【论文整理】小样本学习Few-shot learning论文整理收藏(最全,持续更新)
一、综述类
1. Generalizing from a Few Examples: A Survey on Few-Shot Learning
2. Generalizing from a few examples: A survey on few-shot learning, CSUR, 2020.
3. Rethinking few-shot image classification: a good embedding is all you need?ECCV2020.
4. Prototypical networks for few-shot learning,2017.
5. A survey of zero-shot learning: Settings, methods, and applications,ACM2019.
6. Meta-learning for few-shot natural language processing: A survey.2020.
二、数据集
1. Learning from one example through shared densities on transforms, in CVPR, 2000.
2. Domain-adaptive discriminative one-shot learning of gestures, in ECCV, 2014.
3. One-shot learning of scene locations via feature trajectory transfer, in CVPR, 2016.
4. Low-shot visual recognition by shrinking and hallucinating features, in ICCV, 2017.
5. Improving one-shot learning through fusing side information, arXiv preprint, 2017.
6. Fast parameter adaptation for few-shot image captioning and visual question answering, in ACM MM, 2018.
7. Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning, in CVPR, 2018.
8. Low-shot learning with large-scale diffusion, in CVPR, 2018.
9. Diverse few-shot text classification with multiple metrics, in NAACL-HLT, 2018.
10. Delta-encoder: An effective sample synthesis method for few-shot object recognition, in NeurIPS, 2018.
11. Low-shot learning via covariance-preserving adversarial augmentation networks, in NeurIPS, 2018.
12. AutoAugment: Learning augmentation policies from data, in CVPR, 2019.
13. EDA: Easy data augmentation techniques for boosting performance on text classification tasks, in EMNLP and IJCNLP, 2019.
三、小样本论文汇总
(一)基于Finetune
这种方法已被广泛地应用。获得一定量的标注数据,然后基于一个基础网络进行微调。
这个基础网络是通过含有丰富标签的大规模数据集获得的,比如imagenet,我们的淘宝电商数据,称为通用数据域。然后在特定数据域上进行训练。训练时,会固定基础网络部分的参数,对领域特定的网络参数进行训练(这里有很多训练的trick,包括如何设置固定层和学习率等),如下图所示。这个方法可以相对较快,依赖数据量也不必太多,效果还行。

参考论文:
Fine tuning现有参数
- Efficient k-shot learning with regularized deep networks, in AAAI, 2018.
- CLEAR: Cumulative learning for one-shot one-class image recognition, in CVPR, 2018.
- Learning structure and strength of CNN filters for small sample size training, in CVPR, 2018.
- Dynamic few-shot visual learning without forgetting, in CVPR, 2018.
- Low-shot learning with imprinted weights, in CVPR, 2018.
- Neural voice cloning with a few samples, in NeurIPS, 2018.
Fine tuning元学习参数
- Meta-learning with latent embedding optimization, in ICLR, 2019.
- Amortized bayesian meta-learning, in ICLR, 2019.
- The effects of negative adaptation in model-agnostic meta-learning, arXiv preprint, 2018.
- Few-shot human motion prediction via meta-learning, in ECCV, 2018.
- Recasting gradient-based meta-learning as hierarchical Bayes, in ICLR, 2018.
- Gradient-based meta-learning with learned layerwise metric and subspace, in ICML, 2018.
- Bayesian model-agnostic meta-learning, in NeurIPS, 2018.
(二)基于metric
如果在 Few-shot Learning 的任务中去训练普通的基于 cross-entropy 的神经网络分类器,那么几乎肯定是会过拟合,因为神经网络分类器中有数以万计的参数需要优化。
相反,很多非参数化的方法(最近邻、K-近邻、Kmeans)是不需要优化参数的,因此可以在 meta-learning 的框架下构造一种可以端到端训练的 few-shot 分类器。该方法是对样本间距离分布进行建模,使得同类样本靠近,异类样本远离。下面介绍相关的方法。
孪生网络(Siamese Network)
孪生网络 通过有监督的方式训练孪生网络来学习,然后重用网络所提取的特征进行 one/few-shot 学习。

