C++学习笔记
@[TOC]
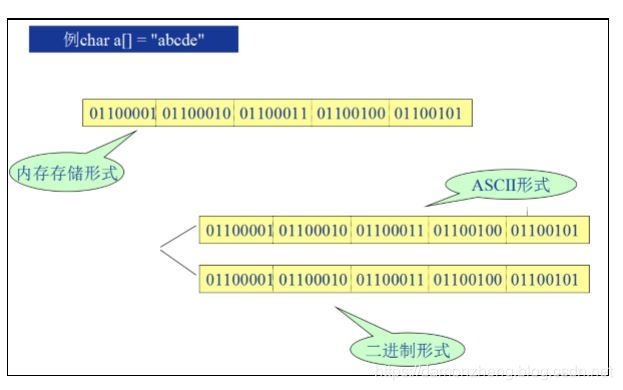
打算从今天开始学习C++,以下是个人的学习笔记。
第一章:基础语法
1.0 发展历史:
总共可以划分为以下阶段:
- 二进制指令;
- 汇编语言;
- 高级语言(C, C++, java…)
C++ 是简单也是最复杂的一门语言,如果不使用C++的一系列特性, 那么它写起来就很简单;但是既然需要C++,那我们不使用他的特性,那我们学习它干嘛呢? 它的一系列高级特性使得它是一门很复杂的语言。之前有听一位前辈说,C# 敲起来很爽,但是后期优化异常繁琐。但是C++ 前期费劲,可是优化起来就轻松很多了。至于对不对,也是我接下来一段时间想要去研究的一点。
1.1 程序,数据类型:
程序就是一个指令的合集。这些都在以前的 C 的笔记中有提到过,电脑中所有的数据都是以二进制数据储存的,这些都不说了。二进制的转化学习什么的也都是之前学习过的,数据类型也是差不多的,参照原来的笔记适当的去复习了一下下。
1.1.1 变量的声明:
语法与 C 一致:
- 声明变量类型 命名
char ch;
short sh;
int in;
char ch1, ch2;
int in1 = 1, in2 = 2;
关于变量命名的规则,所有语言都差不多。遵守规则的同时,还有考虑可读性就行。
1.2 运算符与表达式:
1.2.1 位运算:
位运算符:
| 操作符 | 功能 | 用法 |
|---|---|---|
| ~ | 按位非 | ~ expr |
| << | 左移 | expr1 << expr2 |
| >> | 右移 | expr1 >> expr2 |
| & | 按位与 | expr1 & expr2 |
| ^ | 按位异或 | expr1 ^ expr2 |
| &= | 按位与赋值 | expr1 &= expr2 |
| ^= | 按位异或赋值 | expr1 ^= expr2 |
- 关于 ~ 的运算就是按位全部取反:
~01111111 = 10000000; - 关于 & 的运算就是按位全部取与运算:
0101 & 1101 = 0101; - 关于 ^ 运算就是按位全部取异或运算:
0101 ^ 1101 = 1000; - 关于 | 就是全部取或运算:
0101 | 1101 = 1101;
==============================================================
-
关于 << 运算就是把所有的位向左移动,空余的补0:
00000001 << 1 = 00000010
00000001 << 2 = 00000100
00000001 << 3 = 00001000 -
关于 >> 的运算就是把所有的位向做移动, 空余的补0:
10000000 >> 1 = 01000000
10000000 >> 2 = 00100000
10000000 >> 3 = 00010000
左移一位相当于这个数乘以2的1次方;
左移两位相当于这个数乘以2的2次方;
左移三位相当于这个数乘以2的3次方;
左移四位相当于这个数乘以2的4次方;
。。。
右移则是除以就好;
==============================================================
-关于 &=, ^=, |= 的大致用法与 +=, -=都差不多,整个表达式的值也是符号右边的值:
int a = 0;
int b = 1;
int c = a &= b;
cout << c << endl;
c 的值就是a的值,输出为 0;
1.3 循环的使用
1.3.1 for循环
这个其实大部分的语言都有这么 for 循环的用法,这里还是记录一下。for 循环其本质也是简洁的需要(简洁对于计算机的使用真的太重要了):
int sum = 0;
for (int i = 0; i <= 100; ++i) {
sum += i;
}
cout << " 1 - 100的总和是 " << sum << endl;
这里在括号内声明的 i 是一个作用域只在这个for循环内部的局部变量,只能在 for 循环以内使用。
或者以下声明也可以,唯一的区别就是 j 和 i 的作用域不同,但他俩都是局部变量:
int j = 0;
for ( ; j <= 100; ++j) {
sum02 += j;
}
cout << " 1 - 100的总和是 " << sum02 << endl;
然后是下面这种写法因为可以的:
int k = 0;
for ( ; k <= 100; ) {
sum03 += k;
++k;
}
cout << " 1 - 100的总和是 " << sum03 << endl;
随后试了一下, for循环里是否可以什么都不添加,发现是可以的,只不过是一个死循环,将一直循环下去,如果硬要用这种形式写的话:
int g = 0;
for ( ; ; ) {
if (g > 100) {
break;
}
sum04 += g;
++g;
}
cout << " 4: 1 - 100的总和是 " << sum04 << endl;
条件语句来break出去;
1.3.2 continue的用法:
计算 1 - 100 中,能被5整除的数:
int num01 = 0;
for (int i = 1; i <= 100; ++i) {
if (!(i % 5)) {
cout << i << endl;
++num01;
}
}
cout << "1: 0 - 100 中能被5整除的数有 " << num01 << endl;
或者我们也可以用 continue 来实现:
int num02;
for (int i = 1; i <= 100; ++i) {
if (i % 5) {
continue;
}
cout << i << endl;
++num02;
}
cout << "2: 0 - 100 中能被5整除的数有 " << num02 << endl;
当 i 不能被 5 整除时,通过 continue 跳转到 for 里的 ++i,然后开始新的循环;
1.3.4 作用域:
当我们在声明变量的时候,每个变量都会有一个他自己的生命周期,通常来说,一个变量的生存周期就是在它被声明的时候起,到往后离它最近的一个大括号结束。这就是变量的生命周期。
1.3.5 while 循环
while( 表达式 ){
}
若括号内的表达式值为真,那么就执行大括号内的内容;
int sum = 0, int i =0;
while(i ++ < 10) {
sum += i;
}
当然也可以结合 continue 和 break 做到。
1.3.6 do{ } while();
与 while 类似,不同的是,do{ } while () 始终执行一此,然后再判断是否执行。类似上一个输出1 到 10 的总和,就可以用do while 来写:
int k = 1, sum02 = 0;
do {
sum02 += k;
k++;
} while (k <= 10);
cout << sum02 << endl;
1.3.7 跳转
-
break: 不能单独使用, 经常在switch里跳出;在循环里,经常跟在 if () 跳出循环。一般不会无缘无故的使用,且break只能跳出当前循环及一层循环
-
continue: 使用就像是一个筛子,过滤掉不必要的内容。也是结束当前循环及一层循环。
-
return: 退出当前函数。但是再main函数中比较特殊,是直接结束程序。 同时包含多个return的话,以第一个为准。
-
goto: 属于慎用的一个短跳转,属于很矛盾的存在,有它在基本推翻了所有之前所学的循环,对代码的结构性有极大的破坏性,不过偶尔用用还是很舒服的,比如跳出多重循环,效率特别的高。如果按照平常break层层跳出,代码会非常繁琐,我们需要声明多个flag来判断,不简洁,效率低,但是有了goto可以直接跳出多重循环。还有就是可以用于集中错误处理。
第二章:数组与指针
2.0.1:一维数组定义大小初始化
这是学习的第一种构造类型,这个构造类型是相对于之前的基本类型来说的,构造类型就是由基本类型所构造出来的产物,而不是凭空出现的。

就好比基本类型是一块砖,而构造类型是一面墙。
数组干嘛用呢:
- 当我们需要一个敌人军队,我们可以一个一个声明军队中的敌人:int enemy1; int enemy2; int enemy3… int enemy100; 这时候就可以用数组来搞定:int enemy[100];
及方便于书写,也方便于管理。
- 定义:
需要类型,命名,以及大小:
int arr[10];
相同的数据类型进行构造就组成了数组,不同的数据类型构造就组成了结构体。
这里简单说一下结构体,之后还会细学一次:
结构体的声明于定义:
struct { int a = 1; char b = a; double c = 3; }testStru;
结构体的访问:
cout << testStru.a << endl;
- 数组的初始化与赋值:
1.不初始化;》》》》》》成员初始值未知
int arr[10];
2.全初始化
int arr[10] = {1,2,3,4,5,6,7,8,9};
3.部分初始化;》》》》》未初始化的部分,自动清零
int arr[10] = {1}
4.不指定大小初始化;》》经常出没
int arr[] = {0,1,2,3,4,5,6};
C++里不可以越界初始化,但是可以越界访问,越界访问的数据的值是不确定的。凡是构造类型,要么在定义时初始化,不可以先定义再以初始化的方式赋值;凡是基本类型,既可以在定义时初始化,也可以先定义,在赋值。:
int arr[10];
arr[10] = {0,1,2,3,4,5,6,7,8,9,};
这样是错误的,arr[10]arr数组里的第十个成员,赋值运算符两边的类型是不对等的。
2.0.2 一维数组的逻辑与存储
- 一维数组在内存中是一段连续的储存区域。

如何证明一维数组的储存空间在内存中是连续的呢?
int testSaving[10] = { 0,1,2,3,4,5,6 };
for (int i = 0; i < 7; i++) {
cout << i << " 的地址是 " << &testSaving[i] << endl;
}

可以看到,他们储存的地址是连续的,且第一位成员地址是最下面的。
数组的命名不仅仅代表了一个数组构造类型,还要参与元素的访问,此时代表首元素的地址。[ ] 实际上是基址运算符,指偏移了多少个地址。
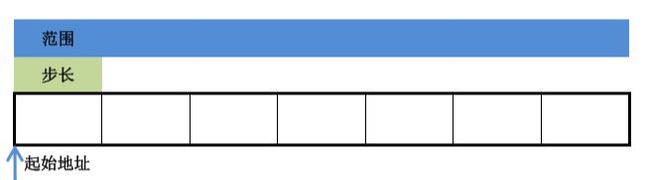
在 int arr[10] 这个声明中,int就是步长且为4,arr就是起始地址,10就是范围。起始地址,步长,以及范围是数组的三要素。
2.1.0 数组的运用
2.1.1 数组求和与平均值
int practice01[10] = { 0,1,2,3,4,5,6,7,8,9 };
int sum = 0;
for (int i = 0; i < 10; i++) {
sum+=practice01[i];
}
cout <<"这一组数的总和是:"<< sum << endl;
cout << "这一组数的平均值是:" << (float)sum / (sizeof(practice01) / sizeof(int)) << endl;
2.1.2 数组的最值
int practice02[5] = { };
int lengthOfArr = sizeof(practice02) / sizeof(int);
for (int i = 0; i < lengthOfArr; i++){
cout << "请输入第 " << i+1 << " 个数" << endl;
cin >> practice02[i];
}
int minNum = practice02[0], maxNum = practice02[0];
for (int i = 0; i < 5; i++) {
maxNum = practice02[i] >= maxNum ? practice02[i] : maxNum;
minNum = practice02[i] <= minNum ? practice02[i] : minNum;
}
cout << "这一组数中,最大的数是 " << maxNum << endl << "这一组数中,最小的数是 " << minNum << endl;
2.1.3 排序
- 选择排序:
int selectSort[N] = { 4,2,1,3,5,8,7,9,0,6 };
int lengOfSel = sizeof(selectSort) / sizeof(int);
int temp = 0;
for (int i = 0; i < 9; i++) {
for (int j = i+1; j < 10; j++) {
if (selectSort[i] > selectSort[j]) {
temp = selectSort[j];
selectSort[j] = selectSort[i];
selectSort[i] = temp;
}
}
}
- 选择排序Pro:
比较不换,只记下标,只换最小值的下标;
int newSort[N] = { 3,6,8,1,0,5,3,2,9,33 };
int newTemp = 0;
for (int i = 0; i < 9; i++) {
int idx = i;
for (int j = i+1; j < 10; j++) {
if (newSort[j] < newSort[idx]) {
idx = j;
}
}
if (idx != i) {
cout << newSort[i] << "交换" << newSort[idx] << endl;
newSort[idx] ^= newSort[i];
newSort[i] ^= newSort[idx];
newSort[idx] ^= newSort[i];
}
}
2.1.3 查找
- 线性查找
就是从头找到尾:
int findArry[N] = { 0,1,2,3,4,5,6,7,8,100 };
int findNum = 0;
int newIdx = -1;
cin >> findNum;
for (int i = 0; i < 10; i++) {
if (findArry[i] == findNum) {
newIdx = i;
}
}
if (newIdx == -1) {
cout << "没有找到" << endl;
}
else {
cout << "索引是 " << newIdx << endl;
}
- 折半查找:
要求数组是有序为前提:
int findArry[N] = { 0,1,2,3,4,5,6,7,8,100 };
int right = N - 1, left = 0, mid = -1, newFindNum = 0, ifFind=0;
cin >> newFindNum;
while (right >= left) {
mid = (right + left) / 2;
if (findArry[mid] == newFindNum) {
ifFind = 1;
break;
}
else
{
if (newFindNum < findArry[mid]) {
right = mid - 1;
}
else {
left = mid + 1;
}
}
}
if (ifFind) {
cout << "下标是 " << mid << endl;
}
else {
cout << "没有找到" << endl;
}
2.2.0 二维数组
- 二维数组的本质也是一个数组,只不过相当于每个一维数组中的每个元素又是一个一维数组而已。
- int[4] arry[3] => int arry[3][4],相当于一个三行四列的表格一样。
- 声明/定义:
int arr[3][4];
- 初始化:
- 满初始化:
int arr[3][4] = {{1,2,3,4}, {4,5,6,7}, {7,8,9,0}};
- 未初始化:
随机值; - 部分初始化:
情况一(行部分初始化):
int arr[3][4] = {{1,2}, {4,5,7}, {7,8,}};

会在每一个一维数组里缺失的部分填入0;
情况二(整体部分初始化):
int arr[3][4] = {1, 2 , 4, 5, 7, 7,8};

会依次按照步长来凑齐前面的一维数组;
总结就是,一维数组的数组名是一个一级指针,二维数组的数组名是一个数组指针。
2.2.1 二维数组的数据形态
- 我们主要在二维数组中研究二维平面中的逻辑。
- 主对角线与此对角线的输出:输入一个 4x4 的二维数组,并输出该数组的主对角线和此对角线上的元素:
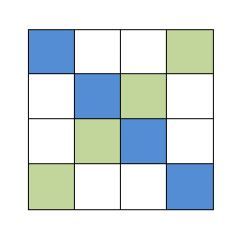
for (int i = 0; i < 4; i++) {
int temp = i;
while (temp--){
cout << " ";
}
cout << chaseArry[i][i] << endl;
}
for (int i = 0; i < 4; i++) {
int temp2 = 3-i;
while (temp2--) {
cout << " ";
}
cout << chaseArry[i][3-i] << endl;
}
- 逆置一个二维字符数组:将一个 4x4 矩阵进行逆置处理,要求初始化原始矩阵,输出原矩阵和逆置后的矩阵。

char temp3;
for (int i = 0; i < 4; i++) {
for (int j = 0; j < 4; j++) {
if (i > j) {
temp3 = charsArry[i][j];
charsArry[i][j] = charsArry[j][i];
charsArry[j][i] = temp3;
}
}
}
- 天生棋局:生成一个 10*10 的棋局,要求,初始化为 0, 随机置入10颗棋子,棋子的位置为1,并打印:
srand((int)time(0));
int newChas[10][10] = { 0 };
int count = 10;
while(count--) {
int ramX = rand() % 10, ramY = rand() % 10;
while (newChas[ramX][ramY]) {
ramX = rand() % 10;
ramY = rand() % 10;
cout << "重复了 " << "X:" << ramX << " Y:" << ramY << endl;
}
newChas[ramX][ramY] = 1;
}
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
cout << newChas[i][j] << " ";
}
putchar(10);
}
或者
srand((int)time(0));
int newChas[10][10] = { 0 };
int count = 0;
while(1) {
int ramX = rand() % 10, ramY = rand() % 10;
if (newChas[ramX][ramY] != 1) {
newChas[ramX][ramY] = 1;
count++;
if (count == 10) {
break;
}
}else{
cout << "重复了 " << "X:" << ramX << " Y:" << ramY << endl;
}
}
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
cout << newChas[i][j] << " ";
}
putchar(10);
}
- 或者可以用continue来实现:
srand((int)time(0));
int newChas[10][10] = { 0 };
int count = 10;
while(count--) {
int ramX = rand() % 10, ramY = rand() % 10;
if (newChas[ramX][ramY] == 1) {
cout << "重复了 " << "X:" << ramX << " Y:" << ramY << endl;
continue;
}
else {
newChas[ramX][ramY] = 1;
}
}
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
cout << newChas[i][j] << " ";
}
putchar(10);
}
- 判断上面生成的棋局是否是好棋:
关键思路就是我们需要扫描我们的棋盘,先一行一行进行扫描,如果有连续5个一横排,就是好棋,如果横排没有那么我们就竖着扫描。
int chaseCount = 0;
int flag = 0;
int flagCol = 0;
for (int i = 0; i < 10; i++) {
chaseCount = 0;
for (int j = 0; j < 10; j++) {
if (chaseBd[i][j] == 1) {
chaseCount++;
if (chaseCount == 3) {
flag = 1;
break;
}
}
else {
chaseCount = 0;
}
}
if (flag == 1) {
break;
}
}
chaseCount = 0;
for (int i = 0; i < 10; i++) {
flagCol = 0;
for (int j = 0; j < 10; j++) {
if (chaseBd[j][i] == 1) {
chaseCount++;
if (chaseCount == 3) {
flagCol = 1;
break;
}
}
else {
chaseCount = 0;
}
}
if (flagCol == 1) {
break;
}
}
if (flag == 1 || flagCol == 1) {
cout << "flag: " << flag << " flagCol: " << flagCol << endl;
cout << "好棋" << endl;
}
-
五子棋的输赢判断:

在五子棋中,除了判定横竖的范围外,我们还需要判定类似于以上斜着的获胜条件。因为并不是所有的斜获胜都能行,所以在10 x 10的棋盘中,有以上的一个范围。 -
有序数组归并
合并两个已经有序的数组A[M], B[N],到零为一个数组C[M+N]中去,使另外一个数组依然有序,其中M和N均是宏常量。
int A[M] = { 1,34,65,76,80 };
int B[N] = { 2,4,6,8 };
int C[M + N];
int i = 0, j = 0, k = 0;
while (i < M &&j < N) {
if (A[i] < B[j]) {
C[k++] = A[i++];
}
else {
C[k++] = B[j++];
}
}
while (i < M) {
C[k++] = A[i++];
}
while (j < N) {
C[k++] = B[j++];
}
for (int i = 0; i < M + N; i++) {
cout << C[i] << " ";
}
2.2.2 数组名的二义性
数组名是数组的唯一标识符。
- 数组名充当一种构造类型
int arr[10];
cout << "sizeof(arr[10]) = " << sizeof(arr) << endl;
cout << "sizeof(int[10]) = " << sizeof(int[10]) << endl;
- 数组名充当访问数据成员的首地址
int arr[10] = {2};
cout << "arr = " << arr << endl;
]cout << "&arr[0] = " << &arr[0] << endl;
cout << "*(arr+0) = " << *(arr+0) << endl;

第三章:指针(Pointer)
指针本身并不复杂,但是指针的难点在于它将与我们学习过的所有的数据类型都产生关系。所有的数据都被我们储存在内存里。而指针又是直接操作内存的。所以它是天使也是魔鬼,后期所有的bug,崩溃等问题基本都与指针有关。
3.1 认识内存
3.1.1 线性内存
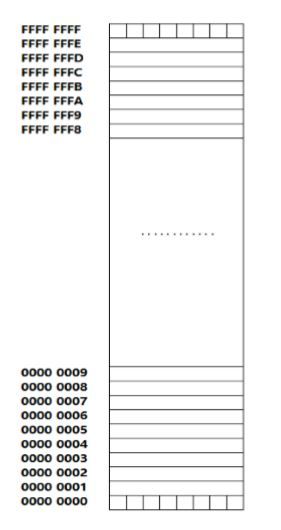
之前学习的那些一维数组,二维数组都仅仅是逻辑上的体现,最终数据都是要保存到内存当中的,而内存又是线性的,内存的线性是物理基础。
之前我们看到看到的二维数组都是一种行列的表格形式,但是那仅仅是我们在逻辑上的一种表达方式:
但是内存一种线性的存在,所以他实际在内存中的储存形式是这样的:

我们知道一维数组的逻辑和储存都是一致的,均是线性的,而二维数组的逻辑是二维的,但是其储存是线性的。储存的线性原因就是内存的物理特质所决定的。
int arr[3][4] = { 1,2,3,4 };
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
cout << &arr[i][j] << endl;
}
putchar(10);
}

有此可见数组在内存中是一段连续的储存空间。
3.1.2 变量的地址与大小

如上图所示,一个格子代表一个内存。在一段内存中,int类型包含了4个地址,double包含了8个地址等,那么我们在取地址的时候,到底取的是哪一个地址呢?我们拿的都是低位字节的那一个地址,也就是每个类型中最下面那一个地址。
32位机的前提下,每个内存的大小都是4个字节,64位则是8个字节。
char a = 1;
short b = 2;
int c = 10;
double d = 123.45;
printf("&a = %p\n", &a);
cout << "&b = " << &b << endl;
cout << "&c = " << &c << endl;
cout << "&d = " << &d << endl;
3.2 指针常量
其实我们在上一节中对一个变量取地址取出的地址就是一个指针了,且是一个常量指针。那么既然取出的地址就是一个指针,但是我们取出的地址往往只是一个单纯的地址而已,真正的常量指针,还需要加上指针类型。所以指针的本质是一个有类型的地址,然而类型决定了从这个地址开始的寻址能力。
3.3 指针变量
但凡与*扯上关系的,都是和指针扯上关系了的,并且一个指针类型的大小都是4个字节,因为只是储存的一个地址。
char a; short b; int c; float d; double e;
cout << sizeof(char *) << endl;
cout << sizeof(short *) << endl;
cout << sizeof(float *) << endl;
cout << sizeof(int *) << endl;
cout << sizeof(double *) << endl;

- 声明一个指针:
type * pointerName
*表明了本变量指针变量,大小,类型决定了该指针变量中的地址的寻址能力。
声明一个指针常量,必须要保存两样东西,一个地址数据,一个类型。
- 寻址能力的研究:
int data = 0x123456;
int *pdata = &data;
cout << hex;
cout << *pdata << endl;
cout << hex;
cout << *(int*)pdata << endl;
printf("%x\n", *(char*)pdata);
cout << hex;
cout << *(short*)pdata << endl;

** - 指针的本质 就是有类型的地址。**
** - 类型又代表着寻址能力。**
** - 所以当我们比较两个指针时,不仅要比较其所指地址,还要比较其类型。**
3.3.1 指向/被指向/更改指向
我们通常进行口述表达时说,谁指向了谁,就是一种描述指针的指向关系。指向谁,就代表保存了谁的地址。
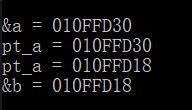
- 指向谁就是保存了谁的地址
int a = 43;
int* pt_a = &a
cout << "&a = " << &a << endl;
cout << "pt_a =" << pt_a << endl;

- 更改指向
指向是可以更改的,就好比一个巫毒娃娃,我今天可以用它来操控小明,明天可以用它来操控小刚;
int a = 43;
int* pt_a = &a;
int b = 305419896;
int *pt_b = &b;
cout << "&a = " << &a << endl;
cout << "pt_a = " << pt_a << endl;
pt_a = &b;
cout << "pt_a = " << pt_a << endl;
cout << "&b = " << &b << endl;
3.3.2 NULL
8.3.2.1 野指针(Invalid Pointer)
也就是无效指针,我们习惯性称它为野指针。因为是一个非常危险的东西,就像野熊,野狼一样的存在。常见情形有两种,一是未初始化的指针, 二是指向已经被释放的空间。
- 关于未初始化的指针为什么危险呢
int* pt_a;
*pt_a = 100;
像以上的例子,我们声明了指针哟吼并没有去初始化它,导致后面去使用它时操纵了一段未知空间的值。一般来说,去读一个野指针问题还不大,但是去写一段野指针往往会被系统拦截或者引发程序崩溃,但是!!!!你若是对一个野指针写入成功了,这造成的后果是无法估量的。
所以我们需要养成一个习惯,就是没声明一个指针,哪怕我们不会马上适用它,我们也要把它声明成一个NULL指针。
3.3.2.2 NULL指针
int* pa = NULL;// NULL (void*) 0;
实际就是约定内存中专门为未初始化的指针的这么一个标记位。官方说法是NULL指针既不能读,也不能写。
3.4 指针运算
指针能参与运算的并不多,但是非常的特别。
3.4.1 赋值运算
不兼容类型的赋值会发生类型丢失,为了避免隐式转换带来可能出现的错误,最好用强制转换显示的区别。
3.4.2 算术运算
指针的算术运算,不是简单的数值运算,而是一种数值加类型运算。将指针加上或者减去某个整数值(以n*sizeof(T)为单位进行操作的)。

前面提到说,指针算术运算是一种数值加类型的一种运算,什么意思呢:
int * i = (int *)0x0001;
short * s = (short *)0x0001;
double * d = (double *)0x0001;
cout << "i = " << i << " i+1 = " << i + 1 << endl;
cout << "s = " << s << " s+1 = " << s + 1 << endl;
cout << "d = " << d << " d+1 = " << d + 1 << endl;
我们能得到结果:
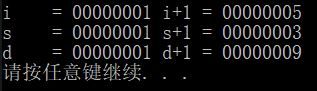
可以总结出,指针算术加减的是步长,也就是指针类型的大小。指针实际就是 类型(步长)+地址(物理数据);
- 具体理解可以通过下面这个例子来理解:
int arr[10];
int * pHead = &arr[0]; int * pTail = &arr[9];
int address = (int)&arr[9] - (int)&arr[0];
cout << address << endl;
cout << pTail - pHead << endl;
我们得到的输出如下:
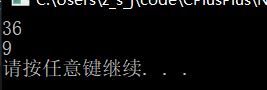
int 类型的指针每加一是加4个数值。实际就可以看成指针的是在储存单元里按照类型大小来进行运动的。
值得一提的是,只有当指针指向一连串连续的储存单元时,指针的移动才有意义。
3.4.3 关系运算

注意,于C不同,C++不同类型的指针是不能进行比较的
指针的关系运算有什么用呢,有了上面的学习吗,现在可以重新来做回文判断了:
判断一char类型数组是否是一个回文数组:
char name[5] = { 'M', 'A', 'D', 'A', 'M' };
char * ptrCharL = &name[0];
char * ptrCharR = &name[4];
int ifTrue = 1;
while (ptrCharR < ptrCharL) {
if (*ptrCharR == *ptrCharL) {
ptrCharL++;
ptrCharR--;
}
else {
ifTrue = 0;
break;
}
}
if (ifTrue) {
cout << "是的" << endl;
}
else {
cout << "不是" << endl;
}
3.5 数组访问
3.5.1 偏移法,本质法
数组名其实就是一个指针,这个例子最能体现数组名就是指针这一本质。
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (int i = 0; i < 10; i++) {
cout << *(arr + i) << endl;
}
3.5.2 下标法
最不能体现数组名本质的方法,但是很直观。
int arr2[10] = { 11,22,33,44,55,66,77,88,99,1010 };
for (int i = 0; i < 10; i++) {
cout <<
3.5.3 一维数组名可以赋给一级指针
先做两个铺垫:
数组名是一个常量指针
能用数组名解决的问题,都能用指针来解决,能用指针解决的问题,一定能用数组名解决,数组名解决不了的事情,指针也可以解决。
数组名就如同孙悟空的金箍棒,也就是定海神针,它是一个常量指针,你试图更改它,那这片海就出大事了。
cout << "arr = " << arr << endl;
cout << "arr+1 = " << arr + 1 << endl;
cout << "&arr[0] = " << &arr[0] << endl;
cout << "&arr[0]+1 = " << &arr[0] + 1 << endl;

由此可见,之前提到过的,数组名就是一个指针,而指针又是一个数据的地址。数组名所储存的就是arr[0]的地址。
int * pa = arr;
cout << pa << endl;
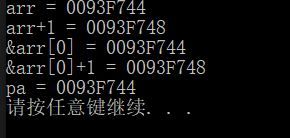
这里有的人可能就就会认为,**二维数组名可以赋值给一个二级指针,这种说法是错误的!**二维数组名就是一个单纯的数组名,二维数组是一个指向指针的指针,两个东西不是一个类型!
3.6 二维数组与指针
有这么一个数组:
int a[3][4] ={
11,12,13,14,
21,22,23,24,
31,32,33,34
};
从 a 到 a[0] 再到 a[0][0] 到底经历了什么呢

第四章 函数
我们为什么使用函数呢,总结起来就是以下几点好处:
- 可以提高程序开发效率。
- 提高了代码的重用性。
- 使程序变得更简短而清晰。
- 有利于维护。
4.1.1 rand()
rand()函数能生成一个随机数,但是这个随机数是一个伪随机数,你会发现每一次运行以下代码:
int randNum = rand();
cout << randNum << endl;
输出结果都是41。
所以为了达到真正的随机数效果,我们通常都会一起使用 srand(unsinged int seed) 函数一起使用。它的作用是初始化随机数生成器。参数seed就是一个给随机数生成器的整形数种子。每一次生成随机数都是在这个种子的基础上套用算法叠加出来的随机数,所以在计算机里压根不存在真正的随机数,这也就是彩票不使用计算机开奖的原因了。那么我们要怎么办才能尽力拿到一个近似随机数呢?
在计算机世界中,也有类似于纪念日的这么一个日期,也就是世界上第一台操作系统诞生的日期,1979-1-1 零点。我们添加 ctime 库,然后在srand中添加(time(0)):
srand((int)time(0));
这个time(0)就是从计算机元年到现在的秒数,并且是一直在变化的。但是如果你运行的足够快,两次运行结果是不变的。
在这里可以尝试写一下往一个数组里添加不同的随机数了。
我写的过程简单,就是用重复的话计数退位,然后两个break搞定。如下:
int randArr[10];
int count = 0;
while (1) {
int randNum = rand() % 10;
randArr[count++] = randNum;
for (int i = 0; i < count - 1; i++) {
if (randArr[i] == randArr[count-1]) {
count--;
break;
}
}
if (count == 10) {
break;
}
}
那如果我们要求对[100,200]取随机数呢,我们只需要对随机数做处理就行了,随机0-100的随机数在加100就行了。或者500 - 900 之间的随机数,也可以:
int arr[400];
int count = 0;
while (1) {
int randNum = rand() % 401 + 500;
arr[count++] = randNum;
for (int i = 0; i < count - 1; i++) {
if (arr[i] == arr[count - 1]) {
count--;
break;
}
}
if (count == 400) {
break;
}
}
注意这里是双边包含的中括号 [ ],所以取0-400的数应该是对401取模。
4.1.2 常用函数库

4.2 自定义函数
我们在写自定义函数的时候,推荐先将函数调用写出来,这样做的原因是在一开始就把所有的调用方法确定下来了,类似于函数名啊,参数啊之类的。比如我们要写一个求两数中最大数的函数:
4.2.1 定义与声明
int main() {
int a = 10,b = 23;
int iMax = FindMax(a, b);
cout << "最大值 = " << iMax << endl;
system("pause");
return 0;
}
这样定义就出来了,然后再去写函数:
int FindMax(int a, int b) {
return a > b ? a : b;
}
int main() {
int a = 10,b = 23;
int iMax = FindMax(a, b);
cout << "最大值 = " << iMax << endl;
system("pause");
return 0;
}
在这里我们就可以区分定义和声明的区别了,之前我没有区分过声明和定义的具体区别,在这里就可以具体说一下区别了。
- 定义在前,调用在后,是显式声明。
//定义在这里
int FindMax(int a, int b) {
return a > b ? a : b;
}
//第哦啊用
int main() {
int a = 10,b = 23;
int iMax = FindMax(a, b);
cout << "最大值 = " << iMax << endl;
system("pause");
return 0;
}
- 调用在前,定义在后,是隐式声明,此时需要前向声明,例子如下:
int FindMax(int a, int b); //前向声明在这里;
//调用在这里
int main()
{
int a = 10, b = 23;
int iMax = FindMax(a, b);
cout << "最大值 = " << iMax << endl;
system("pause");
return 0;
}
//定义在这里
int FindMax(int a, int b) {
return a > b ? a : b;
}
所以,函数的定义和声明的区别,前向声明就是声明,定义就是就是后面的定义。所以函数的特点就是先声明,后使用。所以,头文件的作用就是把里面函数的声明放在调用之前。
4.2.2 实参与形参
- 实参
在函数调用的时候,输入的参数,就是实参。 - 形参
在函数定义或是声明的时候的参数,就是形参。其中,声明中的形参可以省略。
int FindMax(int a, int b); //前向声明在这里,这里就是形参
//int FindMax(int , int ); 也可以这样省略形参
int main()
{
int a = 10, b = 23;
int iMax = FindMax(a, b);// 调用在这里,所以是实参
cout << "最大值 = " << iMax << endl;
system("pause");
return 0;
}
//定义在这里,所以是形参
int FindMax(int a, int b) {
return a > b ? a : b;
}
如果入参中没有参数,可以用void表示无入参,通常省略。如果没有返回值,即返回类型是void。
4.3 传址与传值
传址与传值在本质上都是传递了一个数值而已。但是呈现出来的应用结果是有所不同的。
有两句结论需要理解一下:
- 函数在被调用之前,其内所有变量的尚未开辟内存空间。
- 内存空间的开辟起始于函数调用之前,内存空间消失结束于函数调用完毕。
看以下例子:
void Func(int a);
int main()
{
int a = 10;
Func(a);
cout << "Main a = " << a << endl;
system("pause");
return 0;
}
void Func(int a)
{
a++;
cout << "Func a = " << a << endl;
}
运行结果如下:

这是为什么呢?原因是,
- 当我们调用main的时候,此时有了main中 a的内存空间。
- 其后调用了Func(int a) 函数,这时有了Func中a的内存地址,注意,Func中的a和main中的a虽然都是a,但是他们两个是除了名字相同以外的两个东西,两个a的内存空间位置并不是同一个。
- 这时Func中的a自加以后并且输出一此。
- Func调用完毕,此时Func中的a的空间被销毁。
- main开始打印a的值,因为两个a并不是一个内存空间,所以这个a还是10;
这种现象,就叫做传值,通过传值的方式达不到修改变量a的目的,这时候我们就可以通过传址的方式来达到。
void Func(int * a);
int main()
{
int a = 10;
Func(&a);
cout << "Main a = " << a << endl;
system("pause");
return 0;
}
void Func(int * a)
{
(*a)++;
cout << "Func a = " << *a << endl;
}
大致流程如下:
- 当我们调用main的时候,此时有了main中 a的内存空间。
- 其后调用了Func(int * a) 函数,这时我们在Func的内存空间中拿到的是main中a的地址。
- 记得之前理解指针时,我说有了一个内容的指针,就像有了这个指针的巫毒娃娃,我们能随意操纵这个内容了吗,这是我们对这个地址里的内容进行操纵,已经改变了main中a的内容,然后打印的其实是main中a的值 。
- Func调用完毕,此时Func中的空间被销毁。
- main开始打印a的值,因为两个a已经被通过地址改变,所以打印出的就是11;
这就是传址。通过传递地址来操纵地址里的内容,就像火影里的勘九郎和蝎,内容就想一个木偶,而地址就像一根引线,扔一根引线给函数,让函数通过引线简洁操纵内容这个木偶

