Python学习系列之内置函数总结
module __builtin__
1. abs()
描述:返回数字的绝对值,不改变数据类型和数据精度
语法:abs( x )
参数:x -- 数值表达式
返回值:x(数字)的绝对值
2. all()
描述:all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。元素除了是 0、空、None、False 外都算 True
语法:all(iterable)
参数:iterable -- 元组或列表
返回值:如果iterable的所有元素不为0、''、False或者iterable为空,all(iterable)返回True,否则返回False;注意:空元组、空列表返回值为True。
3. any()
描述:any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。也就是可迭代参数中的元素有一个为True则返回True,否则返回False。元素除了是 0、空、None、FALSE 外都算 TRUE
语法:any(iterable)
参数:iterable -- 元组或列表
返回值:如果都为空、0、false,则返回false,如果不都为空、0、false,则返回true
4. basestring()
描述:basestring() 方法是 str 和 unicode 的超类(父类),也是抽象类,因此不能被调用和实例化,但可以被用来判断一个对象是否为 str 或者 unicode 的实例,isinstance(obj, basestring) 等价于 isinstance(obj, (str, unicode))。
语法:basestring()
参数:无
返回值:无
5. bin()
描述:bin() 返回一个整数 int 或者长整数 long int 的二进制表示。
语法:bin(x)
参数:x -- int 或者 long int 数字
返回值:字符串
6. bool()
描述:bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。bool 是 int 的子类。转换原则是 0、空、None、FALSE 是Flase,其他的是True。
空列表,空集合,空元组,空字典都是False,否则是True。
语法:class bool([x])
参数:x -- 要进行转换的参数。
返回值:返回 Ture 或 False。
7. bytearray()
描述:bytearray() 方法返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256(一个字节存储的内容大小)。
语法:class bytearray([source[, encoding[, errors]]])
参数:
- 如果 source 为整数,则返回一个长度为 source 的初始化数组(全0);
- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数(字符串必须是长度为1的字符,然后把字符转为ASCII码);
- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
- 如果没有输入任何参数,默认就是初始化数组为0个元素。
返回值:返回 Ture 或 False。
8. callable()
描述:callable() 函数用于检查一个对象是否是可调用的。如果返回 True,object 仍然可能调用失败;但如果返回 False,调用对象 object 绝对不会成功。
对于函数、方法、lambda 函式、 类以及实现了 __call__ 方法的类实例, 它都返回 True。
魔术方法:
__call__使实例能够像函数一样被调用(可调用对象),同时不影响实例本身的生命周期,可以用来改变实例的内部成员的值(改变类实例的状态)。 x() 与 x.__call__() 等同。
__init__ 函数的意义等同于类的构造器(同理,__del__等同于类的析构函数)
语法:callable(object)
参数:object -- 对象
返回值:可调用返回 True,否则返回 False。
9. chr()
描述:chr() 用一个范围在 range(256)内的(就是0~255)整数作参数(ASCII码对应的数值),返回一个对应的字符。
语法:chr(i)
参数:i -- 可以是10进制也可以是16进制(0x或0X)的形式的数字。
返回值:返回值是当前整数对应的 ASCII 字符。
10. classmethod()
描述:classmethod 修饰符对应的函数不需要实例化,不需要 self 参数,但第一个参数需要是表示自身类的 cls 参数(需要传入类本身作为参数,否则访问出错),可以来调用类的属性,类的方法,实例化对象等。将普通方法转为类方法,作用同装饰器@classmethod。在类中调用,将实例方法转为类方法。
语法:classmethod(function)
参数:function -- 类中实例方法。
返回值:返回普通函数(实例方法)的类方法。
11. cmp()
描述:cmp(x,y) 函数用于比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
数字:数字大小。
字符串:每个字符的ASCII码的大小。
语法:cmp(x, y)
参数:
- x -- 数值表达式。
- y -- 数值表达式。
返回值:如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
12. compile()
描述:compile() 函数将一个字符串编译为字节代码。然后使用exec, eval, single函数执行。
语法:compile(source, filename, mode[, flags[, dont_inherit]])
参数:
- source -- 字符串或者AST(Abstract Syntax Trees)对象。。
- filename -- 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
- mode -- 指定编译代码的种类。可以指定为 exec, eval, single。
- flags -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。。
- flags和dont_inherit是用来控制编译源码时的标志
返回值:返回表达式执行结果。
13. complex()
描述:complex() 函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。字符串必须是“j”,不能是i。
z=a+bi(a,b均为实数)的数称为复数,其中a称为实部,b称为虚部,i称为虚数单位。当z的虚部等于零时,常称z为实数;当z的虚部不等于零时,实部等于零时,常称z为纯虚数。
语法:class complex([real[, imag]])
参数:
- real -- int, long, float或字符串;
- imag -- int, long, float;
返回值:返回一个复数。即使虚部为0(实数),格式也是虚数。
14. delattr()
描述:delattr 函数用于删除类实例对象的属性。再次访问会出错。
delattr(x, 'foobar') 相等于 del x.foobar。
语法:delattr(object, name)
参数:
- object -- 对象。
- name -- 必须是对象的属性。
返回值:无。
访问报错:
Traceback (most recent call last):
File "test.py", line 22, in
print('z = ',point1.z)
AttributeError: Coordinate instance has no attribute 'z' 15. dict()
描述:dict() 函数用于创建一个字典。
语法:
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)参数:
- **kwargs -- 关键字
- mapping -- 元素的容器。
- iterable -- 可迭代对象。
返回值:返回一个字典。
>>>dict() # 创建空字典
{}
>>> dict({'three': 3, 'four': 4}) # 传一个字典
>>> dict(a='a', b='b', t='t') # 传入关键字
{'a': 'a', 'b': 'b', 't': 't'}
>>> dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典
