QNX_IPC
QNX IPC
进程间通信在将微内核从嵌入式实时内核转换为完整的POSIX操作系统的过程中起着至关重要的作用。随着各种提供服务的进程被添加到微内核中,IPC是将这些组件连接成一个内聚整体的粘合剂。虽然在QNX中微子RTOS中,消息传递是IPC的主要形式,但是也有其他几种形式。除非另有说明,否则这些其他形式的IPC是建立在我们的native消息传递之上的。该策略是创建一个简单、健壮的IPC服务,可以通过微内核中的简化代码路径进行性能调优;这样就可以实现更多杂乱的IPC服务特性。
更高级的IPC服务(如通过我们的消息传递实现的管道和fifo)与一体化内核基准比较,显示出了相当可观的性能。
QNX中微子至少提供以下形式的IPC:
- Message-passing Implemented in Kernel
- Signals Implemented in Kernel
- POSIX message queue External process
- Share memory Process Manager
- Pipes External Process
- FIFOS External Process
设计人员可以根据带宽需求、排队需求、网络透明性等来选择这些服务。权衡可能很复杂,但灵活性也是有用的。
作为定义微内核的工程工作的一部分,将重点放在作为基本IPC原语的消息传递上是经过深思熟虑的。作为IPC的一种形式,消息传递(在MsgSend()、MsgReceive()和MsgReply()中实现)就是是同步,并复制数据。让我们更详细地研究这两个属性。
Synchronous message passing 同步的消息传递
同步消息传递是QNX中微子RTOS中IPC的主要形式。向另一个线程(可能在另一个进程中)执行MsgSend()的线程将被阻塞,直到目标线程执行MsgReceive()、处理消息并执行MsgReply()。如果一个线程执行MsgReceive()而没有一个先前发送的消息被挂起,它将阻塞,直到另一个线程执行了MsgSend ()。在QNX中微子中,服务器线程通常循环,等待从客户端线程接收消息。
如前所述,线程(无论是服务器还是客户端)位于准备状态,如果它可以使用CPU。由于它和其他线程的优先级和调度策略,它实际上可能不会获得任何CPU时间,但是线程不会被阻塞。让我们先来看看客户端线程:
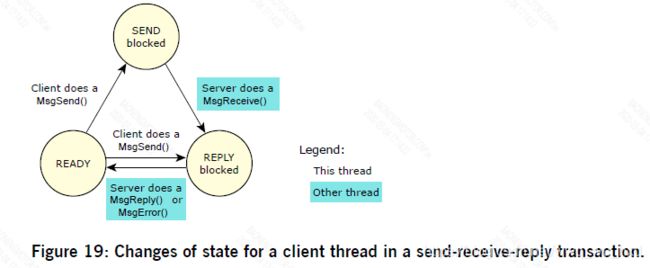
- 如果客户端线程调用MsgSend(),而服务器线程还没有调用MsgReceive(),然后客户端线程变为SEND阻塞。一旦服务器线程调用MsgReceive(),内核将客户端线程的状态更改为Reply阻塞,这意味着服务器线程已经收到消息,现在必须应答。
当服务器线程调用MsgReply()时,客户机线程就变成READY。 - 如果客户端线程调用MsgSend(),而服务器线程已经在MsgReceive()上被阻塞,那么客户端线程立即变成REPLY阻塞,完全跳过SEND阻塞状态。
- 如果服务器线程失败、退出或消失,则客户端线程变成准备READY,MsgSend()返回错误。
接下来,让我们考虑服务器线程:
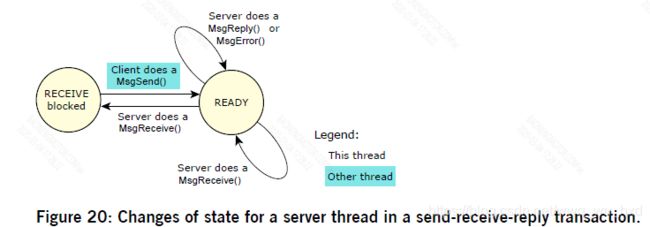
4. 如果服务器线程调用MsgReceive(),并且没有其他线程发送给它,那么服务器线程将成为RECEIVE阻塞。当另一个线程发送给它时,服务器线程就准备好了。
5. 如果服务器线程调用MsgReceive(),而另一个线程已经向它发送了消息,那么MsgReceive()立即返回消息。在这种情况下,服务器线程不会阻塞。
6. 如果服务器线程调用MsgReply(),它不会被阻塞。
这种固有的阻塞会同步发送线程的执行,因为请求发送数据的行为也会导致发送线程被阻塞,而接收线程被调度执行。这并不需要内核进行显式的工作来确定下一步运行哪个线程(与大多数其他形式的IPC一样)。执行和数据直接从一个上下文移动到另一个上下文。
这些消息传递原语中省略了数据排队功能,因为在接收线程中需要时可以实现排队。发送线程通常准备等待响应;排队是不必要的开销和复杂。(它减慢了跟非排队情况比较)。因此,发送线程不需要进行单独的、显式的阻塞调用来等待响应(如果使用了其他IPC,就需要)。
虽然发送和接收操作是阻塞和同步的,但MsgReply()(或MsgError())不会阻塞。由于客户端线程在等待回复时已经被阻塞,因此不需要额外的同步,因此不需要阻塞MsgReply()。
这允许服务器响应客户机并继续处理,而内核和/或网络代码异步地将响应数据传递给发送线程,并将其标记为准备执行。由于大多数服务器都倾向于进行一些处理以准备接收下一个请求(此时它们将再次阻塞),所以这样做效果很好。
MsgReply()函数的作用是:向客户端返回一个状态零或多个字节。另一方面,MsgError()只用于向客户端返回一个状态。这两个函数都将解除客户机对其MsgSend()的阻塞。
Message copying 信息复制
由于我们的消息传递服务直接将消息从一个线程的地址空间复制到另一个线程,而没有中间缓冲,因此消息传递性能接近底层硬件的内存带宽。
内核对消息的内容没有什么特殊的意义——消息中的数据只有发送方和接收方相互定义的意义。然而,还提供了“定义良好的”消息类型,以便用户编写的进程或线程可以补充或替代系统提供的服务。
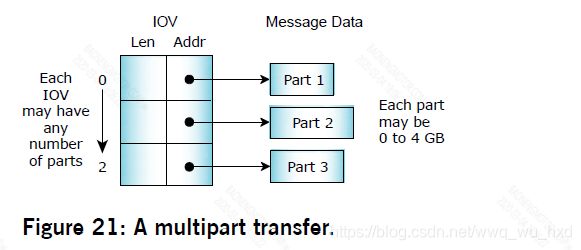
消息传递原语支持多部分传输,因此从一个线程的地址空间传递到另一个线程的消息不必预先存在于一个连续的缓冲区中。相反,发送和接收线程都可以指定一个向量表,指出发送和接收消息片段在内存中的位置。注意,发送方和接收方的各个部分的大小可能不同。
多部分传输允许将消息头块与数据块分开发送,而无需对数据进行性能消耗的复制以创建连续消息。此外,如果底层数据结构是一个环形缓冲区,那么指定一个由三部分组成的消息将允许将环形缓冲区中的头和两个不相交的范围作为单个原子消息发送。与此概念等价的硬件是DMA设施。
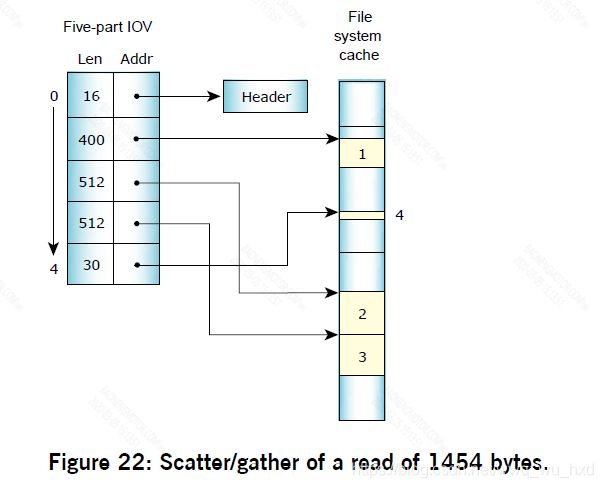
多部分传输也被文件系统广泛使用。在读取时,使用包含n个数据部分的消息将数据直接从文件系统缓存复制到应用程序中。每个部分有指针指向缓存,因为缓存块在内存中不是连续的,而读取操作开始或结尾不止跨一个内存块。
例如,缓存块大小为512字节,读取1454字节就可以满足5个部分的消息:
由于消息数据是在地址空间之间显式复制的(而不是通过页表操作),因此可以在堆栈上轻松地分配消息,而不是从用于MMU“页面翻转”的页面对齐内存的特殊池中分配消息。因此,许多实现客户机和服务器进程之间API的库例程可以简单地表达出来,而不需要复杂的特定于ipc的内存分配调用。
例如, 下面客户端线程用来请求文件系统manager执行lseek的代码是这样实现的:
#include
#include
#include
off64_t lseek64(int fd, off64_t offset, int whence) {
io_lseek_t msg;
off64_t off;
msg.i.type = _IO_LSEEK;
