同时也深入了解了谱减法以及音频噪声抑制的原理和工作方式,对采用谱减法对语音处理的流程有了总体的认知。对于WAV文件的格式和内部结构有了深层次的了解,能够较为清晰的辨别WAV文件各参数代表的含义。通过一点一滴的积累,对于音频噪声抑制和谱减法不再感到陌生和高深,深入了解多了反而还觉得有趣,尤其是当自己遇到困惑迎刃而解的那一瞬间,突然发现知识带给人的那种乐趣是其它东西给予不了的。
六、参考文献:
[1] 钱国青.赵鹤鸣.基于改进谱减算法的语音增强新方法[J].苏州大学电子信息学院,苏州,2005:42-51
[2] 洪晓芬.基于谱减法的改进语音增强方法[J].甘肃联合大学信息技术中心,2007.
[3] 罗海涛.wav音频文件格式分析与数据获取[J].广东外语外贸大学,2016:211-213
[4] 严思伟,屈晓旭,娄景艺.基于连续噪声谱估计的谱减法语音增强算法[J].计算机应用研究,2018.
[5] 郑成诗,胡笑浒,周翔, 李晓东. 基于噪声谱结构特性的谱减法[N].北京: 声学学报,2010,(2).
[6] 祝震宇. 语音信号增强算法的谱减法应用探究[J].黑龙江大学电子工程学院,2010.
[7] 百度百科:https://wenku.baidu.com/view/c41a0e49fe4733687e21aa09.html
[8] CSDN: https://blog.csdn.net/LB2925184/article/details/88615212
https://blog.csdn.net/jingling122/article/details/84570266