QNX Easy start : chapter 2 message passing
chapter 2 message passing
消息基础
在本章中,我们将介绍Neutrino的最鲜明特征,即消息传递。
消息传递是操作系统微内核体系结构的核心,使操作系统OS具有模块化功能。
小内核和消息传递
Neutrino的主要优点之一是可扩展。
所谓“可扩展”,是指它可以针对具有严格内存限制的微型嵌入式盒进行定制,直至具有几乎无限内存的大型多处理器SMP盒网络。
Neutrino通过将每个服务提供组件模块化来实现其可伸缩性。这样,您可以仅在最终系统中包括所需的组件。通过在设计中使用线程,您还将帮助使其可扩展到SMP系统,我们将在本章中看到线程的更多用法)
这是QNX操作系统系列的初始设计期间所使用的理念,并一直延续到今天。关键是小型微内核架构,其模块传统上将作为可选组件合并到单片内核中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h4Q6iwgD-1584938299285)(DraggedImage.png)]
您,系统架构师,决定所需的模块。您的项目中需要文件系统吗?如果是这样,则添加一个。如果您不需要一个,那就不用费心了。需要串口驱动程序吗?答案是肯定还是否,这不会影响(也不会受到)您先前有关文件系统的决定。
在运行时,您可以决定正在运行的系统中包括哪些系统组件。您可以动态地从活动系统中删除组件,然后在其他时间重新安装它们或其他组件。
这些“驱动程序”有什么特别之处吗?不会,它们只是常规的用户级程序,它们恰巧通过硬件执行特定的工作。实际上,我们将在“资源管理器”一章中看到如何编写它们。
完成此操作的关键是消息传递。在Neutrino下,这些模块不是将OS模块直接绑定到内核中,而是与内核进行某种“特殊”安排,而是通过它们之间的消息传递进行通信。内核基本上只负责线程级服务(例如调度)。实际上,消息传递不仅仅用于此安装和卸载技巧,它是几乎所有其他服务的基本构建块(例如,内存分配是通过给进程管理器的消息执行的)。当然,某些服务是通过直接内核调用提供的。
考虑打开文件并向其中写入数据块。这是通过从应用程序发送到Neutrino的可安装组件(称为文件系统)的许多消息来完成的。该消息告诉文件系统打开文件,然后另一条消息告诉文件系统写入一些数据(并包含该数据)。不过,请不要担心-Neutrino操作系统可以非常快速地执行消息传递。
消息传递和客户端/服务器
想象一个应用程序从文件系统读取数据。在QNX术语中,该应用程序是客户端从服务器请求数据。此客户端/服务器模型介绍了与消息传递相关的几种流程状态(我们在“进程和线程”一章中讨论了这些状态)。
最初,服务器正在等待消息从某个地方到达。此时,服务器将被辅助接收(也称为RECV状态)。这是一些pidin输出示例:

在上面的示例中,pseudo-tty服务器(称为devc-pty)的进程ID为4,具有一个线程(线程ID为1),以优先级10 Round-Robin运行,并被接收阻塞,等待来自channel ID 1(我们很快就会看到有关“channel”的所有信息)。

收到消息后,服务器将进入“就绪READY”状态,并且可以运行。如果它恰好是优先级最高的READY进程,它将获取CPU并可以执行一些处理。由于它是服务器,因此它会查看刚刚收到的消息并决定如何处理。在某个时候,服务器将完成消息告诉它要做的任何工作,然后“回复reply”到客户端。
让我们切换到客户端。最初,客户端一直在运行,消耗CPU,直到决定发送消息为止。客户端从READY变为发送send-blocked or reply-blocked,这取决于它向其发送消息的服务器的状态。
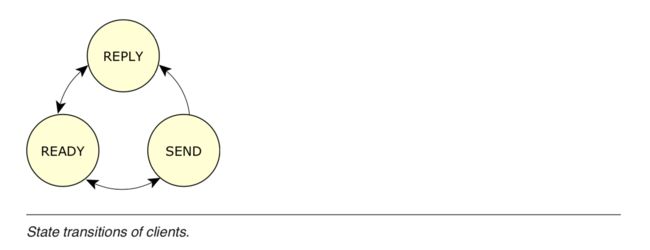
通常,与send-blocked状态相比,您会经常看到reply-blocked状态。那是因为回复阻止状态意味着:
服务器已收到该消息,现在正在处理它。在某个时候,服务器将完成处理并回复客户端。客户端被阻止等待此回复。
将此与发送阻止状态进行对比:
服务器尚未收到该消息,很可能是因为它正忙于先处理另一条消息。当服务器到处“接收”(客户端)消息时,您将从发送阻止状态变为回复阻止状态。
实际上,如果您看到一个被发送阻止的进程,则意味着两件事之一:
- 在服务器正忙于为客户端提供服务并且新请求到达该服务器的情况下,您碰巧为系统制作了快照snapshot。这是正常情况-您可以通过再次运行pidin来获取新快照snapshot来进行验证。这次您可能会发现该进程不再被发送阻止。
- 服务器遇到错误,并且由于任何原因不再监听请求。发生这种情况时,您会看到许多进程在一台服务器上被发送阻止。为了验证这一点,请再次运行pidin,观察到客户端进程的阻塞状态没有变化。
这是一个示例,显示了被阻止答复的客户端和被阻止block的服务器:

这表明程序esh(嵌入式外壳程序)已向进程1(内核和进程管理器procnto)发送了一条消息,并且正在等待答复。现在您知道了客户机/服务器体系结构中消息传递的基础。
所以现在您可能在想:“我是否必须编写特殊的Neutrino消息传递调用才能打开文件或写入一些数据?!?”
您无需编写任何消息传递功能,除非您希望获得**“下引擎盖 under the hood”(稍后再讨论)。实际上,让我向您展示一些实现消息传递**的客户端代码:

消息传递是由Neutrino C库完成的。您只需发出标准POSIX 1003.1或ANSI C函数调用,C库即可为您完成消息传递工作。
在上面的示例中,我们看到了三个函数被调用并且三个清晰消息正在发送。
当我们查看资源管理器时(在“资源管理器”一章中),我们将更详细地讨论消息本身,但是现在您只需要知道发送了不同类型的消息这一事实即可。让我们退一步,将其与示例在传统操作系统中的工作方式进行对比。
客户端代码将保持不变,而差异将被供应商提供的C库隐藏。在这样的系统上,open()函数调用将调用一个内核函数,该内核函数随后将直接调用文件系统,该文件系统将执行一些代码并返回文件描述符。 write()和close()调用将做同样的事情。
所以?用这种方式做事有好处吗?继续阅读!
- 服务器遇到错误,并且由于任何原因不再监听请求。发生这种情况时,您会看到许多进程在一台服务器上被发送阻止。为了验证这一点,请再次运行pidin,观察到客户端进程的阻塞状态没有变化。
网络分布的消息传递
假设我们要更改上面的示例以与网络上的其他节点通信。您可能会认为我们必须调用特殊的函数调用才能“联网”。这是网络版本的代码:

如果您认为两个版本中的代码几乎相同,那您是对的。
在传统的OS中,C库open()调用内核,内核查看文件名并说“哎呀,这是在另一个节点node上”。然后,内核调用网络文件系统(NFS)代码,该代码确定/ net / wintermute / home / rk / filename的实际位置。然后,NFS调用网络驱动程序,并向节点wintermute上的内核发送消息,然后重复我们在原始示例中描述的过程。
请注意,在这种情况下,实际上涉及两个文件系统。一种是NFS客户端文件系统,另一种是远程文件系统。不幸的是,由于不兼容,取决于远程文件系统和NFS的实现,某些操作可能无法按预期incompatibilities进行(例如,文件锁定)。
在Neutrino下,C库open()创建与发送到本地文件系统相同的消息,并将其发送到节点wintermute上的文件系统。在本地和远程情况下,使用exact相同的文件系统。
这是Neutrino的另一个基本特征:网络分发的操作基本上是“免费的”,因为已经通过消息传递完成了将客户端的功能需求与服务器提供的服务脱钩的工作。在传统内核上,有一个“双重标准”,其中本地服务以一种方式实现,而远程(网络)服务则以完全不同的方式实现。
What it means for you
消息传递是优雅的并且是网络分布的。所以呢?程序员,您能得到什么?
