Detecting Insults in Social Commentary 数据分析报告(python)
文章目录
- Detecting Insults in Social Commentary 数据分析报告
- 报告摘要
- 一、问题描述
- 二、数据加载
- 三、文本数据处理
- 3.1 数据清洗
- 3.2 停止词处理
- 3.3 文本词干化处理
- 3.4 计算词频矩阵
- 四、模型构建与评估
- 4.1 划分训练集和测试集数据
- 4.2 利用逻辑斯蒂模型建模
- 4.3 利用L1正则化建模
Detecting Insults in Social Commentary 数据分析报告
报告摘要
- 目标:本分析旨在利用文本数据判断一个评论是否为侮辱性评论。
- 方法:对评论数据进行数据清洗、停止词处理、词干化基础上,构建词频矩阵,利用逻辑斯蒂回归和L1正则化的逻辑回归对评论是否为侮辱性评论进行判断。
- 结论:对测试集数据进行测试后,发现模型具有一定的判断效果。
目录
- 问题描述
- 数据加载
- 文本数据处理
- 数据清洗
- 停止词处理
- 文本词干化处理
- 计算词频矩阵
- 模型构建与评估
- 划分训练集和测试集
- 利用逻辑斯蒂模型建模
- L1正则化建模
一、问题描述
本问题旨在判断一个评论是否为侮辱性评论。每个样本由一句/一段评论构成,判断每个评论是否为针对个人的侮辱性评论。
| 变量名 | 含义 |
|---|---|
| Insult | 评论是否为侮辱性评论 |
| Date | 评论时间 |
| Comment | 评论内容 |
二、数据加载
# 加载所需的python库
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.graphics.api as smg
import patsy
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
from scipy import stats
import seaborn as sns
#载入train数据集
traindata = pd.read_csv("D:/学习/数据挖掘与机器学习/homework week3/train.csv")
train = traindata
# 查看前五条数据
train.head()
| Insult | Date | Comment | |
|---|---|---|---|
| 0 | 1 | 20120618192155Z | "You fuck your dad." |
| 1 | 0 | 20120528192215Z | "i really don't understand your point.\xa0 It ... |
| 2 | 0 | NaN | "A\\xc2\\xa0majority of Canadians can and has ... |
| 3 | 0 | NaN | "listen if you dont wanna get married to a man... |
| 4 | 0 | 20120619094753Z | "C\xe1c b\u1ea1n xu\u1ed1ng \u0111\u01b0\u1edd... |
# 训练集中共有3947条数据,其中Insult和Comment没有缺失值,Date有718条缺失。
train.info()
Int64Index: 3947 entries, 0 to 3946
Data columns (total 3 columns):
Insult 3947 non-null int64
Date 3229 non-null object
Comment 3947 non-null object
dtypes: int64(1), object(2)
memory usage: 123.3+ KB
三、文本数据处理
3.1 数据清洗
# 构建数据清洗函数、去掉标点等符号
import re
def preprocessor(text):
text = re.sub('<[^>]*>', '', text)
emoticons = re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)', text)
text = re.sub('[\W]+', ' ', text.lower()) + \
' '.join(emoticons).replace('-', '')
return text
# 利用构建的函数进行数据清洗
train.Comment = train.Comment.apply(preprocessor)
train.Comment[1]
' i really don t understand your point xa0 it seems that you are mixing apples and oranges '
3.2 停止词处理
# 载入停止词库
import nltk
nltk.download('stopwords')
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\yunlai\AppData\Roaming\nltk_data...
[nltk_data] Package stopwords is already up-to-date!
True
# 去掉停止词
from nltk.corpus import stopwords
stop = stopwords.words('english')
[w for w in train.Comment if w not in stop]
train.Comment.head()
0 you fuck your dad
1 i really don t understand your point xa0 it s...
2 a xc2 xa0majority of canadians can and has be...
3 listen if you dont wanna get married to a man...
4 c xe1c b u1ea1n xu u1ed1ng u0111 u01b0 u1eddn...