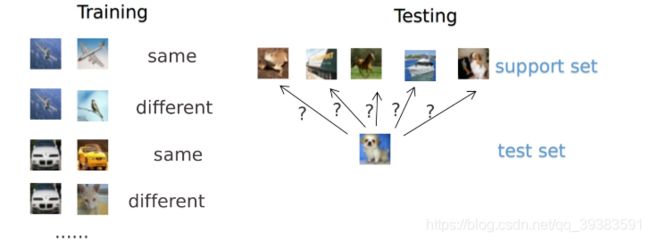
具体的网络是一个双路的神经网络,训练时,通过组合的方式构造不同的成对样本,输入网络进行训练,在最上层通过样本对的距离判断他们是否属于同一个类,并产生对应的概率分布。在预测阶段,孪生网络处理测试样本和支撑集之间每一个样本对,最终预测结果为支撑集上概率最高的类别。以5way-5shot为例,从5个类中随机抽取5个样本,把这个mini-batch=25的数据输入网络,最后获得25个值,取分数最高对应的类别作为预测结果(形式化来说,few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。即要求模型从 C*K 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题。 )。
参考论文:
- Siamese neural networks for one-shot image recognition.ICML2015.
匹配网络(matching networks)
相比孪生网络,匹配网络(Match Network) 为支撑集和 Batch 集构建不同的编码器,最终分类器的输出是支撑集样本和 query 之间预测值的加权求和。

如上图 所示,匹配网络是在不改变网络模型的前提下能对未知类别生成标签,其主要创新体现在建模过程和训练过程上。对于建模过程的创新,文章提出了基于 memory 和 attention 的 matching nets,使得可以快速学习。
关于训练策略。首先对imagenet进行的采样,制作了3种适合做one/few shot的数据集,其中miniImageNet,它包含100类,每类600张图片,其中80个类用来训练,20类用来测试, 称为后续相关研究经常被采用的数据集。以5-way 5-shot为例。训练时,在80类中随机采样5个类,然后把这5类中的数据分成支持集S和测试B,训练matching net模型来使得在S条件下的B的预测结果误差最小。测试时,在20个未被训练过的类中抽取5类,每类5张图,作为测试支持集S’。如下图,MatchNet方法相对原始的Inception模型能正确识别模型从未见过的轮胎和自行车。

参考论文:
- Matching networks for one shot learning.NIPS2016.
原型网络(Prototype Network)
基于这样的想法:每个类别都存在一个原型表达,该类的原型是 support set 在 embedding 空间中的均值。然后,分类问题变成在 embedding 空间中的最近邻。