好吧,这意味着您的程序继承了这些特性-它们也可以通过网络分发,而工作量却比在其他系统上少得多。但是我发现最有用的好处是,它们使您能够以一种很好的模块化方式modular manner来测试软件。
您可能已经在大型项目中工作,其中许多人必须提供不同的软件。当然,这些人中有些人早晚做。
这些项目通常有两个阶段的问题:最初是在项目定义时,很难确定一个人的开发工作在哪里结束而另一个人开始了,然后在测试/集成时,不可能进行完整的系统集成测试。因为所有的东西都不可用。
通过消息传递,可以非常轻松地解耦项目的各个组件,从而实现非常简单的设计和相当简单的测试。如果你要想想这个在现有的范式而言,它非常类似于面向对象编程中使用的概念(OOP)。
归结为可以逐项进行测试。您可以设置一个简单的程序,将消息发送到服务器进程,并且由于该服务器进程的输入和输出已经(或应该被记录),因此可以确定该进程是否正常运行。哎呀,这些测试用例甚至可以自动化并放置在定期运行的回归套件中!
中微子的哲学 The philosophy of Neutrino
信息传递是Neutrino哲学的核心。了解消息传递的用途和含义将是有效使用操作系统的关键。在详细介绍之前,让我们先看一些理论。
多线程
尽管客户端/服务器模型易于理解并且是最常用的模型,但是在主题上还有两个变体。
第一个是使用多个线程(本节主题),第二个是称为服务器/子服务器的模型,该模型有时对常规设计有用,但在网络分布式设计中确实很有用。两者的结合可能非常强大,尤其是在SMP盒网络上!
正如我们在“进程和线程”一章中讨论的那样,Neutrino能够在同一进程中运行多个执行线程。当我们将其与消息传递结合在一起时,如何利用这一优势?答案很简单。我们可以启动一个线程池(使用我们在“进程和线程”一章中讨论的thread_pool_()函数),每个线程都可以处理来自客户端的消息:

这样,当客户向我们发送消息时,只要工作完成,我们就真的不在乎哪个线程收到消息。这具有许多优点。与仅使用一个线程为多个客户端提供服务相比,使用多个线程为多个客户端提供服务的能力是一个强大的概念。主要优点是内核可以在各个客户端之间对服务器执行多任务处理,而服务器本身不必执行多任务处理。
在单处理器计算机上,运行一堆线程意味着它们都在争夺CPU时间。但是,在SMP盒上,我们可以有多个线程争用多个CPU,同时在多个CPU之间共享相同的数据区域。这意味着我们仅受该特定计算机上可用CPU数量的限制。
服务器/子服务器
现在让我们看一下服务器/子服务器模型,然后将其与多线程模型结合起来。
在此模型中,服务器仍然为客户端提供服务,但是由于这些请求可能需要很长时间才能完成,因此我们需要能够启动请求,并且仍然能够处理来自其他客户端的新请求。
如果我们尝试使用传统的单线程客户端/服务器模型执行此操作,则一旦接收到一个equest并启动它,我们将无法再接收任何请求,除非我们定期停止我们正在做的事情,然后快速浏览一下查看是否还有其他待处理的请求,将其放在工作队列中,然后继续进行,将我们的注意力分散到工作队列中的各个作业上。
不是很有效。您实际上是通过在多个作业之间“时间分片”来复制内核的工作!
想象一下,如果这样做的话,会是什么样子。您在办公桌旁,有人拿着一个满是工作的文件夹走到您身边。您开始处理它。当您忙于工作时,您会注意到其他人正站在您的小隔间的门口,同时还有更多同样高优先级的工作(当然)!
