研磨设计模式 之 组合模式(Composite) 3——跟着cc学设计系列
15.3 模式讲解
15.3.1 认识组合模式
(1)组合模式的目的
组合模式的目的是:让客户端不再区分操作的是组合对象还是叶子对象,而是以一个统一的方式来操作。
实现这个目标的关键之处,是设计一个抽象的组件类,让它可以代表组合对象和叶子对象。这样一来,客户端就不用区分到底是组合对象还是叶子对象了,只需要全部当成组件对象进行统一的操作就可以了。
(2)对象树
通常,组合模式会组合出树形结构来,组成这个树形结构所使用的多个组件对象,就自然的形成了对象树。
这也意味着凡是可以使用对象树来描述或操作的功能,都可以考虑使用组合模式,比如读取XML文件,或是对语句进行语法解析等。
(3)组合模式中的递归
组合模式中的递归,指的是对象递归组合,不是常说的递归算法。通常我们谈的递归算法,是指“一个方法会调用方法自己”这样的算法,是从功能上来讲的,比如那个经典的求阶乘的例子,示例如下:
| public class RecursiveTest { /** * 示意递归算法,求阶乘。这里只是简单的实现,只能实现求数值较小的阶乘, * 对于数据比较大的阶乘,比如求100的阶乘应该采用java.math.BigDecimal * 或是java.math.BigInteger * @param a 求阶乘的数值 * @return 该数值的阶乘值 */ public int recursive(int a){ if(a==1){ return 1; } return a * recursive(a-1); } public static void main(String[] args) { RecursiveTest test = new RecursiveTest(); int result = test.recursive(5); System.out.println("5的阶乘="+result); } } |
而这里的组合模式中的递归,是对象本身的递归,是对象的组合方式,是从设计上来讲的,在设计上称作递归关联,是对象关联关系的一种,如果用UML来表示对象的递归关联的话,一对一的递归关联如图15.4所示,而一对多的递归关联如图15.5所示:
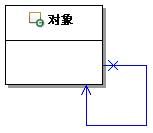
图15.4 一对一递归关联结构示意图

图15.5 一对多递归关联结构示意图
另外组合对象还有一个特点,就是理论上没有层次限制,组合对象A包含组合对象B,组合对象B又包含组合对象C……,这样下去是没有尽头的。因此在实现的时候,一个必然的选择就是递归实现。
(4)Component中是否应该实现一个Component列表
大多数情况下,一个Composite对象会持有子节点的集合。有些朋友可能就会想,那么能不能把这个子节点集合定义到Component中去呢?因为在Component中还声明了一些操作子节点的方法,这样一来,大部分的工作就可以在Component中完成了。
事实上,这种方法是不太好的,因为在父类来存放子类的实例对象,对于Composite节点来说没有什么,它本来就需要存放子节点,但是对于叶子节点来说,就会导致空间的浪费,因为叶节点本身不需要子节点。
因此只有当组合结构中叶子对象数目较少的时候,才值得使用这种方法。
(5)最大化Component定义
前面讲到了组合模式的目的是:让客户端不再区分操作的是组合对象还是叶子对象,而是以一种统一的方式来操作。
由于要统一两种对象的操作,所以Component里面的方法也主要是两种对象对外方法的和,换句话说,有点大杂烩的意思,组件里面既有叶子对象需要的方法,也有组合对象需要的方法。
其实这种实现是与类的设计原则相冲突的,类的设计有这样的原则:一个父类应该只定义那些对它的子类有意义的操作。但是看看上面的实现就知道,Component中的有些方法对于叶子对象是没有意义的。那么怎么解决这一冲突呢?