当我们需要改变main函数中变量本身的时候,比如这里的a和b,我们就需要传址。地址对于不同的作用域来说是开放的。
4.3.1 如何传递一个一维数组
C++是基于效率原因,数组的传递是不可能通过拷贝的方式来传递,试想以下,当你要传递一个包含成千上万个元素的数组的时候,你要把所有元素拷贝到另外一个空间,那将是一个大工程。我们看看以下例子:
void DisArry(int arr[10]);
int main()
{
int arr[10] = { 0,1,2,3,4,5,6,7,8,9 };
cout << "sizeof(main arr_ = " << sizeof(arr) << endl;
DisArry(arr);
system("pause");
return 0;
}
void DisArry(int arr[10])
{
cout << "sizeof( DisArry) = " << sizeof(arr) << endl;
}
输出结果如下:

其实不管你在数组那里使用char也好,double也好,short也好,在DisArry里的输出都是4个字节。这是为什么呢,在我们一直更改内省的时候,它的size都没有改变,而且一直是4,这让我第一时间想到了,这可能是 arr[0] 的地址,所以我便测试了一下
void DisArry(int arr[10]);
int main()
{
int arr[10] = { 0,1,2,3,4,5,6,7,8,9 };
cout << "sizeof(main arr_ = " << sizeof(arr) << endl;
cout << "main a = " << &arr[0] << endl;
DisArry(arr);
system("pause");
return 0;
}
void DisArry(int arr[10])
{
cout << "sizeof( DisArry) = " << sizeof(arr) << endl;
cout << "DisArry a = " << arr << endl;
}
输出如下:

看来猜测并没有错,数组传递真的是传递数组的首地址。这时候的数组名仅仅只充当首元素地址使用。所以像以上那样传递数组,我们仅仅传递了数组的起始地址和它的步长,当我们想要写一个打印数组的函数时,如下:
void PrintArry(int * ptrArr);
int main()
{
int arr2[10] = { 0,1,2,3,4,5,6,7,8,9 };
PrintArry(arr2);
system("pause");
return 0;
}
void PrintArry(int * ptrArr)
{
for (int i = 0; i < 10; i++)
{
cout << *ptrArr++ << endl;
}
}
这样就行了,但是,这里有一个弊端,上面提到了,我们这样只把数组名当作入参的话,只传入了起始地址和步长,所以我们需要打印其他长度的数组时,又要去修改自定义的PrintArry或者是重新写一个自定义,这样也很麻烦,所以我们也需要把数组的长度也就是范围一起传递进去,就变成了下面这样:
void PrintArry(int * ptrArr,int length);
int main()
{
int arr2[] = { 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15};
PrintArry(arr2,sizeof(arr2)/sizeof(*arr2));
system("pause");
return 0;
}
void PrintArry(int * ptrArr, int length)
{
for (int i = 0; i < length; i++)
{
cout << *ptrArr++ << endl;
}
}
这样就ok啦;
4.3.2 函数的包装
像之前写选择排序,我们现在就可以把整个方法一点一点包装起来了。
- 我们先在main里写出大致思路:
需要一个数组,然后用随机数初始化这个数组,再打印一此,然后排序,最后再输出一次
int main()
{
int arr[10];
InitRandArr(arr,10);
DisPlayArr(arr, 10);
SelecSort(arr, 10);
DisPlayArr(arr, 10);
system("pause");
return 0;
}
- 随后我们包装我们的InitRandArr
简单的在数组里填入随机数就好
void InitRandArr(int * arr, int length)
{
for (int i = 0; i < length; i++)
{
*arr++ = rand() % 100;
}
}
- 再然后是DIsPlayArr:
void DisPlayArr(int * arr, int length)
{
for (int i = 0; i < length; i++)
{
cout << *arr++ << " ";
}
cout << endl;
}
- 这里就是选择排序的函数:
void SelecSort(int * arr, int length)
{
int idx;
for (int i = 0; i < length-1; i++)
{
idx = SmallestIdx(i, arr, length);//找出最小数的索引
if (idx != i)
{
MySwape(arr, idx, i);
}
}
}
- 找出最小数索引SmallestIdx():
int SmallestIdx(int i, int * arr, int length)
{
int idx = i;
for (int j = i + 1; j < length; j++)
{
if (arr[j] < arr[idx])
{
idx = j;
}
}
return idx;
}
- 最后是交换函数,因为只有两个不一样的才需要交换,所以我这里用了位运算来进行:
void MySwape(int * arr,int idx,int i){
arr[idx] ^= arr[i];
arr[i] ^= arr[idx];
arr[idx] ^= arr[i];
}
- 整体代码就如下:
void InitRandArr(int * arr, int length);
void DisPlayArr(int * arr, int length);
void SelecSort(int * arr, int length);
int SmallestIdx(int i, int * arr, int length);
void MySwape(int * arr, int idx, int i);
int main()
{
srand((int)time(0));
int arr[10];
InitRandArr(arr,10);
DisPlayArr(arr, 10);
SelecSort(arr, 10);
DisPlayArr(arr, 10);
system("pause");
return 0;
}
void SelecSort(int * arr, int length)
{
int idx;
for (int i = 0; i < length-1; i++)
{
idx = SmallestIdx(i, arr, length);
if (idx != i)
{
MySwape(arr, idx, i);
}
}
}
void MySwape(int * arr,int idx,int i){
arr[idx] ^= arr[i];
arr[i] ^= arr[idx];
arr[idx] ^= arr[i];
}
int SmallestIdx(int i, int * arr, int length)
{
int idx = i;
for (int j = i + 1; j < length; j++)
{
if (arr[j] < arr[idx])
{
idx = j;
}
}
return idx;
}
void InitRandArr(int * arr, int length)
{
for (int i = 0; i < length; i++)
{
*arr++ = rand() % 100;
}
}
void DisPlayArr(int * arr, int length)
{
for (int i = 0; i < length; i++)
{
cout << *arr++ << " ";
}
cout << endl;
}
这就可以看出函数在结构和逻辑设计上的应用。
4.3.3 小结
上面我们主要还是讲解了按值传递与按址传递的一些区别。从下图我们可以看书,按值传毒其实就是一张单程票,去了就回不来的一个状态。而按址传递则是一张往返票,地址传递过去对地址里的内容进行操作而达到一个反作用在原数据上的一种方式。

4.4 函数的调用
4.4.1 普通调用
首先树立一个概念,所有的函数都是平行的。即在定义函数时是分别进行的,是相互独立的。函数间可以互相调用。常见有平行调用,嵌套调用。
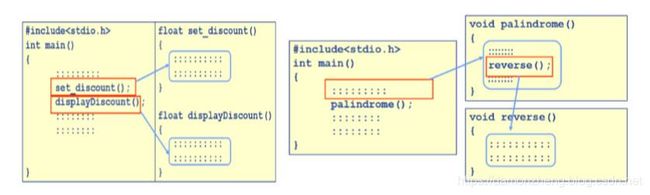
上图大致描绘了一个函数在调用时所走的流程。每个函数都是独立的,且函数之间都是相互平行且可以被相互调用的。如下:
void Fun();
void Foo();
int main()
{
cout << "main()被调用" << endl;
Fun();
Foo();
cout << "main()调用结束" << endl;
putchar(10);
system("pause");
return 0;
}
void Fun()
{
cout << "Fun()被调用" << endl;
Foo();
cout << "Fun()调用结束" << endl;
putchar(10);
}
void Foo()
{
cout << "Foo()被调用" << endl;
cout << "Foo() 调用结束" << endl;
putchar(10);
}
之后做了一个猜想,既然所有函数都是可以相互调用的,那么main()函数是否也可以被其他函数所调用呢。于是有了以下测试:
int main()
{
cout << "main()被调用" << endl;
Fun();
cout << "main()调用结束" << endl;
putchar(10);
system("pause");
return 0;
}
void Fun()
{
cout << "Fun()被调用" << endl;
main();
cout << "Fun()调用结束" << endl;
putchar(10);
}
编译通过是没有问题的,但是在运行时,会发现程进入了一种类似于死循环的一种状态,但是却有一点不同之处在于,这个程序随后会挂掉。这就是嵌套调用,main()调用了Fun(), 在Fun()中又调用了main(),随后又调用Fun(),这就形成了你调用我,我调用你的状态,两个人拉拉扯扯没完没了的调用对方。那么为什么嵌套调用多了以后程序会挂掉呢,就是因为栈溢出,以后会慢慢讲到。
以上就说明了所有函数都是平行的,可以互相调用方,哪怕你是main()函数也不例外。
4.4.2 递归(Recursive)调用
其实大部分人会在刚才我们就会想到递归调用的本质,因为刚才我们说所有函数都是平行的,且可以相互调用。肯定有人会想到,那么一个函数自己调用自己会发生什么呢?其实这就是递归调用的本质,**函数直接或是间接的自己调用自己。**如同刚才我们让main() 函数调用了Fun()。然后在Fun() 中又调用了main()函数,这其实就可以看作是main()函数间接的调用了自己不是吗?
那么为什么我i们要去学习递归调用呢?这是因为,递归调用是一种比较接近自然语言特性的一种调用方式。
递归如下:
int main()
{
cout << "main()被调用" << endl;
Fun();
Foo();
cout << "main()调用结束" << endl;
putchar(10);
main();//递归调用在这里,main()自己调用自己
system("pause");
return 0;
}
以上就是main()的递归,直接调用自己。其运行结果不用猜就知道,大致等价于Fun()和main()互相调用,程序最终会挂掉。
当然了,这并不是我们设计递归的初中,我们一定是希望在调用递归时,所谓的递归,我们把值传递过去,随后好要再归还一个值回来,才是递归。也就是说,递归都应该有一个合理的出口。
具体看一个例子会更容易一点(昨天有学习一点关于游戏剧本的写法,这里当作一个练习来试试):
- (cg01-俯视)明亮房间,有5个人坐在一起,他们对面单独坐着一侦探
- (cg02-侦探单人)看向最右:“告诉我年龄。”
- (cg03-戊单人)回答:“我比丁大2岁。”
- (cg04-丁单人)回答:“我比丙大两岁。”
- (cg05-丙单人)回答:“我比乙大两岁。”
- (cg06-乙单人)回答:“我比甲大两岁。”
- (cg07-众人看向甲-俯视)灯微微闪几下。
- (cg08-甲单人)回答:“我今年10岁。”
- (cg09-侦探单人-bgm响-自信)回答:“我知道戊你的岁数了,真相永远只有一个!”
玩归玩闹归闹,我们需要写一个递归求戊的岁数。这之前,我们先理清他们每个人之间岁数的关系:

大家都看的出来吧,这就是一个等差数列而已,每一项与前一项相差 2。那么这里侦探的思想就大致如下:
- 求第5,我们需要求第4;
- 求第4,我们需要求第3;
- 求第3,我们需要求第2;
- 求第2,我们需要求第1;
- 第1是10岁;
- 第2是10+2 = 12岁;
- 第3是12+2 = 14岁;
- 第4是14+2 = 16岁;
- 第5是16+2 = 18岁;
不难看出,递归有一个往返的过程,我们往A1方向走,有了A1的结果了,我们再走回来。当我们理清了这个等差数列的关系以后,就可以很简单的写出以下递归:
int GuessAge(int n);
int main()
{
int age = GuessAge(5);
cout << "第5人的年龄是 " << age << endl;
system("pause");
return 0;
}
int GuessAge(int n)
{
if (n == 1)
{
return 10;
}
else
{
return GuessAge(--n) + 2;
}
}
上面这一个简单的递归,其实就已经结束了递归最根本的工作本质,特别注意这一句代码:
return GuessAge(--n) + 2;
每一次在这里调用递归,但是每次调用时,并没有立马执行 GuessAge(–n) + 2 ,而是 GuessAge(–n) 拿到了返回值以后,才会执行后面的+2。
综上所述,递归的需要一条使递归趋于结束的语句,这句话怎么理解呢,我们看下面的例子:
int GuessAge(int n)
{
if (n == 1)
{
return 10;
}
else
{
return GuessAge(--n) + 2;
}
}
这一个递归中,递归的结束条件是 n=1,趋于递归结束的语句当然是 GuessAge(–n) + 2 中的 --n。因为每次自减后n才会最终等于1.那么如果说我们把–n改成n:
int GuessAge(int n)
{
if (n == 1)
{
return 10;
}
else
{
return GuessAge(n) + 2;//区别在这里
}
}
当我们调用 GuessAge(5)时,这条函数则会一直调用 GuessAge(5)的一个循环,直到程序挂掉,也就是上面所提到的栈溢出。因为每调用一个函数都会开辟出一个新的空间,但是我们的栈空间是有限的,所以当持续调用持续开辟新的空间时,空间不够用以后,程序就会挂掉,这就是栈溢出。
所以,综上所述,递归的组成部分大致可以区分为以下三点:
- 递归起始条件(GuessAge(5));
- 使递归趋于结束的语句(GuessAge(–n));
- 递归终止条件(n == 1);
在这里就会有人发现了,这不就和循环语句非常的相似了吗!是的,基本上所有能用循环写出的语句,都可以用递归来实现。这里差不多对递归有了较为清晰的结构概念了,再写一道题:
猴子第一天摘下若干个,当即吃了一半,感觉没吃饱,于是又再吃了一个;第二天早上又将剩下的桃子吃掉了一般,随后又多吃了一个,以此类推,到第10天时,发现只剩下一个桃子了。求第一天摘了多少个桃子。
int GetSumOfPeach(int n);
int main()
{
int numOfPeachs = GetSumOfPeach(1);
cout << "桃子原本有 " << numOfPeachs << " 个" << endl;
system("pause");
return 0;
}
int GetSumOfPeach(int n)
{
if (n == 10)
{
return 1;
}
else
{
return (GetSumOfPeach(++n) + 1) * 2;
}
}
有了大概的感觉,就能总结出以下简单的递归结构:

4.4.3 递归求阶乘
int CinIN();
int Factorials(int n);
int main()
{
int result = Factorials(CinIN());
cout << result << endl;
system("pause");
return 0;
}
int Factorials(int n)
{
if (n == 0)
{
return 1;
}
else
{
return n*Factorials(n-1);
}
}
int CinIN()
{
cout << "请输入一个数:";
int num;
cin >> num;
return num;
}
之前说过,能用循环写的语句,基本都能用递归来实现。但是其实一般情况下,我们能用迭代(也就是循环)解决的问题,就不要用递归来解决了。原因就是递归的内存消耗大,容易导致栈溢出。
第五章 变量的作用域/生命周期/修饰符
5.1 作用域(Scope)
所谓鹰击长空,鱼翔浅底,万事万物都有一个限定的区域,鹰无法在水里飞,鱼也不i能在天上游。
5.1.1 变量之分
5.1.1.1 局部变量
凡是在 { } 以内的变量都是局部变量,也包括形式参数。如:
int Fun(int a, int b){
int a;
int b;
}
这样也是不行的.
局部变量未初始化的话,它的值是随机的,且有的编译器不通过。
5.1.1.1 全局变量
凡是在{}以外的变量都是全局变量。
#include 这样是可以的
另外,全局变量未初始化的话,那么它的值是固定的,是 0。
5.1.2 作用域概念
{ } 以内的称之为局部作用域,{ } 以外的称之为全局作用域。可以这么理解,我们先有了作用域的概念,然后才有了局部变量与全局变量的概念。同一个作用域内不能重复使用重名的变量,函数也是全局函数,在全局作用域里,函数也是不能重名的。可以总结为以下几点:
- { } 以内的作用域,称为局部作用域,主要包含的是变量;
- { } 以外的作用域,称为全局作用域,主要包含两类,一类是变量,二类是函数;
- 同一作用域内,不可以用重复的标识符。
- 其中,局部变量的作用域起始于定义处到所在的 { } 结束;全局变量的作用域起始于定义处,直到本文件结束。
- 在不同的作用域,可有重名的标识符,这时候就会出现作用域叠加,局部变量就会覆盖全局变量的作用域。
int a = 100;
int main()
{
int a = 10;
cout << a << endl;
system("pause");
return 0;
}
输出结果为:

- 更小的作用域:局部作用域内,可以直接添加 { } 进行划分,记住,只能划分局部作用域。
int a = 100;
int main()
{
int a = 10;
{
a = 15;
}
cout << a << endl;
system("pause");
return 0;
}

5.2 生命周期
5.2.1 局部变量的生命周期
在讨论局部变量的生命周期之前,我们要先了解函数的生命周期,函数的生命周期起于调用,结束于调用结束。那么在这个函数内的变量是局部变量,也是起于这个函数的调用,结束于函数的调用结束。
其中,**Main函数是一个例外,main函数的生命周期非常的长,main函数的生命周期起始于进程的开始,结束于进程的结束。**main函数中的局部变量的生命周期就可和main函数的生命周期一样长。
5.2.2 全局变量的生命周期
全局变量的生命周期也是起始于main函数的调用,结束于main函数的调用结束,也就是等于程序的生命周期。但是main函数里的局部变量和全局变量的作用域虽然不同,但是他们的生命周期是一样的。
5.3 修饰符(Storage Description)
修饰符据定了储存位置,从而可以改变生命周期,亦或是作用域。修饰符放在声明变量的类型之前,如下所示:

5.3.1 auto(大将军)
auto 只能用于修复局部变量,不可以用来修复全局变量。表示此变量存储于栈上。
- 储存于栈上的特点就是随用随开,用完消失。
- 默认的局部变量就是auto类型的,所以通常将其省略。
5.3.2 register(小太监)
只能修饰局部变量。由 register 修饰的变量都是存储在CPU上的。将内存中的变量升级到CPU的寄存器当中,原因是因为CPU计算速度更快。但是由于寄存器的数量相当有限,我们不能把所有的变量都放到寄存器且通常被优化。适用于频繁使用的变量。但是多数情况下不用,因为太容易被优化了。
5.3.3 extern(通关文牒)
给全局变量使用的修饰符。用于跨文件来使用一个全局变量。原因是我们的文件是单文件编译,需要链接其他文件里的声明才能使用。当然在同一个文件里的全局变量也可以提供链接。
定义与声明:
int a = 100; // 一定是定义
int a;// 不一定是声明
5.3.4 Static
5.3.4.1 修饰局部变量时:
可修饰局部变量也可以修饰全局变量:
- 修饰局部变量时,默认初始化为0,当局部变量不使用static时,变量存储在栈上,随用随开,用完消失;当使用了static时,变量存储在Data数据段。时生命周期等同于进程,也等于main的生命周期。便且static变量的初始化只执行一次,
- 例子如下:
int main()
{
for (int i = 0; i < 8; i++)
{
StaticFun();
}
system("pause");
return 0;
}
void StaticFun()
{
int a = 0;
cout << " a = " << a++;
static int b = 0;
cout << " b = " << b++ << endl;
cout << "*****************" << endl;
}
输出如下:

