如何自动生成推荐歌单:ACM论文翻译与解读 | Translation and Interpretation of ACM Survey
如何自动生成推荐歌单:ACM论文翻译与解读 | How to Automatically Generate Music Playlists: Translation and Interpretation of ACM Survey
本文由@EthanLifeGreat/@EthanUnBeaten原创发表在CSDN, 转载请注明出处.
本文是对 Geoffray Bonnin 等人在2014年发表于 ACM Computer Survey (CSUR) 的论文《Automated Generation of Music Playlists: Survey and Experiments》部分内容的翻译和解读. 如无特别标注,本文所出现的“论文”均指上述论文. 如无特别标注,如下所示的引用文本均出本人的翻译(中文)以及对应的原文(英文). 原论文的英文完整版可在论文名所指向的网页中获得.
This article is a partial translation ( to Chinese ) and interpretation of the literature Automated Generation of Music Playlists: Survey and Experiments that Geoffray Bonnin et al. published on the journal ACM Computer Survey (CSUR) in 2014. The word ‘literature’ in this article, if not specified, refers to the article stated above. The citation below, if not specified, is a demonstration of direct copy of the sentences in the literature. The complete literature can be found on the website the above name linked to.
这是个引用文本. | This is a piece of citation.
1 简介 | Introduction
1.1 本文简介 | Introduction to this article
本文是对论文《Automated Generation of Music Playlists: Survey and Experiments》部分内容的翻译与解读。由于论文的综述性质与笔者的科学知识深度,本文偏向于科普类而非研究类,偏向于翻译兼顾解读。如对深度内容感兴趣,请查阅原文及其中的参考文献。对于本文及涉及内容的疑惑,欢迎读者留言,笔者将尽可能地进行解答。
This article is a partial translation ( to Chinese ) and interpretation of the literature Automated Generation of Music Playlists: Survey and Experiments. Because of the nature of a survey, the limited knowledge the editor owns, this article prefers to popularize rather than research into the field with more translation and less interpretation. If interested in studying in depth, it’s recommended that read the complete literature and it’s references. If in doubt, feel free to leave your comment. I would endeavor to answer your questions, if any.
1.2 论文简介 | Introduction to the literature
论文主要介绍了现阶段(2014年1月)的音乐播放列表(以下简称歌单)自动生成的算法,所用到的数据,算法的评估和未来的研究方向.
The literature introduced current (Jan. 2014) used algorithms to automatically generate music playlists, the input data they depend on, the evaluation of the algorithms and perspectives for future research.
详细的简介参见 2.1.
For detailed introduction, refer to 2.1.
1.3 论文脉络 | Structure of the literature
原论文正文共有 7 个部分,分别是:简介、播放列表生成问题、背景知识和目标特性、列表生成算法、评价列表生成系统、列表生成技术间的对比评价和研究视角与结论.
The main text of the literature is separated into 7 parts, namely: INTRODUCTION, THE PLAYLIST GENERATION PROBLEM, BACKGROUND KNOWLEDGE AND TARGET CHARACTERISTICS, PLAYLIST GENERATION ALGORITHMS, EVALUATING PLAYLIST GENERATION SYSTEMS, A COMPARATIVE EVALUATION OF PLAYLIST GENERATION TECHNIQUES and RESEARCH PERSPECTIVES AND CONCLUSIONS.
正文第一部分是行文目的的概括,第二、三部分介绍了论文主要探讨了(音乐播放列表的自动生成)问题内涵与其涉及的背景知识,第四部分是解决问题的算法枚举,第五、六部分是对第四部分所述算法的评价,最后一部分分别总结了全文研究的三个视角并做了全文总结.
Section 1 of the literature the propose of the whole article. The following 2 sections reviewed the background knowledge and the meaning of the problem. Section 4 is a introduction to the algorithms that solve the problem. In section 5 and section 6 the authors evaluated the algorithms they reviewed in the previous section. The last section synthesize three perspectives of the research and then made a conclusion.
附录部分介绍了公开的音乐数据集和(正文中涉及到的三个)算法的计算复杂度分析.
In the appendix, were some available music data sets and the computational complexity analysis of the algorithms.
1.4 其它注意事项 | Other information
为方便起见,在所有的引用中,笔者省略了部分原文的文献注释.
In consideration of convenience, some of the references in the literature were pruned when citing.
2 论文翻译与解读 | Translation And Interpretation
为方便起见,本章中所有小节的标题均为论文对应部分的标题及其翻译. 每个小节的所有引用都来自于文章对应部分.
In consideration of convenience, titles of sections in this part correspond to the original titles of the literature. Citations in all sections of this article come from the corresponding section of the literature.
2.1 简介 | INTRODUCTION
许多我们听到的音乐都是以播放列表的形式呈现的. 这些播放列表历来是人工生成的,这些人包括电台DJ或者音乐制作者. 这些播放列表有其内在的组织逻辑,比如其中的乐曲都有着相同的音乐体裁1或者都是由相关的艺术家演奏的.
Much of the music that we listen to is organized in some form of a playlist. Such playlists are traditionally created manually, e.g., by a radio DJ or music producer, and usually have some internal organization logic, for example that their tracks belong to the same musical genre or are performed by related artists.
这些播放列表被用于许多场合,例如公开活动的背景音乐库与分享自己的音乐品味等.
People use such personal playlists for a number of purposes, for example to create a collection of tracks used as background music for some event or activity or to share their musical preferences with others.