常见的做法是在Component里面为对某些子对象没有意义的方法,提供默认的实现,或是默认抛出不支持该功能的例外。这样一来,如果子对象需要这个功能,那就覆盖实现它,如果不需要,那就不用管了,使用父类的默认实现就可以了。
从另一个层面来说,如果把叶子对象看成是一个特殊的Composite对象,也就是没有子节点的组合对象而已。这样看来,对于Component而言,子对象就全部看作是组合对象,因此定义的所有方法都是有意义的了。
(6)子部件排序
在某些应用中,使用组合模式的时候,需要按照一定的顺序来使用子组件对象,比如进行语法分析的时候,使用组合模式构建的抽象语法树,在解析执行的时候,是需要按照顺序来执行的。
对于这样的功能,需要在设计的时候,就要把组件对象的索引考虑进去,并仔细的设计对子节点的访问和管理接口,通常的方式是需要按照顺序来存储,这样在获取的时候就可以按照顺序得到了。可以考虑结合Iterator模式来实现按照顺序的访问组件对象。
15.3.2 安全性和透明性
根据前面的讲述,在组合模式中,把组件对象分成了两种,一种是可以包含子组件的Composite对象,一种是不能包含其它组件对象的叶子对象。
Composite对象就像是一个容器,可以包含其它的Composite对象或叶子对象。当然有了容器,就要能对这个容器进行维护,需要向里面添加对象,并能够从容器里面获取对象,还有能从容器中删除对象,也就是说需要管理子组件对象。
这就产生了一个很重要的问题:到底在组合模式的类层次结构中,在哪一些类里面定义这些管理子组件的操作,到底应该在Component中声明这些操作,还是在Composite中声明这些操作?
这就需要仔细思考,在不同的实现中,进行安全性和透明性的权衡选择。
- 这里所说的安全性是指:从客户使用组合模式上看是否更安全。如果是安全的,那么不会有发生误操作的可能,能访问的方法都是被支持的功能。
- 这里所说的透明性是指:从客户使用组合模式上,是否需要区分到底是组合对象还是叶子对象。如果是透明的,那就是不再区分,对于客户而言,都是组件对象,具体的类型对于客户而言是透明的,是客户无需要关心的。
1:透明性的实现
如果把管理子组件的操作定义在Component中,那么客户端只需要面对Component,而无需关心具体的组件类型,这种实现方式就是透明性的实现。事实上,前面示例的实现方式都是这种实现方式。
但是透明性的实现是以安全性为代价的,因为在Component中定义的一些方法,对于叶子对象来说是没有意义的,比如:增加、删除子组件对象。而客户不知道这些区别,对客户是透明的,因此客户可能会对叶子对象调用这种增加或删除子组件的方法,这样的操作是不安全的。
组合模式的透明性实现,通常的方式是:在Component中声明管理子组件的操作,并在Component中为这些方法提供缺省的实现,如果是有子对象不支持的功能,缺省的实现可以是抛出一个例外,来表示不支持这个功能。
2:安全性的实现
如果把管理子组件的操作定义在Composite中,那么客户在使用叶子对象的时候,就不会发生使用添加子组件或是删除子组件的操作了,因为压根就没有这样的功能,这种实现方式是安全的。
但是这样一来,客户端在使用的时候,就必须区分到底使用的是Composite对象,还是叶子对象,不同对象的功能是不一样的。也就是说,这种实现方式,对客户而言就不是透明的了。
下面把用透明性方式实现的示例,改成用安全性的方式再实现一次,这样大家可以对比来看,可以更好的理解组合模式的透明性和安全性这两种实现方式。
先还是来看一下使用安全性方式实现示例的结构,如图15.6所示

图15.6 使用组合模式的安全性实现方式来实现示例的结构示意图
(1)首先看看Component的定义,跟透明性的实现相比,安全性的实现方式,Component里面不再定义管理和操作子组件的方法,把相应的方法都去掉。示例代码如下:
| /** * 抽象的组件对象,安全性的实现方式 */ public abstract class Component { /** * 输出组件自身的名称 */ public abstract void printStruct(String preStr); } |
(2)Composite对象和Leaf对象的实现都没有任何的变化,这里就不去赘述了
(3)接下来看看客户端的实现,客户端的变化主要是要区分Composite对象和Leaf对象,而原来是不区分的,都是Component对象。示例代码如下:
| public class Client { public static void main(String[] args) { //定义所有的组合对象 Composite root = new Composite("服装"); Composite c1 = new Composite("男装"); Composite c2 = new Composite("女装"); //定义所有的叶子对象 Leaf leaf1 = new Leaf("衬衣"); Leaf leaf2 = new Leaf("夹克"); Leaf leaf3 = new Leaf("裙子"); Leaf leaf4 = new Leaf("套装");
//按照树的结构来组合组合对象和叶子对象 root.addChild(c1); root.addChild(c2); c1.addChild(leaf1); c1.addChild(leaf2); c2.addChild(leaf3); c2.addChild(leaf4);