平时我们都怎么用static呢:
int main()
{
PrintData(1001,'X', 53.2 );
PrintData(888, 'X', 40.5);
PrintData(95526, 'X', 90.43);
PrintData(888, 'X', 74.3);
PrintData(1001, 'X', 63.2);
PrintData(95526, 'X', 20.4);
PrintData(888, 'X', 55.6);
system("pause");
return 0;
}
void PrintData(int carNum, char date, float weight)
{
static int count_1001 = 1;
static int count_888 = 1;
static int count_95526 = 1;
static float weightSum_1001 = 0;
static float weightSum_888 = 0;
static float weightSum_95526 = 0;
static int flag = 1;
if (flag == 1)
{
cout << "车牌\t日期\t吨位\t总趟数\t总吨位" << endl;
flag = 0;
}
if (carNum == 1001)
{
weightSum_1001 += weight;
cout << carNum << "\t" << date << "\t" << weight << "\t" << count_1001++ << "\t" << weightSum_1001 << endl;
}
else if (carNum == 888)
{
weightSum_888 += weight;
cout << carNum << "\t" << date << "\t" << weight << "\t" << count_888++ << "\t" << weightSum_888 << endl;
}
else if (carNum == 95526)
{
weightSum_95526 += weight;
cout << carNum << "\t" << date << "\t" << weight << "\t" << count_95526++ << "\t" << weightSum_95526 << endl;
我们可以依靠他储存位置的生命周期,也就是data数据段的生命周期,来进行输出控制以及数据的存储和运算,或是记录控制某条函数的调用次数。
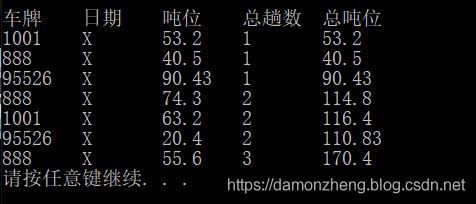
- 还有一大用处就是,用来加载资源,游戏中非常常见!!!游戏初始化之后加载游戏资源!
5.3.4.4 修饰全局变量时:
人们之所以使用全局变量,是因为它全局可用,避免传参的麻烦,一个全局变量天生拥有外延性,可以被其他文件所使用,但因为因此带来了命名污染这一问题。这时候我们就可以使用static了。使用static来封锁住外延性,将其变成本文件的全局变量,将无法再被extern到其他外文件去。当然,规则同样适用于函数。
- 因此,static并没有改变全局变量的存储位置,因为全局变量也是存储于Data段的,static只改变了全局变量的作用域。
第六章 String
6.1 引入
以下是一个进程空间的示意图
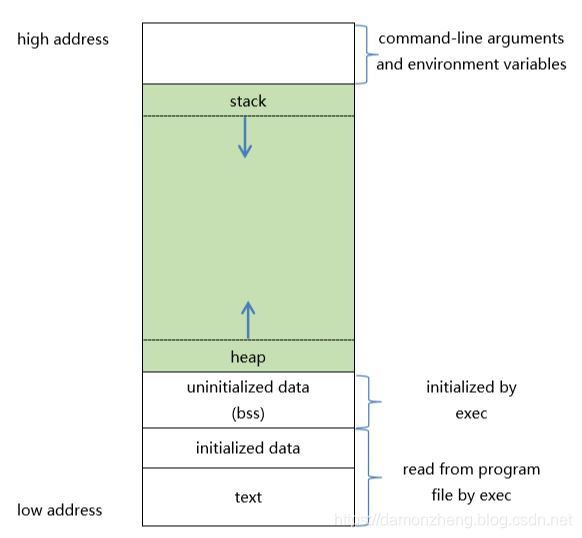
string 也是存储在进程中的data段。
我们先回顾以下C中关于字符串的使用。
int main()
{
cout << " size of string \"zheng\" = " << sizeof("zheng") << endl;
system("pause");
return 0;
}
我们得到的输出是:
![]()
明明只有5个char,怎么会输出6呢?因为默认会在字符常量末尾加一个空格,“ \0 ”。
C在处理字符串时,将其处理成了一个指向data段里这个字符串的首地址。
本质就是一个const char类型的指针,它有类型,有步长,也因为字符串会被系统自动添加一个\0,所以也时有步长的。所以这个\0真的太重要了。string的本质也是读到\0就停止读取,所以,要记住在声明定义时,要记住不要把\0给弄丢了,有\0才是字符串,不然就只是字符数组而已。

6.2 字符串的输入与输出
- fgets(arr,10,stdin) 这个函数的是指,在键盘读入9个字符存储到arr中包括空格字符。
6.3 字符串操作函数
接下来要学习的就是字符串的数据组织形态。将对字符串的处理转化为对字符数组或是字符指针的处理。
6.3.1 字符数组原生函数操作
当字符串被放到字符数组以后,且等价条件成立后(字符数组的长度大于等于字符串的长度),我们就可以通过字符数组名来操作字符串,包括求长度,拷贝,追加等操作。
6.3.1.1 求字符串的长度
字符串的长度和大小是两个不同的概念,比如,长度一般不包括 ‘ \0 ’,
const char * p = "China";
const char * q = p;
int count = 0;
while (*q++)
{
count++;
}
cout << "长度为 " << count << endl;
可以写的再高级一丢丢,我们知道while()里写的是循环结束判断条件,所以更高级的写法如下:
for (count; *q++; count++);
cout << "长度为 " << count << endl;
棒否???
或者,在包含了string头文件以后,我们可以直接用 strlen() 函数来直接求其长度。
const char * p = "China";
int len = strlen(p);
cout << "strlen的长度为 " << len << endl;
6.3.1.2 链接字符串
被链接的串必须要有足够的空间
int main()
{
char firstName[30] = "Shaojie";
char lastName[30] = "Zheng";
P_LinkStr(firstName, lastName);
cout << firstName << endl;
system("pause");
return 0;
}
void P_LinkStr(char * arr03, char * arr04)
{
while (*arr03) arr03++;
while (*arr03++ = *arr04++);
}
但是如果我们需要取层层套用,链式表达的话,我们需返回char * 类型就好了:
int main()
{
char arr[30] = "China";
char arr01[30] = "Always";
char arr02[30] = "Number1";
MyLinkStr(MyLinkStr(arr, arr01), arr02);
cout << arr << endl;
system("pause");
return 0;
}
char * MyLinkStr(char * p, char * q)
{
char * d = p;
while (*p) p++;
while ((*p++ = *q++));
return d;
}
6.3.2.2 拷贝
在string库函数里,我们用strcpy_s来实现,但是必须有足够的空间来容纳:
char fullName[30];
char firstName[30] = "Shaojie", lastName[30] = "Zheng";
MyLinkStr(firstName, lastName);
strcpy_s(fullName, firstName);
cout << firstName << endl;
6.3.2.3 匹配
库函数使用 strcmp 来比较,依次比较ASCII码的字母数值大小。
- 若相等,返回0;( 返回 0)
- 若大于,返回1;(返回一个大于0的数)
- 若小于,返回-1;(返回一个小于0的数)
接下来将用一个客户登录的例子来复写一遍strcmp:
int main()
{
char myName[30] = "szhe139", myPasswd[30] = "wl1314520";
LogInSvs(myName, myPasswd);
system("pause");
return 0;
}
void LogInSvs(char * myName, char * myPasswd)
{
char name[50] = { 0 };
char passwd[50] = { 0 };
int count = 3;;
while (1)
{
cout << "===========================================" << endl;
cout << "您还可以输入 " << count << " 次。" << endl;
cout << "请输入用户名:";
cin >> name;
cout << "请输入密码:";
cin >> passwd;
if (strcmp(myName, name)==0 && strcmp(myPasswd, passwd)==0)
{
break;
} else
{
if ((--count) == 0)
{
break;
}
}
}
if (count)
{
cout << "登入成功。" << endl;
} else
{
cout << "超过次数,稍后再试。" << endl;
}
}
接下来开始试着去自己写strcmp:
int MyStrcmp(char * p, char * d)
{
for( ; *p && *d ;p++,d++)
{
if (*p != *d)
{
break;
}
}
return *p - *d;
}
这里就只是返回一个数,这个数要么大于0,要么小于0,要么等于0。一步步优化下来就是这样的,但是实际上还可以优化,就是下面这样:
int MyStrcmp(char * p, char * d)
{
for( ; *p && *d && (*p==*d) ;p++,d++);
return *p - *d;
}
棒否?????

说实话后面写到这一步我有点被吓到了。。。突然就懂了为什么有时候看不懂别人写的代码,原因可能就是我并没有把对方的逻辑梳理透彻吧。但是其实并不太建议写道这个地步,因为压根没必要,除了看起来很吊以外,更难的是未来的优化会异常的让人费劲。
6.4 多文件编程
- 把一类功能的函数写到一个xxx.cpp里面。(实现)
- 把xxx.cpp中的所有函数声明写到xxx.h中。(声明)
- 在xxx.h中加入避免头文件重复的语句。(把 1 做成库)
#ifndef __STRFUNCTION_H__
#define __STRFUNCTION_H__
void P_LinkStr(char * arr01, char * arr02);
int P_StrLength(char * arr);
int P_MyStrcmp(char * p, char * d);
void Cout_Strcmp(char * p, char* d);
#endif
- 将xxx.h 包含到 xxx.cpp 中(自包含)。
- 在main函数包含 xxx.h(谁用谁包含)。
如果完成上述操作以后,vs提示说无法打开源文件,记得在main的项目属性里,附加包含目录,把头文件的路径赋值进去就好了。
6.5 指针数组
指针数组的本质是数组,数组指针的本质是指针。
6.5.1 定义
一个数组中的各个元素都是指针,我们称该数组为字符指针数组,或是指针数组。
- 整型指针数组
int a, b, c, d;
int * arr_int[] = { &a,&b,&c,&d };
- 字符指针数组
char aa, bb, cc, dd;
char* ptArr[] = { &aa,&bb,&cc,&dd };
-以下的字符指针数组是一样的
const char *pa = "shaojie", *pd = "always", *pc = "number1";
const char * dtArr[] = { pa,pd,pc };
const char * dtArr2[] = { "shaojie","always","number1" };
6.5.2 指针数组排序
有序输出china,ameria,japan,canada:
int main()
{
const char * bookArr[4] = { "china","ameria","canada","japan" };
int ln = sizeof(bookArr) / sizeof(bookArr[0]);
for (int i = 0; i < ln-1; i++)
{
int idx = i;
for (int j = i + 1; j < ln; j++)
{
if (strcmp(bookArr[j],bookArr[idx])==-1)
{
idx = j;
}
}
if (idx != i)
{
const char* temp = bookArr[i];
bookArr[i] = bookArr[idx];
bookArr[idx] = temp;
}
}
for (int i = 0; i < 4; i++)
{
cout << bookArr[i] << endl;
}
system("pause");
return 0;
}
}
得到的输出如下:

6.5.2.1 arge,argv[ ]
- 在启动进程时,通过命令行,传递给进程的参数,即传递main的参数
- arg = agrument, 参数, c = count 个数,argc = 参数的个数
- arg = 指针数组,v = vector 向量, argv = 指针数组向量
第七章 内存管理
7.1 进程管理 (Memory)
7.1.1 进程 vs 程序
- 源程序就是源代码。
- 程序就是可执行性文件,是源代码经过编译形成的可执行文件。
- 进程 可以理解为是一个时间概念,一个可执行性文件被拉起调用,到结束的这样一段的过程被称为进程。我们的程序只有一个,但是我们的进程可以有多个,例如我们可以同时打开多个office应用。
- **进程空间是可执行性文件被拉起以后,在内存中的分布情况。**不管哪一个进程被拉起,总要在内存中占据一定的空间。
进程空间的示意图如下:
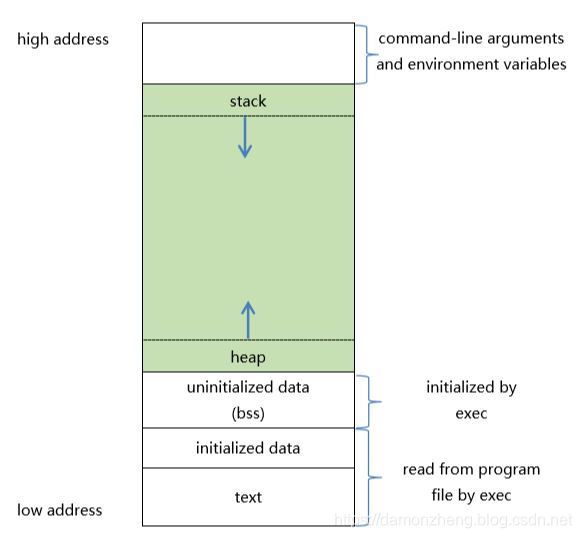
- text: 代码段
- uninitialized data:data段
- initialized data:data段
- heap:堆段
- stack:栈段
在32位 系统中,一个进程被加载到内存中的大小是 4GB。

一个进程4个G是没有问题的,理论上也确实是这样的。但是有时我们的进程并没有用到4个G,可执行文件大概二十kb作用用完以后,我们的stack空间不是一下全被占用的,比如我们一个程序有时候就一个整型数据,那么这整个进程被映射到真实物理空间的大小就这么几十个KB,剩下的内存空间我们又可以开其他的进程。
7.2 栈内存(stack)
7.2.1 栈内存的内容。
栈中存放的类型是任意类型的变量,但必须是auto类修饰的变量,即自动类型的局部变量。
7.2.2 栈储存的特点
随用随开,用完既消(压栈出栈)。内存的分配和销毁是系统自动完成的,不需要人工干预。
7.2.3 栈空间
栈的大小并不大,它的意义不在于大空间的申请储存数据,而在于交换数据。
- 栈溢出:“ 这人喝醉了 ”,酒量不是很大。
7.2.3.1 栈的发展方向
先定义变量高地址位在上,自上而下开辟空间。
7.2.4 堆内存(heap)
也可以存储各类型的数据,但是需要自己主动申请与释放。用于大空间的申请储存空间。
7.2.4.1 堆大小
想象中的无穷大,对于栈空间来说,大空间申请,无它耳。先定义变量在低地址位,自下往上开辟空间。
7.2.4.2 malloc()
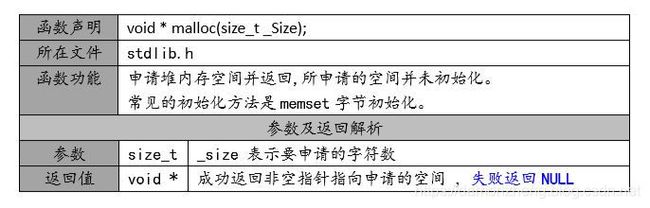
以字节为单位进行申请的。
- 基础数据类型:
char * p = (char*)malloc(1024 * 1024 * 1024);
if (p)
{
cout << "申请成功" << endl;
} else
{
cout << "申请不成功" << endl;
}
free(p);
若分配成功则返回指向被分配内存的指针,否则返回NULL。释放用free()来释放。
- 数组类型:
int * p = (int*)malloc(10 * sizeof(int));//我需要40平米的房子
memset(p,0, 10*sizeof(int));
for (int i = 0; i < 10; i++)
{
cout << p[i] << endl;
}
free(p);
memset()是初始化申请的这个堆内存。
7.2.4.3 calloc()

int * p = (int*)calloc(10, sizeof(int));//我需要10个房间,每个房间4平米
for (int i = 0; i < 10; i++)
{
cout << p[i] << endl;
}
free(p);
相当于自带memset()功能。
7.2.4.4 ralloc()

7.2.4.5 free()

7.2.4 常见错误操作
说是错位操作,不如说是使用规范。
7.2.4.1 未配对使用malloc与free
malloc 与 free 必须配套使用,否则:
- malloc > free,必然造成内存泄漏
- malloc < free, 会造成 double free,程序挂掉。
7.2.4.2 置空与判断
堆内存使用的逻辑尽量严格按照 申请,判空,使用,释放,置空的逻辑来使用。
//申请
int * p = (int*)malloc(10 * sizeof(int));
//判空
if (NULL == p)
{
cout << "erro" << endl;
exit(-1);
}
//使用:
for (int i = 0; i < 10; i++)
{
p[i] = 100 + i;
cout << p[i] << endl;
}
//释放
free(p);
//置空
p = NULL;
7.2.4.1 谁申请,谁释放(并非绝对)
目的就是为了避免多次释放
void DoubleFree(int* p)
{
p[0] = 100;
free(p);
}
int main()
{
int * p = (int*)malloc(10 * sizeof(int));
if (NULL == p)
{
cout << "erro" << endl;
exit(-1);
}
DoubleFree(p);
free(p);
p = NULL;
system("pause");
return 0;
}
如上所示,我们在DoubleFree里free了p,然后再main里也free了p,这时就触发了double free,程序直接挂掉。所以为了防止这种情况,我们规范在哪里申请的内存,就在哪里释放,这里我们就应该在main里释放。
7.2.4 应用模型
7.2.4.1 动态数组
7.2.4.1.1 VAL
int * p;
cout << "输入需要的数组长:";
int len;
cin >> len;
p = (int*)malloc(sizeof(int)*len);
for (int i = 0; i < len; i++)
{
p[i] = 100 + i;
cout << p[i] << endl;
}
int oldLen = len;
cout << "输入更长的数组长:";
cin >> len;
p = (int*)realloc(p, sizeof(int)*len);
for (int i = 0; i < len; i++)
{
if ( i >= oldLen)
{
p[i] = 200 + i;
}
cout << p[i] << endl;
}
free(p);
7.3 堆与栈空间的返回
7.3.1 栈空间不可以返回
有的平台不报错,但是确实是不可以返回的
7.3.2 堆空间可以返回
第八章 结构体(Struct)
从某种意义上来说,会不会用 Struct,怎么使用 Struct 是区别一个开发人员是否具备丰富开发经验的重要标志,
8.1 引例
问题: 储存一个班级中四名学生的信息(学号,姓名,性别,成绩);
- 方案一: 分别建立四个数组,int num[4]; string name[4];char sex[4];float score[4]
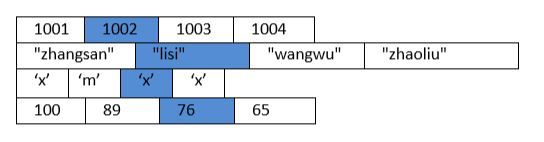
这样是可以实现的,但是要建立数组与数组之间的关联比较麻烦。 - 方案二: 建立一个二维数组