msg.i.combine_len = sizeof msg.i;
msg.i.offset = offset;
msg.i.whence = whence;
msg.i.zero = 0;
if(MsgSend(fd, &msg.i, sizeof msg.i, &off, sizeof off) == -1) {
return -1;
}
return off;
}
off64_t tell64(int fd) {
return lseek64(fd, 0, SEEK_CUR);
}
off_t lseek(int fd, off_t offset, int whence) {
return lseek64(fd, offset, whence);
}
off_t tell(int fd) {
return lseek64(fd, 0, SEEK_CUR);
}
这段代码本质上在堆栈上构建了一个消息结构,用各种常量填充它,并从调用线程传递参数,然后将它发送给与fd相关的文件系统管理器。应答指示操作的成功或失败。
这个实现并不会妨碍内核检测大型消息传输并选择为这些情况实现“页面翻转”。由于传递的大多数消息都非常小,因此复制消息通常比操作MMU页表要快。对于批量数据传输,进程之间共享内存(通过消息传递或其他同步原语进行通知)也是一个可行的选择。
simple messages 简单的消息
对于简单的单部分消息,OS提供了直接将指针指向缓冲区的函数,而不需要IOV(输入/输出向量)。在这种情况下,部件的数量(part of number)被直接指向的message的size所代替。
在消息发送原语的情况下——它接受一个发送和一个应答缓冲区——这里引入了四种变体:
| Function | Send message | Reply message |
|---|---|---|
| MsgSend() | Simple | Simple |
| MsgSendsv() | Simple | IOV |
| MsgSendvs() | IOV | simple |
| MsgSendv() | IOV | IOV |
其他消息传递原语只需在它们的名称中去掉末尾的“v”:
| IOV | simple |
|---|---|
| MsgReceivev() | MsgReceive() |
| MsgReceivePulsev() | MsgReceivePulse() |
| MsgReplyv() | MsgReply() |
| MsgReadv() | MsgRead() |
| MsgWritev() | MsgWrite() |
channels and connections 通道跟连接
在QNX中微子RTOS中,消息传递直接针对通道和连接,而不是直接针对线程之间的连接。希望接收消息的线程首先创建一个通道;另一个希望向该线程发送消息的线程必须首先通过“附加attaching”该通道建立连接。
channels 是在消息内核调用中申请的,并且被使用在server调用MsgReceive()上。connection是由客户线程创建,用来连接到server的channel上。一旦建立了连接,客户端就可以通过它们MsgSend消息。
如果一个进程中的许多线程都连接到同一个通道,那么为了提高效率,这些连接都映射到同一个内核对象。通道和连接在进程中由一个小的整数标识符命名。客户端连接直接映射到文件描述符。
在架构上,这是一个关键点。通过让客户端连接直接映射到FDs,我们消除了另一层转换。我们不需要去’找出’消息的发送地。相反,我们可以直接向“文件描述符”发送消息(connection ID)。
| Function | Description |
|---|---|
| ChannelCreate() | Create a channel to receive messages on. |
| ChannelDestroy() | Destroy a channel. |
| ConnectAttach() | Create a connection to send messages on. |
| ConnectDetach() | Detach a connection. |

作为服务器的进程将实现一个事件循环来接收和处理消息,如下所示:
chid = ChannelCreate(flags);
SETIOV(&iov, &msg, sizeof(msg));
for(;;) {
rcv_id = MsgReceivev( chid, &iov, parts, &info );
switch( msg.type ) {
/* Perform message processing here */
}
MsgReplyv( rcv_id, &iov, rparts );
}
这个循环允许线程从与通道有连接的任何线程接收消息。
NOTE:服务器还可以使用name_attach()创建一个通道,并将名称与之关联。然后,发送方进程可以使用name_open()来定位该名称并创建到它的连接。
通道有几个与之相关的消息列表:
- Receive: 一个后进先出线程队列,线程等待着message。
- Send: 一个具有优先级的先进先出的队列,其中的线程,已经发送消息但是消息还没有被收到。
- Reply: 一个无序线程列表,线程已经发送了消息,消息也已经被收到了,但是还没有回复。
而在这些列表中,等待的线程被阻塞(即SEND-、RECV-或 REPLY-blocked)。多个线程和多个客户端可以在一个通道上等待。
Pulses 脉冲
除了同步发送/接收/应答服务之外,操作系统还支持固定大小的非阻塞消息。这些被称为脉冲,携带一个小的有效负载(四个字节的数据加上一个单字节代码)。
脉冲封装相对较小的有效负载——8位代码和32位数据。脉冲通常用作中断处理程序中的通知机制。它们还允许服务器在不阻塞客户机的情况下发出信号。

优先级继承和消息
服务器进程按优先级顺序接收消息和脉冲。当服务器中的线程接收请求时,它们将继承发送线程的优先级(但不包括调度策略服务器进程按优先级顺序接收消息和脉冲。当服务器中的线程接收请求时,它们将继承发送线程的优先级(但不包括调度策略)。
因此,请求服务器工作的线程的相对优先级将被保留,并且服务器工作将以适当的优先级执行。这种消息驱动的优先级继承避免了优先级反转问题。
例如,假设系统包含以下内容:
- a server thread, at priority 22
- a client thread, T1, at priority 13
- a client thread, T2, at priority 10
在没有优先级继承的情况下,如果T2向服务器发送一条消息,那么它实际上在优先级为22的情况下完成了工作,因此T2的优先级被颠倒了。
实际发生的情况是,当服务器接收到消息时,它的有效优先级更改为发送方的最高优先级,在本例中,T2的优先级低于服务器的优先级,因此当服务器接收到消息时,服务器的有效优先级将发生变化。
接下来,假设T1向服务器发送了一条消息,而它的优先级仍然是10。由于T1的优先级高于服务器当前的优先级,所以当T1发送消息时,服务器的优先级发生变化。
