一 介绍
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
说明:

1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值
2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值
sex enum('male','female') not null default 'male'
age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20
3. 是否是key
主键 primary key
外键 foreign key
索引 (index,unique...)
二 not null与default
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1(
nid int not null defalut 2,
num int not null
);
先说一点:在我们插入数据的时候,可以这么写insert into tb1(nid,num) values(1,‘chao’);就是在插入输入的时候,指定字段插入数据,如果我在只给num插入值,可以这样写insert into tb1(num) values('chao');还可以插入数据的时候,指定插入数据字段的顺序:把nid和num换个位置,但是对应插入的值也要换位置。注意:即便是你只给一个字段传值了,那么也是生成一整条记录,这条记录的其他字段的值如果可以为空,那么他们就都是null空值,如果不能为空,就会报错。
not null和default测试:
==================not null====================
mysql> create table t1(id int); #id字段默认可以插入空
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t1 values(); #可以插入空
mysql> create table t2(id int not null); #设置字段id不为空
mysql> desc t2;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t2 values(); #不能插入空
ERROR 1364 (HY000): Field 'id' doesn't have a default value
==================default====================
#设置id字段有默认值后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值
mysql> create table t3(id int default 1);
mysql> alter table t3 modify id int not null default 1;
==================综合练习====================
mysql> create table student(
-> name varchar(20) not null,
-> age int(3) unsigned not null default 18,
-> sex enum('male','female') default 'male',
-> hobby set('play','study','read','music') default 'play,music'
-> );
mysql> desc student;
+-------+------------------------------------+------+-----+------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------------------------+------+-----+------------+-------+
| name | varchar(20) | NO | | NULL | |
| age | int(3) unsigned | NO | | 18 | |
| sex | enum('male','female') | YES | | male | |
| hobby | set('play','study','read','music') | YES | | play,music | |
+-------+------------------------------------+------+-----+------------+-------+
mysql> insert into student(name) values('chao');
mysql> select * from student;
+------+-----+------+------------+
| name | age | sex | hobby |
+------+-----+------+------------+
| chao| 18 | male | play,music |
+------+-----+------+------------+
注意一点:如果是非严格模式,int类型不传值的话会默认为0,因为null不是int类型的,字段是int类型,所以他会自动将null变为0
三 unique
独一无二,唯一属性:id,身份证号等
是一种key,唯一键,是在数据类型之外的附加属性,其实还有加速查询的作用,后面再讲这个。
unique创建
============设置唯一约束 UNIQUE===============
方法一:
create table department1(
id int,
name varchar(20) unique,
comment varchar(100)
);
方法二:
create table department2(
id int,
name varchar(20),
comment varchar(100),
constraint uk_name unique(name)
);
mysql> insert into department1 values(1,'IT','技术');
Query OK, 1 row affected (0.00 sec)
mysql> insert into department1 values(1,'IT','技术');
ERROR 1062 (23000): Duplicate entry 'IT' for key 'name'
联合唯一
create table service(
id int primary key auto_increment,
name varchar(20),
host varchar(15) not null,
port int not null,
unique(host,port) #联合唯一
);
mysql> insert into service values
-> (1,'nginx','192.168.0.10',80),
-> (2,'haproxy','192.168.0.20',80),
-> (3,'mysql','192.168.0.30',3306)
-> ;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into service(name,host,port) values('nginx','192.168.0.10',80);
ERROR 1062 (23000): Duplicate entry '192.168.0.10-80' for key 'host'
四 primary key
从约束角度看primary key字段的值不为空且唯一,那我们直接使用not null+unique不就可以了吗,要它干什么?
主键primary key是innodb存储引擎组织数据的依据,innodb称之为索引组织表,一张表中必须有且只有一个主键。
一个表中可以:
单列做主键
多列做主键(复合主键或者叫做联合主键)
关于主键的通俗解释和强调内容(重点*****)
unique key和primary key都是MySQL的特殊类型,不仅仅是个字段约束条件,还称为索引,可以加快查询速度,这个索引功能我们后面再讲,现在只讲一下这些key作为约束条件的效果。
关于主键的强调内容:
1.一张表中必须有,并且只能由一个主键字段:innodb引擎下存储表数据的时候,会通过你的主键字段的数据来组织管理所有的数据,将数据做成一种树形结构的数据结构,
帮你较少IO次数,提高获取定位数据、获取数据的速度,优化查询。
解释:如果我们在一张表中没有设置primary key,那么mysql在创建表的时候,会按照顺序从上到下遍历你设置的字段,直到找到一个not null unique的字段,
自动识别成主键pri,通过desc可以看到,这样是不是不好啊,所以我们在创建表的时候,要给他一个主键,让他优化的时候用,如果没有pri也没有not null unique字段,
那么innodb引擎下的mysql被逼无奈,你没有设置主键字段,主键又有不为空且唯一的约束,又不能擅自给你的字段加上这些约束,那么没办法,它只能给你添加一个隐藏字段来帮你组织数据,
如果是这样,你想想,主键是不是帮我们做优化查询用的啊,这个优化是我们可以通过主键来查询数据:例如:如果我们将id设置为主键,当我们查一个id为30的数据的时候,
也就是select * from tb1 where id=30;这个查询语句的速度非常快,不需要遍历前面三十条数据,就好像我们使用的字典似的,找一个字,不需要一页一页的翻书,可以首先看目录,
然后看在哪一节,然后看在哪一页,一步步的范围,然后很快就找到了,这就像我们说的mysql的索引(主键、唯一键)的工作方式,一步一步的缩小范围来查找,几步就搞定了,
所以通过主键你能够快速的查询到你所需要的数据,所以,如果你的主键是mysql帮你加的隐藏的字段,你查询数据的时候,就不能将这个隐藏字段作为条件来查询数据了,
就不能享受到优化后的查询速度了,对么
2.一张表里面,通常都应该有一个id字段,而且通常把这个id字段作为主键,当然你非要让其他的字段作为主键也是可以的,看你自己的设计,创建表的时候,
一般都会写create table t1(id int primary key);id int primary key这个东西在建表的时候直接就写上
在没有设置主键的时候,not null+unique会被默认当成主键
mysql> create table t1(id int not null unique);
Query OK, 0 rows affected (0.02 sec)