在这篇论文中,我们评价播放列表生成的多种实现方式并进行归类.
In this paper, we review and categorize the various approaches to automated playlist generation.
2.2 播放列表生成问题 | THE PLAYLIST GENERATION PROBLEM
2.2.1 定义 | Definitions
播放列表指的是一系列曲目(录制的音频)
A playlist is a sequence of tracks (audio recordings).
“个人电台”是 last.fm 或 Pandora 等互联网音乐服务商生成的的播放列表.
Personalized radio playlists are generated by Web music services such as last.fm or Pandora.
“业余歌单”是非专业的音乐爱好者创建的播放列表.
Amateur playlists are playlists made by non-professional music enthusiasts.
在国内(以网易云音乐为例),“个人电台”对应“私人FM”,而“业余歌单”对应“歌单”.
In China, (take NetEase Cloud Music as an example,) “Personalized radio playlists” is called “Personal FM”, and “Amateur playlists” is called “Playlists”.
播放列表生成:给定 (1)一个曲目库 (2)一个背景知识库 (3) 某些目标特征,创建一组最能满足给定特征的曲目集.
Playlist generation: Given (i) a pool of tracks, (ii) a background knowledge database and (iii) some target characteristics of the playlist, create a sequence of tracks fulfilling the target characteristics in the best possible way.
2.2.2 歌单生成的挑战 | Challenges of playlist generation
首先,虽然我们谈论的是一个自动化过程,大量可供选择的曲目与其对应的附加信息仍将导致极高的计算复杂度… 问题还存在于:许多应用场景要求歌单的“按需”生成或是对用户输入的及时反应.
First, even if we talk of an automated process, the large number of available tracks that can potentially be included in the playlists – already personal music libraries can be huge – and the corresponding enormous amount of additional information that has to be processed can lead to high computational complexity… the problem exists that many application scenarios require the “on-demand” generation of playlists or the immediate reaction on user feedback.
这一段是挑战的第一点,即计算复杂度高且很多时候要求反应迅速.
This is the first part of the challenge, i.e., high computational complexity in “on-demand” situation.
另一个挑战在于获取曲目的信息的获取. 从大量曲目的声信号中提取特征可能需要大量的计算时间.
Another challenge lies in the acquisition of information about the tracks. Extracting characteristics from the audio signal for a large number of tracks can require significant computation times.
这一段是挑战的第二点,歌曲信息提取本身就是一个研究方向,即基于内容的音乐信息检索技术(CB-MIR).这一点在之后的内容中将被深入介绍,也可参见
Y V Srinivasa Murthy 等人相关综述论文 《Content-Based Music Information Retrieval (CB-MIR) and Its Applications toward the Music Industry: A Review》.
The second challenge is, a information extraction from the track, i.e. Content-Based Music Information Retrieval (CB-MIR), which will be introduced later in the literature. Also refer to Content-Based Music Information Retrieval (CB-MIR) and Its Applications toward the Music Industry: A Review by Y V Srinivasa Murthy et al.
最后,听者的品味和所处环境是两个能对歌单接受度产生重大影响的因素. 两个用户可能在相同环境下对相同歌单产生不同的理解.
Finally, the taste and context of the listeners are two factors that can have a major influence on the perceived suitability or quality of a playlist and two users may actually perceive the same playlist differently even if listened to in the same context.
这是挑战的第三点,正所谓“一千个观众眼中有一千个哈姆雷特”,理解用户的品味和环境也是能左右歌单好坏的一点.
This is the third challenge. As Shakespeare once said:“There are a thousand Hamlets in a thousand people’s eyes”, it’s also important to know the user’s taste and context for generating a good playlist.
2.2.3 与 MIR 和 RS 之间的关系 | Relation to music information retrieval and recommender systems
2.2.3.1 音乐信息检索(MIR) | Music Information Retrieval
歌单生成属于 MIR, 而后者是信息检索(IR)在音乐领域的延伸. 在这里我们主要讨论 IR 与歌单生成的关系.
Playlist generation problem belongs to the field of MIR. The latter goes far beyond the application of in- formation retrieval (IR) to music data. In this article we mainly review the relationship between IR and the playlist generation problem.
在传统的 IR 场景下,算法的优化目标通常是对与查询到与问题相关的条目,并进行排序. 但是一个歌单的好坏不能只由其中的条目而单独判断,因为还有一些与整个列表有关的性质. 比如:这个列表是否足够多元,即其中的曲目对用户而言足够新颖;这个列表中曲目的衔接是否得当. 还有一点是,在歌单生成里清晰的查询输入一种可能的用户输入2.
In traditional IR scenarios, the optimization goal is usually to find and rank all items that are relevant for a query. The quality of a playlist however cannot be assessed by only looking at its individual items as there might be desirable characteristics that concern the list as a whole, e.g., that it is diverse, contains items that are unknown to the user, or that track transitions are smooth. Furthermore, explicit queries are only one possible user input3.
2.2.3.2 推荐系统(RS) | Recommender Systems
概念上而言,歌单生成问题可以看作是一种推荐系统(RS),即,集合推荐.
Conceptually, the playlist generation problem can be considered as a special case of the recommendation problem, i.e., the recommendation of collections.
不像是许多 RS 的研究场景那样,在歌单生成里中,即时输入非常常见.
Unlike in many RS research scenarios, the immediate consumption of the recommendations is common in playlist generation scenarios.