//调用根对象的输出功能来输出整棵树 root.printStruct(""); } } |
从上面的示例可以看出,从实现上,透明性和安全性的实现差别并不是很大。
3:两种实现方式的选择
对于组合模式而言,在安全性和透明性上,会更看重透明性,毕竟组合模式的功能就是要让用户对叶子对象和组合对象的使用具有一致性。
而且对于安全性的实现,需要区分是组合对象还是叶子对象,但是有的时候,你需要将对象进行类型转换,却发现类型信息丢失了,只好强行转换,这种类型转换必然是不够安全的。
对于这种情况的处理方法是在Component里面定义一个getComposite的方法,用来判断是组合对象还是叶子对象,如果是组合对象,就返回组合对象,如果是叶子对象,就返回null,这样就可以先判断,然后再强制转换。
因此在使用组合模式的时候,建议多用透明性的实现方式,而少用安全性的实现方式。
15.3.3 父组件引用
在上面的示例中,都是在父组件对象里面,保存有子组件的引用,也就是说都是从父到子的引用。而本节来讨论一下子组件对象到父组件对象的引用,这个在实际开发中也是非常有用的,比如:
- 现在要删除某个商品类别。如果这个类别没有子类别的话,直接删除就好了,没有太大的问题,但是如果它还有子类别,这就涉及到它的子类别如何处理了,一种情况是连带全部删除,一种是上移一层,把被删除的商品类别对象的父商品类别,设置成为被删除的商品类别的子类别的父商品类别。
- 现在要进行商品类别的细化和调整,把原本属于A类别的一些商品类别,调整到B类别里面去,某个商品类别的调整会伴随着它所有的子类别一起调整。这样的调整可能会:把原本是兄弟关系的商品类别变成父子关系,也可能会把原本是父子关系的商品类别调整成了兄弟关系,如此等等会有很多种可能。
要实现上述的功能,一个较为简单的方案就是在保持从父组件到子组件引用的基础上,再增加保持从子组件到父组件的引用,这样在删除一个组件对象或是调整一个组件对象的时候,可以通过调整父组件的引用来实现,这可以大大简化实现。
通常会在Component中定义对父组件的引用,组合对象和叶子对象都可以继承这个引用。那么什么时候来维护这个引用呢?
较为容易的办法就是:在组合对象添加子组件对象的时候,为子组件对象设置父组件的引用;在组合对象删除一个子组件对象的时候,再重新设置相关子组件的父组件引用。把这些实现到Composite中,这样所有的子类都可以继承到这些方法,从而更容易的维护子组件到父组件的引用。
还是看示例会比较清楚。在前面实现的商品类别的示例基础上,来示例对父组件的引用,并实现删除某个商品类别,然后把被删除的商品类别对象的父商品类别,设置成为被删除的商品类别的子类别的父商品类别。也就是把被删除的商品类别对象的子商品类别都上移一层。
(1)先看看Component组件的定义,大致有如下变化:
- 添加一个属性来记录组件对象的父组件对象,同时提供相应的getter/setter方法来访问父组件对象
- 添加一个能获取一个组件所包含的子组件对象的方法,提供给实现当某个组件被删除时,把它的子组件对象上移一层的功能时使用
示例代码如下:
| public abstract class Component { /** * 记录父组件对象 */ private Component parent = null; /** * 获取一个组件的父组件对象 * @return 一个组件的父组件对象 */ public Component getParent() { return parent; } /** * 设置一个组件的父组件对象 * @param parent 一个组件的父组件对象 */ public void setParent(Component parent) { this.parent = parent; } /** * 返回某个组件的子组件对象 * @return 某个组件的子组件对象 */ public List throw new UnsupportedOperationException( "对象不支持这个功能"); } /*-------------------以下是原有的定义----------------------*/ public abstract void printStruct(String preStr); public void addChild(Component child) { throw new UnsupportedOperationException( "对象不支持这个功能"); } public void removeChild(Component child) { throw new UnsupportedOperationException( "对象不支持这个功能"); } public Component getChildren(int index) { throw new UnsupportedOperationException( "对象不支持这个功能"); } } |
(2)接下来看看Composite的实现,大致有如下变化:
- 在添加子组件的方法实现里面,加入对父组件的引用实现
- 在删除子组件的方法实现里面,加入把被删除的商品类别对象的父商品类别,设置成为被删除的商品类别的子类别的父商品类别的功能