如图 所示,c1、c2、c3 分别是三个类别的均值中心(称 Prototype),将测试样本 x 进行 embedding 后,与这 3 个中心进行距离计算,从而获得 x 的类别。
参考论文:
- Prototypical networks for few-shot learning.2017.
关系网络(Relation Network)
前面介绍的几个网络结构在最终的距离度量上都使用了固定的度量方式,如 cosine,欧式距离等,这种模型结构下所有的学习过程都发生在样本的 embedding 阶段。而 Relation Network认为度量方式也是网络中非常重要的一环,需要对其进行建模,所以该网络不满足单一且固定的距离度量方式,而是训练一个网络来学习(例如 CNN)距离的度量方式,在 loss 方面也有所改变,考虑到 relation network 更多的关注 relation score,更像一种回归,而非 0/1 分类,所以使用了 MSE 取代了 cross-entropy。
参考论文:
- Learning to compare: Relation network for few-shot learning.CVPR2018.
(三)基于元学习meta learning
通过大量的数据,现在的AI系统能从0开始学习一个复杂的技能。我们希望AI系统能获得多种技能并能适应各种环境,但针对每种技能都从0开始训练是无法承受的。因此,我们希望它能够从之前的经验快速地学习新的技能,而不是把新的任务孤立地考虑。这个方法,我们称为元学习(learning to learn,或meta learning), 使得我们的系统在它的整个生命周期中可以持续地学习各种各样的任务。
meta learning是机器学习的一个子领域,它自动学习一些应用于机器学习实验的元数据,主要目的是使用这些元数据来自动学习如何在解决不同类型的学习问题时变得灵活,从而提高现有的学习算法。灵活性是非常重要的,因为每个学习算法都是基于一组有关数据的假设,即它是归纳偏(bias)的。这意味着如果bias与学习问题中的数据相匹配,那么学习就会很好。学习算法在一个学习问题上表现得非常好,但在下一个学习问题上表现得非常糟糕。这对机器学习或数据挖掘技术的使用造成了很大的限制,因为学习问题与不同学习算法的有效性之间的关系尚不清楚。
通过使用不同类型的元数据,如学习问题的属性,算法属性(如性能测量)或从之前数据推导出的模式,可以选择、更改或组合不同的学习算法,以有效地解决给定的学习问题。
元学习一般有两级,第一级是快速地获得每个任务中的知识,第二级是较慢地提取所有任务中学到的信息。下面从不同角度解释了元学习的方法
- 通过知识诱导来表达每种学习方法如何在不同的学习问题上执行,从而发现元知识。元数据是由学习问题中的数据特征(一般的,统计的,信息论的......)以及学习算法的特征(类型,参数设置,性能测量...)形成的。然后,另一个学习算法学习数据特征如何与算法特征相关。给定一个新的学习问题,测量数据特征,并且可以预测不同学习算法的性能。因此,至少在诱导关系成立的情况下,可以选择最适合新问题的算法。
- stacking. 通过组合一些(不同的)学习算法,即堆叠泛化。元数据是由这些不同算法的预测而形成的。然后,另一个学习算法从这个元数据中学习,以预测哪些算法的组合会给出好的结果。在给定新的学习问题的情况下,所选择的一组算法的预测被组合(例如通过加权投票)以提供最终的预测。由于每种算法都被认为是在一个问题子集上工作,所以希望这种组合能够更加灵活,并且能够做出好的预测。
- boosting. 多次使用相同的算法,训练数据中的示例在每次运行中获得不同的权重。这产生了不同的预测,每个预测都集中于正确预测数据的一个子集,并且结合这些预测导致更好(但更昂贵)的结果。
- 动态偏选择(Dynamic bias selection)通过改变学习算法的感应偏来匹配给定的问题。这通过改变学习算法的关键方面来完成,例如假设表示,启发式公式或参数。
- learning to learn,研究如何随着时间的推移改进学习过程。元数据由关于以前的学习事件的知识组成,并被用于高效地开发新任务的有效假设。其目标是使用从一个领域获得的知识来帮助其他领域的学习。
Optimization Based方法((meta-learning LSTM))
文章研究了在少量数据下,基于梯度的优化算法失败的原因,即无法直接用于meta learning。首先,这些梯度优化算法包括momentum, adagrad, adadelta, ADAM等,无法在几步内完成优化,特别是在非凸的问题上,多种超参的选取无法保证收敛的速度。其次,不同任务分别随机初始化会影响任务收敛到好的解上。虽然finetune这种迁移学习能缓解这个问题,但当新数据相对原始数据偏差比较大时,迁移学习的性能会大大下降。我们需要一个系统的学习通用初始化,使得训练从一个好的点开始,它和迁移学习不同的是,它能保证该初始化能让finetune从一个好的点开始。
文章学习的是一个模新参数的更新函数或更新规则。它不是在多轮的episodes学习一个单模型,而是在每个episode学习特定的模型。具体地,学习基于梯度下降的参数更新算法,采用LSTM表达meta learner,用其状态表达目标分类器的参数的更新,最终学会如何在新的分类任务上,对分类器网络(learner)进行初始化和参数更新。这个优化算法同时考虑一个任务的短时知识和跨多个任务的长时知识。文章设定目标为通过少量的迭代步骤捕获优化算法的泛化能力,由此meta learner可以训练让learner在每个任务上收敛到一个好的解。另外,通过捕获所有任务之前共享的基础知识,进而更好地初始化learner。