{'three': 3, 'two': 2, 'one': 1}
>>> dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典:包含一个或多个元组的列表
{'three': 3, 'two': 2, 'one': 1}16. dir()
描述:dir() 函数不带参数时,返回当前范围(当前模块)内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息
语法:dir([object])
参数:object -- 对象、变量、类型
返回值:返回模块的属性列表
>>>dir() # 获得当前模块的属性列表
['__builtins__', '__doc__', '__name__', '__package__', 'arr', 'myslice']
>>> dir([ ]) # 查看列表的方法
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__delslice__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getslice__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__setslice__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']17. divmod()
描述:python divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
在 python 2.3 版本之前不允许处理复数。
语法:divmod(a, b)
参数:
- a: 数字
- b: 数字
返回值:包含商和余数的元组。
18. enumerate()
描述:enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python 2.3. 以上版本可用,2.6 添加 start 参数。
语法:enumerate(sequence, [start=0])
参数:
- sequence -- 一个序列、迭代器或其他支持迭代对象。
- start -- 下标起始位置。
返回值:返回 enumerate(枚举) 对象。
19. eval()
描述:eval() 函数用来执行一个字符串表达式,并返回表达式的值。
语法:eval(expression[, globals[, locals]])
参数:
- expression -- 表达式。
- globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值:返回表达式计算结果。
20. execfile()
描述:execfile() 函数可以用来执行一个文件。
语法:execfile(filename[, globals[, locals]])
参数:
- filename -- 文件名。
- globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值:返回文件内内容的执行结果。
python3 删去了 execfile(),代替方法如下:
with open('test1.py','r') as f:
exec(f.read())21. file()
描述:file() 函数用于创建一个 file 对象,它有一个别名叫 open(),更形象一些,它们是内置函数。参数是以字符串的形式传递的。
file是类,open才是内置函数。
语法:file(name[, mode[, buffering]])
参数:
- name -- 文件名
- mode -- 打开模式
- buffering -- 0 表示不缓冲,如果为 1 表示进行行缓冲,大于 1 为缓冲区大小。
返回值:文件对象。
22. filter()
描述:filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判别,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
注意: Pyhton2.7 返回列表,Python3.x 返回迭代器对象。 filter 类对象。filter 类实现了 __iter__ 和 __next__ 方法, 可以看成是一个迭代器, 有惰性运算的特性, 相对 Python2.x 提升了性能, 可以节约内存。
语法:filter(function, iterable)
参数:
- function -- 判断函数。
- iterable -- 可迭代对象。
返回值:返回列表。
判断整数:math.sqrt(x) % 1 == 0
23. float()
描述:float() 函数用于将整数和字符串转换成浮点数。(类)
语法:class float([x])
参数:x -- 整数或字符串
返回值:返回浮点数。
24. format()
描述:Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
语法:str.format(参数)
参数:需要格式化的参数(字符串,整数,浮点数)。
返回值:格式化后的字符串。
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
# 设置参数
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
# 传入对象
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的格式化数字:
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | |
|
进制 |
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号 {} 来转义大括号,如下实例:
print ("{} 对应的位置是 {{0}}".format("runoob"))
25. frozenset()
描述:frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
语法:class frozenset([iterable]) 类
参数:iterable -- 可迭代的对象,比如列表、字典、元组等等。
返回值:返回新的 frozenset 对象,如果不提供任何参数,默认会生成空集合。
返回不可变集合。
26. getattr()
描述:getattr() 函数用于返回一个对象属性值。
语法:getattr(object, name[, default])
参数:
- object -- 对象。
- name -- 字符串,对象属性(名)。
- default -- 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
返回值:返回对象属性值。
27. globals()
描述:globals() 函数会以字典类型返回当前位置的全部全局变量。
语法:globals()
参数:无。
返回值:返回一个全局变量的字典,除了内置变量,还包括所有导入的变量。
{'__builtins__': , '__name__': '__main__', '__doc__': None, 'a': 'runoob', '__package__': None} Python里只有2种作用域:全局作用域和局部作用域。全局作用域是指当前代码所在模块的作用域,局部作用域是指当前函数或方法所在的作用域。局部作用域里的代码可以读外部作用域(包括全局作用域)里的变量,但不能更改它。如果想更改它,这里就要使用global关键字了。
具体来看分以下几种情况:
1. 当你直接在局部域读取全局变量,可以直接使用。
2. 当你直接在局部域修改全局变量分两种情况:但是我们一定无法直接修改全局变量。
(1)比如a+=1的情况,是必须要首先声明变量才能执行。所以会报错,未声明该变量。
(2)比如a=1的情况,则系统认为你声明a局部变量,所以不会报错。但并不是修改全局变量。
3. 要想在局部域修改全局变量,可以使用global关键字首先声明该变量,然后修改。
4. 如果提前在局部域声明了该全局变量的同名变量,则覆盖全局变量(包括读取和修改)。
在Python 2.x中,闭包只能读外部函数的变量,而不能改写它。为了解决这个问题,Python 3.x引入了nonlocal关键字,在闭包内用nonlocal声明变量,就可以让解释器在外层函数中查找变量名。
注意:关键字nonlocal:是python3.X中出现的,所以在python2.x中无法直接使用.