即时输入指的是如“(在个人电台里)按下切歌按钮”的输入,这某种程度上意味着用户对当前歌曲的反感. 这些是一种有用的信息.
A immediate consumption means, e.g., pressing the skip bottom when using a personalized music radio, which means repugnance to some extent. These are useful information.
2.3 背景知识与目标特性 | BACKGROUND KNOWLEDGE AND TARGET CHARACTERISTICS
2.3.1 背景知识 | Background knowledge
2.3.1.1 声学信号中的音乐特征 | Musical features from the audio signal
许多 MIR 研究者的目标是自动地提取声学信号中的音乐特征,包括但不限于:音调,响度,节奏,和弦走向等或者直接压缩音频谱特别是频谱聚类和高斯混合模型4.
The goal of many MIR researchers is to automatically extract musical features from the audio signal including, e.g., pitch, loudness, rhythm, chord changes, or simply compact representations of the frequency spectrum, in particular spectral clusters and Gaussian mixture models.
2.3.1.2 元数据与专家标注 | Meta-data and expert annotations
元数据在这里被定义为所有不属于声学信号的,用于描述曲目的信息. 例如发行年份、标签、艺术家和体裁信息、歌词等的曲目属性.
Meta-data shall be defined here as any information describing the tracks which is not derived from the audio signal, e.g., track attributes such as the year of release, the label, artist and genre information, lyrics, etc.
2.3.1.3 社交网络数据 | Social Web data
标签. 源于社区用户的标注(标签)和评论可以通过爬虫手段或者预置应用程序接口(API)被廉价地获取.
Tags. Community-provided annotations (tags) and comments made by users are common on many social platforms and can be obtained at comparably low cost through a crawling process or with pre-defined APIs.
评分. 明确的评分在社交网络也很常见:iTunes上的1-5评分,last.fm上的“喜欢”与“不喜欢”评论,以及其它表达对曲目评价的形式,比如 Facebook 上的“墙帖子”或者 Twitter 上的推文.
Ratings. Explicit ratings are also typical on the Social Web and include 1-to-5 rating scales like on iTunes, ‘like’ or ‘dislike’ statements as on last.fm, as well as other forms of expressing an evaluation for a track, e.g., through a wall posting on Facebook or a tweet on Twitter.
社交关系网. 在社交网络平台上,人们被“朋友”(或其它称谓)关系所连接,形成社交关系网. 当我们认为被这种关系所连接的人们有着相近的品味时,我们就可以利用这样的关系,比如说:创建一个包含朋友喜欢的曲目的歌单.
The Social Graph. On Social Web platforms, people are connected to each other through “friend” relationships or similar concepts, forming a social graph. When we assume that people who are connected on such platforms share similar tastes, we can exploit such relations and, e.g., create playlists containing tracks that are liked by the friends of a given user.
2.3.1.4 使用记录 | Usage data
网络音乐平台时常提供包括:用户的“最近听过”歌曲/歌单以及每首歌的整体流行程度.
Web music platforms often provide information about the listening behavior of their users including listening logs for individual tracks or playlists or about the general popularity of individual tracks.
使用记录包括: (1) 曲目流行程度 (2) “最近听过” (3) 用户自制歌单 .
Usage data include: (i) Track popularity (ii) Listening logs (iii) Manually created playlists.
2.3.2 用于生成歌单的对象特征 | Specifying target characteristics for playlists
2.3.2.1 明确的偏好与限制: | Explicit preferences and constraints
我们定义四种参考文献里典型的辨别用户当前偏好和限制办法:(1) 种子曲目 (2) 自由形式关键词 (3) 明确的预定义限制 (4) 对曲目的实时反馈
We identified four typical ways for users to specify their short-term preferences and constraints in the literature: (1) seed tracks, (2) free-form keywords, (3) explicit, pre- defined constraints and (4) real-time feedback about tracks.
关于“限制”:
限制包括多个方面:期待的体裁、节奏、发行年份等.
The constraints can concern various aspects including the desired genre, tempo, year of release, etc.
2.3.2.2 用户过去偏好 | Past user preferences
这些偏好可以是被用户明确表达的,也可以由系统评估得到. 评估的内容包括用户设备伤的私人曲库、音乐历史记录以及用户过去创建的歌单.
Such preferences can be explicitly stated (ratings) but also estimated by the system. Typical sources for estimates are the user’s personal track library on the device, the listening history or playlists that the user has created in the past.
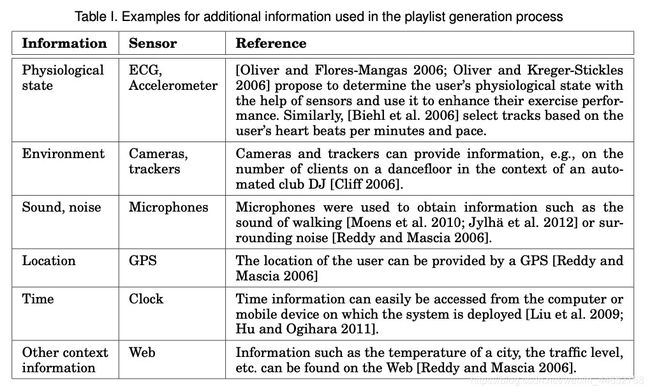
2.3.2.3 环境与传感器信息 | Contextual and sensor information
下面的这个表格对应其后的原论文表格中的前两列.