现在您的办公桌上有两堆工作。您要花几分钟时间在一堆上,切换到其他的东西,等等,一直在看着你的门口,看看是否有人在忙着做更多的工作。
服务器/子服务器模型在这里更有意义。在此模型中,我们有一个服务器,它创建了其他几个进程(子服务器)。这些子服务器每个都向服务器发送一条消息,但是服务器直到收到客户端的请求才回复它们。然后,它将客户端的请求通过应执行的工作进行回复,从而将客户端的请求传递给子服务器之一。
下图说明了这一点。注意箭头的方向-它们指示发送的方向!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A1aDvc41-1584938299287)(DraggedImage.tiff)]
如果你正在做这样的工作,你首先要雇用一些额外的员工。这些员工都会来找你(正如子服务器向服务器发送消息 - 因此关于上图中箭头的注释),寻找工作要做。最初,您可能没有,所以您不会回复他们的查询。当有人带着一个装满工作的文件夹进入你的办公室时,你会告诉你的一位员工(子服务器),“这里有一些工作要做。”然后那个员工(子服务器),就去做了工作。随着其他工作的进入,您将其委托给其他员工(子服务器)。
这个模型的诀窍在于它是reply-driven的 - 当您回复子服务器时,工作就开始了。标准客户端/服务器模型是send-driven的,因为在向服务器发送消息时工作开始。 那么为什么客户会进入您的办公室,而不是您雇佣的员工办公室?你为什么“仲裁”这项工作?答案很简单:你是负责执行特定任务的协调员。由您来确保工作完成。与您一起工作的客户知道您,但他们不知道您(可能是临时)员工的姓名或位置。
您可能怀疑,您当然可以将多线程服务器与服务器/子服务器模型混合使用。主要技巧是确定“问题”的哪些部分最适合通过网络分布(通常那些不会过多地消耗网络带宽的部分)以及哪些部分最适合分布在 SMP架构(通常是那些想要使用公共数据区域的部分)。
那么我们为什么要使用一个呢?使用服务器/子服务器方法,我们可以在网络上的多台计算机上分配工作。这实际上意味着我们仅受网络上可用机器数量的限制(当然还有网络带宽)。将其与通过网络分布的一堆SMP盒上的多个线程相结合,产生“计算集群”,其中中央“仲裁器”委托(通过服务器/子服务器模型)工作到网络上的SMP盒*。**
Some examples
现在我们将考虑每种方法的几个例子。
Send-driven (client/server)
文件系统,串行端口,控制台和声卡都使用客户端/服务器模型。C语言应用程序承担客户端的角色并向这些服务器发送请求。服务器执行指定的任何工作,并回复答案。
其中在一些传统的“客户端/服务器”的服务器中可能实际是reply-driven(服务器/子服务器)服务器!这是因为,对于最终客户端而言,其服务器是为标准服务器,即使服务器本身使用服务器/子服务器方法来完成工作。我的意思是,客户端仍然向它认为是“服务提供过程”发送消息。实际发生的是“服务提供过程”简单地将客户端的工作委托给不同的进程(子服务器)。
Reply-driven (server/subserver)
一种比较流行的reply-driven程序是分布在网络上的分形图形程序。主程序将屏幕划分为若干区域,例如64个区域。在启动时,主程序将获得可参与此活动的节点列表。主程序启动子程序(子服务器),每个节点上有一个子程序,然后等待子程序发送给主程序。
然后,主程序重复选择“未填充”区域(屏幕上的64个),并通过回复将分形计算工作委托给另一个节点上的子程序。当子程序完成计算后,它会将结果发送回主程序服务器,主程序服务器会在屏幕上显示结果。
因为子程序发送给主程序,现在由主程序再次回复更多的工作。主程序继续这样做,直到屏幕上的所有64个区域都已填满。
An important subtlety
因为主程序将工作委托给子程序,所以主程序不能在任何一个程序上被阻止打断! 在传统的send-driven方法模型中,您希望主服务器创建一个子程序然后发送给它。不幸的是,主程序不会应答,直到工作计划已完成,这意味着主程序不能同时发送给另一个字程序,在一定程度上有,否定了具有多个工作节点的优势。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lSSATmrP-1584938299288)(DraggedImage-1.tiff)]
此问题的解决方案是让子工作程序启动,并通过向主程序发送消息询问是否有任何工作要做。我们再一次使用图中箭头的方向来指示发送的方向。现在工人程序正在等待master回复。当某些东西告诉master做一些工作时,它会回复一个或多个工作人员,这会导致他们离开并完成工作。这让工人可以开展业务; 主程序仍然可以响应新的请求(它不会被阻止等待其中一个工作人员的回复)。
Multithreaded server
从客户端的角度来看,多线程服务器与单线程服务器无法区分。事实上,服务器的设计者可以通过启动另一个线程来“打开”多线程。无论如何,服务器仍然可以在SMP配置中使用多个CPU,即使它只为一个“客户端”提供服务。这意味着什么?让我们重新审视分形图形示例。当一个子服务器从服务器获得“计算”的请求时,绝对没有什么能阻止子服务器在多个CPU上启动多个线程来为一个请求提供服务。事实上,为了使应用程序在具有一些SMP盒和一些单CPU盒的网络中更好地扩展,服务器和子服务器最初可以交换消息,从而子服务器告诉服务器它有多少CPU - 这让它知道多少要求它可以同时服务。然后,服务器将排队更多的SMP盒请求,允许SMP盒比单CPU盒做更多的工作。
Using message passing
现在我们已经看到了消息传递中涉及的基本概念,并了解到即使像C库这样的常见日常事物也使用它,让我们来看看其中的一些细节。
Architecture & structure
我们一直在谈论“客户”和“服务器”。我还使用了三个关键短语:
• “The client sends to the server.”