28. hasattr()
描述:hasattr() 函数用于判断对象是否包含对应的属性。
语法:hasattr(object, name)
参数:
- object -- 对象。
- name -- 字符串,属性名。
返回值:如果对象有该属性返回 True,否则返回 False。
29. hash()
描述:hash() 用于获取取一个对象(字符串或者数值等)的哈希值。
语法:hash(object)
参数:
- object -- 对象;
返回值:返回对象的哈希值。hash 值都是固定长度的。
可以应用于数字、字符串和对象,不能直接应用于 list、set、dictionary。
在 hash() 对对象使用时,所得的结果不仅和对象的内容有关,还和对象的 id(),也就是内存地址有关。
30. help()
描述:help() 函数用于查看函数或模块用途的详细说明。
语法:help([object])
参数:
- object -- 对象;
返回值:返回对象帮助信息。
可以直接传入字符串,比如'sys','print'。
还可以直接传入类实例对象,返回该实例对象对应类的帮助信息,直接传入类实例对象的属性,返回该实例对象对应类属性的帮助信息。
31. hex()
描述:hex() 函数用于将10进制整数转换成16进制,以字符串形式表示。
语法:hex(x)
参数:
- x -- 10进制整数
返回值:返回16进制数,以字符串形式表示。
32. id()
描述:id() 函数用于获取对象的内存地址。
语法:id([object])
参数:
- object -- 对象(包括数字,字符串,布尔变量,类,类示例等任何对象)。
返回值:返回对象的内存地址。
33. input()
描述:
Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。
Python2.x 中 input() 相等于 eval(raw_input(prompt)) ,用来获取控制台的输入。raw_input() 将所有输入作为字符串看待,返回字符串类型。而 input() 在对待纯数字输入时具有自己的特性,它返回所输入的数字的类型( int, float )。
注意:Python2 input() 和 raw_input() 这两个函数均能接收 字符串 ,但 raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
除非对 input() 有特别需要,否则一般情况下我们都是推荐使用 raw_input() 来与用户交互。
注意:python3 里 input() 默认接收到的是 str 类型,不要求是合法python表达式。
语法:input([prompt])
参数:
- prompt: 提示信息
返回值:返回输入内容。
34. int()
描述:int() 函数用于将一个字符串或数字转换为整型。对于浮点数向下取整。
语法:class int(x, base=10)
参数:
- x -- 字符串或数字。
- base -- 进制数,默认十进制。(指定输入的x的进制,输出都是十进制)
返回值:返回整型数据。不传入参数时,得到结果0。
35. isinstance()
描述:isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
语法:isinstance(object, classinfo)
参数:
- object -- 实例对象。
- classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组(多个选项)。
返回值:如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。
type(A()) == A
type()函数返回对象类型,但不考虑父类(继承)关系。
基本类型包括:int,float,bool,complex,str(字符串),list,dict(字典),set,tuple。
除了基本类型就是类(系统类或自定义)。
36. issubclass()
描述:issubclass() 方法用于判断参数 class 是否是类型参数 classinfo 的子类。
语法:issubclass(class, classinfo)
参数:
- class -- 类。
- classinfo -- 类。
返回值:如果 class 是 classinfo 的子类返回 True,否则返回 False。
两个类之间的比较。
37. iter()
描述:iter() 函数用来生成迭代器。
语法:iter(object[, sentinel])
参数:
- object -- 支持迭代的集合对象。
- sentinel -- 如果传递了第二个参数,则参数 object 必须是一个可调用的对象(如,函数),此时,iter 创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用 object。
返回值:迭代器对象。
38. len()
描述:len() 方法返回对象(字符、列表、元组、字典、集合等)长度或项目个数。
语法:len( s )
参数:
- s -- 对象(字符、列表、元组、字典、集合等)。
返回值:返回对象长度。
39. list()
描述:list() 方法用于将元组转换为列表。(元组和列表相同包括索引和访问,除了不能修改。而集合和字典都无法使用索引进行访问)
注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中。
语法:list( tup )
参数:
- tup -- 要转换为列表的元组。
返回值:返回列表。
40. locals()
描述:locals() 函数会以字典类型返回当前位置(当前模块或下层局部域,比如类内,函数内等)的全部局部变量。
语法:locals()
参数:
- 无
返回值:返回字典类型的局部变量。
函数的话包括函数的形参及所有定义的其他变量。
41. long()
描述:long() 函数将数字或字符串转换为一个长整型。
语法:class long(x, base=10)
参数:
- x -- 字符串或数字。
- base -- 可选,进制数,默认十进制。
返回值:返回长整型数。输出带有L结尾。
42. map()
描述:map() 会根据提供的函数对指定序列做映射(处理)。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
语法:map(function, iterable, ...)
参数:
- function -- 函数
- iterable -- 一个或多个序列
返回值:
Python 2.x 返回列表。
Python 3.x 返回迭代器。
# 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]43. max()
描述:max() 方法返回给定参数的最大值,参数可以为序列。
语法:max( x, y, z, .... )
参数:
- x -- 数值表达式。
- y -- 数值表达式。
- z -- 数值表达式。
返回值:返回给定参数的最大值。
1 . 列表数字
直接比较大小即可。
2. 字符串
>>> a='1,2,3,4'
>>> type(a) #类型为字符串
>>> max(a) #max 返回了最大值
'4' 3. 列表里面是元组构成元素
按照元素里面元组的第一个元素的排列顺序,输出最大值(如果第一个元素相同,则比较第二个元素,输出最大值)据推理是按ascii码进行排序的,类似于字符串的比较。4. 比较字典
比较字典里面的最大值,会输出最大的键值。因为键值不重复,所以不会出现元组重复的情况。(注:字典中如果键重复,后一个会覆盖前一个)
44. memoryview()
描述:memoryview() 函数返回给定参数的内存查看对象(Momory view)。
所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。
语法:memoryview(obj)
参数:
- obj -- 对象
返回值:返回元组列表。
Python2
>>>v = memoryview('abcefg')
>>> v[1]
'b'
>>> v[-1]
'g'
>>> v[1:4]
>>> v[1:4].tobytes()
'bce' Python3
>>>v = memoryview(bytearray("abcefg", 'utf-8'))
>>> print(v[1])
98
>>> print(v[-1])
103
>>> print(v[1:4])
>>> print(v[1:4].tobytes())
b'bce'
45. min()
描述:min() 方法返回给定参数的最小值,参数可以为序列。
语法:min( x, y, z, .... )
参数:
- x -- 数值表达式。
- y -- 数值表达式。
- z -- 数值表达式。
返回值:返回给定参数的最小值。
可变参数:多个数值或数值表达式,输出这几个参数的最小值
多个序列,以序列的形式输出,将单个序列的最小值组成一个序列。
46. next()
描述:next() 返回迭代器的下一个项目。
语法:next(iterator[, default])
参数:
- iterator -- 可迭代对象
- default -- 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。
返回值:返回迭代器的元素。
47. object()
描述:返回一个新的无特征对象,object是所有类的基类,有所有Python类实例的通用方法,该函数不接受任何参数。
注意:object没有__dict__方法,所以你不能给某个object类的实例分配任意属性。
其他类可直接设置属性:
#定义一个类A
>>> class A:
pass
>>> a = A()
>>> a.name = 'kim' # 能设置属性语法:o = object()
参数:无。
返回值:返回一个object的实例对象。
>>> dir(object)
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']python的__slots__设计是为了节省内存,也可以用于构造安全的类、如果一个类使用了__slots__那么它的属性就不再自由了。
slots__设置非自由属性
class person(object):
__slots__=('Name','Age')
def __init__(self,name,age):
self.Name=name #注意,__init__的执行在__slots__之后;所以就算在__init__方法里也是不能执行self.ID=007的。
self.Age=age
if__name__=='__main__':
p=person('jiangle',100)
p.ID=7 #这里会报错,由于我们使用了__slots__来声明属性,所以属性再也不是自由的了。__new__ and __init__
新式类都有一个__new__的静态方法,它的原型是object.__new__(cls[, ...])