The following table corresponds to the first two columns in the table next to it.
| 信息 | 传感器 |
|---|---|
| 物理状态 | 心电图(ECG)、加速度计 |
| 环境 | 相机、跟踪器 |
| 声音、噪音 | 话筒 |
| 位置 | 全球定位系统(GPS) |
| 时间 | 时钟 |
| 其它环境信息(气温、交通状况等) | 网络 |
2.4 播放列表生成算法 | PLAYLIST GENERATION ALGORITHMS
下面是原文中提及的七种播放列表生成策略(strategies).
The following is seven strategies reviewed in the literature.
2.4.1 基于相似性的算法 | Similarity-based algorithms
曲目之间的聚合性是检验歌单质量好坏的一个常见标准. 所以,基于相似性的歌曲选择和排序自然是一个策略. 基于相似度的算法的核心要义是距离函数,它刻画了两首歌之间的接近程度.
The coherence of the tracks is a typical quality criterion for playlists. Therefore, selecting and ordering tracks based on their similarities is an obvious strategy to generate playlists. The core of any similarity-based approach is its distance function, which characterizes the closeness of two tracks.
一旦相似性被计算出,我们就有许多生成歌单的策略:可以选择那些离种子曲目离得近的歌曲; 可以重复选择离最近一首被选择的歌曲近似的歌曲; (更不同的是)还可以选择与用户喜欢过的歌曲最相似的歌曲,这对应一种基于内容的推荐实现. 聚类算法也依赖于相似性函数…
Once these similarities are computed, different strategies of determining the tracks in the playlist are possible.In [Lehtiniemi and Seppa ̈nen2007], for example, tracks are selected based on their distance to the seed track. Another approach is to repeatedly select a track according to the similarity with the previously selected one. Quite differently, one could also simply select those tracks that have the highest similarity with the tracks the user liked, which corresponds to a typical content-based recommendation approach. Clustering techniques also rely on similarity functions…
然而基于相似性的算法也有缺点:
Whereas similarity-based algorithms has the following shortcomings:
纯粹的基于相似性的实现方案的一个潜在缺点是:相似性(同质性)通常被视为主要的甚至可能是唯一的好坏评判标准. 所以危险在于,这样生成的歌单可能太过于同质化或者包含太多的来自同一艺术家的歌曲以至于不适合被用于发现新歌曲.
One possible drawback of pure similarity-based approaches is that the similarity (homogeneity) is often considered as the main and possibly only quality criterion. Therefore, the danger exists that such playlists are too homogeneous or contain too many tracks from the same artist and are thus not well suited for the discovery of new tracks.
从应用场景和特殊的技术手段看,基于相似性的实现方案也可能存在很大的计算开销.
Depending on the application scenario and the specific technique, similarity-based approaches can also be computationally expensive.
2.4.2 协同过滤(CF) | Collaborative filtering
协同过滤(CF)是推荐系统(RS)领域中的一种主流实现方式,它仅仅需要基于社区的评价. 这些评价既可以是明确提供的,也可以是自动收集的(比如通过记录听歌记录). 理论上说,CF中的各式各样的技术都可被用于歌单生成,只要足够大的评价数据库. 然而,CF实现法并不能应对歌单生成的挑战,所以歌曲的相似性、曲目之间的平滑过渡等方面的问题都需要单独解决.
Collaborative Filtering (CF) is the predominant approach in the field of RS and is solely based on community-provided ratings. These ratings can be either provided explicitly or automatically collected (e.g., by recording track listening logs). In principle, any of the various collaborative filtering techniques can be used for playlist generation, provided that there exists a reasonably large dataset with ratings. Still, CF approaches were not designed for the specific challenges of playlist generation, and aspects like list homogeneity or smooth transitions between the tracks have to be addressed separately.
CF 的另一种应用方法是:考虑歌单为(传统意义上的)用户,曲目为(传统意义上的)商品,其中传统意义指的是用户-商品评分矩阵. 这种办法是,当我们要往一个现有的歌单中添加歌曲的时候,我们将其中已有的曲目视作正确的分数. 然后,我们可以用最近邻法找到包括当前歌单中的曲目的近似歌单.
A different way of applying CF techniques for playlist generation is to consider playlists as users and tracks as items in the sense of a binary user-item rating matrix. The idea is that when we are given a playlist which is currently being constructed, we consider the set of already selected tracks as the positive ratings. Then, we can for example apply a nearest-neighbor approach and look for similar playlists that contain some of these tracks.
这种实现的一个主要局限在于所谓“新用户”问题,即,当用户信息不是很充分时(或者初始曲目集很小5),应该如何选择新加入的曲目呢?这个问题在把歌单视作用户时更为突出,因为每一个新歌单都是一个新用户.
One of the main limitations of such approaches is what is called the “new user” problem, i.e., the question what to additionally include in the playlist when not much information about the user is available (or the set of start tracks is small5). This problem is even more important when considering playlists as users, as each playlist to generate is equivalent to a new user.
2.4.3 频繁模式挖掘 | Frequent pattern mining
上述的基于近邻的生成方法要求不同歌单之间由相同的歌曲. 频繁模式挖掘基于类似的原理. 然而,不同于只寻找给定歌单的“邻居”们, 频繁模式挖掘试图分辨数据中的全面的模式. 这些模式分为两种:关联规则(AR)与序列模式(SP). AR通常用于购物车分析问题:A ⇒ B表示“只要A被买了,那么B就会有一定几率也被买,其中A和B是商品的集合. SP也类似,只是它不考虑A和B之间的先后关系. AR与SP哪个更精确、更合适则取决于数据的具体特征.