更改发生在服务器接收到消息之前,以避免出现另一种优先级反转的情况。如果服务器的优先级保持在10,而另一个线程,T3,以优先级11开始运行,服务器必须等待,直到T3允许它有一些CPU时间,以便它最终可以接收到T1的消息。因此,T1将被低优先级线程T3延迟。
您可以通过在调用ChannelCreate()时指定_NTO_CHF_FIXED_PRIORITY标志来关闭优先级继承。如果使用自适应分区,此标志还会导致接收线程不能在发送线程的分区中运行。
消息传递 API
| function | Description |
|---|---|
| MsgSend() | Send a message and block until reply. |
| MsgReceive() | Wait for a message. |
| MsgReceivePulse() | Wait for a tiny, nonblocking message(pulse) |
| MsgReply() | Reply to a message. |
| MsgError() | Reply only with an error status. No message bytes are transferred. |
| MsgRead() | Read additional data from a received message |
| MsgWrite() | Write additional data to a reply message |
| MsgInfo() | Obtain info on a received message. |
| MsgSendPulse() | Send a tiny, nonblocking message (pulse). |
| MsgDeliverEvent() | Deliver an event to a client. |
| MsgKeyData() | Key a message to allow security checks. |
Send/Receive/Reply的健壮实现
通过使用Send/Receive/Replay将QNX APP架构成为一个多个线程和多个进程协作的团队。这种架构导致QNX 是一个使用同步通知的系统。所以IPC 发生在指定转变时发生,而不是异步。
异步系统的一个重要问题是,事件通知需要运行信号处理程序。异步IPC可能使彻底测试系统的操作变得困难,并确保无论信号处理程序何时运行,处理都将按预期的方式继续也变得困难。
应用程序常常试图通过依赖显式打开和关闭的“窗口”来避免这种情况,在此期间信号将被接受。
使用围绕发送/接收/应答构建的同步、非排队的系统体系结构,可以非常容易地实现和交付健壮的应用程序体系结构。
在从排队的IPC、共享内存和其他同步原语的各种组合构建应用程序时,避免死锁是另一个难题。例如,假设线程A直到线程B释放互斥锁2才释放互斥锁1。不幸的是,如果线程B处于在线程A释放互斥锁1之前不释放互斥锁2的状态,则会导致僵局。为了确保死锁不会在系统运行时发生,常常调用仿真工具。
发送/接收/应答IPC原语允许构造无死锁的系统,只需要观察这些简单的规则:
- 永远不要让两个线程互相发送
- 总是把你的线程安排在一个层次结构中,发送总是沿树向上。
第一个规则是明显避免僵局的情况,但第二个规则需要进一步解释。例如:合作线程和进程团队安排如下:
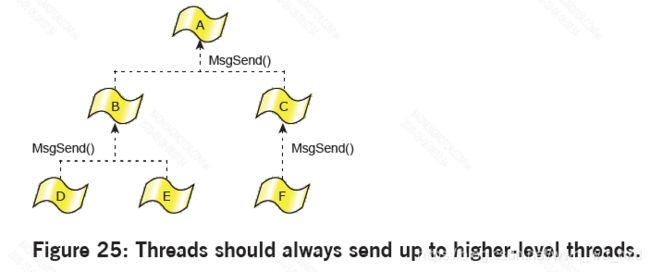
在这里,层次结构中任何给定级别的线程都不会相互发送,而是只向上发送。
这方面的一个例子可能是发送到数据库服务器进程的客户机应用程序,而数据库服务器进程又发送到文件系统进程。当发送线程阻塞在目标线程的reply,而这时候目标线程不会阻塞在sending线程, 这样死锁不会发生。
但是,一个高级别线程如何通知一个低级别线程它有先前请求的操作的结果呢?(假设较低级别的线程不期望望发送时等待响应结果(最后一次发送)。)
QNX中微子RTOS通过MsgDeliverEvent()内核调用提供了一个非常灵活的体系结构来交付非阻塞事件。所有的通用异步服务都可以用它来实现。服务端的select()调用一个应用程序可用于允许线程在一组文件描述符上等待I/O事件完成的API。除了需要一个异步通知机制作为从高级别线程到低级别线程的通知的“反向通道”之外,我们还可以围绕此构建一个可靠的通知系统,用于定时器、硬件中断和其他事件源。

一个相关的问题是,高级线程如何能够请求低级线程的工作而不用Send给它,从而避免死锁的风险。低级线程仅作为高级线程的工作线程,根据请求执行工作。较低级别的线程将发送以"报告工作"形式,但较高级别的线程不会在那时回复。它将延迟响应,直到更高级的线程工作完成,并且它将使用“描述工作”的数据进行响应(这是一个非阻塞操作)。实际上,应答是用来启动工作的,而不是用来发送工作的,后者巧妙地避开了规则#1。
#Events 事件
QNX中微子内核设计的一个重大进步是事件处理子系统。POSIX及其实时扩展定义了许多异步通知方法(例如,Unix 信号是不能排队或传递数据的,而POSIX实时信号却可以排队并传递数据,等等)。
内核还定义了额外的、特定于QNX中微子的通知技术,比如脉冲。实现所有这些事件机制可能会消耗大量代码空间,因此我们的实现策略是在单个、丰富的事件子系统上构建所有这些通知方法。
这种方法的一个好处是,一种通知技术独有的功能可以提供给其他技术。例如,应用程序可以将POSIX实时信号的相同队列服务应用于UNIX信号。这可以简化应用程序中信号处理程序的健壮实现。
执行线程遇到的事件可以来自以下三个来源:
- a MsgDeliverEvent() kernel call invoked by a thread 线程调用MsgDeliverEvent()系统调用
- an interrupt handler 中断处理函数
- the expiry of a timer 计时器的过期
事件本身可以是许多不同类型中的任何一种:QNX中微子脉冲、中断、各种形式的信号和强制的“解除阻塞”事件。“Unblock”是一种方法,通过这种方法,线程可以在没有任何显式事件实际交付的情况下从故意阻塞的状态释放出来。
考虑到事件类型的多样性,以及应用程序需要请求最适合其需要的异步通知技术,要求服务器进程(上一节中的高级线程)携带支持所有这些选项的代码将会很困难。
相反,客户端线程可以向服务器提供一个数据结构(或“cookie”),以便稍后使用。当服务器需要通知客户端线程时,它将调用
MsgDeliverEvent()和微内核将在客户端线程上设置cookie中编码的事件类型。

I/O notification
ionotify()函数的作用是:客户端线程可以请求异步事件传递。许多POSIX异步服务(例如,mq_notify()和select())都构建在ionotify()之上。在对文件描述符fd执行I/O时,线程可以选择等待I/O事件完成(对于写()情况),或等待数据到达(对于读()情况)。
相比让线程阻塞在对资源管理器的读写服务请求上,ionotify()能够允许client 线程post一个event到资源管理器(resource manager)然后在IO条件发生的时候,接受到事件通知。以这种方式等待允许线程继续执行和响应事件源,而不仅仅是单个I/O请求。