cls是一个类对象,当调用C(*args, **kargs)来创建一个类C的实例时,python的内部调用是 :
- C.__new__(C, *args, **kargs)
- 然后返回值是类C的实例c
- 确认c是C的实例后
- python再调用C.__init__(c, *args, **kargs)来初始化实例c
所以调用一个实例c = C(2),实际执行的代码为:
c = C.__new__(C, 2)
if isinstance(c, C):
C.__init__(c, 23)#__init__第一个参数要为实例对象 object.__new__()创建的是一个新的,没有经过初始化的实例。当重写__new__方法时,可以不用使用装饰符@staticmethod指明它是静态函数,解释器会自动判断这个方法为静态方法。如果需要重新绑定C.__new__方法时,只要在类外面执行C.__new__ = staticmethod(yourfunc)就可以了。
此外,如果(新式)类中没有重写__new__()方法,即在定义新式类时没有重新定义__new__()时,Python默认是调用该类的直接父类的__new__()方法来构造该类的实例,如果该类的父类也没有重写__new__(),那么将一直按此规矩追溯至object的__new__()方法,因为object是所有新式类的基类。
__repr__ and __str__
print(someobj)会调用someobj.str(), 如果str没有定义,则会调用someobj.repr().
48. oct()
描述:oct() 函数将一个整数转换成8进制字符串。
语法:oct(x)
参数:
- x -- 整数。
返回值:返回8进制字符串。
以0开头。
49. open()
描述:open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
语法:open(name[, mode[, buffering]])
参数:
-
name : 一个包含了你要访问的文件名称的字符串值(文件路径)。
-
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
-
buffering : 如果 buffering 的值被设为 0,就不会有缓存。如果 buffering 的值取 1,访问文件时会缓存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的缓存区的缓冲大小。如果取负值,缓存区的缓冲大小则为系统默认。
返回值:返回file对象。
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
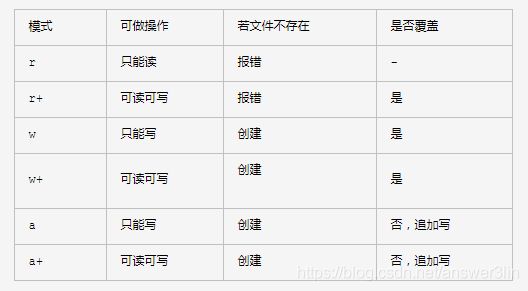
+多一个功能。
file 对象方法
-
file.read([size]):size 未指定则返回整个文件,如果文件大小 >2 倍内存则有问题,f.read()读到文件尾时返回""(空字串)。
-
file.readline():返回一行。
-
file.readlines([size]) :返回包含size行的列表, size 未指定则返回全部行。
-
for line in f: print line :通过迭代器访问。
-
f.write("hello\n"):如果要写入字符串以外的数据,先将他转换为字符串。
-
f.tell():返回一个整数,表示当前文件指针的位置(就是到文件头的比特数)。
-
f.seek(偏移量,[起始位置]):用来移动文件指针。
- 偏移量: 单位为比特,可正可负
- 起始位置: 0 - 文件头, 默认值; 1 - 当前位置; 2 - 文件尾
-
f.close() 关闭文件
50. ord()
描述:ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
语法:ord(c)
参数:c -- 字符(长度为1的字符串)
返回值:对应的十进制整数
51. pow()
描述:pow() 方法返回 x^y(x的y次方) 的值。
语法:
math 模块 pow() 方法的语法:
math.pow( x, y )
内置的 pow() 方法
pow(x, y[, z])函数是计算x的y次方,如果z存在,则再对结果进行取模,其结果等效于pow(x,y) %z
pow(x,y) 等价于 x**y:
pow(x,y,z) 等价于 x**y%z:
注意:pow() 通过内置的方法直接调用,math 模块会把参数转换为 float,内置方法不修改参数类型:py2和py3相同。
math.pow(11.2,3.2)
Out[39]: 2277.7060352240815
math.pow(100, 2)
Out[40]: 10000.0
pow(11.2,3.2)
Out[42]: 2277.7060352240815
pow(100, 2)
Out[43]: 10000pow(x,y,z) 当 z 这个参数不存在时 x,y 不限制是否为 float 类型, 而当使用第三个参数的时候要保证前两个参数只能为整数。
>>> pow(11.2,3.2)
2277.7060352240815
>>> pow(11.2,3.2,2) # 结果报错
Traceback (most recent call last):
File "", line 1, in
TypeError: pow() 3rd argument not allowed unless all arguments are integers 参数:
- x -- 数值表达式。
- y -- 数值表达式。
- z -- 数值表达式。
返回值:返回 x^y(x的y次方) 的值。
52. print()
描述:print() 方法用于打印输出,最常见的一个函数。
print 在 Python3.x 是一个函数,但在 Python2.x 版本不是一个函数,只是一个关键字。语法:print(*objects, sep=' ', end='\n', file=sys.stdout)
参数:
- objects -- 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。在Python2中会输出元组。
- sep -- 用来间隔多个对象,默认值是一个空格。前面多个对象的分隔符。
- end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
- file -- 要写入的文件对象。
返回值:无。
>>> print(a,b)
1 runoob
# py2会输出元组53. property()
描述:property() 函数的作用是在新式类中返回属性值。
语法:class property([fget[, fset[, fdel[, doc]]]])
参数:
- fget -- 获取属性值的函数
- fset -- 设置属性值的函数
- fdel -- 删除属性值函数
- doc -- 属性描述信息
返回值:返回新式类属性。
# 定义一个可控属性值 x
class C(object):
def __init__(self):
self._x = None
def getx(self):
return self._x
def setx(self, value):
self._x = value
def delx(self):
del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")如果 c 是 C 的实例化, c.x 将触发 getter,c.x = value 将触发 setter , del c.x 触发 deleter。
如果给定 doc 参数,其将成为这个属性值的 docstring,否则 property 函数就会复制 fget 函数的 docstring(如果有的话)。
将 property 函数用作装饰器可以很方便的创建只读属性:
class Parrot(object):
def __init__(self):
self._voltage = 100000
@property
def voltage(self):
"""Get the current voltage."""