The above-mentioned neighborhood-based method for playlist generation relies on the co-occurrence of items in playlists. Frequent pattern mining approaches are based on a similar principle. However, instead of only looking on local neighbors for a given playlist, they try to identify global patterns in the data. There are two types of such patterns: association rules (AR) and sequential patterns (SP). AR are often applied for shopping basket analysis problems and have the form A ⇒ B, where both A and B are sets of items and the rule expresses “whenever A was bought, also the items in B were bought with some probability”. Sequential patterns are similar, except that the order of the elements in A and B is relevant. Whether or not sequential patterns are more accurate and preferable over association rules depends on the data characteristics.
频繁模式挖掘的一个最主要的好处在于:它允许我们直观地重现手工建立的歌单中的可见的特点,而不用去观察歌曲的“内容”6. 而一个可能的缺点是:其所生成的歌单的质量取决于(用于学习的)现有歌单的数量和质量.
One of the main advantages of frequent patterns is that they allow us to implicitly reproduce the observed characteristics of manually-defined playlists without looking at the “content” of the tracks7. A possible drawback is that the quality of the generated playlists depends on the number and quality of the playlists used for rule extraction.
2.4.4 统计模型 | Statistical Models
也可以用统计模型来生成歌单8. 一个最简单的操作是:认定每一个曲目的选择都只取决于上一个选定的曲目,这对应这马可夫模型(Markov model).
Playlists can also be generated using statistical models9. One of the simplest approaches is to assume that each track selection is only dependent on the previous track, which corresponds to Markov models.
一个较大的缺陷是:在这个问题上,认定马可夫性质成立可能实际太“激进”(strong)了.
A major drawback of the some of these approaches is that assuming the Markov Property may actually be too strong for the domain.
总体而言,统计模型的一个主要的优势是许多存在的目的都是去优化参数值… 而且不同的统计模型可以简单地通过线性插值法结合起来… 一个可能的缺陷在于这个模型的学习过程可能需要很大的时间开销,这将在第六 10部分中讨论到.
In general, one main advantage of using statistical models is that many algorithms exist to optimize the values of the parameters… Moreover, different statistical models can be easily combined through linear interpolations… One possible drawback however is that the learning pro- cess can be highly time consuming, as will be discussed in Section 611.
2.4.5 基于案例的推理(CBR) | Case-Based Reasoning
基于案例的推理(CBR)利用过去发生过的案例来解决当前的问题. CBR 在案例库中存储一系列有代表性的案例及其解法. 当给定一个新问题时,人们通过搜索案例库并按实际情况应用库中的某些解决方案.
The general idea of Case-Based Reasoning (CBR) techniques is to exploit information about problem settings (cases) encountered in the past to solve new problems. CBR approaches therefore first store a set of representative cases together with their solutions. Given a new problem instance, the case repository is searched for past similar cases whose solution is then adapted according to the specifics of the new case.
典型的 CBR 技术有一个潜在的优势是,当提供案例较少时其计算复杂度相对较低. 但对于如 Baccigalupo 等人提出的方法,其可拓展性可能受限,原因是他们每遇到一个新的歌单生成请求时就将整个案例库搜索一遍.
One possible advantage of typical CBR-techniques is that their computational complexity can be comparably low when only a limited number of cases is used. The specific techniques proposed by Baccigalupo et al., however, may be limited in their scalability as they scan the entire database upon new playlist generation requests.
2.4.6 离散优化 | Discrete optimization
将歌单生成问题看作是一个离散优化问题算是一个较为不同的思路:给定一个曲目集,它们的属性以及(描述想要得到的歌单的性质的)约束条件,目标是生成满足约束条件的任意一个或者最优的一个曲目序列. 限制条件的例子有:给定歌单的始末曲目, 歌单中的曲目必须来自至少 n 种不同的体裁,或者关于曲目之间(平滑)过渡的约束条件.
A quite different approach is to consider playlist generation as a discrete optimization problem. Given a set of tracks, their characteristics and a set of explicitly specified constraints capturing the desired characteristics, the goal is to create one arbitrary or an optimal sequence of tracks that satisfies the constraints. Examples for constraints could be a given start or end track, that the tracks in the playlist are taken from at least n different genres, or constraints related to the transitions between the tracks.
这些方法的优势在于,如果背景知识准确,只有那些满足全部 或大部分 目标属性的歌单被生成. 一个潜在的缺点是当曲目集很大时,高计算复杂性将让问题变得棘手.
The advantage of these approaches is that if the used background knowledge is accurate, only playlists will be generated that satisfy all or most of the target characteristics. A potential drawback is the high computational complexity which makes the problem intractable for larger music collections.
2.4.7 混合算法 | Hybrid techniques
为了取长补短,推荐系统(RS)领域会将不同的算法混合,下表是对七种混合方式的分类.