• “The server receives from the client.”
• “The server replies to the client.”
我特意使用这些短语,因为它们密切反映了QNX Neutrino Message Passing操作中使用的实际函数名称。以下是QNX Neutrino下可用消息传递的完整功能列表(按字母顺序排列):
• ChannelCreate(), ChannelDestroy()
• ConnectAttach(), ConnectDetach()
• MsgDeliverEvent()
• MsgError()
• MsgRead(), MsgReadv()
• MsgReceive(), MsgReceivePulse(), MsgReceivev()
• MsgReply(), MsgReplyv()
• MsgSend(), MsgSendnc(), MsgSendsv(), MsgSendsvnc(), MsgSendv(), MsgSendvnc(), MsgSendvs(), MsgSendvsnc()
• MsgWrite(), MsgWritev()
不要让这个名单压倒你!您可以使用列表中的一小部分调用来编写非常有用的客户端/服务器应用程序-当您习惯这些想法时,您会发现某些其他函数在某些情况下非常有用。
The client
客户端想要向服务器发送请求,处于阻止状态直到服务器完成请求,然后当请求完成并且客户端被解除阻塞时,才能获得“回答”。
这意味着两件事:客户端需要能够建立与服务器的连接,然后通过消息传输数据 - 从客户端到服务器的消息(“发送”消息)和从服务器返回到服务器的消息 客户端(“回复”消息,服务器的回复)。
Establishing a connection
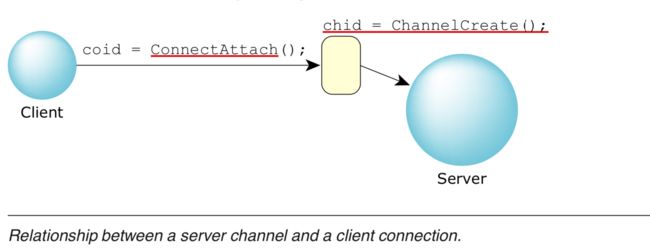
那么,让我们依次看看这些功能。我们需要做的第一件事是建立连接。我们使用ConnectAttach()函数执行此操作,如下:
#include ConnectAttach()有三个标识符:nd,即节点描述符,pid,即进程ID,以及chid,即通道ID。这三个ID(通常称为“ND / PID / CHID”)唯一标识客户端要连接的服务器。我们将忽略索引和标志(只需将它们设置为0)。
因此,我们假设我们要连接到节点上的进程ID 77,通道ID 1。这是执行此操作的代码示例:
int coid;
coid = ConnectAttach (0, 77, 1, 0, 0);
如您所见,通过指定nd为零,我们告诉内核我们希望在节点上建立连接。
Note:我怎么知道我想和进程ID 77和通道ID 1对话?我们很快就会看到(参见下面的“Finding the server’s ND/PID/CHID”)。
此时,我有一个连接ID,一个小整数,用于唯一标识从客户端到特定服务器上特定通道的连接。我可以根据需要多次发送到服务器时使用此连接ID。 当我完成它之后,我可以通过以下方式销毁它:
ConnectDetach (coid);
Sending messages
用MsgSend ()函数系列的某些变体实现在客户端上传递的消息。我们将看看最简单的成员MsgSend():
#include MsgSend()’s arguments are:
• the connection ID of the target server (coid),
• a pointer to the send message (smsg),
• the size of the send message (sbytes),
• a pointer to the reply message (rmsg), and
• the size of the reply message (rbytes).