return self._voltage上面的代码将 voltage() 方法转化成同名只读属性的 getter 方法。
property 的 getter,setter 和 deleter 方法同样可以用作装饰器:
class C(object):
def __init__(self):
self._x = None
@property
def x(self):
"""I'm the 'x' property."""
return self._x
@x.setter
def x(self, value):
self._x = value
@x.deleter
def x(self):
del self._x这个代码和第一个例子完全相同,但要注意这些额外函数的名字和 property 下的一样,例如这里的 x。
54. range()
描述:python range() 函数可创建一个整数列表,一般用在 for 循环中。
语法:range(start, stop[, step])
参数:
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
返回值:Python2整数列表,Python3是range对象。
Python3.x 中 range() 函数返回的结果是一个整数序列的对象(不是迭代器),而不是列表。
class 'range',可以利用list()函数强转为列表。注意负数和0作为参数。
>>> range(0, -10, -1) # 负数
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0)
[]
>>> range(1, 0)
[]55. raw_input()
描述:python raw_input() 用来获取控制台的输入。raw_input() 将所有输入作为字符串看待,返回字符串类型。
注意:input() 和 raw_input() 这两个函数均能接收 字符串 ,但 raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
除非对 input() 有特别需要,否则一般情况下我们都是推荐使用 raw_input() 来与用户交互。
注意:python3 里 input() 默认接收到的是 str 类型。
语法:raw_input([prompt])
参数:
- prompt: 可选,字符串,可作为一个提示语。
返回值:字符串。
Python3.x 中 raw_input( ) 和 input( ) 进行了整合,去除了 raw_input( ),仅保留了 input( ) 函数,其接收任意任性输入,将所有输入默认为字符串处理,并返回字符串类型。
56. reduce()
描述:reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(列表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
语法:reduce(function, iterable[, initializer])
参数:
- function -- 函数,有两个参数(lambda表达式)
- iterable -- 可迭代对象
- initializer -- 可选,初始参数(用于与第一个对象进行计算的参数)
返回值:返回函数计算结果。
在 Python3 中,reduce() 函数已经被从全局名字空间里移除了,它现在被放置在 functools 模块里,如果想要使用它,则需要通过引入 functools 模块来调用 reduce() 函数:
57. reload()
描述:reload() 用于重新载入之前载入的模块。
语法:reload(module)
参数:
- module -- 模块对象。
返回值:返回模块对象。
Python 3.0 把 reload 内置函数移到了 imp 标准库模块中。它仍然像以前一样重载文件,但是,必须导入 imp包才能使用。
需要先import来加载需要的模块,这时候再去reload。
58. repr()
描述:repr() 函数将对象转化为供解释器读取的形式。
语法:repr(object)
参数:
- object -- 对象。
返回值:返回一个对象的 string 格式。
函数str() 用于将值转化为适于人阅读的形式,而repr() 转化为供解释器读取的形式,主要指可以用eval()函数重新将文本转为对象。当然并不是所有repr()返回的字符串都能够用 eval()内建函数得到原来的对象。
会显示类型的特点,比如字符串会输出引号。
但大多数情况下,str,repr和"输出相同。print调用__str__。在python解释器里直接敲对象后回车,调用的是__repr__.
对应 __repr__功能。意思是当需要显示一个对象在屏幕上时,将这个对象的属性或者是方法整理成一个可以打印输出的格式。
59. List reverse()
描述:reverse() 函数用于反向列表中元素。
语法:list.reverse()
参数:无。
返回值:返回值是一个None,也就是该方法没有返回值,但是会对列表的元素进行反向排序。直接操纵所调用的列表。
是python中列表的一个内置方法(也就是说,在字典,字符串或者元组中,是没有这个内置方法的),用于列表中数据的反转。
reversed()
描述:python自带的一个方法,准确说,应该是一个类。可以操纵列表,元组,字符串等序列和迭代器。不在原始迭代器或序列中操作,返回被操作之后的迭代器。
语法:list = reversed(iter)
参数:iter是列表,元组,字符串等序列,或迭代器。 要转换的序列,可以是 tuple, string, list 或 range。
返回值:反转之后的迭代器。
反转迭代器的序列值,返回反向迭代器。需要通过遍历,或者List,或者next()等方法,获取作用后的值。
60. round()
描述:round() 方法返回浮点数x的四舍五入值。
语法:round( x [, n] )
参数:
- x -- 数值表达式。
- n -- 数值表达式。保留的小数点后数字的位数。
返回值:返回浮点数x的四舍五入值。
61. set()
描述:set() 函数创建一个无序不重复元素集(集合),可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
语法:class set([iterable])
参数:
- iterable -- 可迭代对象对象;
返回值:返回新的集合对象。
& 交集,| 并集,- 差集。
62. setattr()
描述:setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的。
语法:setattr(object, name, value)
参数:
- object -- 对象。
- name -- 字符串,对象属性。
- value -- 属性值。
返回值:无。
如果属性不存在会创建一个新的对象属性,并对属性赋值。
63. slice()
描述:slice() 函数实现切片对象,主要用在切片操作函数里的参数传递。
语法:
class slice(stop)
class slice(start, stop[, step])参数:
- start -- 起始位置