In order to combine the advantages of different techniques and at the same time avoid the drawbacks of individual techniques, hybridization is often used in the field of RS. The following is a classification in seven categories for hybridization of recommender systems.
| 混合方法 | 描述 |
|---|---|
| 权重法 | 综合每个推荐方法的得分 |
| 替换法 | 在不同的情况下选择不同的推荐方法 |
| 混合法 | 多种推荐结果同时呈现 |
| 特征结合 | 不同数据源的特征放在一起传入一个推荐算法 |
| 特征增强 | 一个方法的输出作为另一个方法的特征输入 |
| 流式法 | 一个推荐系统完善另一个推荐系统给出的推荐 |
| 元层面 | 一个推荐系统学习到的模型作为另一个推荐系统的输入 |
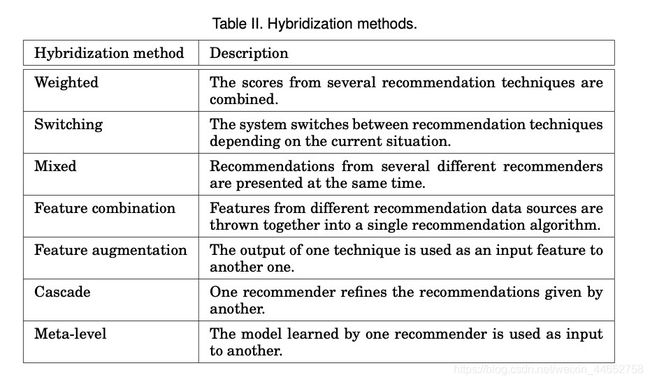
具体到歌单生成领域,论文作者列举了一下例子,我将之概括在下表.
Particularly, in the field of playlists generation, the author of the literature listed a few examples. I present them in the following table.
| 混合方法 | 描述 | 参考文献 |
|---|---|---|
| 权重法 | 综合基于曲目相似度、熟悉度和均匀分布 | [McFee 与 Lanckriet 2011] |
| 综合多标准基于kNN的CF和基于本体论的相似度算法 | [Chedrawy 与 Abidi 2009] | |
| 权重法 + 特征增强 | 首先从标签中提取潜在话题并从中抽离频繁模式. 结合频繁模式挖掘算法和kNN算法 | [Hariri 等人 2012] |
| 特征增强 | 综合从音频文件和歌词中提取的特征以产生符合某种情绪的歌单 | [Meyers 2007] |
| 从声学信号中推断特征并将之与人工标注的元数据相结合 | [Aucouturier 与 Pachet 2002c; Vignoli 与 Pauws 2005] | |
| 其它 | 在歌单生成领域之外的混合推荐算法 | [Burke 2002; Lampropoulos 等人 2012; Hornung 等人 2013] |
| Hybridization | Description | Reference |
|---|---|---|
| Weighted | Combines algorithms that rely on track similarity, track familiarity and the uniform distribution. | [McFee and Lanckriet 2011] |
| Combine a multi-criteria kNN-based collaborative filtering algorithm with an ontology-based item similarity approach. | [Chedrawy and Abidi 2009] | |
| Weighted + Feature augmentation | First extract latent topics from tags and then extract frequent patterns from them. Combine a frequent pattern mining approach with the kNN-approach. | [Hariri et al. 2012] |
| Feature combination | Features extracted from the audio file and lyrics are combined to generate playlists matching a certain mood. | [Meyers 2007] |
| Features are inferred from the audio signal and then combined with manually annotated meta-data. | [Aucouturier and Pachet 2002c; Vignoli and Pauws 2005] | |
| Others | Hybrid recommendations outside of the specific scope of playlist generation | [Burke 2002; Lampropoulos et al. 2012; Hornung et al. 2013] |
2.5 评估列表生成系统 | EVALUATING PLAYLIST GENERATION SYSTEMS
总体上说,用户满意度可以看作是评价生成的歌单的质量和是否有用的根本标准.
In general, user satisfaction could be considered as the ultimate criterion to assess the quality or usefulness of the generated playlists.
2.5.1 列表质量评价标准 | Quality criteria for playlists
第一个用于确定好歌单的普适准则的办法是:分析 用户创建并分享的 歌单的特征.
One first way to determine the general principles for a good playlist design is to analyze the characteristics of playlists that are created and shared by users.
另一个用于确定指导生成歌单的规则的实现方式,被[Cunningham 等人 2006]所使用,后者:研究了Art of the Mix论坛上发布的消息.
A different approach to determine the guiding rules of playlist creators was chosen by [Cunningham et al. 2006], who analyzed the messages posted on the Art of the Mix forum.
还有一个可能的实现是针对歌单的好坏标准进行用户调查.
Another possible approach is to perform user studies aimed at determining quality criteria for playlists.
接下来的这一段蕴含了一个潜在的博士课题.
A potential doctoral research is embodied in the following paragraph.
总体上讲,对于用户认为什么重要以及什么标准可以用于判断歌单的好坏,这些分析手段都给了我们深刻的洞悉. 然而,在我们看来,在这方面还需要更多的研究:一个可能可行的未来研究方向是系统地辨别出质量评价标准,正如[Wang 和 Strong 1996]在信息质量领域所做的那样.
Overall, such analyses give us important insights about what users find important and which criteria can be used to judge the quality of playlists. However, in our view, more research in that respect is required and one possible direction for future work could be a systematic approach for quality criteria identification as was done in [Wang and Strong 1996] for the Information Quality field.
2.5.2 评价方法 | Evaluation approaches for automatically generated playlists
2.5.2.1 用户调查 | User studies
用户调查是检验歌单的接受程度的很好的形式. 然而一个最大的缺点是这又贵有浪费时间.
User studies are a form of evaluation that helps us to determine the perceived quality of playlists with good confidence. One of the major drawbacks of such studies however is that they are time consuming and expensive.
2.5.2.2 日志分析 | Log analysis
除了询问用户的主观感受,人们还可以用分析听歌记录与交互记录的方式分析所生成的歌单的接受度.
