CS224n 斯坦福深度自然语言处理课笔记 Lecture02—词向量表示
课程概要
1.词义
2.Word2vec介绍(学习词汇向量模型(2013年提出))
(当然还有别的方法进行词汇表征(后续会提到))
3.Word2vec目标函数的梯度推导
4.目标函数优化:梯度下降法
一、词义
定义:meaning:(Webster dictionary)用单词、短语等表达的想法;人们想要通过单词、符号等表达想法
某种意义上来说,这非常接近于语言学上最常理解的meaning的含义
利用分类资源,例如处理词义的方法是WordNet
WordNet:意义相近的单词组成一个同义词组(Synset),而同义词组之间则以上-下义,同义-反义,整体-部分以及蕴含等语义关系连接在一起,构成一个由同义词组作为结点,语义关系作为边的网状结构。(给每个单词对应的上下义关系以及同义词集合)
from nltk.corpus import wordnet as wn
panda = wn.synset('panda.n.01')
hyper = lambda s : s.hypernyms()
list(panda.closure(hyper))
如果以上代码不成功需要重新安装nltk库:https://blog.csdn.net/gggggertie/article/details/80148765
以上代码执行后的结果为:
更加详细的wordnet使用方法可参照:https://blog.csdn.net/King_John/article/details/80252594
WordNet的缺点
1.会忽略一些细微差别,比如同义词之间的差别(good, expert是同义词,但存在差别)
2.无法即时收录一些新的单词
3.主观性
4.需要花费人工去修正和创造
5.很难准确去计算单词之间的相似程度
分类表征普遍存在的问题
传统NLP(几乎所有,除了现代深度学习和80年代的神经网络),用原子符号(atomic symbols)来表示单词。
即用one-hot向量(独热编码)来表示。
it is a localist representation.(这是一个本地的表示)
 使用原子符号就像是使用一个只有一个位置是1,其他都是0 的大向量。那么,我们有了大量的与原子符号相对应的词汇。在这个向量某个位置为1,就代表一个特定的符号,比如酒店。
使用原子符号就像是使用一个只有一个位置是1,其他都是0 的大向量。那么,我们有了大量的与原子符号相对应的词汇。在这个向量某个位置为1,就代表一个特定的符号,比如酒店。
问题
1.维度会非常大;
2.没有表示出词汇间的内在联系(did not give any inherent notion of similarity),这存在于传统机器学习算法中

在这里它们的乘积为0,表示没有内在相似性。
解决方法:分布相似性
建立一套词汇之间完全独立的相似性关系。
构造能够表示单词含义的向量,通过单词向量之间点乘的结果,从而了解两个单词的相似度。
NLP概念称作分布相似性:通过单词出现的上下文来描述词汇的意思,并对这些上下文做一些处理来得到。
e.g. 要想知道‘banking’的含义:通过找到数千个包含‘banking’的例句,然后观察每一次它出现的场合,会看到经常和它一起出现的’governments’, ‘debt problems’, ‘regulations’, ‘Europe’,‘unified’,然后开始统计所有出现的内容,通过某种方式用这些上下文中的词来表示banking的含义。
“You shall know a word by the company it kepps”
你应该通过一个单词的同伴知道它的意思。
我们接下来要做的就是给每一个单词构造一个向量,我们会选择一个密集向量,让它可以预测目标单词所在文本的其他词汇。
二、Word2vec
词嵌入模型
词嵌入模型(word embedding model):用中心词汇预测它上下文的词汇,或预测给定单词的上下文单词出现的概率。

损失函数 J 可以用来计算出预测的准确率, 其中Wt 表示中心词汇 t ,W-t表示围绕在 t 中心词周围的其他词汇。训练模型的目标就是要最小化损失函数。
词汇的向量表示的概念在1986年被第一次提出,但没有被重视。
相关论文:
• Learning representations by back-propagating errors (Rumelhart et al., 1986)
• A neural probabilistic language model (Bengio et al., 2003)
• NLP (almost) from Scratch (Collobert & Weston, 2008)
Word2cev核心是构建一个很简单的、可扩展的、快速的训练模型,让我们可以处理数十亿单词文本,并生成非常棒的单词表示。
Word2vec主要用途是预测每一个单词和它上下文的词汇。

基础算法之一:Skip-grams
概念:在每一个估算的步骤中取一个词作为中心词汇,尝试预测它在一定窗口大小(window size)下的上下文单词。这个模型将定义一个概率分布——以这个词为中心词汇的情况下,某个单词在它上下文出现的概率;训练模型的过程就是选取词汇的向量表示来让概率分布值最大化。对一个词汇,有且只有一个概率分布。
求目标函数
我们要做的就是定义一个半径为m,然后从中心词汇开始,到距离为m的位置来预测周围的词汇,然后我们会在多处进行多次重复操作,选择词汇向量,以便于让预测的概率达到最大。因此损失函数或者说是目标函数,即 J 。