Name: Comment, dtype: object
3.3 文本词干化处理
from nltk.stem.porter import PorterStemmer
porter = PorterStemmer()
def tokenizer_porter(text):
return [porter.stem(word) for word in text.split()]
# 词干化
train.Comment = train.Comment.apply(tokenizer_porter)
train.Comment[0]
['you', 'fuck', 'your', 'dad']
# 编写函数、将词干化后的词连接
def join_data(text):
text = ' '.join(text)
return text
train.Comment = train.Comment.apply(join_data)
train.Comment[1]
'i realli don t understand your point xa0 it seem that you are mix appl and orang'
3.4 计算词频矩阵
from sklearn.feature_extraction.text import TfidfTransformer
tfidf = TfidfTransformer(use_idf=True, norm='l2', smooth_idf=True)
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer()
# 计算每个词的词频矩阵
comment = tfidf.fit_transform(count.fit_transform(train.Comment)).toarray()
comment =DataFrame(comment)
# 将计算结果合并到数据集中
train = pd.merge(train,comment,left_index = True, right_index = True)
四、模型构建与评估
4.1 划分训练集和测试集数据
data = train
del data["Date"]
del data["Comment"]
data.head()
| Insult | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ... | 12691 | 12692 | 12693 | 12694 | 12695 | 12696 | 12697 | 12698 | 12699 | 12700 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 12702 columns
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, roc_curve,roc_auc_score,classification_report
from sklearn.cross_validation import cross_val_score
from sklearn.cross_validation import train_test_split
train_y = data.Insult
train_x = data
del train_x["Insult"]
train_x['intercept'] = 1.0
train_x.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 12692 | 12693 | 12694 | 12695 | 12696 | 12697 | 12698 | 12699 | 12700 | intercept | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
5 rows × 12702 columns
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
train_x, train_y, test_size=0.3, random_state=0)
4.2 利用逻辑斯蒂模型建模
# 考虑到样本数据量较少,构建随机森林等模型效果可能不好,故构建逻辑斯蒂模型
clf = LogisticRegression()
clf.fit(X_train,y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
# 利用模型进行预测
clf.predict(X_test)
array([0, 0, 0, ..., 0, 0, 1], dtype=int64)
preds = clf.predict(X_test)
# 计算混淆矩阵
confusion_matrix(y_test,preds)
array([[840, 22],
[197, 126]])
# 计算roc_auc得分
pre = clf.predict_proba(X_test)
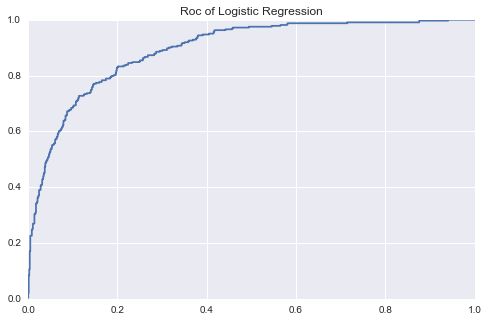
roc_auc_score(y_test,pre[:,1])
0.89364858166981531
# 画出roc曲线
fpr,tpr,thresholds = roc_curve(y_test,pre[:,1])
fig,ax = plt.subplots(figsize=(8,5))
plt.plot(fpr,tpr)
ax.set_title("Roc of Logistic Regression")
4.3 利用L1正则化建模
# 参数调整,C=2
lrtrain = LogisticRegression(penalty='l1', C=2)
lrtrain.fit(X_train,y_train)
LogisticRegression(C=2, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l1', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
# 利用模型预测,构建混淆矩阵
preds2 = lrtrain.predict(X_test)
confusion_matrix(y_test,preds2)
array([[809, 53],
[146, 177]])
# 计算roc_auc得分
pre2 = lrtrain.predict_proba(X_test)
roc_auc_score(y_test,pre2[:,1])
0.8920287616817395
# 画出roc曲线
fpr,tpr,thresholds = roc_curve(y_test,pre2[:,1])
fig,ax = plt.subplots(figsize=(8,5))
plt.plot(fpr,tpr)
ax.set_title("Roc of Logistic Regression L1")

逻辑斯蒂模型和L1正则化的逻辑斯蒂模型roc_auc 得分分别为0.87和0.89,说明模型具有一定效果。