VAE详解
VAE原理
首先就是VAE的原理部分了,VAE的目的就是将训练的时候将输入映射到latent vector,然后再将latent vector映射到一个高斯分布上面去从而得到z,再将得到的z通过decoder得到和输入模态相同的数据。
分布变换
我们拿一句话来举例子,假设这句话是"I love you",那么这句话就是输入,输入数据有三个词分别是"I",“love”,“you”,我们通过encoder得到这句话中每个单词的embedding,然后VAE就会根据每个单词的embedding去学习其对应的高斯分布,其实具体来说就是学两个东西,均值和方差,也就是说当网络学习好了之后你给我一个单词的embedding,我就能告诉你对应的均值和方差。得到均值和方差之后,我其实就是得到了一个高斯分布,然后我再在这个高斯分布中采样得到向量z,然后再通过z去decode得到我想要的采样输出,在这个例子中,采样输出也就是一个单词了。
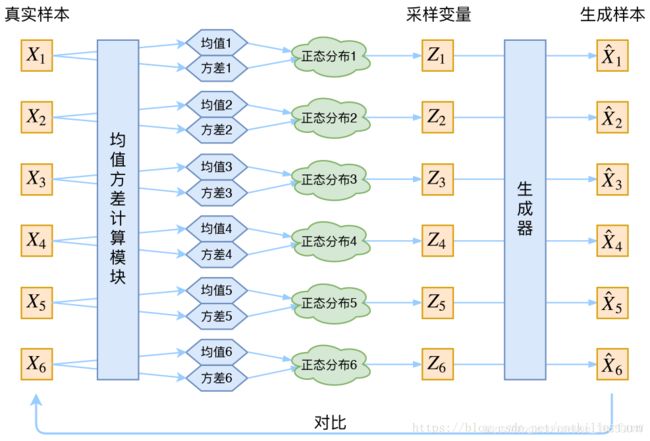
这个时候有人就要问了,为什么要给每个输入X都去计算一个高斯分布呢,用所有的X生成一个高斯分布不就好了,然后再去采样得到Z,然后再decode得到我的输出。这样做的问题就是,生成Z之后你不知道你的Z应该对应哪个X,难道Z1在时间上先生成就应该对应X1吗?这样做也是没有意义的,因此才要计算多个分布。

损失函数
假如这个时候我们仅仅拿重构的结果X’和X计算损失函数,那么会出问题。因为这样的话通过不断地训练,每次训练我都希望我生成的X’和真正X尽可能像,那么最后就会出现一个情况,那就是训练出来的均值是固定的,方差为0,这样我每次采样得到的Z都是固定的且正确的Z,那么我们就得到了什么样的结果呢?我们得到了6个均值(以上图为例),且方差都为0,也就是说我们不管怎么采样,最后其实都最多只能得到6个不同的Z,这样显然是不合理的,因为模型失去了生成的能力。
那么这个时候该怎么做呢?我们需要让每个高斯分布的方差不趋向于0,而是让每个高斯分布尽可能的趋向于标准正态分布,具体的操作也就是加上计算出来的高斯分布和标准正态分布的KL散度,两个分布之间越相近,kl_loss的值就越小。这样做的目的就是和之前那部分的loss进行“制衡”,因为前者希望稳定希望每次都能正确地重构,也就是方差为零;后者希望模型具有生成能力,所以不希望方差为0,所以通过两者相加就组成了VAE的loss function。
代码示例
下面是一个encoder和decoder都基于GRU的VAE的代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, vocab, config):
super().__init__()
self.vocabulary = vocab
# Special symbols
for ss in ('bos', 'eos', 'unk', 'pad'):
setattr(self, ss, getattr(vocab, ss))
# Word embeddings layer
n_vocab, d_emb = len(vocab), vocab.vectors.size(1)
self.x_emb = nn.Embedding(n_vocab, d_emb, self.pad)
self.x_emb.weight.data.copy_(vocab.vectors)
if config.freeze_embeddings:
self.x_emb.weight.requires_grad = False
# Encoder
# 这里通过GRU去对输入做encode,将原始输入其变成latent vector
if config.q_cell == 'gru':
self.encoder_rnn = nn.GRU(
d_emb,
config.q_d_h,
num_layers=config.q_n_layers,
batch_first=True,
dropout=config.q_dropout if config.q_n_layers > 1 else 0,
bidirectional=config.q_bidir
)
else:
raise ValueError(
"Invalid q_cell type, should be one of the ('gru',)"
)
q_d_last = config.q_d_h * (2 if config.q_bidir else 1)
# 通过一个线性层去计算高斯分布的均值和方差(方差取了log)
# 线性层的输入就是latent vector
self.q_mu = nn.Linear(q_d_last, config.d_z)
self.q_logvar = nn.Linear(q_d_last, config.d_z)
# Decoder
# 将Z解码成和输入模态相同的数据,这里用的也是GRU
if config.d_cell == 'gru':
self.decoder_rnn = nn.GRU(
d_emb + config.d_z,
config.d_d_h,
num_layers=config.d_n_layers,
batch_first=True,
dropout=config.d_dropout if config.d_n_layers > 1 else 0
)
else:
raise ValueError(
"Invalid d_cell type, should be one of the ('gru',)"
)
self.decoder_lat = nn.Linear(config.d_z, config.d_d_h)
self.decoder_fc = nn.Linear(config.d_d_h, n_vocab)
# Grouping the model's parameters
self.encoder = nn.ModuleList([
self.encoder_rnn,
self.q_mu,
self.q_logvar
])
self.decoder = nn.ModuleList([
self.decoder_rnn,
self.decoder_lat,
self.decoder_fc
])
self.vae = nn.ModuleList([
self.x_emb,
self.encoder,
self.decoder
])
@property
def device(self):
return next(self.parameters()).device
def string2tensor(self, string, device='model'):
ids = self.vocabulary.string2ids(string, add_bos=True, add_eos=True)
tensor = torch.tensor(
ids, dtype=torch.long,
device=self.device if device == 'model' else device
)
return tensor
def tensor2string(self, tensor):
ids = tensor.tolist()
string = self.vocabulary.ids2string(ids, rem_bos=True, rem_eos=True)
return string
def forward(self, x):
"""Do the VAE forward step
:param x: list of tensors of longs, input sentence x
:return: float, kl term component of loss
:return: float, recon component of loss
"""