select()调用是使用I/O通知实现的,它允许一个线程阻塞和等待多个fd上的混合I/O事件,同时继续响应其他形式的IPC。
以下是可以交付所请求事件的条件:
- _NOTIFY_COND_OUTPUT : 输出缓冲区中有更多数据的空间。
- _NOTIFY_COND_INPUT: 资源管理器定义的总数据可读。
- _NOTIFY_COND_OBAND:资源管理器定义的“out-of-band"数据可用
Signals 信号
该操作系统支持32个标准的POSIX信号(as UNIX)和POSIX实时信号,这两个信号都是具有统一功能的,由内核实现的64个信号中编号的。而POSIX标准定义的实时信号与unix形式不同(posix实时信号包含数据的四个字节,字节代码和可能排队等候交付),posix 实时信号可以显式地选中或者去掉一个信号,而允许这个实现仍然符合标准。
顺便说一句,如果应用程序需要,unix风格的信号可以选择POSIX实时信号队列。QNX中微子RTOS还扩展l了POSIX的信号传递机制,允许信号针对特定的线程,而不是简单地针对包含线程的进程。由于信号是异步事件,所以它们也是通过事件传递机制实现的。
| microkernel call | POSIX call | Description |
|---|---|---|
| SignalKill | kill(),pthread_kill(),raise(),sigqueue() | 在进程组,进程中,线程中设置信号 |
| SignalAction() | sigaction() | 定义接收到信号后要采取的行动 |
| SignalProcmask() | sigprocmask(),pthread_sigmask() | 改变一个线程的信号阻塞掩码。 |
| SignalSuspend() | sigsuspend(), pause() | 阻塞,直到信号调用信号处理程序。 |
| SignalWaitinfo() | sigwaitinfo() | 等待信号并返回信息。 |
最初的POSIX规范只定义了进程上的信号操作。在多线程进程中,遵循以下规则:
- 信号动作是在进程级维护的。如果一个线程忽略或捕获一个信号,它将影响进程中的所有线程。
- 信号掩码保持在线程级。如果一个线程阻塞了一个信号,它只会影响这个线程。
- 针对某个线程的未忽略信号将单独传递给该线程。
- 针对进程的未忽略信号被传递到第一个没有阻塞该信号的线程。如果所有线程都阻塞了该信号,则该信号将在进程中排队,直到任何线程忽略或解除阻塞该信号。如果忽略,进程上的信号将被删除。如果解除阻塞,信号将从进程移动到解除阻塞的线程。
当一个信号针对一个有大量线程的进程时,必须扫描线程表,寻找一个没有阻塞信号的线程。大多数多线程进程的标准实践是在除一个线程之外的所有线程中屏蔽信号,该线程专门用于处理这些信号。为了提高进程信号传递的效率,内核将缓存最后一个接受信号的线程,并始终尝试首先将信号传递给它。
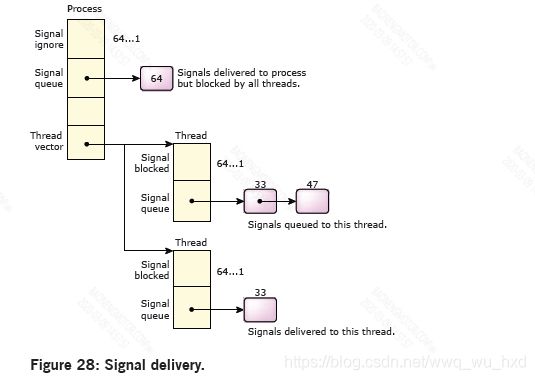
POSIX标准包括排队实时信号的概念。QNX的中微子RTOS支持任意信号的可选排队,而不仅仅是实时信号。可以在进程中逐个信号地指定队列。每个信号可以有一个相关的8位代码和一个32位值。
这与前面描述的消息脉冲非常相似。内核利用了这种相似性,并使用通用代码来管理信号和脉冲。使用_SIGMAX - signo将信号号映射到脉冲优先级。因此,信号以优先级顺序传递,信号数越低,优先级越高。这符合POSIX标准,该标准规定现有信号优先于新的实时信号.
NOTE:在信号处理程序中使用浮点运算是不安全的。
特殊信号
如前所述,操作系统总共定义了64个信号。它们的范围如下:
| Signal range | Description |
|---|---|
| 1-57 | 57个POSIX信号(包括传统的UNIX信号) |
| 41-56 | 16 POSIX实时信号(SIGRTMIN to)SIGRTMAX) |
| 57-64 | 8个特殊用途的QNX中微子信号 |
这八种特殊信号不能被忽视或捕捉。调用signal()或sigaction()函数或SignalAction()内核调用来更改它们的尝试将失败,并出现EINVAL错误。
此外,这些信号总是被阻塞,并启用了信号队列。通过sigprocmask()函数或SignalProcmask()内核调用来解除这些信号阻塞的尝试将被忽略。
可以使用以下标准信号调用将常规信号编程为这种行为。特殊的信号因该避免程序员编写这段代码,并保护信号不受这种行为的意外影响。
sigset_t *set;
struct sigaction action;
sigemptyset(&set);
sigaddset(&set, signo);
sigprocmask(SIG_BLOCK, &set, NULL);
action.sa_handler = SIG_DFL;
action.sa_flags = SA_SIGINFO;
sigaction(signo, &action, NULL);
这种配置使这些信号适合使用sigwaitinfo()函数或SignalWaitinfo()内核调用来同步通知。以下代码将被阻塞,直到收到第8个特殊信号:
sigset_t *set;
siginfo_t info;
sigemptyset(&set);
sigaddset(&set, SIGRTMAX + 8);
sigwaitinfo(&set, &info);
printf("Received signal %d with code %d and value %d\n",
info.si_signo,
info.si_code,
info.si_value.sival_int);
由于信号总是被阻塞,如果特殊信号是在sigwaitinfo()函数之外传递的,则程序不能被中断或终止。因为信号队列总是启用的,所以信号不会丢失——它们将排队等待下一次调用sigwaitinfo()。
这些信号是为了解决一个常见的IPC需求而设计的,在这个需求中,服务器希望通知客户机它有可供客户机使用的信息。服务器将使用MsgDeliverEvent()调用来通知客户机。对于通知中的事件,有两种合理的选择:脉冲或信号。
当客户机client 本身是其他客户机的服务器时,脉冲是首选的方法,在这种情况下,这个客户机将创建一个用于接受消息的通道,并且还可以接受脉冲。
对于大多数简单的客户端,情况并非如此。为了接收脉冲,一个简单的客户端将被迫为此创建一个通道。如果信号被配置为同步信号(信号被阻塞)和排队,则可以使用信号来代替脉冲(信号被阻塞)和排队——这正是特殊信号的配置方式。客户端将使用简单的sigwaitinfo()调用替换MsgReceive()调用,后者用于等待通道上的脉冲,而sigwaitinfo()调用用于等待信号。
八种特殊信号包括用于特殊目的的命名信号:SIGSELECT Used by select() to wait for I/O from multiple servers.