没有比这更简单的了!让我们发送一条简单消息到进程ID 77,通道ID 1:
#include 假设进程ID 77是活动服务器,并且在其通道ID 1上期望消息的特定格式。服务器接收到该消息后,将对其进行处理,并在某时答复结果。那时,MsgSend()将返回0,表示一切正常。如果服务器在答复中向我们发送了任何数据,我们将在最后一行代码中进行打印(假设我们返回的是NUL终止的ASCII数据)。
The server
现在我们已经看到了客户端,让我们看一下服务器。
客户端使用ConnectAttach()创建与服务器的连接,然后使用MsgSend()进行所有消息传递。
Creating the channel
这意味着服务器必须创建一个通道,这是客户端在发出ConnectAttach()函数调用时所连接的对象。创建通道后,服务器通常会将其永久保留。通过ChannelCreate()函数创建通道,并通过ChannelDestroy()函数销毁通道:
#include 稍后我们将返回flags参数(在下面的“通道标志”部分中)。现在,我们仅使用0。因此,要创建通道,服务器将发出:
int chid;
chid = ChannelCreate (0);
Message handling
就消息传递方面而言,服务器分两个阶段处理消息传递。 “接收”阶段和“答复”阶段:

我们将首先看一下这些函数的两个简单版本,即MsgReceive()和MsgReply(),然后再看其中的一些变体。
#include 让我们看一下参数之间的关系:
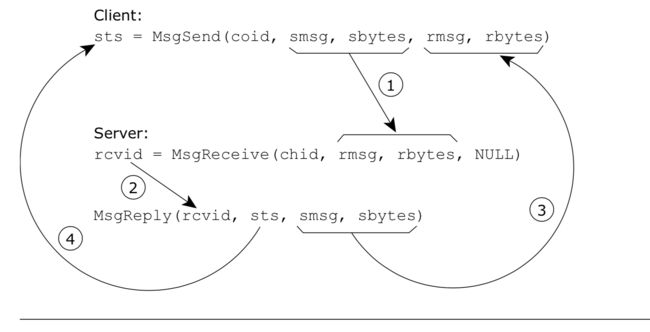
从图中可以看到,我们需要谈论四件事:
- 客户端发出MsgSend()并指定其发送缓冲区(smsg指针和sbytes长度)。这将被传输到服务器的MsgReceive()函数提供的缓冲区中,以rmsg表示,长度为rbytes。客户端现在被阻止。
- 服务器的MsgReceive()函数取消阻止,并返回一个rcvid,服务器稍后将使用该rcvid进行回复。此时,数据可供服务器使用。
- 服务器已经完成了对消息的处理,现在使用了从MsgReceive()获得的rcvid,并将其传递给MsgReply()。请注意,MsgReply()函数将具有定义大小(字节)的缓冲区(smsg)作为要传输到客户端的数据的位置。现在,数据已由内核传输。
- 最后,sts参数由内核传输,并显示为来自客户端MsgSend()的返回值。客户端现在解除阻止。
您可能已经注意到,每个缓冲区传输都有两种大小(在客户端发送情况下,客户端有sbytes,在服务器端有rbytes;在服务器回复情况下,服务器端有sbytes,客户端有rbytes出现了两组大小,以便每个组件的程序员可以指定其缓冲区的大小。这样做是为了增加安全性。在我们的示例中,MsgSend()缓冲区的大小与消息字符串的长度相同。
让我们看一下服务器,看看那里的大小是如何使用的。
Server framework
这是服务器的整体结构:
#include 如您所见,MsgReceive()告诉内核它可以处理大小为sizeof (message)或512字节)的消息。我们的示例客户端(上面)只发送了28个字节(字符串的长度)。下图说明了:

内核传输两个大小指定的最小值。在我们的例子中,内核将传输28个字节。服务器将被解除阻止并打印出客户端的消息。
(512字节缓冲区中的)其余484字节将不受影响。我们再次使用MsgReply()遇到相同的情况。 MsgReply()函数表示要传输512个字节,但是我们客户的MsgSend()函数已指定最多可以传输200个字节。因此内核再次传输最小值。在这种情况下,客户端可以接受的200个字节限制了传输大小。(这里一个有趣的方面是,一旦服务器传输了数据,如果客户端没有收到所有数据,如我们的示例所示,就无法取回数据-它永远消失了。)
note:请记住,这种“修整”操作是正常的和预期的行为。当我们讨论通过网络传递消息时,您会看到存在一个很小的“陷阱”,其中包含了已传输的数据量。我们将在下面的“网络消息传递差异”中看到这一点。
发送层次结构t he send-hierarchy