想法很好,但是二维数组无法实现,因为数组中的元素要求类型一致。 - **方案三:**方案二的思想很好,但是由于二维数组的元素类型要求限制了它的可行性。但是如果我们把其中的每一行看成一个新的整体的话,那就是一个一维数组了。同样满足了每个元素都是同一类型的话。

二维数组,是数组中每个元素又是一维数组,一维数组是一种构造类型,上表格 其实也是一种二维的结构,只不过,二维中嵌套的不是一维数组这种构造类型,而是 构造体这种构造类型而己
8.2 为什么引入结构体
8.2.1 开放类型定义
我们先有了基本类型,当我们需要把一堆相同的基本类型变量放在一起时,我们有了数组。大师当我们需要把一堆不同类型的变量放在一起时,无计可施的C++这时候就放开了自定义权限,struct就出现了,从而拥有了基本上所有的自定义类型。
8.2.3 从单变量 》 数组 》 结构体
从描述一个人的年龄,到描述一堆人的年龄,再到描述一个人的状态。
//一个人的年龄
int age;
//一堆人的年龄
int ages[5];
//一个人的状态
char name[10];
int id;
char sex;
int age;
当我们处理不同类型的成员时,我们不论是 维护也好,处理也好,使用也好,都很麻烦。所以我们就需要结构体来帮忙。
struct {
char name[10];
int id;
char sex;
int age;
};
8.3 结构体的定义
- 无名结构体
struct {
char name[10];
int id;
char sex;
int age;
}a1,a2,a3,a4;
一般而言用于,定义类型的同时,定义变量;并且不会带来多余的命名。
- 给结构体取个名字:有名结构体
struct stu
{
char name[10];
int id;
char sex;
int age;
};
struct stu s1;
struct stu s2;
一处定义,随处使用,很方便。
现在我们再回头看之前的引例:
struct student
{
int num;
string name;
char sex;
float score;
};
int main(int argc, char * argv[])
{
struct student students[4] = {
{ 001,"Damon",'M',100.0},
{ 002,"Giraffe",'M',100.0 },
{ 003,"Eric",'M',100.0 },
{ 004,"Raymond",'M',100.0 },
};
system("pause");
return 0;
}
- 别名构造体类型(typedef)
更好的使用结构体, 主要对现有类型取别名,不能创造新的类型。
typedef char m_int8;
typedef short m_int16;
typedef int m_int32;
typedef long long m_int64;
int main(int argc, char* argv[])
{
m_int8 i8;
m_int16 i16;
m_int32 i32;
m_int64 i64;
system("pause");
return 0;
}
我们可以对基本类型取别名,当然了,我们也可以对构造函数取别名
typedef int ARRY[10];
int main(int argc, char* argv[])
{
int arr[10];
cout << "sizeof arr[10] = " << sizeof(arr) << endl;
ARRY arr02;
cout << "sizeof arr02 = " << sizeof(arr02) << endl;
system("pause");
return 0;
}
输出:

使用方法总结:
1.先用原类型定义变量;
2. 在定义前加typedef
3. 将原变量的名字改成你需要改的名字。
方法同样适用于结构体:且是常用于给结构体取名字的方式,当然是为了让我们更好的使用结构体。
typedef struct students
{
int num;
string name;
char sex;
float score;
} STU;
int main(int argc, char * argv[])
{
STU students1;
STU students2;
system("pause");
return 0;
}
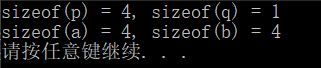
值得注意的是指针被typedef以后的使用区别:
typedef char *cpt;
int main(int argc, char *argv[])
{
char *p, q;
printf("sizeof(p) = %d, sizeof(q) = %d\n", sizeof(p), sizeof(q));
cpt a, b;
printf("sizeof(a) = %d, sizeof(b) = %d\n", sizeof(a), sizeof(b));
system("pause");
return 0;
}
输出如下:
- typedef 是C语言语句,是要参与编译的;
- #define 是一个宏,在预处理阶段就处理完毕。
再看看宏定义的:
typedef char *cpt;
int main(int argc, char *argv[])
{
char *p, q;
printf("sizeof(p) = %d, sizeof(q) = %d\n", sizeof(p), sizeof(q));
cpt a, b;
printf("sizeof(a) = %d, sizeof(b) = %d\n", sizeof(a), sizeof(b));
#define Dcptr char *
Dcptr s, d;
printf("sizeof(s) = %d, sizeof(d) = %d\n", sizeof(s), sizeof(d));
输出如下:

可以发现宏定义的输出与一开始的是一样的,原因不难探求,其实就是把char*换成了Dcptr。
8.4 结构体变量的初始化及成员访问
- 基本类型,既可以在定义的时候初始化,也可以先定义再赋值。
- 构造类型 要么在定义的时候初始化,不可以先定义再以初始化的方式赋值。
结构体的赋值可以通过点乘运算符来完成,因为结构体中的成员类型是不一样的,所所以将无法再通过下标来进行访问。
STU s1 = { 111,"Damon",'M',100.0 };
strcpy_s(s1.name, "shaojie zheng");
我们也可以从键盘来读入输入:
STU s2;
cout << "请输入学生姓名: ";
cin >> s2.name;
8.4.2 访问
像之前说的,我们可以通过点乘运算符来访问
strcpy_s(s1.name, "shaojie zheng");
我们也可以声明一个指针指向这个结构体,让后通过指向成员运算符来进行访问:
STU * pt_s3 = &s3;
strcpy_s(pt_s3->name,"Shaojie Zheng");
一共分为两类访问,一是访问栈上的,二是访问堆上的。
-
访问栈上的:
如上都是访问栈上的。 -
访问堆上的:
一定要记得 free();
int main(int argc, char* argv[])
{
STU * ptr_s4 = (STU*)malloc(sizeof(STU));
strcpy_s(ptr_s4->name, "WangLan");
ptr_s4->num = 11001;
ptr_s4->score = 100.0;
ptr_s4->sex = 'F';
cout << "学生学号:" << ptr_s4->num << "\n学生姓名:" << ptr_s4->name << "\n学生性别:" << ptr_s4->sex << "\n期末成绩:" << ptr_s4->score << endl;
free(ptr_s4);
system("pause");
return 0;
}
8.5 结构体的传参与赋值。
相同结构体的变量间是可以赋值的,不同类型之间则不可以。这种语法基础可以用于传参和返值。
- 传参和返值的本质就是赋值。
typedef struct _Complex {
float real;
float image;
} COMPLEX;
void ShowStruct(STU* ptr);
COMPLEX AddComplex(COMPLEX c1, COMPLEX c2);
//结构体同类可相互赋值的特性可以用于传参与返值
int main(int argc, char * argv[])
{
COMPLEX c1 = { 1,2 };
COMPLEX c2 = { 3,4 };
COMPLEX c3 = AddComplex(c1, c2);
cout << c3.real << " " << c3.image << endl;
system("pause");
return 0;
}
COMPLEX AddComplex(COMPLEX c1, COMPLEX c2)
{
COMPLEX c3;
c3.image = c1.image + c2.image;
c3.real = c1.real + c2.real;
return c3;
}
之前在学习数组的时候,我们是使用传地址的方式的。对于结构体,我们也推荐传指针。不管一个结构体或是数组里面有多少数据,我们都只需要穿4个字节的地址就行了,大大的节省了性能。
8.6 结构体数组及其应用
二维数组的本质就是一个一维数组,但是数组中的每个成员又是一个一维数组。结构体数组一样,其本质也是一个一维数组,只不过数组中的每个成员又是一个结构体。
int main(int argc, char * argv)
{
STU stus[4] = { { 111,"Damon",'M',100.0 },{ 110,"WangLan",'F',100.0 },
{ 101,"DianDian",'M',100.0 },{ } };
for (int i = 0; i < (sizeof(stus) / sizeof(*stus)); i++)
{
STU* ptr_s = &stus[i];
ShowStruct(ptr_s);
}
system("pause");
return 0;
}
8.6.2 实战
- 现有三位候选人员,候选人包括名字和选票数两项,现在10人对其投票,每个人限投票一次,投票完毕后打印投票结果。
typedef struct _Candidate {
char name[1024];
int voteCount;
} CAN;
void Winner(CAN * cans, int n, int k);
void VoteSys(CAN* cans, int numOfCount, int numOfCandidate);
//8.6.2 投票程序编写
int main(int argc, char* argv[])
{
CAN cans[3] = {
{ "ShaojieZheng",0 },
{ "WangLan",0 },
{ "Diandian",0 },
};
VoteSys(cans, 10,3);
system("pause");
return 0;
}
void VoteSys(CAN* cans, int numOfCount,int numOfCandidate)
{
char cinName[1024];
int count = 0;
int invaliVoted = 0;
for (int i = 0; i < numOfCount; i++)
{
int flag = 0;
cout << "请输入您对其投票的姓名:";
cin >> cinName;
cout << endl;
for (int j = 0; j < 3; j++)
{
if (!strcmp(cinName, cans[j].name))
{
cans[j].voteCount++;
flag = 1;
}
}
if (!flag)
{
invaliVoted++;
}
}
Winner(cans, 3, invaliVoted);
}
void Winner(CAN * cans,int n,int k)
{
int idx = 0;
for (int i = 1; i < n; i++)
{
if (cans[i].voteCount >= cans[idx].voteCount)
{
idx = i;
}
}
cout << "恭喜 " << cans[idx].name << "获得 " << cans[idx].voteCount
<< " 票, 胜出!另外,弃权票有 " << k << " 票。" << endl;
}
8.7 结构体嵌套与结构体大小
- 结构体支持赋值。
- 在学习数组时,我们知道数组名时数组的唯一标识符,且1是一个常量,所以不能直接进行拷贝操作。但是当我们把一个数组放进结构体里面时,却可以直接进行拷贝赋值:
typedef struct _Array {
int nums[10];
} ARRAY;
//8.7 结构体嵌套与大小
int main(int argc, char* argv[])
{
ARRAY arr = { 1,2,3,4,5,6,7,8,9,10 };
ARRAY arr02;
arr02 = arr;
cout << arr02.nums[0] << endl;
system("pause");
return 0;
- 结构体中可以嵌套结构体
int main(int argc, char * argv[])
{
BIRTH b1 = { 1996,12,18 };
PERSON p1 = { "Damon",23,'M',100,b1 };
cout << p1.birth.year << endl;
system("pause");
return 0;
}
8.7.2 结构体类型的大小
结构体本身是不占有内存空间的,只有当它生成了变量时,变量才占有内存空间。就好比你只声明了一个int
int
此时这个int时不占据空间的,占据空间的时int a:
int a;
再来看看结构体类型的大小:
typedef struct _Staff {
char car;
int num;
} STAFF;
// 8.7.2 结构体类型的大小
int main(int argc, char * argv[])
{
STAFF s1 = { 'D',1 };
printf("size of s1 = %d \t%p\n", sizeof(s1), &s1);
printf("size of s1.car = %d\t%p\n", sizeof(s1.car), &s1.car);
printf("size of s1.num = %d\t%p\n", sizeof(s1.num), &s1.num);
system("pause");
return 0;
}
得到的输出如下:

我们看到的输出很奇怪,明明4+1应该等于5的,怎么s1大小是8呢,不妨画个表看一下:

以上输出我们大可如上来表示,这里可以看到,s1.car后面还预留了3个字节并没有使用。这时候偶我们在结构体的后面加上一个short类型:
typedef struct _Staff {
char car;
int num;
short age;
} STAFF;
// 8.7.2 结构体类型的大小
int main(int argc, char * argv[])
{
STAFF s1 = { 'D',1 };
printf("size of s1 = %d \t%p\n", sizeof(s1), &s1);
printf("size of s1.car = %d\t%p\n", sizeof(s1.car), &s1.car);
printf("size of s1.num = %d\t%p\n", sizeof(s1.num), &s1.num);
system("pause");
return 0;
}
此时输出如下:

此时的表格应是如下:

再来看第三种情况:
typedef struct _Staff {
char car;
short age;
int num;
} STAFF;
// 8.7.2 结构体类型的大小
int main(int argc, char * argv[])
{
STAFF s1 = { 'D',1 ,20};
printf("size of s1 = %d \t%p\n", sizeof(s1), &s1);
printf("size of s1.car = %d\t%p\n", sizeof(s1.car), &s1.car);
printf("size of s1.age = %d\t%p\n", sizeof(s1.age), &s1.age);
printf("size of s1.num = %d\t%p\n", sizeof(s1.num), &s1.num);
system("pause");
return 0;
}
得到的输出如下:
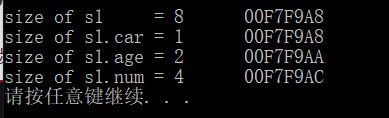
表格示意如下:

再看最后一种:
#pragma pack(1)
typedef struct _Staff {
char car;
short age;
int num;
} STAFF;
// 8.7.2 结构体类型的大小
int main(int argc, char * argv[])
{
STAFF s1 = { 'D',1 ,20};
printf("size of s1 = %d \t%p\n", sizeof(s1), &s1);
printf("size of s1.car = %d\t%p\n", sizeof(s1.car), &s1.car);
printf("size of s1.age = %d\t%p\n", sizeof(s1.age), &s1.age);
printf("size of s1.num = %d\t%p\n", sizeof(s1.num), &s1.num);
system("pause");
return 0;
}
输出如下:
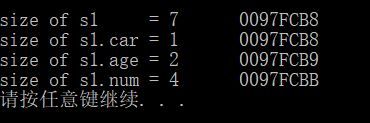
表格如下:

8.7.4.1 内存不对齐与内存对齐
当我们要去读一个成员,造成需要花费多个机器周期的现象,就是内存不对其。那我们为什么要内存对齐呢,本质就是牺牲空间换取时间。
8.7.4.2 内存对齐规则
x86(linux 默认#pragma pack(4), window 默认#pragma pack(8))。linux 最大支持 4 字节对齐。
- ①取 pack(n)的值(n= 1 2 4 8–),取结构体中类型最大值 m。两者取小即为外对齐大 小 Y= (m
- ②将每一个结构体的成员大小与 Y比较取小者为 X,作为内对齐大小.
- ③所谓按 X 对齐,即为地址(设起始地址为 0)能被 X整除的地方开始存放数据。
- ④外部对齐原则是依据 Y 的值(Y 的最小整数倍),进行补空操作。
我们的内对其是为了进行节省机器周期,那外对其是为了什么呢?这是为了,哪怕在进行结构体数组操作时,也是保证都内存都是对其的。
8.8 结构体的使用注意事项
- 在结构体中使用指针时,记得从堆中申请空间来初始化指针成员,并且在申请空间时,我们应由外围向内围申请,释放时由内围向外围释放:
typedef struct _Caution {
char * name;
int num;
} CAUTION;
// 8.8 结构的使用注意事项
int main(int argc, char * argv[])
{
CAUTION * c1 = (CAUTION *)malloc(sizeof(CAUTION));
c1->name = (char *)malloc(100);
free(c1->name);
free(c1);
system("pause");
return 0;
}
8.9 实战
8.9.1 栈的自实现
栈的典型特点就是先进后出(FILO),或是后进先出(LIFO),和我们坐电梯一样,先进的人后出来,后进的人先出来,也和我们小时候玩叠罗汉的思想是一样的。主要接口操作,主要有 四类,分别是,判空,判满,压栈,出栈。
大致逻辑可以分为余下几个步骤(假设只能压入8个数据):
- top == 0,不能继续出栈,一斤到栈底;
- top == 8,不能继续压栈,已到栈顶
- top始终指向一个待插入的位置
- push操作:1.写入数据; 2. top++(栈非满)
- pop操作:1.top–;2.弹出数据。(栈非空)`
梳理完业务逻辑,我们就可以开始敲代码了。记住敲代码前一定要梳理业务逻辑,梳理清楚了,代码很容易就会敲出来,哪怕出错,也很容易去调试去修正。
typedef struct _Stack {
char mem[1024];
int top;
}STACK;
int IfFull(STACK* s);
int IfEmpty(STACK* s);
void Push(STACK* s, char ch);
char Pop(STACK* s);
// 8.9 自定义栈的实现
int main(int argc, char* argv[])
{
STACK s = { {0},0 };
for (char ch = 'a'; ch <= 'z'; ch++)
{
if (IfFull(&s))
{
Push(&s,ch);
}
}
while (IfEmpty(&s))
{
putchar(Pop(&s));
putchar(0);
}
putchar(10);
system("pause");
return 0;
}
int IfFull(STACK* s)
{
return s->top - 1024;
}
int IfEmpty(STACK* s)
{
return s->top - 0;
}
void Push(STACK* s,char ch)
{
s->mem[s->top++] = ch;
}
char Pop(STACK* s)
{
return s->mem[--s->top];
}
输出结果如下:

8.9 类型总结
学到这里,是否对类型有了一定的了解了呢,那么,类型到底是什么东西,有什么意义呢?
类型是以字节为单位进行线性编址的硬件基础,类型就是对内容的格式化。
第九章 共用(Union)于枚举(Enum)
9.1 共用体
不同的成员使用共同的存储区域的数据构造类型称为共用体,简称共用, 又称联合体。共用体在定义、说明和使用形式上与结构体相似。两者本质上的不同仅在于 使用内存的方式上。
9.1.1 类型定义与变量定义
- 定义形式
union 共用体名
{
成员列表;
}
共用体和结构体又有什么区别呢:
大小:
- 对于结构体而言,如果不考虑内存对齐的话,它的大小就是所有元素大小之和,每个元素都有属于自己内存空间。
- 对于共用体而言,其大小就是最大元素所占用的空间大小。
成员地址:
-对于结构体而言,每个成员都有一个自己独立的地址。
- 对于共用体而言,所有成员都共用一个地址。
9.1.2 共用体的应用
设有若干个人员的数据,其中有学生和老师。学生的数据包括:姓名,编号,性 别,职业,年级。老师的数据包括:姓名,编号,性别,职业,职务。可以看出,学 生和老师所包含的数据是不同的。先要求把他们放在同一个表格中:

要求设计程序输入人员信息然后输出。 如果把每个人都看作一个结构体变量的话,可以看出老师和学生的前 4 个成员变 量是一样的,并且第五个成员变量可能是 grade 或者 position,当第四个成员变量是 s 的时候,第五个成员变量就是 grade;当第四个成员变量是 t 的时候,第五个成员变 量就是 position。
typedef union GorP {
float grades;
char position;
} GORP;
typedef struct Staff {
char name;
char job;
GORP gorp;
} STAFF;
//9.1.2 共用体的应用
int main(int argc, char * argv[])
{
STAFF s[2];
for (int i = 0; i < 2; i++)
{
printf("请输入姓名:");
scanf_s("%c", &(s[i].name));
getchar();
printf("请输入职业:");
scanf_s("%c", &(s[i].job));
getchar();
if (s[i].job == 's')
{
printf("grade:");
scanf_s("%f", &(s[i].gorp.grades));
} else
{
printf("position:");
scanf_s("%c", &(s[i].gorp.position));
}
getchar();
}
putchar(10);
for (int i = 0; i < 2; i++)
{
cout << s[i].name << endl;
cout << s[i].job << endl;
if (s[i].job == 's')
{
cout << s[i].gorp.grades << endl;
}
else
{
cout << s[i].gorp.position << endl;
}
}
system("pause");
return 0;
}
- 测试大端序或是小端序:
typedef union UnionTest {
char ch;
int num;
}UT ;
//
int main03(int argc, char * argv[])
{
UT test = { 0X123456 };
if (test.ch == 0X12)
{
cout << "大端序" << endl;
} else
{
cout << " 小端序" << endl;
}
system("pause");
return 0;
}
9.2 枚举(Enum)
枚举类型定义了一组整型常量的集合,目的是提高程序的可读性。语法方面,与结构体相同。
enum 枚举类型
{
变量列表;
};
enum Day {
MON, TUS, WED, THU, FRI, SAT, SUN //提供一组可选的常量,0,1,2,3,4,5,6
};
typedef union UnionTest {
char ch;
int num;
}UT ;
enum Day {
MON = 1 , TUS, WED, THU, FRI=99, SAT, SUN //提供一组可选的常量,0,1,2,3,4,5,6
};
//9.2 枚举类型 Enum
int main(int argc, char* argv[])
{
cout << TUS << endl;
cout << SAT << endl;
enum Day day = MON;
system("pause");
return 0;
}
第十章 单向链表
单项链表形象的比喻起来,就是一个托马斯!!!

车头就是一个领头人开车的作用。每一节车厢不仅要拉后面的车厢,还需要载客。
10.1 链表的价值
有在没有链表之前,我们使用的是数组。但是数组有一个特点就是,申请空间的时候,空间必须是连续的,当我们定义的空间不够用时,我们就会其malloc更多的空间。malloc空间也有一个entire,就是会先在定义的数组后面尝试申请,如果有足够的空间,那么就会跟在数组后面直接申请;如果空间不够,就会把整个数组重新移动到一个能一并容纳下新申请空间的地址去。问题就来了,有时候系统中连续的空间不够多时,我们就可以依靠链表来使用那些琐碎的空间了。
10.2 静态链表
链表包括两个区域:
- 数据域:我们要储存的数据放在这里。
- 指针域:指针指向下一个节点,下一节点的类型就是本类型。
具体实现就如下:
- 当前指针指向第一个元素,并且不为空;
- 打印第一个元素的值,同时能得到第二个元素的地址;
- 将第二个元素的地址赋值给当前指针。
typedef struct node {
int data;
struct node * next;
} Node;
int main(int argc, char * argv[])
{
Node a, b, c, d, e;
Node * head = &a; // 链头,指向第一个节点;
Node * pHead = head; // 链头复制】品,移动这个头,否则这个链表将没有链头了。
a = { 1996,&b };
b = { 12,&c };
c = { 18,&d };
d = { 13,&e };
e = { 40,NULL }; // 结尾。
while (pHead)
{
cout << pHead->data<<endl;
pHead = pHead->next;
}
system("pause");
return 0;
但是当我们将访问链表打包成一个函数的时候,就可以不定义链头的替身了。 如下:
int main(int argc, char * argv[])
{
Node a, b, c, d, e;
Node * head = &a; // 链头,指向第一个节点;
Node * pHead = head; // 链头复制】品,移动这个头,否则这个链表将没有链头了。
a = { 1996,&b };
b = { 12,&c };
c = { 18,&d };
d = { 13,&e };
e = { 40,NULL }; // 结尾。
/*while (pHead)
{
cout << pHead->data << endl;
pHead = pHead->next;
}*/
CoutList(head);
putchar(10);
cout << head->data << endl;
system("pause");
return 0;
}
void CoutList(Node * n)
{
while (n)
{
cout << n->data;
n = n->next;
}
}
当我们把 head 传进 CoutList 的时候,此时CoutList 的 n 就已经是一个head的替身了。
10.3 动态链表
10.3.1 空链表

10.3.2 动态非空链表

第一个空节点我们称之为头节点,什么数据也不放。为什么呢?这个以后我们对链表有了整体的认知以后再回过头来看会更有意义。紧跟着头节点的我们称之为首节点。最后一个叫尾节点。那动态链表和静态链表的出入在哪里呢:
动态链表除了头指针在栈上以外,其他的所有节点都在堆里,并且,每一个节点都是动态创建成功的。
10.3.3 动态链表的创建
10.3.4 尾插法:
尾插法简单,好理解,但是应用面不广,代码如下:
typedef struct node {
int data;
struct node * next;
} Node;
Node * CreateList();
void TravelList(Node * s);
int main(int argc, char * argv[])
{
Node * pHead = CreateList();
node * ptr = pHead;
TravelList(pHead);
system("pause");
return 0;
}
void TravelList(Node * s)
{
cout << "List输出:" << endl;
s = s->next;
while (s)
{
cout << s->data << endl;
s = s->next;
}
}
Node * CreateList()
{
Node * head = (Node *)malloc(sizeof(Node));
if (NULL == head)
{
cout << "CreateList分配空间失败" << endl;
exit(-1);
}
head->next = NULL;
Node * t = head, * cur;
int nodeData;
cin>> nodeData;
while (nodeData)
{
cur = (Node *)malloc(sizeof(Node));
if (NULL == head)
{
cout << "CreateList分配空间失败" << endl;
exit(-1);
}
cur->data = nodeData;
t->next = cur;
t = cur;
cin >> nodeData;
}
t->next = NULL;
return head;
}
尾插法就是在尾节点插入,每插入一个即为尾节点。简单,但是应用面不广。
10.3.5 头插法
就是在头节点后面插入元素,每插入一个元素,即为首节点。
int main()
{
Node * head = CreateNewListHead();
TravelList(head);
system("pause");
return 0;
}
Node * CreateNewListHead()
{
Node * head = (Node *)malloc(sizeof(Node));
if (NULL == head)
{
exit(-1);
}
head->next = NULL;
Node * cur;
int nodeDate;
cin >> nodeDate;
while (nodeDate)
{
cur = (Node *)malloc(sizeof(Node));
if (NULL == cur)
{
exit(-1);
}
cur->data = nodeDate;
cur->next = head->next; // 先让新来的节点有所指向,避免打断原有的只想关系。
head->next = cur;
cin >> nodeDate;
}
return head;
}
最重要的一部就在代码注释部分,先让新来的节点有所指向,避免打断原有的指向关系。
10.4 链表的插入操作
插入操作的本质就是头插法。 这就是头插法运用得比尾插法更广泛的原因。为什么不使用尾插法来插入呢?其实在实现上是没问题的,十来个节点还可以,但是如果这条链表有上百个上万个节点呢?那你从一开始就要先从头节点跑到尾节点,刚跑到尾节点啥事没做就已经累死了。但是如果我们用头插法来实现,就很方便了。
int main()
{
Node * head = CreateNewListHead();
TravelList(head);
InsertList(head,999);
TravelList(head);
system("pause");
return 0;
}
void InsertList(Node * head, int nodeData)
{
Node * cur = (Node *)malloc(sizeof(Node));
if (NULL == cur)
{
exit(-1);
}
cur->data = nodeData;
cur->next = head->next;
head->next = cur;
我们在创建列表的时候,其实就是创建一个空链表。然后再将节点一个一个插入进去。如下:
int main(int argc, char * argv[])
{
Node * head = CreateEmptyList();
for (int i = 0; i < 10; i++)
{
InsertList(head, i);
}
TravelList(head);
system("pause");
return 0;
}
Node * CreateEmptyList()
{
Node * head = (Node *)malloc(sizeof(Node));
if (NULL == head)
{
exit(-1);
}
head->next = NULL;
return head;
}
10.5 链表的求长
求长的本质就是遍历。
int LenOfList(Node * head)
{
int len = 0;
head = head->next;
while (head)
{
len++;
head = head->next;
}
return len;
}
10.6 链表的查找
如果我们要删除一个链表,我们需要查找到对应链表才能进行删除操作。现在我们学习的是单向链表,所以我们查找链表时,不能使用折半查找。查找代码如下:
int main(int argc, char * argv[])
{
Node * head = CreateEmptyList();
for (int i = 0; i < 10; i++)
{
InsertList(head, i);
}
TravelList(head);
cout << "链表长度是 " << LenOfList(head) << endl;
Node * pFind = SearchList(head, 5);
if (pFind == NULL)
{
cout << "Find NULL" << endl;
} else
{
cout << "Find it!" << endl;
}
system("pause");
return 0;
}
Node * SearchList(Node * head, int findNum)
{
head = head->next;
while (head)
{
if (head->data == findNum)
{
break;
}
head = head->next;
}
return head;
}
10.7 删除链表
我们查找到了节点,那么就删除它!我们先找到需要删除的前置节点。
int main(int argc, char * argv[])
{
Node * head = CreateEmptyList();
for (int i = 0; i < 10; i++)
{
InsertList(head, i);
}
TravelList(head);
cout << "链表长度是 " << LenOfList(head) << endl;
Node * pFind = SearchList(head, 5);
if (pFind == NULL)
{
cout << "Find NULL" << endl;
} else
{
DeleteNode(head, pFind);
cout << "Find it!" << endl;
}
cout << "链表长度是 " << LenOfList(head) << endl;
TravelList(head);
system("pause");
return 0;
}
void DeleteNode(Node * head, Node * pFind)
{
for (head; head->next != pFind; head = head->next);
head->next = pFind->next;
pFind = NULL;
free(pFind);
}
输出如下:

在删除节点的方法上,我们还可以进行一个优化。刚才的方法需要遍历链表,比较耗费性能,所以我们是否可以不通过遍历,来删除节点呢。答案是肯定的。我们将需要输出的节点复制成为它的后置节点,然后删除它的后置节点就可以了。代码如下:
void BetterDeleteNode(Node * head, Node * pFind)
{
Node * p = pFind->next;
pFind->data = pFind->next->data;
pFind->next = pFind->next->next;
p = NULL;
free(p);
}
但是有一个问题就是,当我们需要删除的节点是最后一个节点时,我们就没有后置节点可以复制,这时我们就只有使用遍历。
void BetterDeleteNode(Node * head, Node * pFind)
{
if (pFind->next == NULL)
{
cout << "遍历" << endl;
for (head; head->next != pFind; head = head->next);
head->next = pFind->next;
pFind = NULL;
free(pFind);
}
else{
cout << "复制后节点" << endl;
Node * p = pFind->next;
pFind->data = pFind->next->data;
pFind->next = pFind->next->next;
p = NULL;
free(p);
}
}
此时看着代码很多,但是代码多并不代表着效率就很低。二者没有关系。
10.8 链表排序
10.8.1 冒泡排序
在讲排序之前,我们来看一下冒泡排序。冒泡排序是非常适合用来给链表排序的一门排序算法。


可以看到,如果我们需要从小到大排列,那么大数每次都往后冒,冒到最后且不参与下次外层循环。就像一个水泡从水底往上冒,直至到水面水泡炮炸消失为止。仔细观察上表就能发现,
- 冒泡排序的外层有N-1次,也就是N个数需要比较N-1次。
- 内层循环的下标每次都从0开始。比较规则是每次都和它下一个比较内层循环的次是N-1-i;
看到这里是否明白为什么链表使用冒泡排序了吧?因为链表和它的后置节点很好比较,但是间隔比较就比较困难了。
冒泡排序的代码如下:
int main(){
int arr[5] = { 5,4,3,2,1 };
for (int i = 0; i < 4; i++)
{
for (int j = 0; j<4-i ;j++)
{
if (arr[j] > arr[j + 1])
{
arr[j] ^= arr[j + 1];
arr[j + 1] ^= arr[j];
arr[j] ^= arr[j + 1];
}
}
}
for (int i = 0; i < 5; i++)
{
cout << arr[i] << endl;
}
system("pause");
return 0;
}
10.8.2 链表的冒泡排序
void SortListPop(Node * head)
{
int len = LenOfList(head);
Node * t, * p;
head = head->next;
for (int i = 0; i < len - 1; i++)
{
t = head;
p = t->next;
for (int j = 0; j < len - 1 - i; j++)
{
if ((t->data) > (p->data))
{
t->data ^= p->data;
p->data ^= t->data;
t->data ^= p->data;
}
t = t->next;
p=p->next;
}
}
}
这样就算是写完了,理清了思路以后还是很简单的。但是有一个问题。我们这样把数据搬来搬去,数据小无所谓,但是我们用到了链表,那么就不可能是小数据,所以我们这样直接搬数据异常的耗费性能。既然链表就是指针指来指去,那么我们是否能够靠改变指向关系来排序呢, 当然可以。但是我们在这里需要多定义一个指针指向需要交换的节点的前置位置:
void SortListPop(Node * head)
{
int len = LenOfList(head);
Node * t, *p, *prep;
for (int i = 0; i < len - 1; i++)
{
prep = head;
t = prep->next;
p = t->next;
for (int j = 0; j < len - 1 - i; j++)
{
if ((t->data) > (p->data))
{
prep->next = p;
t->next = p->next;
p->next = t;
t = prep->next;
p = t->next;
}
prep = prep->next;
t = t->next;
p=p->next;
}
}
}
10.9 链表的逆置
链表的逆置本质就是将一个链表分割成两个两个链表,然后使用头插法来实现的:
void InverseList(Node * head)
{
Node * cur = head->next;
head->next = NULL;
node * t;
while (cur)
{
t = cur;
cur = cur->next;
t->next = head->next;
head->next = t;
}
}
10.10 链表的销毁
记住一点,有多少malloc,就应该有多少个 free()。
void DestoryList(Node * head)
{
Node * t;
while (head)
{
t = head;
head = head->next;
free(t);
}
}
10.11 头节点的作用
学习到了这里,就可以对之前头节点的数据域为什么是空来进行说明了。因为我们的头节点是一个链表的头,就像是数组里的数组名一样,我们需要能随时获取到它以便于访问链表里的节点。当我们让头节点的指针始终指向第一个空数据域的节点时,我们增删查改排序等操作都在头结点之后的首节点开始进行的话,就不需要更新头指针了,否则每次操作链表都需要更新头指针就会很麻烦。
第11章 文件(File)
Unix的设计哲学之一,就是everything is a file,可见文件是如此的重要。

16.1 文件流
16.1.1 文件流的概念
C 语言把文件看作是一个字符的序列,即文件是由一个一个字符组成的字符流,因 此 C 语言将文件也称之为文件流。即,当读写一个文件时,可以不必关心文件的格式或结构:

文件里最小单位就是一个字符,也就是一字节。
16.1.2 文件类型
16.1.2.1 文件分类
在计算机中的储存在物理上的储存是二进制的,那么既然都是二进制的,那么我们为什么还要去分类别呢?那是因为文本文件与二进制文件的区别在并不在于物理形式上,而是在逻辑上的。简单来说,这两者的差别就在于编码层次上,文本文件时基于字符编码的文件,常见的有ASCII编码,二进制文件则是基于值编码的文件。
- 文本文件::以 ASCII 码格式存放,一个字节存放一个字符。 文本文件的每一个 字节存放一个 ASCII 码,代表一个字符。这便于对字符的逐个处理,但占用存储空间 较多,而且要花费时间转换。
- 二进制文件:以值(补码)编码格式存放。二进制文件是把数据以二进制数的格 式存放在文件中的,其占用存储空间较少。数据按其内存中的存储形式原样存放。
16.1.2.2 举例

在文本文件的储存中,每个字符都转换成ASCII来进行储存,ASCII中,1 = 0011 0001 = 31,0 = 0011 0000 = 30。所以10000组合起来就如上所示。然而,此时二进制文件储存的话,就如同其内存形式一样,是10000的二进制形式了。可以看出,文本文件占用了5个字节,而二进制文件仅仅使用了2个字节。
但是当我们写入的数据本身就是一串字符文件的时候,二进制储存形式和文本文件储存形式就一样了。字符串在内存中的储存方式就是以ASCII的形式储存的,所以它并不需要进行转化,当二进制文件直接照内存形式来写的时候,也就是ASCII的行形式了。
11.1.3 文件缓冲
为什么我们需要缓冲区呢?原因有很多,但是重点有两个:
- 从内存中读取数据比从文件中读取数据快得多。
- 对文件的读写需要用到open、read、write等系统底层函数,而用户进程每次调用一次系统函数都要从用户态切换到内核态,等执行完毕后在返回用户态,这种切换要花费一定的时间成本。
10M的缓存区缓冲是怎样的呢:
- 比如我们的cpu是2G,缓冲区10M,我们每次等待缓冲区10M被放满了数据再将数据刷到磁盘或是演示器上。
11.2 文件的打开或关闭
11.2.1 FILE 结构体
FILE 结构体是对缓冲区和文件读写状态的记录者,所有对文件的操作,都是通过FILE 结构体完成的。

int main(int argc, char * argv[]) {
FILE* pf;
char buf[20] = "Damon Zheng";
fopen_s(&pf, "data.txt", "w");
if (NULL == pf) {
printf("Open file erro!");
}
else {
fwrite(buf, 1, 20, pf);
fclose(pf);
}
system("pause");
return 0;
}
我们通过File * 创建一个指针,以后我们对文件的所有操作都是通过这个指针来进行的,就如同链表的头指针一样。
11.2.2 操作