以训练 miniImage 数据集为例,训练过程中,从训练集(64 个类,每类 600 个样本)中随机采样 5 个类,每个类 5 个样本,构成支撑集,去学习 learner;然后从训练集的样本(采出的 5 个类,每类剩下的样本)中采样构成 Batch 集,集合中每类有 15 个样本,用来获得 learner 的 loss,去学习 meta leaner。
测试时的流程一样,从测试集(16 个类,每类 600 个样本)中随机采样 5 个类,每个类 5 个样本,构成支撑集 Support Set,去学习 learner;然后从测试集剩余的样本(采出的 5 个类,每类剩下的样本)中采样构成 Batch 集,集合中每类有 15 个样本,用来获得 learner 的参数,进而得到预测的类别概率。这两个过程分别如上图中虚线左侧和右侧。
meta learner 的目标是在各种不同的学习任务上学出一个模型,使得可以仅用少量的样本就能解决一些新的学习任务。这种任务的挑战是模型需要结合之前的经验和当前新任务的少量样本信息,并避免在新数据上过拟合。
参考论文:
- Optimization as a model for few-shot learning.ICLR2017.
递归记忆模型 (Memory-Augmented Neural Networks)
基于记忆的神经网络方法通过权重更新来调节bias,并且通过学习将表达快速缓存到记忆中来调节输出。然而,利用循环神经网络的内部记忆单元无法扩展到需要对大量新信息进行编码的新任务上。因此,我们需要让存储在记忆中的表达既要稳定又要是元素粒度访问的,前者是说当需要时就能可靠地访问,后者是说可选择性地访问相关的信息;另外,参数数量不能被内存的大小束缚。像神经图灵机(NTMs)和记忆网络就符合这种必要条件。
文章基于神经网络图灵机(NTMs)的思想,因为NTMs能通过外部存储(external memory)进行短时记忆,并能通过缓慢权值更新来进行长时记忆,NTMs可以学习将表达存入记忆的策略,并如何用这些表达来进行预测。由此,文章方法可以快速准确地预测那些只出现过一次的数据。文章基于LSTM等RNN的模型,将数据看成序列来训练,在测试时输入新的类的样本进行分类。具体地,网络的输入把上一次的y (label)也作为输入,并且添加了external memory存储上一次的x输入,这使得下一次输入后进行反向传播时,可以让y (label)和x建立联系,使得之后的x能够通过外部记忆获取相关图像进行比对来实现更好的预测。这里的RNN就是meta-learner。

参考论文:
- Meta-learning with memory-augmented neural networks.ICML2016.
模型无关自适应(Model-Agnostic)
meta learning 的目标是在各种不同的学习任务上学出一个模型,使得可以仅用少量的样本就能解决一些新的学习任务。这种任务的挑战是模型需要结合之前的经验和当前新任务的少量样本信息,并避免在新数据上过拟合。
文章提出的方法使得可以在小量样本上,用少量的迭代步骤就可以获得较好的泛化性能,而且模型是容易fine-tine的。而且这个方法无需关心模型的形式,也不需要为meta learning增加新的参数,直接用梯度下降来训练learner。文章的核心思想是学习模型的初始化参数使得在一步或几步迭代后在新任务上的精度最大化。它学的不是模型参数的更新函数或是规则,它不局限于参数的规模和模型架构(比如用RNN或siamese)。它本质上也是学习一个好的特征使得可以适合很多任务(包括分类、回归、增强学习),并通过fine-tune来获得好的效果。
文章提出的方法,可以学习任意标准模型的参数,并让该模型能快速适配。方法认为,一些中间表达更加适合迁移,比如神经网络的内部特征。因此面向泛化性的表达是有益的。因为我们会基于梯度下降策略在新的任务上进行finetune,所以目标是学习这样一个模型,它能对新的任务从之前任务上快速地进行梯度下降,而不会过拟合。事实上,是要找到一些对任务变化敏感的参数,使得当改变梯度方向,小的参数改动也会产生较大的loss,如图

该方法的目标函数如下,即训练关于全局模型参数θ的具体任务参数θ‘,使其在从p(T )上采样的各个任务上误差最小。

整个训练的流程如下伪代码,有内外两个循环,外循环是训练meta learner的参数θ,即一个全局的模型,内循环对每个采样任务分别做梯度下降,进而在全局模型上做梯度下降(a gradient through a gradient)。