在消息传递环境中可能不明显的一件事是需要遵循严格的发送层次结构。这意味着两个线程永远不应该相互发送消息; 相反,它们应该被组织起来,使每个线程占据一个层次; 所有发送从一个级别到更高级别,从不到相同或更低级别。让两个线程相互发送消息的问题是,最终你会遇到死锁问题; 两个线程都在等待彼此回复它们各自的消息。由于线程被阻塞,它们永远不会有机会运行并执行回复,因此最终会有两个(或更多!)挂起的线程。
为线程分配级别的方法是将最外层的客户端放在最高级别,然后从那里开始工作。例如,如果你有一个依赖于某个数据库服务器的图形用户界面,而数据库服务器又依赖于文件系统,而文件系统又依赖于块文件系统驱动程序,那么你就拥有了不同的自然层次结构流程。发送将从最外面的客户端(图形用户界面)向下流到下层服务器; 回复将以相反的方向流动。
虽然这在大多数情况下肯定有效,但您会遇到需要“中断”发送层次结构的情况。这绝不是通过简单地违反发送层次结构并发送“反对流”的消息来完成的,而是通过使用MsgDeliverEvent()函数完成的,稍后我们将对此进行介绍。
Receive IDs, channels, and other parameters
我们还没有谈到上面例子中的各种参数,所以我们可以只关注消息传递。现在让我们来看看。
More about channels
在上面的服务器示例中,我们看到服务器只创建了一个通道。它当然可以创建更多,但通常,服务器不会这样做。(具有两个通道的服务器最明显的例子是透明分布式处理(TDP,也称为Qnet)本机网络管理器 - 绝对是一个奇怪的软件!)
事实证明,实际上并不需要在现实世界中创建多个渠道。通道的主要目的是为服务器提供一个明确定义的位置来“监听”消息,并为客户端提供一个明确定义的位置来发送消息(通过连接方式)。关于您在服务器中拥有多个频道的唯一情况是服务器是否要提供不同的服务或不同的服务类别,具体取决于消息到达的频道。例如,第二个信道可用作丢弃唤醒脉冲的地方 - 这确保它们被视为与到达第一信道的消息不同的“服务等级”。
在上一段中,我曾说过你可以在服务器中运行一个线程池,准备接受来自客户端的消息,并且哪个线程获得请求并不重要。这是频道抽象的另一个方面。在以前版本的QNX系列操作系统(特别是QNX 4)中,客户端将在由节点ID和进程ID标识的服务器上定位消息。由于QNX 4是单线程的,这意味着不会混淆有关“向谁发送”消息。但是,一旦你引入了线程,就必须决定如何处理线程(实际上,“服务提供者”)。由于线程是短暂的,因此让客户端连接到特定的节点ID,进程ID和线程ID实际上没有意义。另外,如果那个特定的线程很忙呢?我们必须提供一些方法来允许客户端在定义的服务提供线程池中选择“非忙线程”。
嗯,这正是一个通道。它是“服务线程池”的“address”。这里的含义是,一堆线程可以在特定通道上发出MsgReceive()函数调用,并且阻塞,一次只有一个线程获取消息。
Who sent the message?
通常,服务器需要知道是谁向其发送了消息。有许多的原因:
• accounting
• access control
• context association
• class of service
• compatibility
• etc.
让客户端向发送的每条消息提供此信息将是繁琐的(并且存在安全漏洞)。因此,每当MsgReceive()函数解锁时,内核都会填充一个结构,因为它有一条消息。此结构的类型为struct _msg_info,包含以下内容:
struct _msg_info
{
uint32_t nd;
uint32_t srcnd;
pid_t pid;
int32_t tid;
int32_t chid;
int32_t scoid;
int32_t coid;
int16_t priority;
int16_t flags;
size64_t msglen;
size64_t srcmsglen;
size64_t dstmsglen;
};
您将它作为最后一个参数传递给MsgReceive()函数。如果传递NULL,则没有任何反应。(稍后可以通过MsgInfo()调用检索信息,因此它不会永远消失!)