Instead of asking the users about their subjective evaluations, one can look at how the generated playlists are accepted by the users by analyzing their behavior using listening and interaction logs.
2.5.2.3 客观手段 | Objective measures
我们定义客观手段为,可以近似模拟用户主观感受的自动化计算手段. 一个典型的例子是,歌单的多样性和同质性.
With the term objective measures, we refer to measures that can be automatically computed for a given playlist and which try to approximate a user-perceived subjective quality. A typical example for such a subjective measure is the diversity or homogeneity of a playlist.
2.5.2.4 与手工制作的歌单的对比 | Comparison with hand-crafted playlists
最后一类的评估方法是:评价算法复现手工制作的歌单的能力,其中,歌单指的是被音乐爱好者制作的歌单.
The final category of evaluation approaches discussed here is based on the estimation of the ability of the algorithms to reproduce hand-crafted playlists, i.e., playlists created by music enthusiasts.
论文中提到了该策略的两种标准.
The literature mentioned 2 measures that are based on the strategy.
- 命中率 | Hit rates
- 平均对数似然值 | Average log-likelihood(ALL)
2.5.3 其它衡量标准 | Other evaluation criteria for playlist generation systems
目前为止,我们探讨过了关于歌单本身性质的标准. 然而,当我们把歌单生成算法和其应用结合时,我们就产生了新的标准.
So far, we have focused on measures that are related to the quality of the playlists themselves. There are, however, additional criteria that can be considered when comparing playlist generation algorithms and the corresponding applications.
2.5.3.1 可延展性与计算复杂性 | Scalability and computational complexity
在许多应用领域,能动态地计算不同环境的歌单以及歌单的可延伸性是一个关键的要求. 如 last.fm 等的在线服务多多少少能就一系列给定的关键字当场生成歌单,一个个人电台应该能在合理的时间内对用户的“切歌”作出反应.
In many application domains, being able to dynamically compute contextualized playlists or playlist continuations is a crucial requirement. Online services such as last.fm should more or less be able to immediately create a playlist for a given set of keywords and a personalized radio station should be able to react to the skip actions of a user in a reasonable time frame.
2.5.3.2 用户付出 | User effort
许多广为接受的系统如 last.fm 或 iTunes Genius 提供相对简单的用以明析目标特性的机制. 这些机制中比较典型的有,选定种子曲目、就喜爱的体裁或艺术家的自由文本输入等.
Many popular systems including last.fm or the iTunes Genius provide relatively simple mechanisms for the user to specify the desired playlist characteristics. These mechanisms typically include the selection of a seed track or free text input that can correspond to the preferred genre or artist.
2.6 列表生成技术间的对比评价 | A COMPARATIVE EVALUATION OF PLAYLIST GENERATION TECHNIQUES
2.6.1 实验流程 | Experimental procedure
我们的实验基于手工歌单库,我们将之分为训练集(90%)和测试集(10%),进行10折交叉验证. 算法的任务是,在给定歌单的前几首曲目下,计算接下来的可能出现的曲目的分数(可能性).
Our experiments are based on pools of hand-crafted playlists which we randomly split into training (90%) and test set (10%) in a 10-fold cross-validation procedure. The task of the playlist generation algorithms is to compute scores (which can be probabilities) for the possible next tracks given the first tracks of each playlist in the test set.
2.6.1.1 算法 | Algorithms
这里仅列举了原文实验过的六种算法. 详情阅读原文.
Here are the six algorithms used in the experiment. Read the literature for more information.
- k最近邻 | kNN
- 关联规则 | Association Rules (AR)
- 序列模式 | Sequential Patterns (SP)
- 单一艺术家精选集法 | Same Artist – Greatest Hits (SAGH)
- 搭配艺术家精选集法 | Collocated Artists – Greatest Hits (CAGH)
- 流行度排序 | PopRank
2.6.1.2 数据集 | Datasets
我们使用了来自不同音乐平台的三种歌单.
We used three sets of playlists which we obtained from different music platforms.
- last.fm
- Art of the Mix (AotM)
- 8tracks
2.6.2 评估结果 | Evaluation results
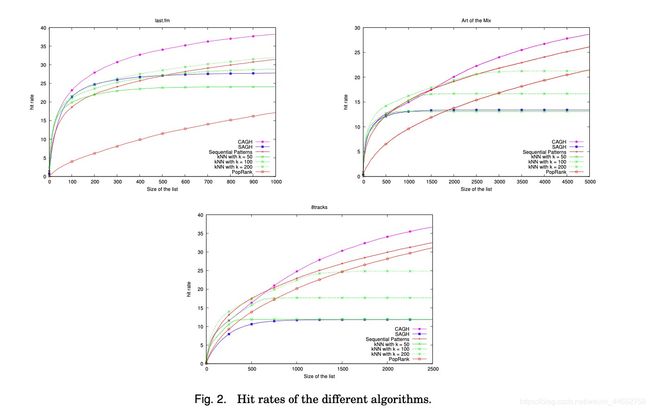
论文使用了命中率 而没有用平均对数似然 来评估算法输出的质量. 原因请见原文.
The literature preferred hit rates over ALL to measure the quality of the output of the algorithms. Refer to the complete article for the reason.
结果展示在下图.
The following figure shows the result.