信号总结
这个表描述了每个信号的含义:
| signal | description |
|---|---|
| SIGABRT | 异常终止信号,例如由abort()函数发出的终止信号。 |
| SIGALRM | 超时信号如由alarm()函数发出。 |
| SIGBUS | 指示内存奇偶校验错误(QNX)Neutrino-specific解释)。请注意如果您的进程在此错误的信号处理程序中发生第二个错误,则该进程将终止。 |
| SIGCHLD (or SIGCLD) | 子进程终止。默认操作是忽略信号。 |
| SIGCONT | 如果进程不是HELD,默认操作是忽略信号,否则 continue |
| SIGDEADLK | 互斥死锁发生。如果一个进程在持有互斥锁时死亡,而您没有调用SyncMutexEvent()来设置要在互斥锁死亡时传递给互斥锁所有者的事件,那么内核将传递一个SIGDEADLK给所有在没有超时的情况下等待互斥锁的线程。注意,SIGDEADLK和SIGEMT指的是同一个信号。一些实用程序(例如,gdb、ksh、slay和kill)知道SIGEMT,但不知道SIGDEADLCK。 |
| SIGEMT | EMT指令(仿真器陷阱)。注意,SIGEMT和SIGDEADLK指的是同一个信号。 |
| SIGFPE | 错误的算术运算(整数或浮点数),如除0或导致溢出的操作。请注意,当您的进程处于该错误的信号处理程序中时,如果发生第二个错误,该进程将被终止。 |
| SIGHUP | 在控制终端检测到会话领导人死亡或挂起。 |
| SIGILL | 检测无效的硬件指令。如果在你的信号处理程序中第二次发生这个错误,进程将会终止。请求I/O特权有可能会导致这个信号。线程请求类似特权:1:PROCMGR_AID_IO 2:ThreadCtl( _NTO_TCTL_IO, 0 ); |
| SIGINT | 互动注意信号(中断)。 |
| SIGIOT | IOT指令(非x86硬件生成)。 |
| SIGKILL | 终止信号只用于紧急情况。这个信号不能被捕捉或忽略。 |
| SIGPIPE | 尝试在没有读取器的管道上进行写入。 |
| SIGPOLL (or SIGIO) | Pollable event occurred. |
| SIGPWR | 电源故障或重启。 |
| SIGQUIT | 互动的终止信号。 |
| SIGSEGV | 检测无效的内存引用。注意,当进程在的信号处理程序中时,发生第二次此故障,该进程将被终止。 |
| SIGSTOP | 停止进程(默认)。这个信号不能被捕获或忽略。 |
| SIGSYS | 错误参数的系统调用 |
| SIGTERM | 终端信号? |
| SIGTRAP | 不受支持的软件中断。 |
| SIGTSTP | 由键盘产生的停止信号。 |
| SIGTTIN | 试图从控制终端读取背景信息。 |
| SIGTTOU | 后台写试图控制终端 |
| SIGURG | socket出现紧急情况 |
| SIGUSR1 | 保留为应用程序定义的信号1。 |
| SIGUSR2 | 保留为应用程序定义的信号2。 |
| SIGWINCH | Window size changed. |
POSIX消息队列
POSIX定义了一组称为消息队列的非阻塞消息传递工具。与管道一样,消息队列也是使用“读取器”和“写入器”操作的命名对象。作为离散消息的优先级队列,消息队列具有比管道更多的结构,并为应用程序提供对通信的更多控制。
*NOTE:要在QNX中微子RTOS中使用POSIX消息队列,消息队列服务器必须正在运行。QNX中微子有两种消息队列实现:
- 使用mqueue资源管理器的“传统”实现。
- 使用mq服务器和异步消息的替代实现。
与我们固有的消息传递原语不同,POSIX消息队列驻留在内核之外。
为什么使用POSIX消息队列?
POSIX消息队列为许多实时程序员提供了一个熟悉的接口。它们类似于许多实时可执行文件的“邮箱”。
我们的消息和POSIX消息队列之间有一个根本的区别。
我们的消息块——它们直接在发送消息的进程的地址空间之间复制数据。另一方面,POSIX消息队列实现了一种存储转发设计,在这种设计中,发送方不需要阻塞,并且可能有许多未完成的消息排队。POSIX消息队列独立于使用它们的进程而存在。您可能会在一种设计中使用消息队列,在这种设计中,随着时间的推移,许多指定的队列将由各种进程操作。
对于原始性能,在传输数据上,POSIX消息队列将比QNX中微子本地消息慢。然而,队列的灵活性可能会使这种小小的性能损失变得值得。
类文件接口
消息队列类似于文件,至少就其接口而言类似文件。您可以使用mq_open()打开一个消息队列,使用mq_close()关闭它,然后使用mq_unlink()销毁它。要将数据放入(“写”)并从(“读”)消息队列中取出数据,可以使用mq_send()和mq_receive()。
为了严格遵守POSIX,您应该创建以单个斜杠(/)开头的消息队列,并且不包含其他斜杠。但是请注意,我们通过支持可能包含多个斜线的路径名来扩展POSIX标准。例如,这允许公司将其所有消息队列置于公司名称之下,并更有把握地分发产品,以确保队列名称不会与另一家公司的名称发生冲突。
在QNX中微子中,所有创建的消息队列将出现在以下目录的文件名空间中:
- /dev/mqueue 您正在使用传统的(mqueue)实现
- /dev/mq 您正在使用备用(mq)实现
For example, with the traditional implementation:
| mq_open() name: | Pathname of message queue: |
|---|---|
| /data | /dev/mqueue/data |
| /qnx/data | /dev/mqueue/qnx/data |
您可以使用ls命令显示系统中的所有消息队列,如下图所示:ls -Rl /dev/mqueue 打印的size是等待消息的数量。
Message-queue functions
POSIX消息队列通过以下功能进行管理:
- mq_open(): Open a message queue
- mq_close(): Close a message queue
- mq_unlink(): Remove a message queue
- mq_send(): Remove a message queue
- mq_receive(): Receive a message from the message queue
- mq_notify():告诉调用进程消息队列中有可用的消息
- mq_setattr(): Set message queue attributes
- mq_getattr(): Get message queue attributes
Shared memory 共享内存
共享内存提供了可用的最高带宽IPC。一旦创建了共享内存对象,访问该对象的进程可以使用指针直接读写该对象。这意味着对共享内存的访问本身是不同步的。如果一个进程正在更新共享内存的一个区域,则必须小心防止另一个进程读取或更新相同的区域。即使在简单的读操作中,其他进程也可能得到不稳定的信息。
为了解决这些问题,共享内存通常与一个同步原语结合使用,在进程之间进行原子性更新。如果更新的粒度很小,那么同步原语本身将限制使用共享内存固有的高带宽。因此,当将大量数据作为一个块进行更新时,共享内存的效率最高。
信号量和互斥对象都是用于共享内存的合适的同步原语。通过POSIX实时进程间同步标准引入了信号量。在POSIX线程同步标准中引入了互斥锁。互斥锁也可以在不同进程的线程之间使用。POSIX认为这是一个可选的功能;我们支持它。通常,互斥锁比信号量更有效。
带有消息传递的共享内存
共享内存和消息传递可以结合起来提供IPC,它提供:
- 非常高的性能(shared memory)
- synchronization (message-passing)
- network transparency (Message-passing)
使用消息传递,客户端向服务器发送请求并阻塞。服务器按优先级顺序从客户端接收消息,处理它们,并在可以满足请求时进行响应。此时,客户机已被解除阻塞并继续运行。发送消息的行为本身就提供了客户机和服务器之间的自然同步。与通过消息传递复制所有数据不同,消息可以包含对共享内存区域的引用,因此服务器可以直接读写数据。这可以用一个简单的例子来解释。
让我们假设一个图形服务器接受来自客户端的绘制图像请求,并将它们呈现到一个图形卡上的帧缓冲区中。仅使用消息传递,客户机将向服务器发送包含图像数据的消息。这将导致图像数据从客户机的地址空间复制到服务器的地址空间。然后,服务器将呈现图像并发出简短的回复。