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
+-------+---------+------+-----+---------+-------+
1 row in set (0.00 sec)
单列主键测试
============单列做主键===============
#方法一:not null+unique
create table department1(
id int not null unique, #主键
name varchar(20) not null unique,
comment varchar(100)
);
mysql> desc department1;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | UNI | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec)
#方法二:在某一个字段后用primary key
create table department2(
id int primary key, #主键
name varchar(20),
comment varchar(100)
);
mysql> desc department2;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.00 sec)
#方法三:在所有字段后单独定义primary key
create table department3(
id int,
name varchar(20),
comment varchar(100),
constraint pk_name primary key(id); #创建主键并为其命名pk_name
mysql> desc department3;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec)
联合主键解释
联合主键
和联合唯一是类似的,
mysql> create table t10(
->id int,
->port int,
->primary key(id,port)
-> );
Query OK, 0 rows affected (0.45 sec)
mysql> desc t10;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | 0 | |
| port | int(11) | NO | PRI | 0 | |
+-------+---------+------+-----+---------+-------+
2 rows in set (0.10 sec)
看key,两个都写的是pri,两个联合起来作为主键,他们两个作为一个主键,不能再有其他的主键了,也就是在创建表的时候,只能出现一次primary key方法。
有同学说,老师,我不写primary key行不,只写一个not null unique字段,当然行,但是我们应该这样做吗,是不是不应该啊,所以以后设置主键的时候,就使用primary key来指定
多列(联合)主键测试
==================多列做主键================
create table service(
ip varchar(15),
port char(5),
service_name varchar(10) not null,
primary key(ip,port)
);
mysql> desc service;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| ip | varchar(15) | NO | PRI | NULL | |
| port | char(5) | NO | PRI | NULL | |
| service_name | varchar(10) | NO | | NULL | |
+--------------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
mysql> insert into service values
-> ('172.16.45.10','3306','mysqld'),
-> ('172.16.45.11','3306','mariadb')
-> ;
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into service values ('172.16.45.10','3306','nginx');
ERROR 1062 (23000): Duplicate entry '172.16.45.10-3306' for key 'PRIMARY'
五 auto_increment
之前我们插入数据的时候,id也需要自己来写,是不是很麻烦啊,我们是不是想,只要有一条记录就直接插入进去啊,不需要考虑说,你现在存储到第多少条数据了,对不对,所以出现了一个叫做auto_increment的属性
约束字段为自动增长,被约束的字段必须同时被key约束,也就是说只能给约束成key的字段加自增属性,默认起始位置为1,步长也为1.
auto_increment测试:
#不指定id,则自动增长
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') default 'male'
);
mysql> desc student;
+-------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | YES | | male | |
+-------+-----------------------+------+-----+---------+----------------+
mysql> insert into student(name) values
-> ('egon'),
-> ('alex')
-> ;
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
| 2 | alex | male |
+----+------+------+
#也可以指定id
mysql> insert into student values(4,'asb','female');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(7,'wsb','female');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+------+--------+
| id | name | sex |
+----+------+--------+
| 1 | egon | male |
| 2 | alex | male |
| 4 | asb | female |
| 7 | wsb | female |
+----+------+--------+
#对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
mysql> delete from student;
Query OK, 4 rows affected (0.00 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> insert into student(name) values('ysb');
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 8 | ysb | male |
+----+------+------+
#应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它
mysql> truncate student;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student(name) values('egon');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
+----+------+------+
1 row in set (0.00 sec)
步长:auto_increment_increment 起始偏移量:auto_increment_offset
#在创建完表后,修改自增字段的起始值
mysql> create table student(
-> id int primary key auto_increment,
-> name varchar(20),
-> sex enum('male','female') default 'male'
-> );
mysql> alter table student auto_increment=3;
mysql> show create table student;
.......
ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
mysql> insert into student(name) values('egon');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 3 | egon | male |
+----+------+------+
row in set (0.00 sec)
mysql> show create table student;
.......
ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
#也可以创建表时指定auto_increment的初始值,注意初始值的设置为表选项,应该放到括号外
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') default 'male'
)auto_increment=3;
#设置步长
sqlserver:自增步长
基于表级别
create table t1(
id int。。。
)engine=innodb,auto_increment=2 步长=2 default charset=utf8
mysql自增的步长:
show session variables like 'auto_inc%';
#基于会话级别
set session auth_increment_increment=2 #修改会话级别的步长
#基于全局级别的
set global auth_increment_increment=2 #修改全局级别的步长(所有会话都生效)
#!!!注意了注意了注意了!!!