- 实现新的返回组件的子组件对象的功能
示例代码如下:
| /** * 组合对象,可以包含其它组合对象或者叶子对象 */ public class Composite extends Component{ public void addChild(Component child) { //延迟初始化 if (childComponents == null) { childComponents = new ArrayList } childComponents.add(child);
//添加对父组件的引用 child.setParent(this); }
public void removeChild(Component child) { if (childComponents != null) { //查找到要删除的组件在集合中的索引位置 int idx = childComponents.indexOf(child); if (idx != -1) { //先把被删除的商品类别对象的父商品类别, //设置成为被删除的商品类别的子类别的父商品类别 for(Component c : child.getChildren()){ //删除的组件对象是本实例的一个子组件对象 c.setParent(this); //把被删除的商品类别对象的子组件对象添加到当前实例中 childComponents.add(c); }
//真的删除 childComponents.remove(idx); } } } public List return childComponents; } /*------------以下是原有的实现,没有变化----------------*/ private List private String name = ""; public Composite(String name){ this.name = name; } public void printStruct(String preStr){ System.out.println(preStr+"+"+this.name); if(this.childComponents!=null){ preStr+=" "; for(Component c : childComponents){ c.printStruct(preStr); } } } } |
(3)叶子对象没有任何的改变,这里就不去赘述了
(4)可以来写个客户端测试一下了,在原来的测试后面,删除一个节点,然后再次输出整棵树的结构,看看效果。示例代码如下:
| public class Client { public static void main(String[] args) { //定义所有的组合对象 Component root = new Composite("服装"); Component c1 = new Composite("男装"); Component c2 = new Composite("女装"); //定义所有的叶子对象 Component leaf1 = new Leaf("衬衣"); Component leaf2 = new Leaf("夹克"); Component leaf3 = new Leaf("裙子"); Component leaf4 = new Leaf("套装"); //按照树的结构来组合组合对象和叶子对象 root.addChild(c1); root.addChild(c2); c1.addChild(leaf1); c1.addChild(leaf2); c2.addChild(leaf3); c2.addChild(leaf4); //调用根对象的输出功能来输出整棵树 root.printStruct(""); System.out.println("---------------------------->"); //然后删除一个节点 root.removeChild(c1); //重新输出整棵树 root.printStruct(""); } } |
运行结果如下:
| +服装 +男装 -衬衣 -夹克 +女装 -裙子 -套装 ----------------------------> +服装 +女装 -裙子 -套装 -衬衣 -夹克 |
仔细观察上面的结果,当男装的节点被删除后,会把原来男装节点下的子节点,添加到原来男装的父节点,也就是服装的下面了。输出是按照添加的先后顺序来的,所以先输出了女装的,然后才是衬衣和夹克节点。
15.3.4 环状引用
所谓环状引用指的是:在对象结构中,某个对象包含的子对象,或是子对象的子对象,或是子对象的子对象的子对象……,如此经过N层后,出现所包含的子对象中有这个对象本身,从而构成了环状引用。比如:A包含B,B包含C,而C又包含了A,转了一圈,转回来了,就构成了一个环状引用。
这个在使用组合模式构建树状结构的时候,是需要考虑的一种情况。通常情况下,组合模式构建的树状结构,是不应该出现环状引用的,如果出现了,多半是有错误发生了。因此在应用组合模式实现功能的时候,就应该考虑要检测并避免出现环状引用,否则很容易引起死循环的操作,或是同一个功能被操作多次。
但是要说明的是:组合模式的实现里面也是可以有环状引用的,当然需要特殊构建环状引用,并提供相应的检测和处理,这里不去讨论这种情况。
那么该如何检测是否有环状引用的情况发生呢?