如果客户机没有将图像数据内联到消息中,而是将引用发送到包含图像数据的共享内存区域,那么服务器可以直接访问客户机的数据。
客户机在服务器上由于发送消息而被阻塞,所以服务器知道共享内存中的数据是稳定的,并且在服务器响应之前不会更改。这种消息传递和共享内存的组合实现了自然同步和非常高的性能。
这种操作模型也可以反过来–服务器可以生成数据并将其提供给客户机。例如,假设客户机向服务器发送一条消息,该消息请求直接从CD-ROM将视频数据读入客户机提供的共享内存缓冲区。在更改共享内存时,客户机将在服务器上被阻塞。当服务器响应并且客户端继续时,共享内存将是稳定的,以便客户端访问。这种类型的设计可以使用多个共享内存区域进行流水线操作。
简单的共享内存不能在通过网络连接的不同计算机上的进程之间使用。另一方面,消息传递是网络透明的。服务器可以为本地客户端使用共享内存,为远程客户端使用数据的完整消息传递。这允许您提供高性能的服务器,同时也是网络透明的。
在实践中,消息传递原语的速度对于大多数IPC需求来说已经足够快了。只有在具有非常高带宽的特殊应用中,才需要考虑组合方法的附加复杂性。
创建共享内存对象
一个进程中的多个线程共享该进程的内存。要在进程之间共享内存,您必须首先创建一个共享内存区域,然后将该区域映射到进程的地址空间。共享内存区域的创建和操作使用以下调用:
- shm_open() :Open (or create) a shared-memory region. POSIX
- close() :Close a shared-memory region. POSIX
- mmap() : Map a shared-memory region into a process’s address space. POSIX
- munmap():Unmap a shared-memory region from a process’s address space. POSIX
- munmap_flags():Unmap以前映射的地址,使用munmap()执行更多的控制 QNX Neutrino
- mprotect() :更改共享内存区域上的保护。 POSIX
- msync():将内存与物理存储器同步。POSIX
- shm_ctl(),shm_ctl_special() :为共享内存对象提供特殊属性。 QNX Neutrino
- shm_unlink():删除共享内存区域。 POSIX
POSIX共享内存是通过进程管理器(procnto)在QNX中微子RTOS中实现的。以上调用被实现为传递给procnto的消息(参见本书的Process Manager一章)。
shm_open()函数接受与open()相同的参数,并向对象返回一个文件描述符。与常规文件一样,此函数允许您创建新的共享内存对象或打开现有的共享内存对象。
NOTE: 您必须打开文件描述符用读访问权限;如果您还想要在内存对象中写入,那么您还需要写访问权,除非您指定了一个私有(MAP_PRIVATE)映射。
当创建一个新的共享内存对象时,该对象的大小被设置为零。要设置大小,可以使用ftruncate()—用于设置文件大小的函数或者shm_ctl ()。
mmap()
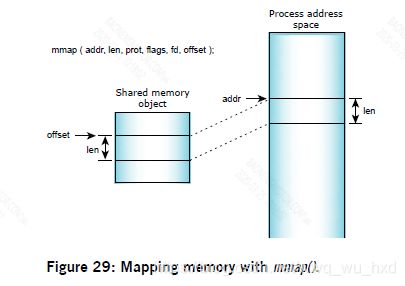
一旦有了共享内存对象的文件描述符,就可以使用mmap()函数将该对象或它的一部分映射到进程的地址空间。mmap()函数是QNX中微子内存管理的基础,值得详细讨论它的功能。
NOTE:还可以使用mmap()将文件和类型化内存对象映射到进程的地址空间。
mmap()函数定义如下:
void * mmap( void *where_i_want_it,
size_t length,
int memory_protections,
int mapping_flags,
int fd,
off_t offset_within_shared_memory );
简单来说就是:“在offset_within_shared_memory中映射与fd相关的共享内存对象的共享内存字节长度length。”mmap()函数将尝试将内存放在地址空间中where_i_want_it所在的地址。内存将被赋予memory_protected指定的保护,映射将根据mapping_flags完成。
三个参数fd、offset_within_shared_memory和length定义了要映射到的特定共享对象一部分。通常在整个共享对象中进行映射,在这种情况下,偏移量为零,长度为共享对象的大小(以字节为单位)。在Intel处理器上,长度是页面大小的倍数,页面大小为4096字节。
mmap()的返回值将是映射对象的进程的地址空间中的地址。参数where_i_want_it被系统用作对象放置位置的提示。如果可能,对象将被放置在请求的地址。大多数应用程序指定一个零地址,这使系统可以自由地将对象放置在它希望的地方。
memory_protections参数可以为以下类型:
- PROT_EXEC:Memory may be executed.
- PROT_NOCACHE:Memory should not be cached.
- PROT_NONE:No access allowed.
- PROT_READ:Memory may be read.
- PROT_WRITE:Memory may be written.
当您使用共享内存区域来访问可能被硬件(例如,视频帧缓冲区或内存映射网络或通信板)修改的双端口内存时,您应该使用PROT_NOCACHE配置。如果没有这个配置,处理器可能会从以前缓存的读操作返回“过期”数据。
mapping_flags确定如何映射内存。这些标志分为两部分,第一部分是一个类型,必须指定为以下内容之一:
- MAP_SHARED: 映射可以由多个进程共享;更改将传递到基础对象。
- MAP_PRIVATE:映射是调用进程的私有映射;更改不会传递到底层对象。函数的作用是:分配系统内存并做一份复制。
MAP_SHARED类型用于在进程之间设置共享内存;MAP_PRIVATE有更特殊的用途。您可以在上面的类型中OR或上多个标记,以进一步定义映射。这些在QNX中微子C库参考的mmap()条目中有详细描述。一些更有趣的标志是:
MAP_ANON:映射不与任何文件描述符关联的匿名内存;您必须将fd参数设置为NOFD。函数的作用是:分配内存,默认情况下,用0来填充分配的内存;“ 详细见“Initializing allocated memory”。
MAP_FIXED:将对象映射到由where_i_want_it指定的地址。如果共享内存区域包含指针,那么您可能需要在所有映射该区域的进程中强制该区域使用相同的地址。这可以通过使用区域内的偏移量来代替直接指针来避免。
MAP_PHYS:此标志表示希望处理物理内存。fd参数设置为NOFD。当不使用MAP_ANON时,offset_within_shared_memory指定要映射的确切物理地址(例如,对于视频帧缓冲区)。如果与MAP_ANON一起使用,则分配物理上连续的内存(例如,为DMA缓冲区)。可以使用MAP_NOX64K和MAP_BELOW16M进一步定义MAP_ANON分配的内存和地址限制出现在某些DMA形式中。
NOTE:您应该使用mmap_device_memory()而不是MAP_PHYS,除非您正在分配物理上连续的内存。
MAP_NOX64K:与MAP_PHYS | MAP_ANON一起使用。分配的内存区域不会跨越64 kb的边界。这是旧的16位PC DMA所需要的。
MAP_BELOW16M:与MAP_PHYS | MAP_ANON一起使用。分配的内存区域将驻留在16mb以下的物理内存中。这在使用ISA 总线的DMA 时是必需的。
MAP_NOINIT:放宽POSIX要求,使分配的内存为零;
使用上面描述的映射标志,一个进程可以很容易地在进程之间共享内存:
fd = shm_open("datapoints", O_RDWR);
addr = mmap(0, len, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
或为总线控制的PCI网卡分配一个DMA buffer:
addr = mmap(0, 262144, PROT_READ|PROT_WRITE|PROT_NOCACHE,
MAP_PHYS|MAP_ANON, NOFD, 0);
可以使用munmap()从地址空间取消对共享内存对象的全部或部分映射。这个原语并不局限于取消对共享内存的映射—它可以用于取消对进程中任何内存区域的映射。当与mmap()的MAP_ANON标志一起使用时,您可以很容易地实现一个私有的页面级分配器/释放器.