If the value of auto_increment_offset is greater than that of auto_increment_increment, the value of auto_increment_offset is ignored.
翻译:如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值会被忽略 ,这相当于第一步步子就迈大了,扯着了蛋
比如:设置auto_increment_offset=3,auto_increment_increment=2
mysql> set global auto_increment_increment=5;
Query OK, 0 rows affected (0.00 sec)
mysql> set global auto_increment_offset=3;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'auto_incre%'; #需要退出重新登录
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
+--------------------------+-------+
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') default 'male'
);
mysql> insert into student(name) values('egon1'),('egon2'),('egon3');
mysql> select * from student;
+----+-------+------+
| id | name | sex |
+----+-------+------+
| 3 | egon1 | male |
| 8 | egon2 | male |
| 13 | egon3 | male |
+----+-------+------+
六 foreign key
一 快速理解foreign key(外键其实就是标明表和表之间的关系,表和表之间如果有关系的话就三种:一对一,多对一,多对多,我们挨个看看~)
员工信息表有三个字段:工号 姓名 部门
公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费
那这就体现出来了三个缺点:
1.表的组织结构不清晰:员工的信息、部门的信息等等都掺在一张表里面。
2.浪费空间,每一条信息都包含员工和部门,多个员工从属一个部门,也需要每个员工的信息里都包含着部门的信息,浪费硬盘空间。
3.扩展性极差:如果想修改一个部门的信息,比如修改部门名称,那么这个包含员工和部门信息的表中的所有的包含这个部门信息的数据都需要进行修改,那么修改起来就非常麻烦,这是非常致命的缺点。
解决方法:(画一个excel表格来表示一下效果~~)
我们完全可以定义一个部门表,解耦和
我们虽然将部门表提出来了,但是员工表本身是和部门有联系的,你光把部门信息提出来还是不够的,还需要建立关联
然后让员工信息表关联该表,如何关联,即foreign key
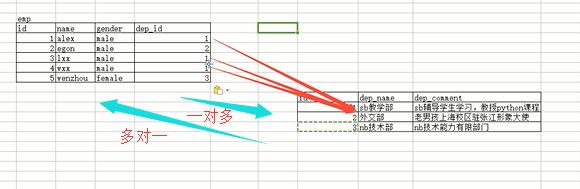
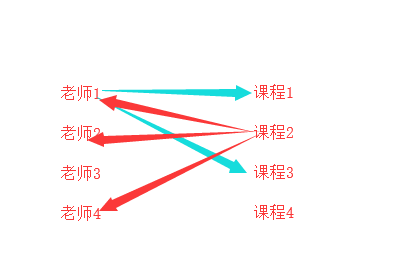
在解释一下:数据要拆到不同表里面存着,你要站在两个表的角度来看两者之间的关系,你站在部门表的角度看,一个部门包含多个员工,站在员工表看,多个员工属于一个部门,以我们上课来举个例子看:现在的多个老师可以讲一个课程python,那么老师对于课程表来说就是多对一个关系,那这是不是就是最终关系呢,我们还需要站在课程表的角度来看,多个课程能不能被一个老师教啊,这个看业务场景,你看咱们学校就不行,讲python的只能讲python,但是我们上的小学,初中,高中是不是多个课程可以被一个老师教啊,所以从老男孩的业务来看,课程表对老师表是一对一的,即便是你多个老师可以讲这一门课程,但是这一门可能对应的那几个老师只能讲这一门,不能讲其他的课程,所以他们只是单纯的多对一的关系,多个老师对应一门课程,但是小学、初中、高中的业务,多个老师可以教一门课程,同样这多个老师每个老师又可以教多门课程,那么从课程表角度来看,多个课程也能从属一个老师,所以是多对多的关系:看下图
二 一对多的关系
我们在看看员工和部门这个多对一的关系表:

如果我们没有做强制的约束关系,那么在员工表里面那个部门id可以随便写,即便是部门表里面没有这个id号,它也是可以写的,但是这样写就错了,因为业务不允许,并且这个数据完全没用,根本就不存在这个部门,哪里来的这个部门的员工呢,对不对,所以要做一个硬性的关系,你员工里面的部门id一定要来自于部门表的id字段。怎么来做这个硬性关系呢,通过外键foreign key,怎么叫外键,就是跟外部的一个表进行关联,建立这种硬性的关系,就叫做外键,就像我们上面这两个表似的,左边的员工表有一个字段(部门id字段)来自于右边的部门表,那么我们就可以通过数据库在员工表的部门id字段加上一个foreign key,外键关联到右边部门表的id字段,这样就建立了这种硬性的关系了,之前我们是看着两张表之间有关系,但是没有做强制约束,还是两张普通的表,操作其中任何一个,另外一个也没问题,但是加上了这种强制关系之后,他们两个的操作也就都关联起来了,具体操作看下面的代码:
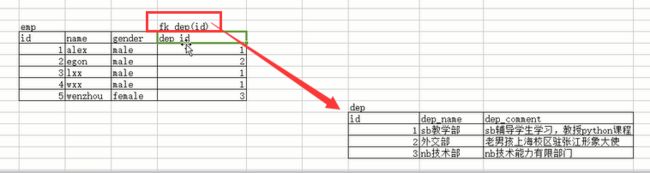
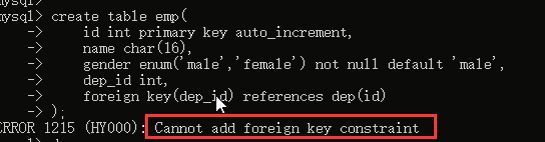
部门表是被关联的表,员工表是关联表,也就是员工表要关联部门表,对吧,如果我们先创建员工表,在创建员工表的时候加外键关系,就会报错,看效果:
所以我们应该先建立部门表,也就是被关联的表,因为关联表中的字段的数据是来根据被关联表的被关联字段的数据而来的。
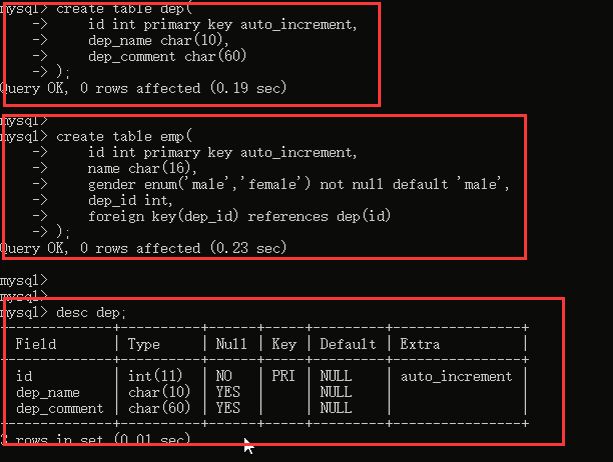
然后看一下表结构:
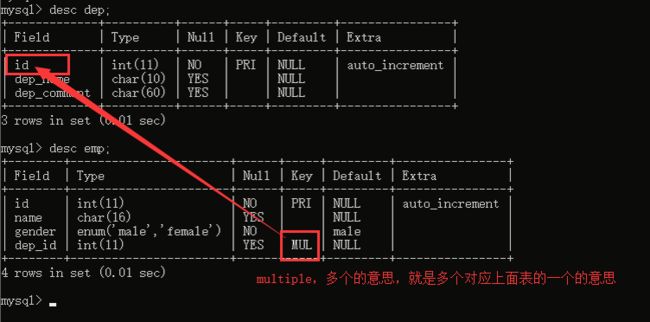
表创建好了,如果我们直接给员工表插入几条数据,那么会报错,因为,你的部门还没有呢,你的员工表里面的那个dep_id外键字段的数据从何而来啊?看效果:

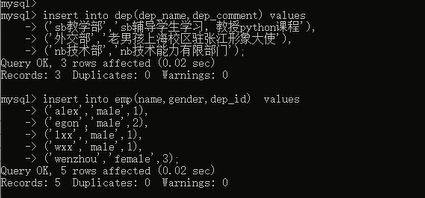
然后我们先插入部门的数据,然后再插入员工的数据:
然后查看一下数据:
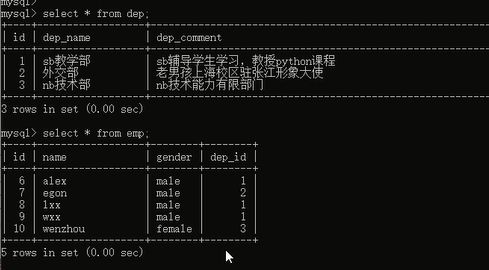
数据没问题了,但是你有没有发现一个问题,就是员工表的id从6开始的,因为我们前面插入了5条数据,失败了,虽然失败了,但是id自动增长了。
所以有引出一个问题,如果想让id从头开始,我们可以把这些数据删掉,用delete的删除是没用的,需要用truncate来删除,这是清空表的意思。
看一下delete:
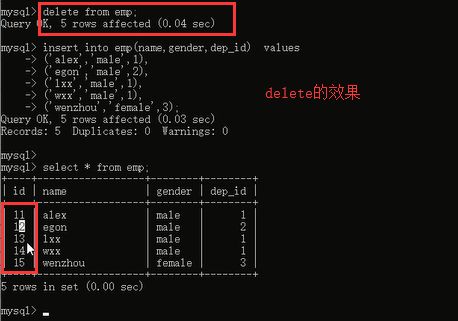
delete不是用来清空表的,是用来删除一些你想删除的符合某些条件的数据,一般用在delete from tb1 where id>20;这样的,如果要清空表,让id置零,使用truncate
再看一下truncate:
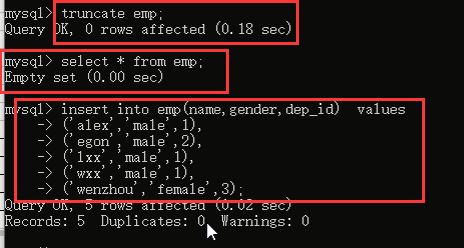
然后查看一下数据看看:
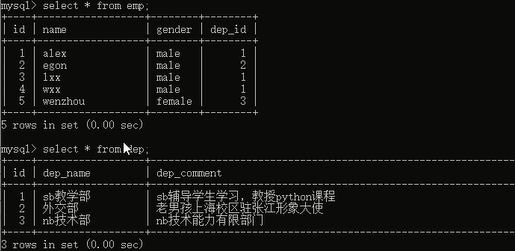
我们来看一下,如果对关联的表进行修改的话会有什么效果,首先我们先修改一下部门表的id字段中的某个数据,将id的值改一下

报错了,那我们改一改员工表里面的外键字段dep_id,改它的值来试试:

还是报错了!我靠,那我试试删除一下试试,解散一个部门,删除他的数据:

报错了!不让你删除,因为你删除之后,员工表里面的之前属于这个部门的记录找不到对应的部门id了,就报错了
那我删除一下员工表里面关于这个要被解散的部门的员工数据,按理说是不是应该没问题啊,来看看效果:
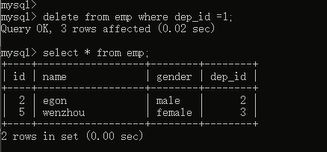
删除成功了,完全没问题啊,那么关于这个部门的所有员工数据都被删除了,也就是说,你这个部门下面没有任何员工了,没有了限制了相当于,所以我们尝试一下看看现在能不能删除部门表里面的这个部门了
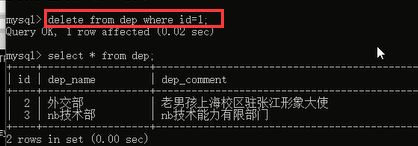
ok~可以删除了
虽然我们修改部门表或者员工表里面的部门id,但是我们可以删除,但是删除这个被关联表部门表的数据的时候由于有关联关系的存在,所以删除的时候也很麻烦,要先将关联数据删除,才能删除被关联的表的数据。
刚才我们删除了教学部这个部门,当我们想解散这个部门的时候,首先想到的是什么,是不是我们的部门表,想直接操作部门表进行删除,对吧,想修改部门的id号,是不是首先想到的也是操作部门表进行修改,把部门的id修改了,但是我们由于关联关系的存在,不得不考虑关联表中的数据,对不对,所以操作就变得很麻烦了,有没有简单的方法呢?我们想做的是不是说,我想删除一个部门,直接删除部门表里面的数据就行了,是不是达到这个效果,删除一个部门的时候,与这个部门关联的所有的员工表的那些数据都跟着删除,或者我更新部门表中一个部门的id号,那么关联的员工表中的关联字段的部门id号跟着自动更新了,
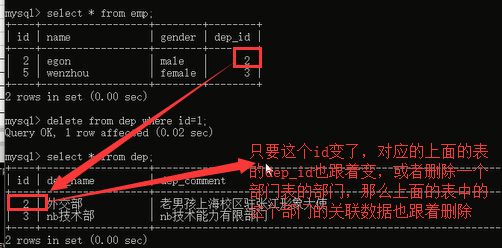
看一下解决办法:
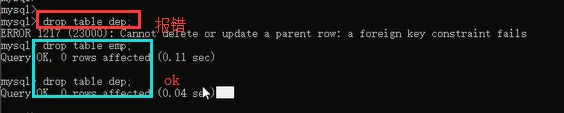
首先我们把之前的两个表删除了,能先删除部门表吗?如果删了部门表,你的员工表是不是找不到对应关系了,你说会不会报错啊,所以先删除员工表:
1.先删除关联表,再删除被关联表,然后我们重新建立两个表,然后建表的时候说一下咱们的解决方案。
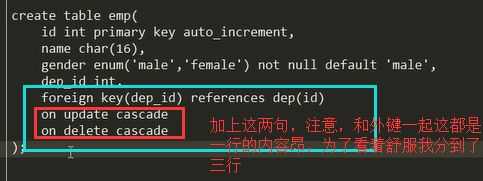
2.重建表,我们现在要解决的问题是:我们要达到一个在做某个表(被关联表)更新或者删除操作的时候,关联表的数据同步的进行更新和删除的效果,所以我们在建表的时候,可以加上两个功能:同步更新和同步删除:看看如何实现:在建立关联关系的时候,加上这两句: on delete cascade和 on update cascade
然后把我们之间的表和数据都插入进去:然后再进行更新删除操作:
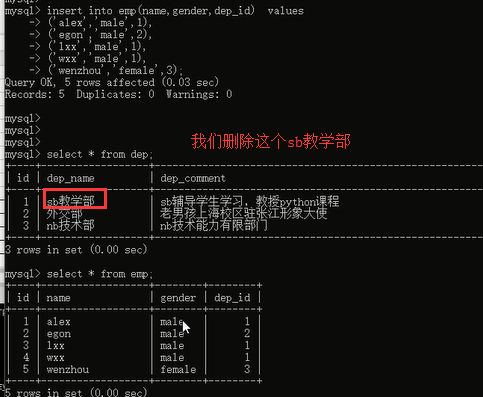
然后我们再直接删除部门表里面的数据的时候,你看看结果:
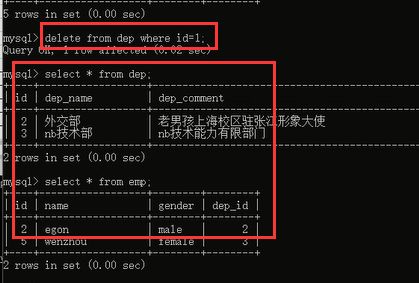
成功了,并且员工表里面关联部门表id的数据也都删除了,是不是达到了我们刚才想要实现的效果呀
下面我们来看一下更新操作,我们之前说更新一个部门的id号,注意一个问题昂,我更新部门的名称,你说有影响吗?肯定没有啊,因为我员工表并不是关联的部门的名称字段,而是关联的部门的id字段,你改部门名称没关系,我通过你的id照样找到你,但是你如果改了id号,那么我员工表里面的id号和你不匹配了,我就没法找到你,所有当你直接更新部门的id的时候,我就给你报错了,大哥,你想改的是关联字段啊,考虑一下关联表的数据们的感受行不行。我们来看一下加上 on update cascade之后的效果:
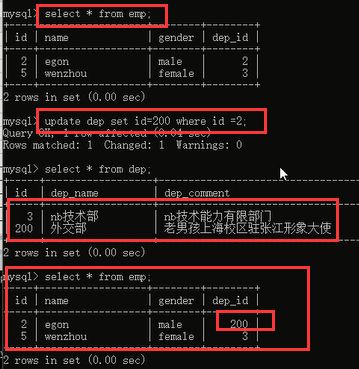
将部门id为2的部门的id改成了200,完全ok,员工表里面之前关联id为2的部门的数据都改成了关联id为200的数据了。说明同步更新也是没问题的。
我们总结一下foreign key的下面几个约束作用:
1、先要建立被关联的表才能建立关联表
2、在插入数据记录的时候,要先想被关联表中插入数据,才能往关联表里面插入数据
3、更新或者删除数据的时候,都需要考虑关联表和被关联表的关系
解决方案:
a.删除表的时候,先删除关联表,再删除被关联表
b.重建表的时候,在加外键关联的时候加上这两句:on delete cascade 和 on update cascade
简单测试:
表类型必须是innodb存储引擎,且被关联的字段,即references指定的另外一个表的字段,必须保证唯一
create table department(
id int primary key,
name varchar(20) not null
)engine=innodb;
#dpt_id外键,关联父表(department主键id),同步更新,同步删除
create table employee(
id int primary key,
name varchar(20) not null,
dpt_id int,
constraint fk_name foreign key(dpt_id) #这句话的意思是constraint 是声明我们要建立一个约束啦,fk_name是约束的名称,foreign key是约束的类型,整体的意思是,我要创建一个名为fk_name的外键关联啦,这个constraint就是一个声明的作用,在创建外键的时候不加constraint fk_name也是没问题的。先理解一下就行了,后面我们会细讲的。
references department(id)
on delete cascade
on update cascade
)engine=innodb;
#先往父表department中插入记录
insert into department values
(1,'欧德博爱技术有限事业部'),
(2,'艾利克斯人力资源部'),
(3,'销售部');
#再往子表employee中插入记录
insert into employee values
(1,'chao',1),
(2,'alex1',2),
(3,'alex2',2),
(4,'alex3',2),
(5,'李坦克',3),
(6,'刘飞机',3),
(7,'张火箭',3),
(8,'林子弹',3),
(9,'加特林',3)
;
#删父表department,子表employee中对应的记录跟着删
mysql> delete from department where id=3;
mysql> select * from employee;
+----+-------+--------+
| id | name | dpt_id |
+----+-------+--------+
| 1 | chao | 1 |
| 2 | alex1 | 2 |
| 3 | alex2 | 2 |
| 4 | alex3 | 2 |
+----+-------+--------+
#更新父表department,子表employee中对应的记录跟着改
mysql> update department set id=22222 where id=2;
mysql> select * from employee;
+----+-------+--------+
| id | name | dpt_id |
+----+-------+--------+
| 1 | chao | 1 |
| 3 | alex2 | 22222 |
| 4 | alex3 | 22222 |
| 5 | alex1 | 22222 |
+----+-------+--------+
一对多的内容大致就说完了,我们看一下多对多的关系
三 多对多关系
我们上面大致提了一下多对多的关系,下面我们通过一个例子来细讲一下,这个例子就用-->书和出版社的关系来看吧:
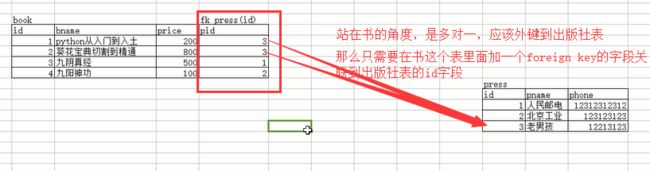
上面是一对多没问题,我们再来看看书和作者的关系:

一本书可以有多个作者,一个作者可不可以写多本书,两者之间是不是站在谁的角度去看都是一个一对多的关系啊,那这就是多对多的关系,那我们创建表的时候,需要将两个表都加一个foreign key的字段,但是你添加字段的时候,你想想,能直接给两个表都这一个foreign key字段吗,两个谁先创建,谁后创建,是不是都不行啊,两个表的创建是不是都依赖着另外一张表啊,所以我们之前的加外键字段的方式对于这种多对多的关系是不是就不好用啦,怎么办,我们需要通过第三张表来缓和一下两者的关系,通过第三张表来创建双方的关系
我们先创建书表和作者表,然后创建第三张表,第三张表就需要有一个字段外键关联书表,还有一个字段外键关联作者表

然后我们如果想查一下alex出了哪些书,你可以怎么查,想一下,首先在author作者表里面找一个alex的id是多少,alex的id为2,然后找一个第三张表里面author_id为2的数据中book的id,然后拿着这些book的id去book表里面找对应的book名称,你就能够知道alex这个作者出了哪几本书了,对不对,这就是一个多表查询的一个思路
来我们创建一下试试看(学了foreign key,这个东西是不是很简单啊,两个foreign key嘛~~)
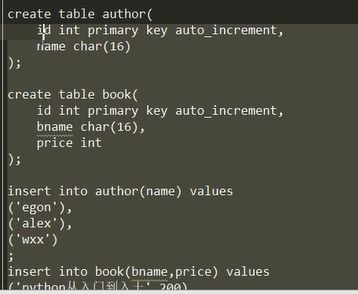
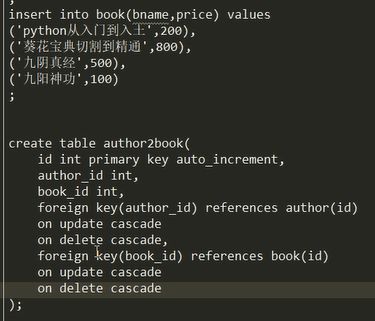
建立前两张表,插入数据,建立第三张表
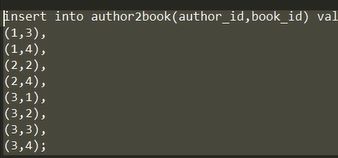
然后给第三张表插入一些数据:
查看一下数据:
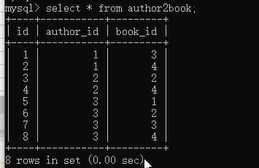
数据就创建好了,多对多就讲完了~~~~
四 一对一关系
我们来以咱们学校的学生来举例:
最开始你只是一个客户,可能还处于咨询考虑的阶段,还没有转化为学生,也有的客户已经转换为学生了,说白了就是你交钱了,哈哈
那我们来建两个表:客户表和学生表
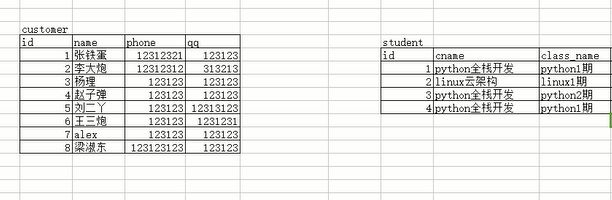
客户表里面存着客户的信息,学生表里面存着客户转换为学生之后的学生信息,那么这两个表是什么关系呢?你想一下,学生是不是从客户转换过来的,那么一个学生能对应多个用户的信息吗?当然是不能的,那么一个客户能对应多个学生的信息吗,当然也是不能的,那么他们两个就是一对一的关系,那这个关系该怎么建立呢?我们知道通过外键可以建立关系,如果在客户表里面加外键关联学生表的话,那说明你的学生表必须先被创建出来,这样肯定是不对的,因为你的客户表先有的,才能转换为学生,那如果在学生表加外键关联客户表的话,貌似是可以的,不过一个学生只对应一个客户,那么这个关系怎么加呢,外键我们知道是一对多的,那怎么搞?我们可以把这个关联字段设置成唯一的,不就可以了吗,我既和你有关联,我还不能重复,那就做到了我和你一对一的关联关系。
表关系的总结
分析步骤:
#1、先站在左表的角度去找
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
#2、再站在右表的角度去找
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
#3、总结:
#多对一:
如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
#多对多
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
#一对一:
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
多对一或一对多
#一对多或称为多对一
三张表:出版社,作者信息,书
一对多(或多对一):一个出版社可以出版多本书
关联方式:foreign key
一对多的简单示例
=====================多对一=====================
create table press(
id int primary key auto_increment,
name varchar(20)
);
create table book(
id int primary key auto_increment,
name varchar(20),
press_id int not null,
foreign key(press_id) references press(id)
on delete cascade
on update cascade
);
insert into press(name) values
('北京工业地雷出版社'),
('人民音乐不好听出版社'),
('知识产权没有用出版社')
;
insert into book(name,press_id) values
('九阳神功',1),
('九阴真经',2),
('九阴白骨爪',2),
('独孤九剑',3),
('降龙十巴掌',2),
('葵花宝典',3)
多对多
#多对多
三张表:出版社,作者信息,书