- stop -- 结束位置
- step -- 间距
返回值:返回一个切片对象。
>>> myslice = slice(5) # 设置截取5个元素的切片
>>> myslice
slice(None, 5, None)
>>> arr = range(10)
>>> arr
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> arr[myslice] # 截取 5 个元素
[0, 1, 2, 3, 4]64. sorted()
描述:sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法(List类的函数,其他对象无法使用),sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作(对当前调用列表进行排序),无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
语法:
sorted(iterable[, cmp[, key[, reverse]]])参数:
- iterable -- 可迭代对象。
- cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。(两个参数的函数) 采用了策略设计模式。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。(一个参数的函数)
- reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
返回值:返回重新排序的列表。
>>> L=[('b',2),('a',1),('c',3),('d',4)]
>>> sorted(L, cmp=lambda x,y:cmp(x[1],y[1])) # 利用cmp函数
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
>>> sorted(L, key=lambda x:x[1]) # 利用key
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]注意:key 和 reverse 比一个等价的 cmp 函数处理速度要快。这是因为对于每个列表元素,cmp 都会被调用多次,而 key和 reverse 只被调用一次
65. str()
描述:str() 函数将对象转化为适于人阅读的形式。
对应于__str__函数。
语法:class str(object='')
参数:
- object -- 对象。
返回值:返回一个对象的str字符串格式。
66. sum()
描述:sum() 方法对序列进行求和计算。
语法:sum(iterable[, start])
参数:
- iterable -- 可迭代对象,如:列表、元组、集合。
- start -- 指定相加的参数,如果没有设置这个值,默认为0。
返回值:返回计算结果。
67. super()
描述:super() 函数是用于调用父类(超类)的一个方法。在子类内部调用父类的方法。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO,method resolution order)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。在python中,每个类都有一个mro的类方法。可以直接调用查看调用顺序。可以看到mro方法返回的是一个祖先类的列表。每个祖先都在其中出现一次,这也是super在父类中查找成员的顺序。 通过mro,python巧妙地将多继承的图结构,转变为list的顺序结构。super在继承体系中向上的查找过程,变成了在mro中向右的线性查找过程,任何类都只会被处理一次。
1. 查找顺序问题。从Leaf的mro顺序可以看出,如果Leaf类通过super来访问父类成员,那么Medium1的成员会在Medium2之前被首先访问到。如果Medium1和Medium2都没有找到,最后再到Base中查找。
2. 钻石继承的多次初始化问题。在mro的list中,Base类只出现了一次。事实上任何类都只会在mro list中出现一次。这就确保了super向上调用的过程中,任何祖先类的方法都只会被执行一次。
钻石继承指继承多个类时,同时初始化多个父类。而这多个父类有同一个父类。导致该父类的父类被初始化了多次。直接调用父类.__init__就会遇到钻石继承,而如果调用super函数,则会自动处理该问题。
单继承的Java和Ruby肯定不会到钻石继承问题。
语法:super(type[, object-or-type])
参数:
- type -- 类。
- object-or-type -- 类,一般是 self
返回值:无。
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
class A:
def add(self, x):
y = x+1
print(y)
class B(A):
def add(self, x):
super().add(x) # Python 3
super(B, self).add(x) # Python 2
b = B()
b.add(2) # 3Python支持多继承。继承时如果是类变量(不需要实例化即可访问)可以直接继承。但如果子类不重写构造器__init__方法,才会调用父类的构造器__init__方法 ,获得父类的实例变量。否则需要主动调用父类的__init__方法来获取父类的实例变量:super(FooChild,self).__init__()。
对于多继承按照继承顺序继承,首先继承第一个类的变量。
直接继承优先于间接继承的内容。
- python调用父类成员共有2种方法:普通方法(直接调用),super方法
- 在钻石继承中,普通方法会遇到Base类两次初始化的问题
68. tuple()
描述:元组 tuple() 函数将列表转换为元组。
语法:tuple( seq )
参数:
- seq -- 要转换为元组的序列。
返回值:返回元组。
参数如果是字典则转换字典的键。
比如遍历字典,一个元素等于遍历key()。itmes()则返回元组(键, 值)对。
元组的元素不能修改(所以可以作为字典的键)。元组使用小括号,列表使用方括号。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
69. type()
描述:type() 函数如果你只有第一个参数则返回对象的类型,三个参数返回新的类型对象。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
语法:
type(object)
type(name, bases, dict)参数:
- name -- 类的名称。
- bases -- 基类的元组。
- dict -- 字典,类内定义的命名空间变量。
返回值:一个参数返回对象类型, 三个参数,返回新的类型对象(等同于直接创建一个类)。
>>> type({0:'zero'})
>>> x = 1
>>> type( x ) == int # 判断类型是否相等
True
# 三个参数
>>> class X(object):
... a = 1
...
