ATOM: Accurate Tracking by Overlap Maximization
文章目录
- Abstract
- Introduction
- Related Work
- Proposed Method
- Target Estimation by Overlap Maximization
- Target Classification by Fast Online Learning
- Experiments
- Conclusions
文章链接
代码链接
Abstract
the advancements in tracking accuracy have been limited,because the focus has been directed towards the development of powerful classifiers,the problem of accurate target state estimation has been largely overlooked,only resorting to a simple multi-scale search in order to estimate the target bounding box
下图是MDNet在OTB100CarScale上的 可视化结果,可以看到,跟踪器可以跟上,但是最后由于视角的变化,bbox不是那么精确。绿色是真值,红色是跟踪结果,siamrpn效果要比这个好很多,所以这个motivation很好。不仅要能跟上,既然能跟上,那么跟的准一些就更好了。

因此本文提出了一种新的跟踪架构,将目标估计和分类结合在一起,high-level knowledge通过离线训练结合到目标估计中。
所以目标估计(target estimation)离线训练(LaSOT,TrackingNet,COCO),为了预测目标物体和估计的bbox之间的重合度。而分类部分在线训练为了保证在有干扰物出现时有很高的判别力。running 30fps
最近几年我们在视觉跟踪鲁棒性看到了惊奇的提升,但是跟踪的准确性被限制。几乎所有的都关注于强大的分类器,而精确的目标状态估计问题被大大的忽视。大部分跟踪器为了估计目标bbox使用了一个简单的多尺度搜索,但是作者认为此方法基本上被限制了,因为目标估计是一个复杂的任务,需要目标的高层信息。
Introduction
介绍visual tracking:
Generic online visual tracking is a hard and ill-posed problem.The tracking method must learn an appearance model of the target online base on minimal supervision,often a single starting frame in the video.The model the needs to generalize to unseen aspects of the target appearance,including different poses,viewpoints,lightning conditions etc.
然后将跟踪问题分解为 分类任务和一个估计任务。
分类任务通过将图像区域分为前景和背景,鲁棒地提供目标的粗略位置,仅仅获得了目标状态的部分信息,比如图形的坐标。目标分类对于目标状态的全部是不敏感的,例如,目标的宽高。
而估计任务估计目标状态,经常用一个bounding box 来表示,bounding box 依赖目标的姿态和视角,这样可以找到full state。
提出最近几年,跟踪研究主要在目标分类上,大多数关注构建一个鲁棒的分类器。事实上,大多数最先进的跟踪器仍然依赖分类成分,通过利用多尺度搜索来进行目标估计(multi-scale search)。然而本文认为,bounding box的估计是一个挑战的任务,需要对物体的姿态有high-level的理解。
对于目标估计借鉴了2018年目标检测提出的IoU-Net 有兴趣可以看看这篇文章,我们训练了目标估计分支为了预测目标物体和估计的bbox之间的IoU(intersection over Union)overlap.由于原来的IoU-Net是class-specific,因此对于一般的跟踪是不适合的,所以我们提出了一个新的结构将target-specific信息融合到IoU 预测中。目标估计分支经过大规模数据集的离线训练,在跟踪时,最终目标的bbox可以被获得,通过简单的使用梯度上升最大化每一帧预测IoU score。
为了保证实时,我们是使用了基于共轭梯度的策略。Conjugate-Gradient-baed strategy
Related Work
这部分就简单讲一下IoU-Net
参考,这篇博文最后引用的也很好
提出了PrRol-Pooling,基于优化的边界框修正流程。Essentially,PrPool is a continuous variant of adaptive average pooling,with the key advantage of being differentiable w.r.t the bounding box coordinates B. This allows the bounding box B to be refined by maximizing the IoU w.r.t B through gradient asent.

RoI Pooling/ RoI Align /PrRoI Pooling三者的区别

Proposed Method
Target Estimation by Overlap Maximization

这是跟踪的整体架构。目标和分类任务都使用相同的backbone ResNet-18(pretrained ImageNet,no fine-tuning)
将当前帧的图片(以及真值)输入到backbone提取特征,得到了Modulation vector;接下来test image 也输入到backbone中提取特征,然后将layer3层的特征经过分类模块(trained online),预测目标的一个置信分数,从而得到一个粗略的BB estimates(位置和宽高),,接着与第一帧得到的Modulation vector进行点乘,根据之前帧得到的粗略的bbox然后随机生成10个bbox,送到目标估计模块(在大量数据离线训练好的),通过最大化iou来refine bbox(取iou最高的三个求平均)。当然在跟踪的时候iounet是不更新的,只更新分类的两层,这部分代码体现在初始化iounet的时候atmo.py中的def init_iou_net()方法中的p.requires_grad=False
另外在pytrakcing/utils/loading中net, _ = ltr_loading.load_network(path_full, backbone_pretrained=False)说明backone不采用预训练模型,而在训练的时候backbone加载的是预训练模型。
其次,原来 IoU -Net是针对class-special,而跟踪针对于任意类都可以,所以,利用了第一帧目标的标注信息,获取targe-specific信息,从而得到相应的IoU predictions。所以在跟踪时,给定第一帧的信息很重要,那怎么可以有效利用呢?本文试着和当前帧的特征融合,但是效果很差,最后提出了 modulation-base network架构来预测任意物体的IoU.我觉得这里是作为一个先验条件的,具体的目标估计网络(训练框架)如下:

清楚的可以看到,分为两个分支
reference branch ( 返回modulation vector c(x0,B0) size:1x1xD)
test branch: As the test branch extracts general features for IoU prediction,which consititutes a more complex task,it employs more layers and higher pooling resolution compared to the reference branch. the computed feature representation of the test image is then modulated by the coefficient vector c via a channel-wise multiplication.
最后bboxB预测的IoU为:g由三层全连接层组成
![]()
离线训练:在最大间隔为50的视频中采样图片对,用COCO 数据集做了数据增强,提取了目标周围的5倍大小的方形区域作为输入,同时为了防止以目标为中心过拟合,在test image上做了抖动,因为没有分类层预测bbox,因此在训练的时候将test image的bbox真值通过增加高斯噪声做了扰动,从而输入到网络作为分类的结果,而test image的真值和扰动后的值做了iou,从而作为loss进行训练。另外我我们可以从优化器部分看到,训练的时候更新的是哪一块:optimizer=optim.Adam(actor.net.bb_regressor.parameters(),lr=1e-3),也就是训练iounet那一部分。
在线跟踪:reference image (以目标为中心采样一个square patch,提取了目标周围的4倍大小的方形区域作为输入,和DaSiamese类似的方法)
For each image pair we generate 16 candidate bounding boxed by adding Gaussian noise to the ground truth coordinates,which ensuring a minimum IoU of 0.1.
data augmentation: image flipping and color jittering
We use the **mean-squared error loss function** and train for 40 epochs with 64 image pairs per batch.The
ADAM optimizer is employed with initial learning rate of 10 -3, and using a factor 0.2 decay every 15 epochs.
Target Classification by Fast Online Learning
classification model:(目标分类模块是2个卷积层)
first layer(1x1,64,w1)
second layer(4x4,1,w2)
表示为:x是backbone feature map,由于训练样本上得不到在线跟踪目标的信息,所以分类网络的head是在线训练的

基于L^2分类误差:
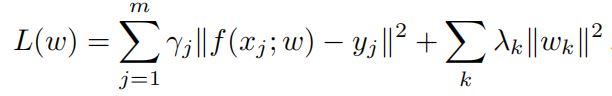
通常我们会应用标准的梯度下降或者随机梯度下降法(SGD),但是这些不是很好的适合于在线学习,因为他们慢的收敛效率。
然后把分类损失分为两部分:
![]()
![]()
最后分类损失函数合并为(将正则项的表达和残差的表达统一起来):
![]()
利用quadratic Gauss-Newton(近似忽略二阶微分)近似得到:
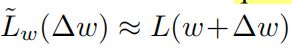
根据一阶泰勒展开式得到:
![]()
所以:

其中Jw代表r对w的雅可比矩阵,我们需要的变量就是Δw用于更新w,可以直接对Δw求导
我们使用Conjugate Gradient(CG)方法来迭代。
头疼呀,下面是优化程序算法:
In comparison to gradient descent,the CG-based method adaptively computes the learning rate a and momentum p in each iteration.
data augmentation:
varuomg degrees of translation,rotation,blur,dropout
target estimation:
extract features->apply classification model->confidence score->together with target width and height->bbox B->generate 10 proposal by adding uniform random noise to B->predicted IoU
hard negative mining
Experiments
baseline approach: only uses the test frame to predict the IoU,excludes target specific information by removing the reference branch in our architecture.
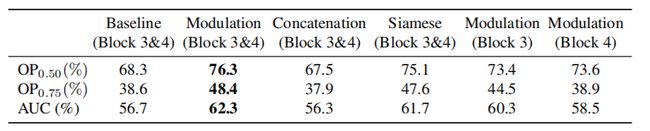
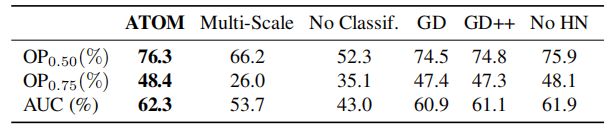
GD:gradient descent
five challenging tracking datasets:
Need For Speed
UAV123
TrackingNet
LaSOT
VOT2018
Conclusions
知道了文章的大体思路,用了一些新的数据集来测评,借鉴目标检测的IoU-Net得到一个更精确的bbox,使用高斯牛顿优化方法,(求解非线性最小二乘问题时的一个特例,把黑森矩阵用雅克比矩阵代替,当然这个是有条件的),还是去跑代码吧!这样会有更深的理解。
牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。
高斯–牛顿迭代法的基本思想是使用泰勒级数展开式去近似地代替非线性回归模型,然后通过多次迭代,多次修正回归系数,使回归系数不断逼近非线性回归模型的最佳回归系数,最后使原模型的残差平方和达到最小。
Correlation filter methods often excel at target classification by computing reliable confidence scores in a dense 2D-grid.


We therefore generate a set of 10 initial proposals by adding uniform random noise to B.The predicted IoU (1)
of each box is maximized using 5 gradient ascent iterations with a step length of 1.