多对多:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
关联方式:foreign key+一张新的表
多对多简单示例
=====================多对多=====================
create table author(
id int primary key auto_increment,
name varchar(20)
);
#这张表就存放作者表与书表的关系,即查询二者的关系查这表就可以了
create table author2book(
id int not null unique auto_increment,
author_id int not null,
book_id int not null,
constraint fk_author foreign key(author_id) references author(id)
on delete cascade
on update cascade,
constraint fk_book foreign key(book_id) references book(id)
on delete cascade
on update cascade,
primary key(author_id,book_id)
);
#插入四个作者,id依次排开
insert into author(name) values('egon'),('alex'),('yuanhao'),('wpq');
#每个作者与自己的代表作如下
1 egon:
1 九阳神功
2 九阴真经
3 九阴白骨爪
4 独孤九剑
5 降龙十巴掌
6 葵花宝典
2 alex:
1 九阳神功
6 葵花宝典
3 yuanhao:
4 独孤九剑
5 降龙十巴掌
6 葵花宝典
4 wpq:
1 九阳神功
insert into author2book(author_id,book_id) values
(1,1),
(1,2),
(1,3),
(1,4),
(1,5),
(1,6),
(2,1),
(2,6),
(3,4),
(3,5),
(3,6),
(4,1)
;
中间那一张存放关系的表,对外关联的字段可以联合唯一
一对一
#一对一
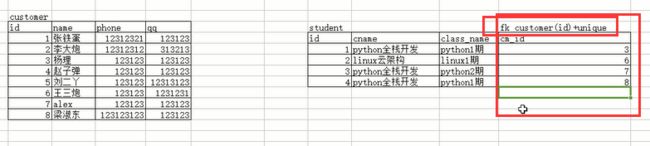
两张表:学生表和客户表
一对一:一个学生是一个客户,一个客户有可能变成一个学校,即一对一的关系
关联方式:foreign key+unique
一对一简单示例
#一定是student来foreign key表customer,这样就保证了:
#1 学生一定是一个客户,
#2 客户不一定是学生,但有可能成为一个学生
create table customer(
id int primary key auto_increment,
name varchar(20) not null,
qq varchar(10) not null,
phone char(16) not null
);
create table student(
id int primary key auto_increment,
class_name varchar(20) not null,
customer_id int unique, #该字段一定要是唯一的
foreign key(customer_id) references customer(id) #外键的字段一定要保证unique
on delete cascade
on update cascade
);
#增加客户
insert into customer(name,qq,phone) values
('李飞机','31811231',13811341220),
('王大炮','123123123',15213146809),
('守榴弹','283818181',1867141331),
('吴坦克','283818181',1851143312),
('赢火箭','888818181',1861243314),
('战地雷','112312312',18811431230)
;
#增加学生
insert into student(class_name,customer_id) values
('脱产3班',3),
('周末19期',4),
('周末19期',5)
;
一对一其他例子
例一:一个用户只有一个博客
用户表:
id name
1 egon
2 alex
3 wupeiqi
博客表
fk+unique
id url name_id
1 xxxx 1
2 yyyy 3
3 zzz 2
例二:一个管理员唯一对应一个用户
用户表:
id user password
1 egon xxxx
2 alex yyyy
管理员表:
fk+unique
id user_id password
1 1 xxxxx
2 2 yyyyy
查看所有外键的名称的方法: select REFERENCED_TABLE_SCHEMA,REFERENCED_TABLE_NAME,REFERENCED_COLUMN_NAME,table_name,CONSTRAINT_NAME from information_schema.key_column_usage; #包含我们创建外键的时候,mysql帮我们自动生成的外键名称。