# Encoder: x -> z, kl_loss
z, kl_loss = self.forward_encoder(x)
# Decoder: x, z -> recon_loss
recon_loss = self.forward_decoder(x, z)
return kl_loss, recon_loss
def forward_encoder(self, x):
"""Encoder step, emulating z ~ E(x) = q_E(z|x)
:param x: list of tensors of longs, input sentence x
:return: (n_batch, d_z) of floats, sample of latent vector z
:return: float, kl term component of loss
"""
x = [self.x_emb(i_x) for i_x in x]
x = nn.utils.rnn.pack_sequence(x)
# 通过下面的操作得到latent vector也就是下面的h
_, h = self.encoder_rnn(x, None)
h = h[-(1 + int(self.encoder_rnn.bidirectional)):]
h = torch.cat(h.split(1), dim=-1).squeeze(0)
# 通过h去得到一个高斯分布
mu, logvar = self.q_mu(h), self.q_logvar(h)
eps = torch.randn_like(mu)
# 采样得到Z
z = mu + (logvar / 2).exp() * eps
# 计算当前计算出来的分布和标准正态分布之间kl_loss
kl_loss = 0.5 * (logvar.exp() + mu ** 2 - 1 - logvar).sum(1).mean()
return z, kl_loss
def forward_decoder(self, x, z):
"""Decoder step, emulating x ~ G(z)
:param x: list of tensors of longs, input sentence x
:param z: (n_batch, d_z) of floats, latent vector z
:return: float, recon component of loss
"""
lengths = [len(i_x) for i_x in x]
x = nn.utils.rnn.pad_sequence(x, batch_first=True,
padding_value=self.pad)
x_emb = self.x_emb(x)
z_0 = z.unsqueeze(1).repeat(1, x_emb.size(1), 1)
x_input = torch.cat([x_emb, z_0], dim=-1)
x_input = nn.utils.rnn.pack_padded_sequence(x_input, lengths,
batch_first=True)
h_0 = self.decoder_lat(z)
h_0 = h_0.unsqueeze(0).repeat(self.decoder_rnn.num_layers, 1, 1)
output, _ = self.decoder_rnn(x_input, h_0)
output, _ = nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
y = self.decoder_fc(output)
recon_loss = F.cross_entropy(
y[:, :-1].contiguous().view(-1, y.size(-1)),
x[:, 1:].contiguous().view(-1),
ignore_index=self.pad
)
return recon_loss
def sample_z_prior(self, n_batch):
"""Sampling z ~ p(z) = N(0, I)
:param n_batch: number of batches
:return: (n_batch, d_z) of floats, sample of latent z
"""
return torch.randn(n_batch, self.q_mu.out_features,
device=self.x_emb.weight.device)
def sample(self, n_batch, max_len=100, z=None, temp=1.0):
"""Generating n_batch samples in eval mode (`z` could be
not on same device)
:param n_batch: number of sentences to generate
:param max_len: max len of samples
:param z: (n_batch, d_z) of floats, latent vector z or None
:param temp: temperature of softmax
:return: list of tensors of strings, samples sequence x
"""
with torch.no_grad():
if z is None:
z = self.sample_z_prior(n_batch)
z = z.to(self.device)
z_0 = z.unsqueeze(1)
# Initial values
h = self.decoder_lat(z)
h = h.unsqueeze(0).repeat(self.decoder_rnn.num_layers, 1, 1)
w = torch.tensor(self.bos, device=self.device).repeat(n_batch)
x = torch.tensor([self.pad], device=self.device).repeat(n_batch,
max_len)
x[:, 0] = self.bos
end_pads = torch.tensor([max_len], device=self.device).repeat(
n_batch)
eos_mask = torch.zeros(n_batch, dtype=torch.uint8,
device=self.device)
# Generating cycle
for i in range(1, max_len):
x_emb = self.x_emb(w).unsqueeze(1)
x_input = torch.cat([x_emb, z_0], dim=-1)
o, h = self.decoder_rnn(x_input, h)
y = self.decoder_fc(o.squeeze(1))
y = F.softmax(y / temp, dim=-1)
w = torch.multinomial(y, 1)[:, 0]
x[~eos_mask, i] = w[~eos_mask]
i_eos_mask = ~eos_mask & (w == self.eos)
end_pads[i_eos_mask] = i + 1
eos_mask = eos_mask | i_eos_mask
# Converting `x` to list of tensors
new_x = []
for i in range(x.size(0)):
new_x.append(x[i, :end_pads[i]])
return [self.tensor2string(i_x) for i_x in new_x]