# 上下作用相同
>>> X = type('X', (object,), dict(a=1)) # 产生一个新的类型 X
>>> X
70. unichr()
描述:unichr() 函数 和 chr()函数功能基本一样, 只不过是返回 unicode 的字符。
语法:unichr(i)
参数:
- i -- 可以是10进制也可以是16进制的形式的数字。
返回值:返回 unicode 的字符。字符前面加u左下标。
71. unicode()
描述:unicode是一种字符表示方法,定义了一系列字符的映射表示。不过在逻辑上unicode是没有编码的格式。进行I/O输出的时候一定要做encode("utf-8")这样类似的操作。每个字符都与唯一的数字关联,称为code point。
一种不用字节的形式来表示文本;就是说是变长的。每种语言的每一个字符都有唯一的数字来表示。支持所有主流的语言;可以表示超过100万的符号。
字符表示的是文本中的单个符号。更重要的是,一个字符不是一个字节。而且,一个字符有许多表示方法,不同的表示方法会使用不同的字节数。字符编码是在理想的字符和实际的字节表示方法之间的映射。这种映射无需面面俱到,即在某种编码中也许无法表示一些特定的字符。如果这些特定的字符用不到,那么这种编码方式还是可以用的。同时也无须为每个字符使用相同的内存空间,譬如某些字符使用单字节编码,而其他字符需要多个字节。
在Python的类型层次中,有3种不同的字符串类型:“unicode”,表示Unicode字符串(文本字符串)。“str”,表示字节字符串(二进制数据)。“basestring”,表示前两种字符串类型的父类。
- Python将字节序列作为另一种类型的字符串对待,允许在这两者上执行同样的操作。
- Python3中则兼容的非常好
字符串a使用decode就会得到unicode类型,a为unicode类型的时候a.encode就会得到str类型了。
语法:unicode(str)
参数:
- str -- 字符串。
返回值:返回 unicode 的字符。字符前面加u左下标。encode之后变成原始字符串。
UTF-8是变长编码方法:就是变量的多字节表示,前128个字符就和ascii一样。(其他的1字节表示不了,需要更多字节,一个字符可能需要1-4个字节)
72. vars()
描述:vars() 函数返回对象object的属性和属性值的字典对象。
语法:vars([object])
参数:
- object -- 对象(类对象,而不是实例对象)
返回值:返回对象object的属性和属性值的字典对象,如果没有参数,就打印当前调用位置的属性和属性值 类似 locals()(当前模块,包括内置变量)。
>>>print(vars())
{'__builtins__': , '__name__': '__main__', '__doc__': None, '__package__': None}
>>> class Runoob:
... a = 1
...
>>> print(vars(Runoob))
{'a': 1, '__module__': '__main__', '__doc__': None}
>>> runoob = Runoob()
>>> print(vars(runoob))
{} 73. xrange()
描述:xrange() 函数用法与 range 完全相同,所不同的是生成的不是一个数组或列表,而是一个生成器。
语法:
xrange(stop)
xrange(start, stop[, step])参数:
- start: 计数从 start 开始。默认是从 0 开始。例如 xrange(5) 等价于 xrange(0, 5)
- stop: 计数到 stop 结束,但不包括 stop。例如:xrange(0, 5) 是 [0, 1, 2, 3, 4] 没有 5
- step:步长,默认为1。例如:xrange(0, 5) 等价于 xrange(0, 5, 1)
返回值:返回生成器。节省内存,惰性结构。可以利用list转换为列表。
迭代器和生成器:
迭代器:访问集合元素的一种方式。字符串,列表或元组对象都可用于创建迭代器。可以记住遍历的对象的上一次位置;从集合的第一个元素开始访问,直到所有的元素被访问结束。
即:只能往前不会后退。使用next()函数进行访问。
内建函数 iter()可以从 可迭代对象中获得迭代器(collections.Iterator)。迭代器可利用iter直接生成。包括:listiterator,tupleiterator,setiterator,dictionary-keyiterator等。
可迭代对象:list tuple dict str set collections.Iterable
序列(字符串,元组和列表)
一个可迭代的对象必须是定义了__iter__()方法的对象,而一个迭代器必须是定义了__iter__()方法和__next()__方法的对象。
iter([1,2,3,4])
Out[23]:
iter((1,2,3,4))
Out[24]: 1)__iter__()
该方法返回的是当前对象的迭代器类的实例。因为可迭代对象与迭代器都要实现这个方法,因此有以下两种写法。
写法一:用于可迭代对象类的写法,返回该可迭代对象的迭代器类(专门用于迭代可迭代对象的一个类)的实例。
写法二:用于迭代器类的写法,直接返回self(即自己本身),表示自身即是自己的迭代器。
2)next()
返回迭代的每一步,实现该方法时注意要最后超出边界要抛出StopIteration异常,以停止for循环。
一个实现了iter方法的对象时可迭代的,一个实现next方法的对象是迭代器,可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
生成器(generator):通过 yield 语句快速生成迭代器,省略了复杂的 _iter__()&__next__()方式。在Python中,这种一边循环一边计算的机制,称为生成器:generator。是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。生成器看起来像是一个函数,但是表现得却像是迭代器。
生成器是能够返回一个迭代器的函数,其最大的作用是将输入对象返回为一个迭代器。Python中使用了迭代的概念,是因为当需要循环遍历一个较大的对象时,传统的内存载入方式会消耗大量的内存,不如需要时读取一个元素的方式更为经济快捷。
简单的说就是在函数的执行过程中,yield语句会把你需要的值返回给调用生成器的地方,然后退出函数,下一次调用生成器函数的时候又从上次中断的地方开始执行,而生成器内的所有变量参数都会被保存下来供下一次使用。创建迭代器的简单而强大的工具。只是在需要返回数据的时候使用yield语句。
生成器在迭代的过程中可以改变当前迭代值,而修改普通迭代器的当前迭代值往往会发生异常,影响程序的执行。
惰性。
如何创建生成器:
第一种方法很简单,把一个列表生成式的[]中括号改为()小括号,就创建一个generator。
#列表生成式
lis = [x*x for x in range(10)]
print(lis)
#生成器
generator_ex = (x*x for x in range(10))
print(generator_ex)(1)通过next()函数获得generator的下一个返回值。
(2)使用for循环,因为generator也是可迭代对象,抛出StopIteration的错误,结束for循环。
一类是集合数据类型,如list,tuple,dict,set,str等
一类是generator,包括生成器和带yield的generator function
这些可以直接作用于for 循环的对象统称为可迭代对象:Iterable
from collections import Iterable
第二种方法是通过yield关键字主动生成一个复杂的生成器。
def fib(max):
n,a,b =0,0,1
while n < max:
yield b
a,b =b,a+b
n = n+1
return 'done'
for i in fib(6):
print(i)但是用for循环调用generator时,发现拿不到generator的return语句的返回值,如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中。
while True:
try:
x = next(g)
print('generator: ',x)
except StopIteration as e:
print("生成器返回值:",e.value)
break生成器和迭代器的区别:
1、语法方面来讲:
生成器是用函数中yield语句来创建的。迭代器的创建首先跟函数无关,可以用iter([1,2])来创建。
2、使用方面来讲:
由于生成器是使用函数的方式创建的,所以生成器里面的所有过程都会被执行,但请注意生成器里面的过程只有在被next()调用或者for循环调用时,里面的过程才会被执行,如同上面的例子只是单纯调用add这个对象时,add里面的过程没有被执行哦
迭代器同样可以被for和next调用但是由于没有其他过程,在被调用时只会返回值,不会有其他动作
74. zip()
描述:zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象(节约了内存)。如需展示列表,需手动 list() 转换。
语法:zip([iterable, ...])