为了方便计算,将求积转化为求和,也就是对该函数进行取对数的计算,可以得到负的对数似然,即模型的负对数分布:

在这里,θ 指的是词汇的向量表示,也是每个词汇向量表示的唯一参数;这里的 1/T 相当于对每一个词汇进行归一化处理,避免计算整个语料库的概率,而是取每个位置上的平均值;- 是为了将最大化转为最小化,如果你喜欢最大化,你也可以不加。
注:包含了几个超参,例如窗口大小、容差系数都是可以调试的,但现在我们先将它当作常数。
Softmax概率分布:
由单词向量构造而成的中心词汇,来得出其上下文单词的概率分布。
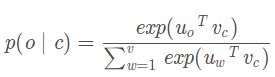
c (中心单词)和o (输出单词)都代表单词在词汇表空间中的索引以及它的类型,u 0和vc是向量。
![]()
点积越大,相似性越大,所以这是点积衡量相似性的方法。

Softmax形式是一种将数值转换为概率的标准方法,当计算点积时仅仅是数值、是实数,不能直接转换为概率分布,最简单的做法就是转换成指数,因为是要你求一个数的指数,其结果一定落在一个正区间,结果为正,这就为了求解概率分布提供了一个很好的基础。
对它们求和,然后用将各项依次除以总和,就能得到它们的概率分布了,接下来要对这个概率进行归一化处理。
每一个单词都有两个向量表示,一个表示它是词,一个表示它是上下文。

上图:一个中心词汇,它是一个独热向量,然后有一个所有中心词汇的表示组成的矩阵,如果将这个矩阵与向量相乘,我们选出这个矩阵的列(代表的就是中心词汇的表示);接下来构造第二个矩阵,用于存储上下文词汇的表示对于上下文的位置只列举了三个(图中最后一列),我们挑出中心词汇和上下文表示的点积,那么,对每个位置来说都是同一个矩阵,我们只有一个上下文词汇矩阵,得出了他们的点积;然后用softmax方法,将他们转化成概率分布,给定一个中心词汇,作为一个生成模型,它可以预测在上下文中出现的词汇的概率。
实际效果就是初始化所有词的向量,把词向量的矩阵当做参数来训练。
训练模型
我们将模型的所有参数(即所有单词的两种向量表示)的集合定义为,然后我们进行优化,通过改变这些参数让模型的目标方程最大化。
所有我们要的参数是对每个单词,我们都有一个d维的小向量(不管它是中心词汇还是上下文词汇),这也难怪我们定义了一个一定大小的单词表,这样我们就有一个代表上下文中aardvark的向量。一个代表上下文单词a的向量,我们有一个以aardvark为中心词汇的向量,这个向量的总长度为2dv。
对于整个问题的求解而言,求解的参数就是每个单词对应的两个向量的值,假设有V个单词,向量是d维的话,一共要求解2dv个参数。

三、word2vec目标函数的梯度推导
利用公式有:
(1)负对数分布:

(2)Softmax概率分布:
得到了目标函数,想要最小化它的负对数似然,思路就是要调整参数(也就是这些向量),以便让负的对数似然项最小化,从而使预测的概率最大化(如图)。

那么该怎么调整参数呢?
![]()
求偏导,然后拆成两部分求解:

第二部分用链式法则:

这里就是之前提到的Softmax概率分布(softmax probability distribution)

=实际输出的上下文词汇 — 期望形式(通过计算上下文可能出现的每个单词的概率来得到这个期望)
四、目标函数优化:梯度下降法
调整模型中的参数,为了使他们(实际、期望)相等。

写成python代码:
while True:
theta_grad = evaluate_gradient(J,corpus,theta)
theta = theta - alpha * theta_grad
这里注意 alpha 的取值,尽可能取值小一点
为了减少训练时间,一般采用随机梯度下降(SGD),先进行采样,粗略估计梯度,这样能快上几个数量级:
我们只选择文本中的一个位置,即有了一个中心词汇以及它周围的词汇,随机梯度法每次只选取一个样本进行梯度的计算,这样的话会引入大量的噪音(noisy),对于自然语言处理的研究而言,这样的噪音是有益的。所以,在NLP会大量得应用随机梯度下降。
while True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J,window,theta)
theta = theta - alpha * theta_grad