参考论文:
- Model-agnostic meta-learning for fast adaptation of deep networks.2017.
最新论文推荐:
2021:
-
Mutual CRF-GNN for Few-Shot Learning;
-
Reinforced attention for few-shot learning and beyond;
-
Domain-adaptive few-shot learning;
-
Shot in the dark: Few-shot learning with no base-class labels;
-
Free lunch for few-shot learning: Distribution calibration;
-
Few-shot learning creates predictive models of drug response that translate from high-throughput screens to individual patients;
-
Prototype Completion with Primitive Knowledge for Few-Shot Learning;
-
Adargcn: Adaptive aggregation GCN for few-shot learning;
-
Multimodal Prototypical Networks for Few-shot Learning;
-
Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning;
-
pDeep3: Toward More Accurate Spectrum Prediction with Fast Few-Shot Learning;
-
ReMP: Rectified Metric Propagation for Few-Shot Learning;
-
Learning adaptive classifiers synthesis for generalized few-shot learning;
-
Parameterless Transductive Feature Re-representation for Few-Shot Learning;
-
Learning Dynamic Alignment via Meta-filter for Few-shot Learning;
-
Few-shot few-shot learning and the role of spatial attention;
-
Self-augmentation: Generalizing deep networks to unseen classes for few-shot learning;
-
Rethinking Class Relations: Absolute-relative Supervised and Unsupervised Few-shot Learning;
-
Partial Is Better Than All: Revisiting Fine-tuning Strategy for Few-shot Learning;
-
Multi-Pretext Attention Network for Few-shot Learning with Self-supervision;
-
Local Propagation for Few-Shot Learning;
-
Learning a Few-shot Embedding Model with Contrastive Learning;
-
A Few-Shot Learning Approach for Accelerated MRI via Fusion of Data-Driven and Subject-Driven Priors;
-
Embedding Adaptation is Still Needed for Few-Shot Learning;
2020:
-
Generalizing from a few examples: A survey on few-shot learning;
-
A new meta-baseline for few-shot learning;
-
Adaptive subspaces for few-shot learning;
-
Interventional few-shot learning;
-
Dpgn: Distribution propagation graph network for few-shot learning;
-
When does self-supervision improve few-shot learning?;
-
Few-shot learning via embedding adaptation with set-to-set functions;
-
Laplacian regularized few-shot learning;
-
Boosting few-shot learning with adaptive margin loss;
-
Prototype rectification for few-shot learning;
-
Leveraging the feature distribution in transfer-based few-shot learning;
-
Few-shot learning via learning the representation, provably;
-
Instance credibility inference for few-shot learning;
-
Diversity transfer network for few-shot learning;
-
Graph few-shot learning via knowledge transfer;
-
Transmatch: A transfer-learning scheme for semi-supervised few-shot learning;
-
Meta-learning of neural architectures for few-shot learning;
-
An overview of deep learning architectures in few-shot learning domain;
-
Adversarial feature hallucination networks for few-shot learning;
-
Charting the right manifold: Manifold mixup for few-shot learning;
-
Xtarnet: Learning to extract task-adaptive representation for incremental few-shot learning;
-
Learning to learn adaptive classifier-predictor for few-shot learning;
-
Transductive Relation-Propagation Network for Few-shot Learning;
-
Few-shot learning for domain-specific fine-grained image classification;
-
Automatic detection of rare pathologies in fundus photographs using few-shot learning;
-
Attentive weights generation for few shot learning via information maximization;
-
Knowledge-guided multi-label few-shot learning for general image recognition;
-
MELR: Meta-learning via modeling episode-level relationships for few-shot learning;
-
Rethinking few-shot image classification: a good embedding is all you need?
2019:
- Meta-transfer learning for few-shot learning;
- A closer look at few-shot classification;
- Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning;
- A baseline for few-shot image classification;
-
Distribution consistency based covariance metric networks for few-shot learning;
-
Lgm-net: Learning to generate matching networks for few-shot learning;
-
Few-shot learning via saliency-guided hallucination of samples;
-
Transductive episodic-wise adaptive metric for few-shot learning;
-
Boosting few-shot visual learning with self-supervision;
-
Few-shot learning-based human activity recognition;
-
Edge-labeling graph neural network for few-shot learning;
-
Adaptive cross-modal few-shot learning;
-
A two-stage approach to few-shot learning for image recognition;
-
Tapnet: Neural network augmented with task-adaptive projection for few-shot learning;
-
Large-scale few-shot learning: Knowledge transfer with class hierarchy;
-
Simpleshot: Revisiting nearest-neighbor classification for few-shot learning;
-
Task agnostic meta-learning for few-shot learning;
-
Generalized zero-and few-shot learning via aligned variational autoencoders;
-
Generating classification weights with gnn denoising autoencoders for few-shot learning;
-
Variational few-shot learning;
-
Dense classification and implanting for few-shot learning;
-
Infinite mixture prototypes for few-shot learning;
-
Few-shot learning with localization in realistic settings;
-
Few-shot learning with global class representations;
-
Finding task-relevant features for few-shot learning by category traversal;
-
Revisiting local descriptor based image-to-class measure for few-shot learning;
-
Holodetect: Few-shot learning for error detection;
参考文章:
-
当小样本遇上机器学习 fewshot learning;
-
小样本学习(Few-shot Learning)综述;