参数:
- iterabl -- 一个或多个迭代器;
返回值:返回元组列表。
75. __import__()
描述:__import__() 函数用于动态加载类和函数 。如果一个模块经常变化就可以使用 __import__() 来动态载入。
语法:__import__(name[, globals[, locals[, fromlist[, level]]]])
参数:
- name -- 模块名
返回值:返回元组列表。
76. staticmethod()
描述:python staticmethod 返回函数的静态方法。该方法不强制要求传递参数(类方法),如下声明一个静态方法(修饰器):
类可以不用实例化就可以调用该方法 C.f(),当然也可以实例化后调用 C().f()。
class C(object):
@staticmethod
def f(arg1, arg2, ...):
...语法:staticmethod(function)
参数:
- function -- 类里定义的函数
返回值:返回元组列表。
77. apply()
描述:用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。类似于反射调用的函数。
语法:apply(func [, args [, kwargs ]])
参数:args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任何参数都不会被传递,kwargs是一个包含关键字参数的字典。
返回值:apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致。
1、假设是执行没有带参数的方法
def say():
print 'say in'
apply(say)
输出的结果是'say in'
2、函数只带元组的参数。
def say(a, b):
print a, b
apply(say,("hello", "老王python"))
输出的结果是hello,老王python
3、函数带关键字参数。
def say(a=1,b=2):
print a,b
def haha(**kw):
#say(kw)
apply(say,(),kw)
print haha(a='a',b='b')
输出的结果是:a,b78. buffer()
描述:创建一个新的缓冲对象,该对象引用(指向)给定的对象。缓冲区将从对象的开始(或在指定的偏移量)引用目标对象的切片。该切片将扩展到目标对象的末端(或具有指定大小)。
语法:buffer(object [, offset[, size]])
参数:
- object:给定引用的对象
- offset:偏移量
- size:大小
返回值:返回一个新的缓冲对象
79. coerce()
描述:返回由两个数值参数组成的元组,使用与算术运算符相同的规则转换为常见类型。如果coerce不可用,那么触发TypeError。
语法:coerce(x, y) -> (x1, y1)
参数:数值
返回值:元组
80. intern()
描述:手动将目标字符串驻留到字符串池子里。
语法:intern(str)
参数:字符串
返回值:字符串
字符串驻留机制:值同样的字符串对象仅仅会保存一份,是共用的,这也决定了字符串必须是不可变对象。
其实我们想一想,就和数值类型一样,同样的数值仅仅要保存一份即可了,不是必须用不同对象来区分。
>>> a = 'opq'
>>> b = 'o' + 'pq'
>>> id(a)
66832910
>>> id(b)
66832910intern机制的优点是,在创建新的字符串对象时,会先在缓存池里面找是否有已经存在的值相同的对象(标识符,即只包含数字、字母、下划线的字符),如果有,则直接拿过来用(引用),避免频繁的创建和销毁内存,提升效率。
缺点是在拼接字符串时,或者在改动字符串时会极大的影响性能(多次重新创建对象)。原因是字符串在Python当中是不可变对象,所以对字符串的改动不是inplace(原地)操作,需要新开辟内存地址,新建对象。这也是为什么拼接字符串的时候不建议用‘+’而是用join()。join()是先计算出全部字符串的长度,然后再一一拷贝,仅仅创建一次对象(类似于字符串拼接中java要用stringbuffer和stringbuilder,而不是string)。
>>> a = 'hello world'
>>> b = 'hello world'
>>> id(a)
66834385
>>> id(b)
66439216 由于字符串里面含有空格,导致不会触发intern机制。
可是为什么会这么做呢?既然Python的内置函数intern()能显式的对随意字符串进行intern,说明不是实现难度的问题。
答案在源代码StringObject.h中的注释能够找到:intern机制仅仅对那些看起来像是Python标识符的字符串对象才会触发。
>>> 'op' + 'q' is 'opq'
>>> True
>>> c = 'op'
>>> d = 'opq'
>>> c + 'q' is 'opq'
>>> False
前半部分是在运行时进行拼接,没有自动调用intern机制
若是intern(a+“n”) is b 则是返回false。
>>> intern(c + 'q') is 'opq'
>>> False在第一个例子中,‘op’ + ‘q’是在compile-time(编译时)求值的,被替换成了’opq’,而在第二个例子中,c + ‘q’是在run-time(运行时)拼接的,导致没有被主动intern。因为c是变量。
>>> s1 = "hell"
>>> s2 = "hello"
>>> s1 + "o" is s2
False
>>> "hell" + "o" is s2
True
>>>
# 说明shell和IDE在这方面没有差异
s1 = "hell"
s2 = "hello"
print(s1 + "o" is s2) # False
print("hell" + "o" is s2) # True
#因为"hell" + "o"在编译时已经变成了"hello",而s1+"o"因为s1是一个变量,他们会在运行时进行拼接,所以没有被intern- 单词,即Python标识符(仅仅包括下划线、数字、字母和任何长度为1的字符串才会被intern),不可修改,默认开启intern机制,共用对象,引用计数为0时自动被回收。当然不能超过20个字符。因为如果超过20个字符的话,解释器认为这个字符串不常用,不用放入字符串池中
- 字符串(包含了除Python标识符以外的字符),不可修改,默认没有开启intern机制,引用计数为0时自动被回收。
- 特殊情况下(上述最后一个例子),不会被主动intern。
- join() 方法除了在拼接字符串时速度较快,它还是目前看来最通用有效的复制字符串的方法
apply()、buffer()、coerce()、intern()---这些是过期的内置函数(3.0开始移除了),少用。具体内容参考:https://docs.python.org/zh-cn/3.7/library/functions.html