Python 处理GBK编码转UTF-8读写乱码问题
今日写了个爬虫,爬取前程无忧的招聘信息
老套路,首先获取网页源代码
#-*- coding:utf-8 -*-
import requests
url = 'http://search.51job.com/jobsearch/search_result.php?'
page_req = requests.get(url)
page = page_req.text.encode('utf-8')
print page结果,中文乱码:

浏览器查看,前程无忧源代码,是GBK编码,好吧,转GBK

非法字符,好吧,高级点,我转GB18030
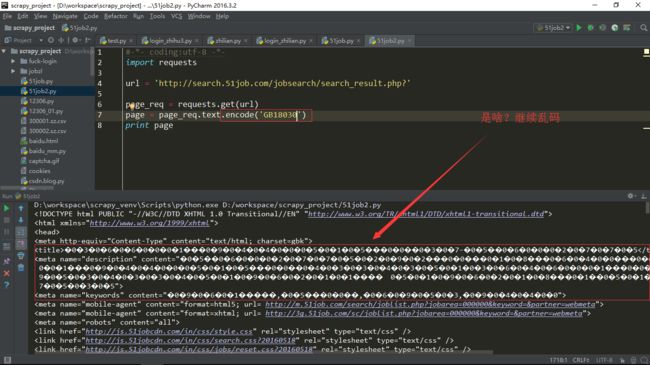
尼玛,又是一种奇怪的字符,继续整,找网页帖子,大概是说先解码成GBK再转UTF_8 把 page = page_req.text.decode('gbk').encode('utf-8') 改成这样
问题是,Python默认字符是ASCII的,decode('GBK')或decode('GB18030')都不成,非法啊。
后来,去stackoverflow看了看,找到了答案,先编码成iso-8859-1在转GBK,问题完美解决 page = page_req.text.encode('iso-8859-1').decode('gbk')

参考:http://stackoverflow.com/questions/23103485/convert-gbk-to-utf8-string-in-python