- r 以只读的方式打开,如果文件不存在,则报错,文件不可写。
- w 如果文件不存在,则创建,如果文件存在,则清空,不可读。
- a 如果文件不存在,则创建,如果文件存在,追加写内容,不可读。
当文件不可读时,将会返回一个EOF给我们:
int main() {
FILE* pf;
char buf[20] = "Rewind Testing\n";
fopen_s(&pf, "RewindTest.txt", "w");
if (NULL == pf) {
cout << "Open File Erro" << endl;
}
else {
fwrite(buf, 1, 15,pf);
fclose(pf);
}
fopen_s(&pf, "RewindTest.txt", "r");
if (NULL == pf) {
cout << "Open File Erro" << endl;
}
else {
fwrite(buf, 1, 15, pf);
rewind(pf);
char ch = fgetc(pf);
if (EOF == ch) {
cout << "EOF" << endl;
}
else {
cout << "Success" << endl;
}
fclose(pf);
}
system("pause");
return 0;
}
rewind()将当前文件指针移向头部。(此指针不是pf)
11.3 fclose
文件被打开以后,就被缓存到内存中去了。内存就像是曼妥思一样,而文件就象是里面的糖一样,一个字节一个字节的排一起的。而整个文件在内存中有太多东西需要去记录了,需要记录的东西就在FILE结构体当中。此时会给我们返回一个FILE *的 pf,此后所有对文件的操作就是通过它来实现的。它就是这个文件的资源所有者——句柄。
fclose 实际上是起到了刷新缓存的功效。它是的机制就类似于主动刷缓存。就像你在CSDN上编辑博客,拿掉fclose就像突然断电,你刚写进去的东西并没有被保存一样,东西是没有写进文件里的。但是实际上你不写fclose,东西最后还会写进文件里,这是因为就像你在word上编辑一样,系统会一直帮你保存。拿掉fclose以后,进程结束时系统会负责任的帮你刷新一次缓存。当然了,我们最好别等着系统来帮我们刷新,因为存在突然断电的情况,这时候东西就确实会发生无法写入文件的情况。当然还有一个原因就是,我们使用fclose,会将我们的文件刷新到硬盘上,然后释放内存中FILE结构体申请的那些内存空间。
11.4 一次读写一个字符(文本操作)
11.4.1 fputc
- 声明:int fputc(int ch, FILE * stream);
- 功能:将ch字符,写入文件
- 返回值:写入成功,返回写入成功的字符,如果失败,返回 EOF。
#define F_PRINT_ERRO(e)\
do{\
if (NULL == e)\
{\
cout << "Open File Erro!" << endl;\
exit(-1);\
}\
}while (0)
//11.4.1 fputc
int main(int argc, char* arhv[])
{
FILE* pf;
fopen_s(&pf, "TestFputc.txt", "w+");
F_PRINT_ERRO(pf);
for (int ch = 'a'; ch <= 'z'; ch++)
{
if (fputc(ch, pf) == EOF)
{
cout << "EOF Erro" << endl;
exit(-1);
}
}
fclose(pf);
system("pause");
return 0;
}
11.4.2 fgetc
- 声明:int fgetc(FILE * stream);
- 功能:从文件中读取一个字符并返回;
- 返回值:正常,返回读取的字符,读到文件尾或是出错时,返回 EOF。
#define F_PRINT_ERRO(e)\
do{\
if (NULL == e)\
{\
cout << "Open File Erro!" << endl;\
exit(-1);\
}\
}while (0)
// 11.4.2 fgetc
int main(int argc, char* argv[])
{
FILE* pf;
fopen_s(&pf, "TestFputc.txt", "r");
F_PRINT_ERRO(pf);
char ch;
while ((ch = fgetc(pf)) != EOF)
{
putchar(ch);
}
fclose(pf);
system("pause");
return 0;
}
11.4.3 练习:拷贝文件
#define F_PRINT_ERRO(e)\
do{\
if (NULL == e)\
{\
cout << "Open File Erro!" << endl;\
exit(-1);\
}\
}while (0)
// 11.4.3 练习:拷贝文件
int main(int argc, char * argv[])
{
FILE* pf_r, * pf_w;
fopen_s(&pf_r, "main1101.cpp", "r");
F_PRINT_ERRO(pf_r);
fopen_s(&pf_w, "data.txt", "w");
F_PRINT_ERRO(pf_w);
char ch;
while ((ch = fgetc(pf_r)) != EOF)
{
putchar(fputc(ch, pf_w));
}
fclose(pf_r);
fclose(pf_w);
system("pause");
return 0;
}
11.4.4 feof
- 声明:int feof( FILE * stream);
- 功能:判断文件是否读取到文件末尾;
- 返回值:未读到文件结尾返回 0,反之返回 非零。
int main(int argc, char * argv[])
{
FILE* pf;
fopen_s(&pf, "TestFeof.txt", "w+");
F_PRINT_ERRO(pf);
for (char ch = 'a'; ch <= 'z'; ch++)
{
putchar(fputc(ch, pf));
}
rewind(pf);
cout << endl;
char ch;
while (!feof(pf))
{
putchar(ch = fgetc(pf));
}
fclose(pf);
system("pause");
return 0;
}
feof有一个小问题,什么小问题呢,注意看下面的输:

feof读文件都会多读一个字符,而有符号十六进制中,ffffffff代表的是-1。不难猜测,最后一位输出的就是EOF。原因就是标志位检测滞后导致的。如果我们非要去使用的话,就如下使用就好:
char ch;
while ((ch = fgetc(pf)) && !feof(pf))
{
printf("\n%x->%c", ch, ch);
}
fclose(pf);
这样既可。但是也就不建议大家使用了,用fgetc就可以了。
11.4.5加密与解密
加密如下,当然了,这是最简单最简单的加密方式,所有字符整体等于其后若干位。
int main()
{
FILE* pf_r, * pf_w;
fopen_s(&pf_r, "main1101.cpp", "r");
F_PRINT_ERRO(pf_r);
fopen_s(&pf_w, "cdMain1101.cpp", "w");
F_PRINT_ERRO(pf_w);
char ch;
while ((ch = fgetc(pf_r)) != EOF)
{
if (ch != '\n'){
ch = ch + CODE;
}
fputc(ch, pf_w);
}
fclose(pf_r);
fclose(pf_w);
system("pause");
return 0;
}
解密如下:
int main09()
{
FILE* pf_r, * pf_w;
fopen_s(&pf_r, "cdMain1101.cpp", "r");
F_PRINT_ERRO(pf_r);
fopen_s(&pf_w, "dcdMain1101.cpp", "w");
F_PRINT_ERRO(pf_w);
char ch;
while ((ch = fgetc(pf_r)) != EOF)
{
if (ch != '\n')
{
ch = ch - CODE;
}
fputc(ch, pf_w);
}
fclose(pf_r);
fclose(pf_w);
system("pause");
return 0;
}
这样写有一个风险。这样写有一个风险,就是溢出风险。
11.5 一次读写一行字符(文本操作)
11.5.1 fputs
- 声明:int fputs(char * str, FILE * fp)。
- 功能:把str指向的字符写入 fp 所指的文件中去。
- 返回值:若正常,则返回0;否则返回EOF。
既然是一次读写一行,那么我们就需要定义什么是一行,什么时候我们知道该换行了。在 Windows 中,换行的定义是 0D 0A, 也就是先让光标到这一行的头部,再移动到下一行。但是当我们去读文件的时候,换行时我们只能读出来一个A。
11.5.2 fgets
有以下几种情况:
- 在去读n-1个字符前遇见了\n,连同\n一并读进。
- 在去读n-1个字符时,既没有遇见\n也有遇见EOF,此时就读到n-1个字符,并在其后添加\0.
- 在去读n-1个字符时,虽没有遇见\n,但是遇见了EOF,就读到现有的字符并添加\0。
11.6 过滤注释与空行
int main()
{
FILE* pf_r;
fopen_s(&pf_r, "TestFputs.txt", "r+");
if (NULL == pf_r)
{
cout << "Open File Erro" << endl;
exit(-1);
}
else
{
char buf[1024];
FILE* pf_w;
fopen_s(&pf_w, "TestConf.txt", "w");
if (NULL == pf_w)
{
cout << "Open File Erro" << endl;
fclose(pf_r);
exit(-1);
}
else
{
while (fgets(buf, 1024, pf_r))
{
if (*buf == '#'|| *buf =='\n')
continue;
printf("%s\n", buf);
fputs(buf, pf_w);
}
}
fclose(pf_r);
fclose(pf_w);
}
system("pause");
return 0;
}
11.7 文件等号后求和

//11.7 文本等号后求和
int main()
{
FILE* pf_r;
fopen_s(&pf_r, "TestAtoi.txt", "r");
if (NULL == pf_r)
{
cout << "Open File Erro" << endl;
exit(-1);
}
else
{
char buf[1024];
char* ch;
int sum = 0;
while ((fgets(buf, 1024, pf_r)) != NULL)
{
ch = buf + 2;//始终略过字母和等号直接找数字位
sum += atoi(ch);
}
cout << sum << endl;
fclose(pf_r);
}
system("pause");
return 0;
}
11.8 一次读写一块字节(二进制操作)
所有的文件接口函数,要么以 ‘\0’ 表示输入结束, 要么以 ‘\n’,EOF(0xff)表示读取结束。 ‘\0’ ‘\n’ 等都是文本文件的重要标识,而二进制文件则往往以块的形式,写入或是读出。而所有的二进制接口对这些标识符是不敏感的。
11.8.1 fwrite
- 声明:int fwrite(void * buffer, int num_bytes, int count, FILE * fp)
- 功能:把buffer指向的数据写入fp指向的文件中
- 返回值:成功,则返回写的字段;否则返回0。
11.8.2 fread
- 声明:int fread(void * buffer, int num_bytes, int count, FILE * fp)
- 功能:将 fp 指向的文件中的数据读取到buffer中。
- 返回值:成功,则返回读的字段,否则返回0。
11.8.3 返回值陷阱
没有\n,EOF,或者n-1作为读出的标识,fread依靠读出块多少来标识读结果和文件结束标识。
以最小单元格式进行读,或是以写入的最小单元进行读。
以下示例:
int main()
{
FILE* pf_r;
fopen_s(&pf_r, "TestFread.txt", "w+");
if (NULL == pf_r)
{
cout << "Open File Erro" << endl;
exit(-1);
}
else
{
char arr[1024] = "12345678";
fwrite((void *)arr, 8, 1, pf_r);
rewind(pf_r);
char nums[10];
int n;
n = fread((void*)nums, 4, 1, pf_r);
printf("%d\n", n);
n = fread((void*)nums, 4, 1, pf_r);
printf("%d\n", n);
fclose(pf_r);
}
system("pause");
return 0;
}
fread这时候返回的是读到的块的个数,此时的输出是:

换成3块与6块:
n = fread((void*)nums, 3, 1, pf_r);
printf("%d\n", n);
n = fread((void*)nums, 6, 1, pf_r);
printf("%d\n", n);
此时输出:

所以,我们宁愿把最小单元设置小一点,因为这样我们在写循环的时候才不会出错。最小单元设置以后,
n = fread((void*)nums, 1, 5, pf_r);
printf("%d\n", n);
n = fread((void*)nums, 1, 6, pf_r);
printf("%d\n", n);
输出如下:

用循环代替就是如下:
int main()
{
FILE* pf_r;
fopen_s(&pf_r, "TestFread.txt", "w+");
if (NULL == pf_r)
{
cout << "Open File Erro" << endl;
exit(-1);
}
else
{
char arr[1024] = "12345678";
fwrite((void *)arr, 8, 1, pf_r);
rewind(pf_r);
char nums[10];
int n;
while ((n = fread((void*)nums, 1, 3, pf_r))>0)
{
for (int i = 0; i < n; i++)
{
cout << nums[i] << endl;
}
}
fclose(pf_r);
}
system("pause");
return 0;
}
通常我们设置最小单元就是我们输入的基本单位的大小。
11.8.4 二进制读写才是本质
在计算机中,当我们打开一个二进制文件的时候,其中到处都是文本的标志性字符。但是对于fread和fwrite来说,一视同仁,都是一个普通字节而已。所以,对于二进制文件的读写就要用对文本标记不敏感的fread和fwrite来进行。
//11.8.4 二进制读写才是本质
int main()
{
int a[10] = { 0xff,0,1,2,3,4,5,6,7,8 };
FILE* pf_w;
fopen_s(&pf_w, "TestBinFile.txt", "wb+");
if (NULL == pf_w)
{
cout << " Open File Erro" << endl;
exit(-1);
}
else
{
fwrite((void*)a, 4, 10, pf_w);
rewind(pf_w);
int n = 0;
int data;
while (n = fread(&data, 4, 1, pf_w) > 0)
{
cout << data << endl;
}
fclose(pf_w);
}
system("pause");
return 0;
}
11.8.4.1 文件的加密与解密
//11.8.4.1 文件的加密与解密
void Encode(char* buff, int n)
{
for (int i = 0; i < n; i++)
{
buff[i]++;
}
}
void Decode(char* buff, int n)
{
for (int i = 0; i < n; i++)
{
buff[i]--;
}
}
int main(int argc, char * argv[])
{
if (argc != 4)
{
cout << "no such command line" << endl;
exit(-1);
}
FILE* pf_r;
fopen_s(&pf_r, argv[2], "rb+");
if (NULL == pf_r)
{
cout << "open file erro" << endl;
exit(-1);
}
FILE* pf_w;
fopen_s(&pf_w, argv[3], "wb+");
if (NULL == pf_w)
{
fclose(pf_r);
cout << "open file erro" << endl;
exit(-1);
}
char buff[1024];
int n;
if (strcmp(argv[1], "-c") == 0)
{
while ((n = fread((void*)buff, 1, 1024, pf_r))> 0)
{
Encode(buff, n);
fwrite((void*)buff, 1, n, pf_w);
}
}
else if(strcmp(argv[1],"-d") == 0)
{
while ((n = fread((void*)buff, 1, 1024, pf_r)) > 0)
{
Decode(buff, n);
fwrite((void*)buff, 1, n, pf_w);
}
}
else
{
cout << "no such command line" << endl;
}
fclose(pf_r);
fclose(pf_w);
system("pause");
return 0;
}
11.8.5 读写结构体是长项
结构体中的数据类型是不统一的,此时最适合用二进制的方式进行读写。二进制的接口可以读文本,而文本的接口不可以读二进制。
typedef struct _Student
{
int num;
char name[10];
char sex;
float math;
float english;
float chinese;
}STU;
//11.8.5 读写二进制是长项
int main()
{
STU s[5] = {
1,"WuKong",'M',100,100,100,
2,"WuJing",'M',23,10,45,
3,"WuFan",'M',34,78,71,
4,"BeiJiTa",'M',100,21,99,
5,"Damon",'M',100,100,100,
};
FILE* pf_w;
fopen_s(&pf_w, "Students.txt", "w");
if (NULL == pf_w)
{
cout << "Open File Erro" << endl;
exit(-1);
}
char ch = '\n';
for (int i = 0; i < 5; i++)
{
fwrite((void*)&s[i], sizeof(STU), 1, pf_w);
fwrite((void*)&ch, 1, 1, pf_w);
}
fclose(pf_w);
system("pause");
return 0;
}
那么我们为什么使用二进制格式来读写结构体呢:
- 结构体当中类型不统一
- 可以将二进制转化为文本,使其统一,降低了效率,占用多余的储存空间
读结构体文件:
int main()
{
FILE* pf_r;
fopen_s(&pf_r, "Students.txt", "r+");
if (NULL == pf_r)
{
cout << "Open File Erro" << endl;
exit(-1);
}
STU s[3];
int n;
while ((n = fread((void*)s, sizeof(STU), 3, pf_r)) > 0)
{
for (int i = 0; i < n; i++)
{
cout << s[i].num << endl;
cout << s[i].name << endl;
cout << s[i].sex << endl;
cout << s[i].math << endl;
cout << s[i].english << endl;
cout << s[i].chinese << endl;
cout << "================" << endl;
}
}
fclose(pf_r);
system("pause");
return 0;
}
11.8.6 管理系统
管理系统分为三大类,内存数据模型,数据库模型,和交互界面。
将链表作为内存数据模型,将文件作为数据库,将终端作为交互界面。读文件生成链表,修改链表写入文件。
typedef struct _Student
{
int num;
char name[20];
char sex;
float math;
float english;
float chinese;
}STU;
typedef struct _StuNode
{
STU data;
struct _StuNode* next;
}StuNode;
// 11.8.6 管理系统
//步骤大致如下:
/*
1. 初始化数据库,此时的数据库是文件;
2. 读数据库,生成内存数据模型——链表;
3. 增,查,改,删,排序;
4. 更新数据库,退出程序;
*/
//初始化数据库,此时的数据库是文件。
void InitialData()
{
STU s[5] = {
{1,"WuKong",'M',100.0,100.0,100.0},
{2,"BaJie",'M',23.0,10.0,45.0},
{3,"TangSanZang",'M',34.0,78.0,7.0},
{4,"ShaHeShang",'M',100.0,21.0,99.0},
{5,"Damon",'M',100.0,100.0,100.0},
};
FILE* pf_w;
fopen_s(&pf_w, "Stu.data", "w+");
if (NULL == pf_w)
{
cout << "Open File Erro" << endl;
exit(-1);
}
else
{
fwrite((void*)s, sizeof(STU), 5, pf_w);
fclose(pf_w);
}
}
//读数据库,生成链表;
StuNode* CreatListFromFile(const char * filePath)
{
FILE* pf_r;
fopen_s(&pf_r, filePath, "r+");
if (NULL == pf_r)
{
cout << "Open File Erro" << endl;
exit(-1);
}
StuNode* head = (StuNode*)malloc(sizeof(StuNode));
if (NULL == head)
{
exit(-1);
}
head->next = NULL;
StuNode* cur = (StuNode*)malloc(sizeof(StuNode));
if (NULL == cur)
{
exit(-1);
}
int n = 0;
while (fread((void*)&(cur->data), sizeof(STU), 1, pf_r))//要么返回0,要么返回1
{
cur->next = head->next;//头插法
head->next = cur;
cur = (StuNode*)malloc(sizeof(StuNode));
if (NULL == cur)
{
exit(-1);
}
}
fclose(pf_r);
free(cur);
return head;
}
void TravelList(StuNode * head)
{
printf("\t\t\t\t\t 学生管理系统\n");
printf("=====================================================================================================\n");
printf("%s\t\t%-10s\t\t%s\t\t%s\t\t%s\t\t%s\n", "学号", "姓名", "性别", "数学", "语文","英语");
head = head->next;
while (head)
{
printf("%d\t\t%-10s\t\t%c\t\t%.2f\t\t%.2f\t\t%.2f\n", head->data.num, head->data.name,
head->data.sex, head->data.math,
head->data.chinese, head->data.english);
head = head->next;
}
}
void AddListNode(StuNode* head)
{
StuNode* newNode = (StuNode*)malloc(sizeof(StuNode));
if (NULL == newNode)
{
exit(-1);
}
printf("Number:");
scanf_s("%d", &(newNode->data.num), sizeof(newNode->data.num));
printf("Name:");
scanf_s("%s", &(newNode->data.name),sizeof(newNode->data.name));
getchar();
printf("Sex:");
scanf_s("%c", &(newNode->data.sex), sizeof(newNode->data.sex));
printf("Math:");
scanf_s("%f", &(newNode->data.math), sizeof(newNode->data.math));
printf("Chinese:");
scanf_s("%f", &(newNode->data.chinese), sizeof(newNode->data.chinese));
printf("English:");
scanf_s("%f", &(newNode->data.english), sizeof(newNode->data.english));
newNode->next = head->next;
head->next = newNode;
}
StuNode * SearchListNode(StuNode* head,int cinNum)
{
head = head->next;
while (head)
{
if (head->data.num == cinNum)
{
break;
}
head = head->next;
}
return head;
}
void DeleteListNode(StuNode* head, int cinNum)
{
StuNode* pFind = SearchListNode(head,cinNum);
if (NULL == pFind)
{
cout << "查无此人,请查证后重试" << endl;
return;
}
else
{
while (head->next != pFind)
{
head = head->next;
}
head->next = pFind->next;
free(pFind);
}
}
int LenListNode(StuNode * head)
{
int len = 0;
head = head->next;
while (head)
{
len++;
head = head->next;
}
return len;
}
void SortStuListNode(StuNode* head)
{
int len = LenListNode(head);
StuNode* pre, * p, * q;
for (int i = 0; i < len - 1; i++)
{
pre = head;
p = pre->next;
q = p->next;
for (int j = 0; j < len - 1 - i; j++)
{
float grades_p = p->data.math + p->data.english + p->data.chinese;
float grades_q = q->data.math + q->data.english + q->data.chinese;
if ( (grades_p) < (grades_q) )
{
pre->next = q;
p->next = q->next;
q->next = p;
pre = q;
q = p->next;
continue;
}
pre = pre->next;
p = p->next;
q = q->next;
}
}
}
void SaveListNode2File(StuNode* head,const char* filePath)
{
FILE* pf_w;
fopen_s(&pf_w, filePath, "w+");
if (NULL == pf_w)
{
cout << "Open File Erro" << endl;
}
head = head->next;
while (head)
{
fwrite((void*)&(head->data), sizeof(STU), 1, pf_w);
head = head->next;
}
}
void DestroyListNode(StuNode* head)
{
StuNode* cur;
while (head)
{
cur = head;
head = head->next;
free(cur);
}
}
int main()
{
//InitialData();
StuNode* head = CreatListFromFile("Stu.data");
StuNode* find;
while (1)
{
system("cls");
TravelList(head);
printf("1->add\t\t2->search\t\t3->delete\t\t4->sort\t\t5->exit\n");
int choice;
cin >> choice;
switch (choice)
{
case 1:
AddListNode(head);
break;
case 2:
int cinNum;
cout << "输入学号:";
cin >> cinNum;
find = SearchListNode(head, cinNum);
if(!find)
{
cout << "查无此人" << endl;
getchar(); getchar();
exit(-1);
}
cout << find->data.name << endl;
cout << "数学:" << find->data.math << endl;
cout << "语文:" << find->data.chinese << endl;
cout << "英语:" << find->data.english << endl;
getchar(); getchar();
break;
case 3:
cout << "请输入要输出学生的学号:";
cin >> cinNum;
DeleteListNode(head,cinNum);
break;
case 4:
SortStuListNode(head);
break;
case 5:
SaveListNode2File(head,"Stu.data");
DestroyListNode(head);
return 0;
default:
cout << "请输入相关指令\n" << endl;
}
}
system("pause");
return 0;
}
11.9 ftell && fseek
ftell返回一个值,此值代表当前文件指针距离文件头的距离。当我们让当前文件指针指向最后时,就可以利用ftell得到文件的大小了。
fseek就是偏移文件指针,0代表从头,1代表当前位置,2代表从末尾偏移。
十二章 位操作(Bit Operation)
12.1 位操作与逻辑操作
位操作不同于逻辑操作,逻辑操作是一种整体的操作,而位操作是针对内部数据位补码的操作。逻辑操作的世界里,只有真与假(0或者非0),而位操作的世界里按位论真假(1和0)。运算符也不同,如下:

12.2.1 按位与(&)
按位与:&
格式:x&y
规则:对应位均为1,否则为0

例如:3&11=3;
#include 输出如下:

一个数,跟1按位与保持不变,跟0按位与清零。在某些位保持不变的情况下,某些清零。
12.2.2 按位或(|)
按位或:|
格式:x|y
规则:对应位均为0时才为0,否则为1.

例如:3|9=11

跟1按位或全变成1,称为置1,跟0按位或保持不变。在某些位保持不变的情况下,某些置1.
12.2.3 位取反(~)
按位求反: ~
格式 :~ y
规则 :各位翻转,即原来为 1 的位变成 0,原来为 0 的置 1
例如 :~3=-4

用于间接的构造某些数据。
12.2.4 位异或(^)
异或什么意思呢:相异的或。所以,只要是相异的,就为1.
按位异或:^
格式 :x^y
规则 :对应相同时 0 ,不同时则为 1。

例如:3^9=10

跟1异或取反,跟0异或不变 。在某些位保持不变的情况下,某些位取反。
12.2.5 左移( << )
按位左移:<<
格式 :x<<位数
规则 :使操作数的各位左移,低位补 0,高位溢出。
备注 :位数为非负整数,且默认对 32 求余
在不溢出的情况下,每左移一位等价于乘2.

备注是什么意思呢,当移动位数超过32位时,会将位数对32求余。比如34,就只会移动2位。
12.2.5 右移( >> )
按位右移:>>
格式 :x>>位数
规则 :使操作数的各位右移,移出的低位舍弃;
高位 :对无符号数和有符号中的正数补 0;有符号数中的负数,取决于所使用的 系 统: 补 0 的称为"逻辑右移",补 1 的称为"算术右移"。
说明 :x、y 和"位数"等操作数,都只能是整型
备注 :位数为非负整数,且默认对 32 求余
在不溢出的情况下,每左移一位等价于除2.
12.3 应用
12.3.1掩码(mask)
掩码的意义在于——掩盖掉一些东西,然后再留下一些东西。
12.3.2 功能
- 位打开——flag |= MASK;
- 位关闭——flag&=~MASK:
- 位转置——flag^=MASK;
- 查看某一位置的值——if((flag&MASK)==MASK);
其实有以下几个套路:
- 确定操作的位数
- 找到合适的掩码
- 位运算
12.4 练习
题目:从键盘上输入 1 个正整数给 int 变量 num,输出由 3~6 位构成的数(从低 0 号开始编号)
int main(int argc, char * argv[])
{
int num;
cin >> num;
Dis32Bin(num);
int mask = (1 << 6) | (1 << 5) | (1 << 4)|(1<<3);
Dis32Bin(num & mask);
int newNum = (num & mask) >> 3;
Dis32Bin(newNum);
system("pause");
return 0;
}
输出如下:

或者也可以先将输入的num右移三位,这样也是可以的。
12.5 优先级

12.6 判断是否是2的幂
int main(int argc, char * argv[])
{
int num;
cout << "输入一个数判断其是否是2的幂:";
cin >> num;
if (!(num & num - 1))
{
cout << "是2的幂" << endl;
} else
{
cout << "不是2的幂" << endl;
}
system("pause");
return 0;
}
12.7 循环位加密
void CircleMove(unsigned int * a, int step)
{
step %= 32;
//左移逻辑
if (step > 0)
{
*a = (*a << step) | (*a >> ((sizeof(*a) * 8 - step)));
}
//右移逻辑
else
{
*a = (*a >> -step) | (*a << (sizeof(*a) * 8 - (-step)));
}
}
int main(int argc, char * argv[])
{
unsigned int a = 0x80000001;
Dis32Bin(a);
CircleMove(&a, -1);
Dis32Bin(a);
system("pause");
return 0;
}
12.8 无参交换
早在学习基本数据类型的时候,就讨论过这个话题了。平时我们交换时,会采用设置一个临时变量来操作,如下:
void MySwape(int * a, int * b)
{
int t = *a;
*a = *b;
*b = t;
}
int main(int argc, char* argv[])
{
int a = 1, b = 2;
MySwape(&a, &b);
cout << "a = " << a << " b = " << b << endl;
system("pause");
return 0;
}
这样做,通俗易懂,但是由于开辟了新的空间来储存临时变量,所以不够高级。然后衍生出了下面的这种,不需要设置临时变量来交换:
void MySwape(int * a, int * b)
{
*a = *a + *b;
*b = *a - *b;
*a = *a - *b;
}
int main(int argc, char* argv[])
{
int a = 1, b = 2;
MySwape(&a, &b);
cout << "a = " << a << " b = " << b << endl;
system("pause");
return 0;
}
思想就是 1 +2 = 3,3 -2 =1,3 - 1 = 2;方便易懂,但是缺点是求和时超出类型所储存最大值会溢出。再后来,就来到了交换的最高境界:异或。通过观察下边的表,你会发现,以后具有一个天然的特性,就是,已知其中任意两个数值,就能求出任意第三个数值:

void MySwape(int * a, int * b)
{
*a = *a ^ *b;
*b = *a ^ *b;
*a = *a ^ *b;
}
进一步简写:
void MySwape(int * a, int * b)
{
*a ^= *b;
*b ^= *a;
*a ^= *b;
}
不要试图从二进制的层间去理解,直接利用他天然的特性,如同上一个方法一样,已知任意两个数,可求第三个数。这个方法既不需要临时变量,也不会溢出,推荐。
12.9 异或加密与解密
void Encode(char* res, char a)
{
char* i = res;
while (*i != '\0')
{
*i ^= a;
i++;
}
}
void Decode(char* res, char a)
{
char* i = res;
while (*i != '\0')
{
*i ^= a;
i++;
}
}
int main(int argc, char* argv[])
{
FILE* pf_w;
fopen_s(&pf_w, "Test.txt", "r+");
if (NULL == pf_w)
{
cout << "Open File Erro" << endl;
} else
{
char res[1024];
int n;
fread(&res, 1024, 1, pf_w);
char code = 'p';
Encode(res, code);
cout << res << endl;
Decode(res, code);
cout << res << endl;
}
system("pause");
return 0;
}
输出结果:

但是如果我把code换成C,就会有问题了:

原因在于,自己与自己异或,结果就会清零。解密到C字母时,就变成了0,0就代表字符串结束。
如果遇到这样的情况,我们在加密与解密时做一个判断就好,如果加密字符等于code,那么我们就跳过。如下:
void Encode(char* res, char a)
{
char* i = res;
while (*i != '\0')
{
if (*i == a)
{
i++;
continue;
}
*i ^= a;
i++;
}
}
void Decode(char* res, char a)
{
char* i = res;
while (*i != '\0')
{
if (*i == a)
{
i++;
continue;
}
*i ^= a;
i++;
}
}
但是这样一次只能使用一个字符作为密码,显得很low,所以我们修改一下,一次可以使用一个字符来作为密码了。
void EnLongCodes(char * res, char * code)
{
int len = strlen(res);
int n = strlen(code);
int j = 0;
for (int i = 0; i < len; i++)
{
if (res[i] == code[j])
{
j++;
}
else
{
res[i] ^= code[j++];
if (j == n)
{
j = 0;
}
}
}
}
void DeLongCodes(char* res, char* code)
{
int len = strlen(res);
int n = strlen(code);
int j = 0;
for (int i = 0; i < len; i++)
{
if (res[i] == code[j])
{
j++;
} else
{
res[i] ^= code[j++];
if (j == n)
{
j = 0;
}
}
}
}
这样就是循环异或加密了。跑起来试一下:
int main(int argc, char* argv[])
{
FILE* pf_w;
fopen_s(&pf_w, "Test.txt", "r+");
if (NULL == pf_w)
{
cout << "Open File Erro" << endl;
} else
{
char res[1024];
int n;
fread(&res, 1024, 1, pf_w);
char code[1024] = "damon";
EnLongCodes(res, code);
cout << res << endl;
DeLongCodes(res, code);
cout << res << endl;
fclose(pf_w);
}
system("pause");
return 0;
}
输出:

十三章 预处理
13.1 发生时机
发生在hello.c到hello.i之间的pre-processor阶段。·
13.2 宏(Macro)
13.2.1 不带参宏
13.2.1.1 常量宏
#define 定义的宏,只能在一行内表达(换行符表示结束而非空格),如果想多行表 达,则需要加续行符。
并且,常量宏很简单,只是在预处理阶段做最简单的替换。在LInux下观察如下:
- 当定义 (2+3)时:
- 当定义2+3时:
由此可见,常量宏定义只是做最简单的替换而已。
13.2.1.2 宏类型
#include 输出如下:
![]()
原因也是在于宏类型也是最简单的替换,拿到Linux下观察就一目了然:

13.2.1 带参宏(宏函数)
我们常将短小精悍的函数进行宏化,这样可以嵌入到代码中,减少调用的开销。但 是代价就是,编译出的文件可能会变大。 宏函数常常一行表达不完,如多行,为了形式上的方便,多采用续行符进行接续。
#include 得到结果3,但是,有一点值得注意:紧跟S的后面不可以有空格。
当我们不需要宏定义的时候,只需要在代码不需要处加上 #undef 宏定义名 就好了:
int main()
{
#undef SQ(a)
int i = 1;
while (i <=5)
{
cout << SQ(i++) << endl;
}
cout << " ==================================================" << endl;
int n = 1;
while (n <= 5)
{
cout << Sq(n++) << endl;
}
system("pause");
return 0;
}
13.3 条件编译(Condition Compile)
13.3.1单双路(#ifdef / #ifndef # else #endif)
依据条件决定是否参与编译
//单双陆条件编译
int main(int argc, char * argv[])
{
#if 0
cout << "Hello World" << endl;
cout << "Hello World" << endl;
cout << "Hello World" << endl;
cout << "Hello World" << endl;
#else 1
cout << "Hello World" << endl;
cout << "Hello World" << endl;
#endif
system("pause");
return 0;
}
13.3.2 多路条件编译
#define X86 1
#define MIPS 2
#define POWERPC 3
#define MACHINE X86
using namespace std;
int Sq(int n)
{
return (n)*(n);
}
//多路条件编译
int main(int argc, char * argv[])
{
#if MACHINE == X86
cout << "X86" << endl;
cout << "X86" << endl;
cout << "X86" << endl;
cout << "X86" << endl;
#elif MACHINE == MIPS
cout << "MIPS" << endl;
cout << "MIPS" << endl;
cout << "MIPS" << endl;
cout << "MIPS" << endl;
#elif
cout << "POWERPC" << endl;
cout << "POWERPC" << endl;
cout << "POWERPC" << endl;
cout << "POWERPC" << endl;
#endif
system("pause");
return 0;
}
13.4 头文件包含(#include)
含义就是,全写入。举个例子:
#include 其本质就是找到iostream这个文件并与代码里面的这句话替换。
13.4.1 多文件编程
13.4.1.1 多文件编程的意义
两大好处:
- 方便管理,协同开发
- 便于分享与加密(做成库函数)
13.4.2 定义头文件
13.4.2.1 定义头文件
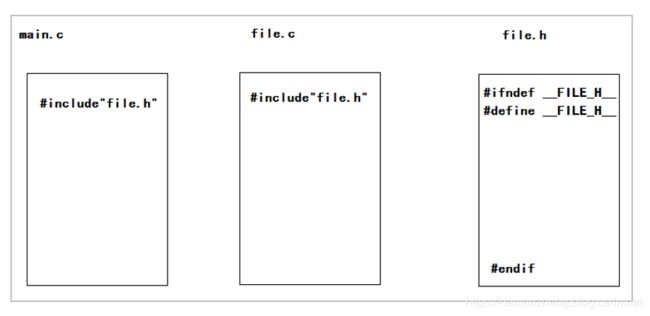
分为三步:
- 谁用谁包含
- 自包含:解决了类型的需要,省却了函数间相互调用需要前项声明的麻烦
- 避免头文件重复包含
13.5 其他
13.5.1 #运算符 利用宏创建字符
#define STR(x) "aaa"#x"bbb"
using namespace std;
int Sq(int n)
{
return (n)*(n);
}
//利用宏替换字符
int main(int argc, char * argv[])
{
cout << STR(2) << endl;
system("pause");
return 0;
}
13.5.2 ##运算符 预处理的粘合剂
#define S(a,b) a##a+b##b
using namespace std;
int Sq(int n)
{
return (n)*(n);
}
//##粘合剂
int main(int argc, char * argv[])
{
cout << S(1, 2) << endl;
system("pause");
return 0;
}