可以使用mprotect()更改内存映射区域上的保护。与munmap()一样,mprotect()并不局限于共享内存区域——它可以更改进程中任何内存区域的保护。
初始化分配的内存
POSIX要求mmap()zero它所分配的任何内存。初始化内存可能需要一段时间,因此QNX中微子提供了一种放松POSIX需求的方法。这允许更快的启动,但可能是一个安全问题。
避免初始化内存需要执行unmapping的进程和执行mapping的进程的合作:
- munmap_flags()函数是一个非posix函数,类似于munmap(),但让你控制当内存下一次映射时会发生什么:
int munmap_flags( void *addr, size_t len, unsigned flags );
如果将flags参数指定为0,则munmap_flags()的行为与munmap()相同。
以下位控制分配时内存的清除:
UNMAP_INIT_REQUIRED:在下一次分配底层物理内存时,需要将页面全部初始化为0。
UNMAP_INIT_OPTIONAL:将底层物理内存的初始化设置为零是可选的。
- 如果您将MAP_NOINIT标志指定给mmap(),并且mmap()的物理内存以前使用UNMAP_INIT_OPTIONAL munmap(),则POSIX要求将内存归零的要求是宽松的。
默认情况下,内核初始化内存,但是您可以通过使用-m选项的procnto来控制它。这个选项的参数是一个字符串,让你启用或禁用内存管理器的一些方面:
i:munmap()的作用就好像指定了UNMAP_INIT_REQUIRED一样
~i:munmap()的作用就好像指定了UNMAP_INIT_OPTIONAL一样。
默认情况下,当释放内存供以后重用时,该内存的内容保持不变;无论拥有遗留内存的应用程序是什么,它都将保持不变,直到下一次该内存被另一个进程分配时为止。在QNX中微子6.6及以后版本中,procnto的-m选项允许您控制取消映射时的默认行为:
- -mc:释放内存时清除内存。
- -m~c: 释放内存时不清除内存(默认情况下)。当释放内存供以后重用时,内存的内容保持不变;无论拥有遗留内存的应用程序是什么,它都将保持不变,直到下一次该内存被另一个进程分配时为止。此时,在内存被传递给下一个进程之前,它被归零。
Typed memory
类型化内存是POSIX在1003.1规范中定义的功能。它是高级实时扩展的一部分,清单位于
类型化内存将以下函数添加到C库:
- posix_typed_mem_open():打开一个类型化内存对象。该函数返回一个文件描述符,然后可以将该文件描述符传递给mmap(),以建立类型化内存对象的内存映射。
- posix_typed_mem_get_info():获取关于类型化内存对象的信息(当前可用内存的数量)。
POSIX类型化内存为打开内存对象(以特定于操作系统的方式定义)并在这些对象上执行映射操作提供了一个接口。在BSP或特定于板的地址布局与设备驱动程序或用户代码之间提供了一个抽象。
实现定义的行为
POSIX指定以特定于实现的方式创建和定义类型化内存池(或对象)。
Seeding of typed memory regions
在QNX中微子下,类型化内存对象是从系统页面的asinfo部分指定的内存区域定义的。因此,类型化内存对象直接映射到由startup定义的地址空间层次结构(asinfo段)。类型化内存对象还继承asinfo中定义的属性,即内存段的物理地址(或界限)。
通常,asinfo条目的命名和属性是任意的,完全由用户控制。然而,也有一些强制性的条目:
- memory:处理器的物理寻址能力,在32位CPU上通常是4GB.
- ram: 系统上所有的RAM。这可能包含多个条目.
- sysram:系统内存, 即内存已经被分配给操作系统来管理。这也可能包含多个条目。
因为按照惯例sysram是分配给操作系统的内存,所以这个内存池与操作系统用来满足匿名mmap()和malloc()请求的内存池是相同的。可以使用as_add()函数在启动时创建其他条目。
Naming of typed memory regions
类型化内存区域的名称直接派生自asinfo段的名称。asinfo部分本身描述了一个层次结构,因此类型化内存对象的命名是一个层次结构。
下面是一个系统配置示例:
| name | Range(start,end) |
|---|---|
| /memory | 0, 0xFFFFFFFF |
| /memory/ram | 0, 0x1FFFFFF |
| /memory/ram/sysram | 0x1000, 0x1FFFFFF |
| /memory/isa/ram/dma | 0x1000, 0xFFFFFF |
| /memory/ram/dma | 0x1000, 0x1FFFFFF |
传递给posix_typed_mem_open()的名称遵循上述命名约定。POSIX允许实现定义当名称不是以斜杠(/)开头时会发生什么。关于开放的决议规则如下:
- 如果名称以/开头,则执行精确匹配。
- 名称可能包含中间/字符。这些被认为是路径分量分隔符。如果指定了多个路径组件,则从下往上匹配它们(与解析文件名的方式相反)。
- 如果名称不是以前导/开头,则对指定的pathname组件执行尾匹配.