一个很简单的思路就是记录下每个组件从根节点开始的路径,因为要出现环状引用,在一条路径上,某个对象就必然会出现两次。因此只要每个对象在整个路径上只是出现了一次,那么就不会出现环状引用。
这个判断的功能可以添加到Composite对象的添加子组件的方法中,如果是环状引用的话,就抛出例外,并不会把它加入到子组件中去。
还是通过示例来说明吧。在前面实现的商品类别的示例基础上,来加入对环状引用的检测和处理。约定用组件的名称来代表组件,也就是说,组件的名称是唯一的,不会重复的,只要检测在一条路径上,组件名称不会重复,那么组件就不会重复。
(1)先看看Component的定义,大致有如下的变化:
- 添加一个记录每个组件的路径的属性,并提供相应的getter/setter方法
- 为了拼接组件的路径,新添加一个方法来获取组件的名称
示例代码如下:
| public abstract class Component { /** * 记录每个组件的路径 */ private String componentPath = ""; /** * 获取组件的路径 * @return 组件的路径 */ public String getComponentPath() { return componentPath; } /** * 设置组件的路径 * @param componentPath 组件的路径 */ public void setComponentPath(String componentPath) { this.componentPath = componentPath; } /** * 获取组件的名称 * @return 组件的名称 */ public abstract String getName(); /*-------------------以下是原有的定义----------------------*/ public abstract void printStruct(String preStr); public void addChild(Component child) { throw new UnsupportedOperationException( "对象不支持这个功能"); } public void removeChild(Component child) { throw new UnsupportedOperationException( "对象不支持这个功能"); } public Component getChildren(int index) { throw new UnsupportedOperationException( "对象不支持这个功能"); } } |
(2)再看看Composite的实现,大致有如下的变化:
- 提供获取组件名称的实现
- 在添加子组件的实现方法里面,进行是否环状引用的判断,并计算组件对象的路径,然后设置回组件对象去
示例代码如下:
| public class Composite extends Component{ public String getName(){ return this.name; } public void addChild(Component child) { //延迟初始化 if (childComponents == null) { childComponents = new ArrayList } childComponents.add(child);
//先判断组件路径是否为空,如果为空,说明本组件是根组件 if(this.getComponentPath()==null || this.getComponentPath().trim().length()==0){ //把本组件的name设置到组件路径中 this.setComponentPath(this.name); } //判断要加入的组件在路径上是否出现过 //先判断是否是根组件 if(this.getComponentPath() .startsWith(child.getName()+".")){ //说明是根组件,重复添加了 throw new java.lang.IllegalArgumentException( "在本通路上,组件 '"+child.getName()+"' 已被添加过了"); }else{ if(this.getComponentPath() .indexOf("."+child.getName()) < 0){ //表示没有出现过,那么可以加入 //计算组件的路径 String componentPath = this.getComponentPath() +"."+child.getName(); //设置子组件的路径 child.setComponentPath(componentPath); }else{ throw new java.lang.IllegalArgumentException( "在本通路上,组件 '"+child.getName()+"' 已被添加过了"); } } } /*---------------以下是原有的实现,没有变化------------------*/ private List private String name = ""; public Composite(String name){ this.name = name; } public void printStruct(String preStr){ System.out.println(preStr+"+"+this.name); if(this.childComponents!=null){ preStr+=" "; for(Component c : childComponents){ c.printStruct(preStr); } } } } |
(3)叶子对象的实现,只是多了一个实现获取组件名称的方法,也就是直接返回叶子对象的Name,跟Composite中的实现是类似的,就不去代码示例了
(4)客户端的代码可以不做修改,可以正常执行,输出商品类别树来。当然,如果想要看到环状引用检测的效果,你可以做一个环状引用测试看看,比如:
| public class Client { public static void main(String[] args) { //定义所有的组合对象 Component root = new Composite("服装"); Component c1 = new Composite("男装"); Component c2= new Composite("衬衣"); Component c3= new Composite("男装"); //设置一个环状引用 root.addChild(c1); c1.addChild(c2); c2.addChild(c3);
//调用根对象的输出功能来输出整棵树 root.printStruct(""); } } |
运行结果如下:
| Exception in thread "main" java.lang.IllegalArgumentException: 在本通路上,组件 '男装' 已被添加过了 后面的堆栈信息就省略了 |
(5)说明
上面进行环路检测的实现是非常简单的,但是还有一些问题没有考虑,比如:要是删除了路径上的某个组件对象,那么所有该组件对象的子组件对象所记录的路径,都需要修改,要把这个组件从所有相关路径上都去除掉。就是在被删除的组件对象的所有子组件对象的路径上,查找到被删除组件的名称,然后通过字符串截取的方式把它删除掉。
只是这样的实现方式有些不太好,要实现这样的功能,可以考虑使用动态计算路径的方式,每次添加一个组件的时候,动态的递归寻找父组件,然后父组件再找父组件,一直到根组件,这样就能避免某个组件被删除后,路径发生了变化,需要修改所有相关路径记录的情况。
15.3.5 组合模式的优缺点
l 定义了包含基本对象和组合对象的类层次结构
在组合模式中,基本对象可以被组合成更复杂的组合对象,而组合对象又可以组合成更复杂的组合对象,可以不断地递归组合下去,从而构成一个统一的组合对象的类层次结构
l 统一了组合对象和叶子对象
在组合模式中,可以把叶子对象当作特殊的组合对象看待,为它们定义统一的父类,从而把组合对象和叶子对象的行为统一起来
l 简化了客户端调用
组合模式通过统一组合对象和叶子对象,使得客户端在使用它们的时候,就不需要再去区分它们,客户不关心使用的到底是什么类型的对象,这就大大简化了客户端的使用
l 更容易扩展
由于客户端是统一的面对Component来操作,因此,新定义的Composite或Leaf子类能够很容易的与已有的结构一起工作,而客户端不需要为增添了新的组件类而改变
l 很难限制组合中的组件类型
容易增加新的组件也会带来一些问题,比如很难限制组合中的组件类型。这在需要检测组件类型的时候,使得我们不能依靠编译期的类型约束来完成,必须在运行期间动态检测。
15.3.6 思考组合模式
1:组合模式的本质
组合模式的本质:统一叶子对象和组合对象。
组合模式通过把叶子对象当成特殊的组合对象看待,从而对叶子对象和组合对象一视同仁,统统当成了Component对象,有机的统一了叶子对象和组合对象。
正是因为统一了叶子对象和组合对象,在将对象构建成树形结构的时候,才不需要做区分,反正是组件对象里面包含其它的组件对象,如此递归下去;也才使得对于树形结构的操作变得简单,不管对象类型,统一操作。
2:何时选用组合模式
建议在如下情况中,选用组合模式:
- 如果你想表示对象的部分-整体层次结构,可以选用组合模式,把整体和部分的操作统一起来,使得层次结构实现更简单,从外部来使用这个层次结构也简单
- 如果你希望统一的使用组合结构中的所有对象,可以选用组合模式,这正是组合模式提供的主要功能
15.3.7 相关模式
l 组合模式和装饰模式
这两个模式可以组合使用。
装饰模式在组装多个装饰器对象的时候,是一个装饰器找下一个装饰器,下一个再找下一个,如此递归下去。那么这种结构也可以使用组合模式来帮助构建,这样一来,装饰器对象就相当于组合模式的Composite对象了。
要让两个模式能很好的组合使用,通常会让它们有一个公共的父类,因此装饰器必须支持组合模式需要的一些功能,比如:增加、删除子组件等等。
l 组合模式和享元模式
这两个模式可以组合使用。
如果组合模式中出现大量相似的组件对象的话,可以考虑使用享元模式来帮助缓存组件对象,这可以减少对内存的需要。
使用享元模式也是有条件的,如果组件对象的可变化部分的状态能够从组件对象里面分离出去,而且组件对象本身不需要向父组件发送请求的话,就可以采用享元模式。
l 组合模式和迭代器模式
这两个模式可以组合使用。
在组合模式中,通常可以使用迭代器模式来遍历组合对象的子对象集合,而无需关心具体存放子对象的聚合结构。
l 组合模式和访问者模式
这两个模式可以组合使用。
访问者模式能够在不修改原有对象结构的情况下,给对象结构中的对象增添新的功能。将访问者模式和组合模式合用,可以把原本分散在Composite和Leaf类中的操作和行为都局部化。
如果在使用组合模式的时候,预计到今后可能会有增添其它功能的可能,那么可以采用访问者模式,来预留好添加新功能的方式和通道,这样以后在添加新功能的时候,就不需要再修改已有的对象结构和已经实现的功能了。
l 组合模式和职责链模式
这两个模式可以组合使用。
职责链模式要解决的问题是:实现请求的发送者和接收者之间解耦。职责链模式的实现方式是把多个接收者组合起来,构成职责链,然后让请求在这条链上传递,直到有接收者处理这个请求为止。
可以应用组合模式来构建这条链,相当于是子组件找父组件,父组件又找父组件,如此递归下去,构成一条处理请求的组件对象链。
l 组合模式和命令模式
这两个模式可以组合使用。
命令模式中有一个宏命令的功能,通常这个宏命令就是使用组合模式来组装出来的。
---------------------------------------------------------------------------
私塾在线学习网原创内容 跟着cc学设计系列 之 研磨设计模式
研磨设计讨论群【252780326】
原创内容,转载请注明出处【http://sishuok.com/forum/blogPost/list/0/5513.html】
---------------------------------------------------------------------------