numpy手写NLP模型(二)————Skip-gram
numpy手写NLP模型(二)———— Skip-gram
- 1. 模型介绍
- 2. 模型
- 2.1 模型的前向传播
- 2.2 模型的反向传播
- 3. 模型的代码实现
- 4. 效果
1. 模型介绍
关于Word2Vector的话就简单说一下(说不定哪天老年痴呆自己都不记得是啥了呢),在进行自然语言处理的时候我们最开始拿到的数据自然是字符串文本,比如英文句子,句子当中有一个个的单词在里面。这样的数据我们是不能直接使用的,需要先将其变成one-hot编码的形式,然后再变成一个向量(比如300维的一个向量),可以把这个向量理解成向量每个维度都包含着这个单词不同的特征。然后这些特征可以通过学习得到,我们所需要的就是一个个单词具有这样特征的向量,也就是embedding矩阵。
那么接下来就是得到embedding的方法了,这里采用的是Skip-gram,我们先来看一张图:
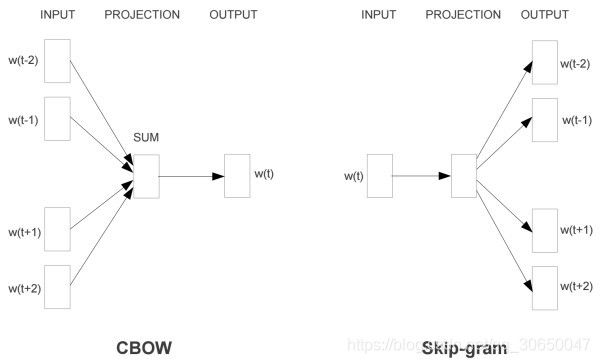
我们可以选择一个取样的大小n,比如n=2,那么意思就是选择一个当前的词,然后找到这个单词前两个和后两个单词作为输出,也就是一个中心词可以对应2n个输入输出对,然后把数据再拿来训练就好了。

2. 模型
网络的结构如下,由输入的one-hot编码直接线性变换到隐藏层,然后再线性变换到输出层,最后再将网络的结果通过softmax层得到最后的概率分布结果。
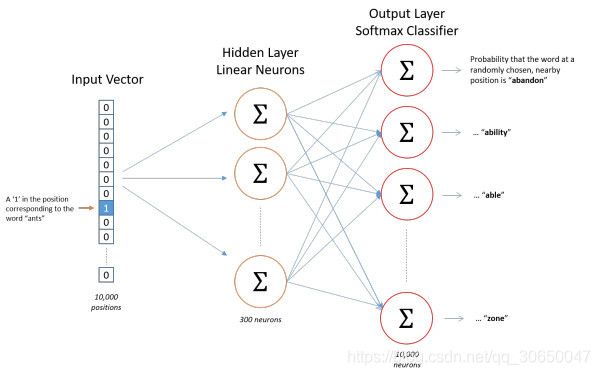
2.1 模型的前向传播
首先看前向传播的公式:
![]()
然后再经过softmax层到最终的输出:
![]()
2.2 模型的反向传播
首先确定损失函数,因为模型的计算结果类似于一个多分类问题,所以采用交叉熵损失函数(CrossEntropyLoss)
![]()
p就是真实结果的向量,只有一个位置是1,其他位置都是0,其实上图是单个元素相乘的公式,其实也就是两个向量做内积运算:
![]()
然后可以开始进行求导了。先求W的导数:

交叉熵损失函数的求导部分的推导请看这里,可以直接得到:

其中:
![]()
然后又有:
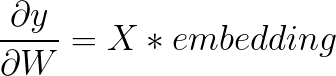
所以得到:

同理可有:

3. 模型的代码实现
模型的代码实现方面的话,主要就是NNLM类的实现和各种参数矩阵的维度。首先解释一下各种变量的含义。
N_HIDDEN:网络隐藏层的维度,也就是每个单词embedding的维数
N_CLASS:总共单词的个数
lr:网络的学习率
然后再明确一下各个参数矩阵的维度:
X:(1, N_CLASS)
W:(N_CLASS, N_HIDDEN)
embedding: (N_CLASS, N_HIDDEN)
首先我们来看网络的初始化部分:
# model.py
def __init__(self):
self.x = np.random.random((1, N_CLASS))
self.embedding = np.random.random((N_CLASS, N_HIDDEN))
self.w = np.random.random((N_CLASS, N_HIDDEN))
self.y = np.random.random((N_CLASS, 1))
self.S = np.random.random((N_CLASS, 1))
self.D = np.random.random((N_CLASS, 1))
self.loss = np.random.random((1, 1))
然后就是计算交叉熵loss的函数:
# model.py
def cal_loss(self, target, predict):
predict = np.log(predict
return -np.dot(target.T, predict)
接下来是前向传播,也就是前面前向传播公式的计算:
# model.py
def forward(self, x):
self.x = x
self.y = np.dot(self.w, (np.dot(self.x, self.embedding)).T)
predict = softmax(self.y)
self.S = predict
return predict
接下来是反向传播的部分,这里其实就是对前面数学公式的实现罢了,看懂了公式的话这里应该还是很好懂的。
# model.py
def backward(self, output, lr):
self.loss = self.cal_loss(output, self.S)
self.D = self.S - output
dLoss_w = np.dot(self.D, np.dot(self.x, self.embedding))
dLoss_emb = np.dot(self.D, np.dot(self.x, self.w))
self.w -= lr * dLoss_w
self.embedding -= lr * dLoss_emb
模型部分的代码已经写好了,剩下要做的就是用一个例子去验证一下。这里只使用了前面提到的比较小的样本去测试:
# train.py
[
"i like dog", "i like cat", "i like animal",
"dog cat animal", "apple cat dog like", "dog fish milk like",
"dog cat eyes like", "i like apple", "apple i hate",
"apple i movie book music like", "cat dog hate", "cat dog like"
]
接下来就是网络的训练:
# train.py
model = Word2Vec()
for epoch in range(30000):
for i in range(len(input_batch)):
model.forward(input_batch[i])
model.backward(output_batch[i], 0.01)
if (epoch + 1) % 500 == 0:
print('Epoch: ', '%04d' % (epoch + 1), ', Loss: ', model.loss[0][0])
4. 效果
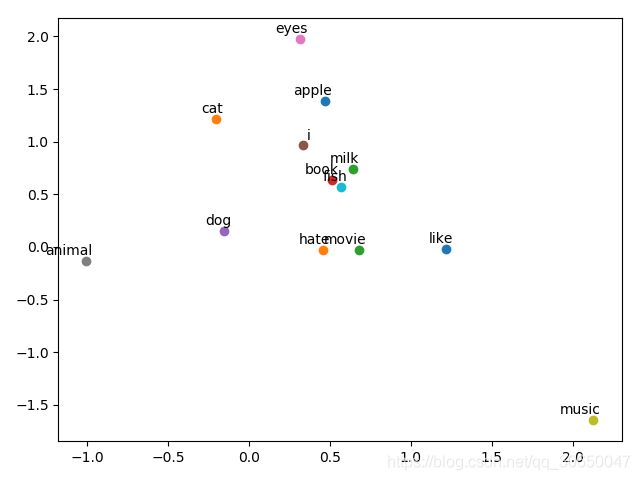
最后附上github地址