计算复杂度与计算时间:
Computational complexity and running times:

2.7 研究视角与结论 | RESEARCH PERSPECTIVES AND CONCLUSIONS
2.7.1 数据视角 | Data perspective
论文中评估的用于明析目标特性的方法的使用频率:
Frequency of usage of methods reviewed in the literature to specify target characteristics:

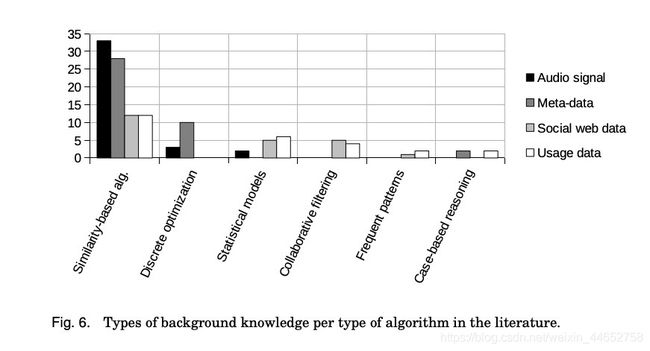
2.7.2 算法视角 | Algorithms perspective
论文中评估的算法与背景知识的使用频率:
Frequency of usage of algorithms and background knowledge reviewed in the literature:
2.7.3 评估视角 | Evaluation perspective
最后,尽管已经有许多的论文清晰地试图解决计算复杂性和可延展性,这个话题在我们严重还是需要更多的关注,特别是我们的实验已经反映出,某些先进的生成法并不能很好的延展,而且仅对于中等大小的问题需要长达数周的模型训练.
Finally, while there exists a number of papers that explicitly address questions of computational complexity and scalability, this topic needs in our view more attention, in particular as our experiments have shown that some advanced playlist generation methods do not scale well and require weeks of training already for medium-sized problem settings.
2.7.4 结论 | Conclusions
在这篇论文离,我们探讨了多种自动生成歌单的解决方案.
In this paper, we have reviewed different approaches to automatically generating music playlists.
在论文的第二段,基于不同的衡量标准,我们比较了现有的文献中的多种方法的质量和复杂度.
In the second part of the paper, we compared several of the existing techniques from the literature on different datasets using different measures of quality and complexity.
基于我们的文献研究和实验,我们最终描绘了集中可能的未来研究方向. 这些方向包括融会新的知识材料,以及使用更好更新的标准来刻画歌单的治疗.
Based on our literature review and the experiments we have finally sketched a number of possible directions for future research. These directions include the incorporation of additional knowledge sources and the use of additional measures that can help us to better characterize the quality of playlists.
2.8 附录 | APPENDIX
2.8.1 部分公开音乐数据集 | Examples for publicly available music datasets
2.8.1.1 公司提供之数据集 | Datasets provided by companies
- the database of last.fm
- Musicbrainz
- music database provided by The Echo Nest
2.8.1.2 研究团队提供之数据集 | Datasets provided by research groups
- the Million Song Dataset (MSD) [Bertin-Mahieux et al. 2011]
- dataset of the CUIDADO project [Pachet 2001; Vinet et al. 2002]
- A dataset of hand-crafted playlists made available by [McFee and Lanckriet 2012]
2.8.2 计算复杂性分析 | Computational complexity analysis
| 算法 | 分析 |
|---|---|
| k-最近邻 | 主要缺陷在于复杂度. 因为每一个被测验的歌单都是一个新的歌单,不能在线下过程提前计算相似度. |
| 频率模式 | 因为可以在线下提取一定量的相关性模式,这个算法理论上可以比 kNN 法节约计算时间和计算空间. |
| 单一艺术家精选集法(SAGH)与搭配艺术家精选集法(CAGH) | SAGH 的时间复杂度特别低. 给定一个歌单历史h,这个算法只需要检索到它们对应的艺术家即可. 这项任务的(时间)复杂度是 O(|h|). 而 CAGH 则相对稍微复杂一些,因为其还要考虑艺术家们之间的相似性. |
| Algorithm | Analysis |
|---|---|
| kNN | The major drawback of this algorithm is its complexity. Because each tested playlist history corresponds to a new playlist, no similarity can be calculated in advance in an offline process. |
| Frequent patterns | By extracting a limited set of relevant patterns in an offline process, this approach theoretically allows a lower time and space complexity than that of the kNN approach. |
| SAGH, CAGH | The time complexity of the SAGH algorithm is particularly low. Given a playlist history h, the algorithm only has to retrieve the corresponding artists. The complexity of this task is O(|h|). The time complexity of the CAGH is a little higher because the algorithm also considers similarities between artists. |
译者注:音乐体裁(Music Genre) ,不同于古典音乐的音乐体裁,这里更多地指区别于摇滚(Rock),爵士(Jazz),流行(Pop)等类型的体裁. ↩︎
具体输入参见2.3. ↩︎
See specified input in 2.3. ↩︎
译者注:又作混合高斯模型. ↩︎
将歌单视作用户时. | When considering playlists as users. ↩︎ ↩︎
这意味着模型使用者不必知道歌曲的内容,例如:是灵魂乐还是福音乐、是四拍子还是三拍子. ↩︎
This means that the model user do not necessarily need to know whether the song is Soul or Gospel, quadruple time or triple time. ↩︎
作者注:值得一提的是,频率模型挖掘也可以被视为是一种统计估计方法. ↩︎
Author’s note: Notice that frequent pattern mining approaches can also be considered as statistical estimation methods. ↩︎
本文的 2.6. ↩︎
2.6 in this article. ↩︎