外键这个key的名称我们可以通过constraint来指定:
删除外键关联,添加外键字段并添加外键关联:
mysql> desc e3; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | xx | char(11) | YES | | NULL | | | ee_id | int(11) | YES | MUL | NULL | | +-------+----------+------+-----+---------+----------------+ 3 rows in set (0.10 sec) mysql> alter table e3 drop ee_id; #直接删除外键字段是不可以的 ERROR 1553 (HY000): Cannot drop index 'ee_id': needed in a foreign key constraint mysql> alter table e3 drop foreign key e3_ibfk_1; #通过上面的方法找到这个表的外键字段,然后先解除外键字段的关系,才能删除外键字段 Query OK, 0 rows affected (0.11 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc e3; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | xx | char(11) | YES | | NULL | | | ee_id | int(11) | YES | MUL | NULL | | +-------+----------+------+-----+---------+----------------+ 3 rows in set (0.10 sec) #解除了外键关系之后,是可以随意插入数据的,就没有了外键的约束 #但是表结构的key那一项里面还是显示MUL,不过没关系,已经没有外键约束的效果了,大家可以插入一条原来那个关联表的字段中不存在的数据来试一试,肯定是没问题的,我没有保存下来,就不给大家演示啦,然后然后我们就可以删除这个外键字段了 mysql> alter table e3 drop ee_id; Query OK, 0 rows affected (0.65 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc e3; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | xx | char(11) | YES | | NULL | | +-------+----------+------+-----+---------+----------------+ 2 rows in set (0.10 sec)
#看添加外键字段和外键关联:
首先创建一个e2表,包含一个id字段,别忘了id字段最少也要是unique属性,primary key当然最好啦
mysql> alter table e3 add ee_id int;
Query OK, 0 rows affected (0.64 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table e3 add foreign key(ee_id) references e2(id);
Query OK, 0 rows affected (0.83 sec)
Records: 0 Duplicates: 0 Warnings: 0
#添加关联删除和关联更新的操作:当删除主表数据的时候,从表中有关的数据都跟着删除,当主表的关系字段修改的时候,从表对应的关系字段的值也更着更新。
alter table 从表 add foreign key(从表字段) references 主表(主表字段) on delete cascade on update cascade;
#另外,能够作为主表(也就是多对一关系的那个一表的被关联的那个字段)的关系字段的约束最少要是唯一的unique属性。
外键约束有三种约束模式(都是针对父表的约束):
模式一: district 严格约束(默认的 ),父表不能删除或者更新已经被子表数据引用的记录
模式二:cascade 级联模式:父表的操作,对应的子表关联的数据也跟着操作 。
模式三:set null:置空模式,父表操作之后,子表对应的数据(外键字段)也跟着被置空。
通常的一个合理的约束模式是:删除的时候子表置空;更新的时候子表级联。
指定模式的语法:foreign key(外键字段)references 父表(主键字段)on delete 模式 on update 模式;
注意:删除置空的前提条件是 外键字段允许为空,不然外键会创建失败。
外键虽然很强大,能够进行各种约束,但是外键的约束降低了数据的可控性和可拓展性。通常在实际开发时,很少使用外键来约束。