以下是posix_typed_mem_open()如何使用上面的示例配置解析名称的一些示例:
| This name: | Resolves to: | See: |
|---|---|---|
| /memory | /memory Rule 1 | |
| /memory/ram | /memory/ram Rule 2 | |
| /sysram | Fails | |
| sysram | /memory/ram/sysram Rule 3 |
Pathname space and typed memory
类型化内存名称层次结构是通过/dev/ tymem之下的process manager名称空间导出的。应用程序可以列出这个层次结构,并查看系统页面中的asinfo条目,以获得关于类型化内存的信息。
NOTE:与共享内存对象不同,您不能通过名称空间接口打开类型化内存,因为posix_typed_mem_open()接受额外的参数tflag,这是必需的,open() API中没有提供。
mmap() allocation flags and typed memory objects
对于类型化内存,考虑了以下分配和映射的一般情况:
- 类型化内存池显式地从(POSIX_TYPED_MEM_ALLOCATE和POSIX_TYPED_MEM_ALLOCATE_CONTIG)分配。一个匿名对象的MAP_SHARED:
mmap(0, 0x1000, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANON,NOFD, 0);
内存被分配了,不能用于其他分配,但是如果您派生进程,子进程也可以访问它。当最后一个到内存的映射被删除时,内存被释放。
请注意,就像有人使用mem_offset()和MAP_PHYS来获得对先前分配的内存的访问一样,其他人可以使用POSIX_TYPED_MEM_MAP_ALLOCATABLE(或者没有标记)打开类型化内存对象,并通过这种方式获得对相同物理内存的访问。
POSIX_TYPED_MEM_ALLOCATE_CONTIG 就像 MAP_ANON | MAP_SHARED一样,它会导致一个连续的分配。
- POSIX_TYPED_MEM_MAP_ALLOCATABLE用于创建到对象的映射,而不需要分配或释放位置。这相当于到物理内存的共享映射。
您应该只使用MAP_SHARED映射,因为对MAP_PRIVATE映射的写操作(通常)将在普通的匿名内存中为进程创建一个私有副本。
如果不指定任何标志,或者指定POSIX_TYPED_MEM_MAP_ALLOCATABLE,则mmap()的偏移参数指定类型内存区域中的起始物理地址;如果类型化内存区域是不连续的(多个asinfo条目),那么允许的偏移量也是不连续的,并且不像共享内存对象那样从零开始。如果您指定的[paddr, paddr + size]区域位于允许的类型化内存对象地址之外,则mmap()失败返回ENXIO。
Permissions and typed memory objects
类型化内存对象的权限由UNIX权限控制。posix_typed_mem_open()的oflags参数指定所需的访问权限,这些标志将根据类型内存对象的权限掩码进行检查。
POSIX没有指定如何将权限分配给类型化内存对象。在QNX中微子下,默认权限是在系统启动时分配的。默认情况下,root是所有者和组,具有读写权限;其他人没有任何权限。目前,还没有改变对象权限的机制。将来,可能会扩展该实现以允许chmod()和chown()修改权限。
Object length and offset definitions
您可以使用posix_typed_mem_get_info()来检索对象的大小。posix_typed_mem_get_info()调用填充posix_typed_mem_info结构,其中包含posix_tmi_length字段,该字段包含类型化内存对象的大小。
正如POSIX所指定的,length字段是动态的,并包含该对象的当前可分配大小(实际上是对象的空闲大小POSIX_TYPED_MEM_ALLOCATE和POSIX_TYPED_MEM_ALLOCATE_CONTIG)。如果使用tflag为0或POSIX_TYPED_MEM_MAP_ALLOCATABLE打开对象,则长度字段设置为0。
在类型化内存对象中进行映射时,通常会向mmap()传递一个偏移量。偏移量是对象中应该开始映射的位置的物理地址。只有在使用tflag为0或POSIX_TYPED_MEM_MAP_ALLOCATABLE打开对象时,偏移量才合适。如果您使用POSIX_TYPED_MEM_ALLOCATE或POSIX_TYPED_MEM_ALLOCATE_CONTIG打开类型化内存对象,非零偏移会导致对mmap()的调用失败,错误为EINVAL。
Interaction with other POSIX APIs
类型化内存可以与其他POSIX api交互。
- rlimits:POSIX setrlimit() api提供了设置进程可以使用的虚拟和物理内存的极限的能力。由于类型化内存操作可以在普通RAM (sysram)上操作,并且会在进程的地址空间中创建映射,所以在进行rlimit核算时需要考虑这些操作。以下规则特别适用:
- mmap()为类型化内存对象创建的任何映射都被计算在进程的RLIMIT_VMEM或RLIMIT_AS limit中。
- 类型化内存从不对RLIMIT_DATA计数。
- POSIX file-descriptor functions:您可以使用posix_typed_memory_open()返回的文件描述符进行POSIX基于文件描述符的调用,如下所示:
- fstat(fd,…),它填充stat结构,就像它填充共享内存对象一样,只是size字段不包含类型化内存对象的大小。
- close(fd) 关闭文件描述符。
- dup()和dup2()复制文件句柄。
- posix_mem_offset()的行为与POSIX规范中记录的一样。
practical examples
下面是一些如何使用类型化内存的示例:
- 从系统RAM中分配连续内存
下面是一个从系统RAM中分配连续内存的代码片段:
int fd = posix_typed_mem_open( "/memory/ram/sysram", O_RDWR,
POSIX_TYPED_MEM_ALLOCATE_CONTIG);
void *vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE, fd, 0);
- 定义包内存并从中分配
假设您有特殊的内存(比如fast SRAM),希望用于包内存。这个SRAM没有放在全局系统RAM池中。相反,在启动时,我们使用as_add()(参见构建的自定义映像启动程序一章)为包内存添加一个asinfo条目:
as_add(phys_addr, phys_addr + size - 1, AS_ATTR_NONE,
"packet_memory", mem_id);
其中,phys_addr是SRAM的物理地址,size是SRAM的大小,mem_id是父节点的ID(通常是内存,由as_default()返回)。
这段代码为packet_memory创建一个asinfo条目,然后可以将其用作POSIX typed memory。下面的代码允许不同的应用程序从packet_memory分配页面:
int fd = posix_typed_mem_open( "packet_memory", O_RDWR,POSIX_TYPED_MEM_ALLOCATE);
void *vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,MAP_SHARED, fd, 0);
或者,您可能希望使用包内存作为直接共享的物理缓冲区。在这种情况下,应用程序将使用它如下:
int fd = posix_typed_mem_open( "packet_memory", O_RDWR,
POSIX_TYPED_MEM_MAP_ALLOCATABLE);
void *vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, offset);
- 定义一个dma安全区域
在某些硬件上,由于芯片组或内存控制器的限制,可能无法对系统中的任意地址执行DMA。在某些情况下,芯片组只能对所有物理RAM的一个子集进行DMA。传统上,如果不静态地保留驱动程序DMA缓冲区的RAM的一部分(这是潜在的浪费),就很难解决这个问题。类型化内存提供了一个干净的抽象来解决这个问题。这里有一个例子:
在启动时,使用as_add_containing()(参见构建嵌入式系统的自定义映像启动程序一章)来定义一个用于dma安全内存的asinfo条目。让这个条目成为ram的子条目:
as_add_containing( dma_addr, dma_addr + size - 1,AS_ATTR_RAM, "dma", "ram");
dma_addr是dma安全RAM的起始位置,size是dma安全区域的大小。这段代码为dma创建一个asinfo条目,它是ram的一个子条目。然后驱动程序可以使用它来分配dma安全缓冲区:
int fd = posix_typed_mem_open( "ram/dma", O_RDWR,
POSIX_TYPED_MEM_ALLOCATE_CONTIG);
void *vaddr = mmap( NULL, size, PROT_READ | PROT_WRITE,
MAP_SHARED, fd, 0);
管道和fifo
管道和fifo都是连接进程的两种队列形式。为了在QNX中微子RTOS中使用管道或FIFOs,管道资源管理器(pipe)必须正在运行。
管道
管道是作为两个或多个协作进程之间的I/O通道的未命名文件:一个进程向管道中写入,另一个进程从管道中读取。管道管理器负责缓冲数据。缓冲区大小在
当两个进程希望并行运行时,通常使用管道,数据从一个进程以单一方向移动到另一个进程。(如果需要双向通信,则应该使用消息。)管道的典型应用程序是将一个程序的输出连接到另一个程序的输入。这种连接通常是由shell实现的。例如:ls | more. 将标准输出从ls程序通过管道定向到more程序的标准输入。
| If you want to: | Use the: |
|---|---|
| Create pipes from within the shell | pipe symbol (“ |
| Create pipes from within programs | pipe() or popen() functions |
FIFOs
FIFOs与管道本质上是一样的,只是FIFOs被命名为永久文件,存储在文件系统目录中。
| If you want to: | Use the: |
|---|---|
| Create FIFOs from within the shell | mkfifo utility |
| Create FIFOs from within programs | mkfifo() function |
| Remove FIFOs from within the shell | rm utility |
| Remove FIFOs from within programs | remove() or unlink() function |