揭秘zm朋友圈-用数据分析获得真相
用python爬取自己朋友圈,用数据分析审视自己
还记得前几年大家还是使用QQ,不知道从何时起,大家都开始使用微信,关注着从幼儿园到研究生各种同学的动态,感受着不同朋友的有趣
学习太累人了,尤其是学到这么大年纪还要学习真是¥%*@#¥%@
不过将学习结合到有趣的事情我还是十分乐意的
于是就有了这篇文章,数据分析+我的朋友圈
这篇文章,我用python爬取了我本人的微信朋友圈数据,使用一些数据处理的库来分析揭秘我朋友圈的真相(代码附在最后)

首先,从基础信息分析看起,我利用itchat库获取了我433位好友的信息,包括昵称,备注,地区,个性签名等等。先放张图吧(这么高糊,应该就看不清个人信息了吧)

好友性别

计算了下我好友中的性别比例,还不错哎,比我想象中好太多了,毕竟工科女,从大学到研究生一路来都是各种男同学,原来姐妹还挺多。说到这个性别问题,必须强调一下,为什么到了研究生性别不均衡问题更加严重了?自从师姐毕业了,我老师这只剩下我这一个女生,每次开会都只有我一个女生,太孤独了吧。
地区分布


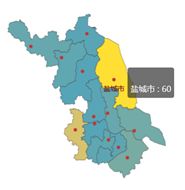
我的好友主要集中在江苏及周边地区,毕竟我是江苏人,大学在南京,现在在上海,绕来绕去都没绕出过包邮区。
盐城,一个让人敞开心扉的地方(我家的宣传标语),欢迎大家来我家玩。
盐城60人,南京44人,这两地方就构成了我所有好友的四分之一,我爱我家

个性签名
从很多年前开始用的QQ上就有设置个性签名的功能
忍不住给大家展示一个浓浓非主流味的个签
\\~’ ㄍ· 眼淚,蔵甾沉黙背後。つ
﹃種溫度.《絲念〉·諟種病。っ
我很喜欢看不同朋友的个签,一句话,虽然短,但可以看出不同好友不同的性格、境况,甚至职业。比如我做了老师的姐妹,直接把个签改成自己电话号码了,毕竟她的好友圈都变成了学生和家长了。姐妹2,“此时此刻的云,二十来岁的你”,一看就知道这个姐妹是个文艺少女哈哈!
为了分析我朋友圈的总体个签风格,我用python中的itchat库爬取每个好友的个性签名(这个库很好的兼容了wechat个人账号的API接口,让我们能更加便捷的爬取python数据),生成可视化词云图,直观的给出个签中关键字词频图,最后调用snownlp情感分析包分析出微信好友中个签正负面比例。

这个代购,店铺吓到我了,原来我朋友圈代购微商这么多啊哈哈哈哈
大家还是很爱生活的,努力,生活,美好,开心都是个签中的高频词!
最后算一下我朋友圈中个签的正负面比例,负面个签比例: 7.75% 中性个签比例: 82.76% 正面个签比例: 9.50%。

生活中总会有很多不开心的事发生,希望那7.75%的朋友们能积极一点,毕竟生活还有烧烤火锅肉夹馍,他们很值得!
头像
幸好微信没有换头像次数限制,我真是换的太勤了,之前迷信了下锦鲤,从众的换成了杨超越,没过半天,我妈就来问候我,吓得我又换回去了
我使用的是腾讯优图提供的人脸识别技术,对头像进行检测和分析,首先获取了所有好友的头像存储至文件夹:
对头像进行人脸检测,检测头像图片中是否存在人脸,统计使用人脸作用头像的占比,在人脸检测时速度较慢,需要耐心等待。
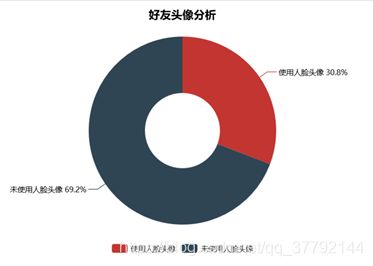
结果出来啦!原来有30.8%的朋友们都是用的人脸图做头像,至于是自拍照还是用的别人的图?这个我可分析不出来啦,给大家看看我最爱用的人脸头像!


我的权律2真是太可爱了,妈妈爱你!
最后我选取了256个程序随机选取的好友头像拼接成了一幅大图(仿佛256人的群聊),快找找有没有你们自己的头像?如果有,恭喜你,今天你也幸运了。

下面这个问题太私密了
“特殊好友”
不知名女学生zm即将爆料自己到底拉黑了谁

其实我不看和不让看的都是代购和微商而已哈哈,毕竟我朋友圈那么多代购微商,不屏蔽的话我这朋友圈就得整天被刷屏了。6位星标朋友,恭喜你们,你们从433位好友中脱颖而出,C位了!
本来还想分析朋友们设置三天可见半年可见的那些数据情况的,但是最近没空再继续啦,后面有时间我再来补充!
最后,感谢朋友们能看到这个环节,希望大家都能热爱生活,有一点热爱学习,送上我的表情包!

******************************************************************************************************************************************
代码分享
使用到的库有:
import pandas as pd
import itchat
from pyecharts.charts.pie import Pie
from pyecharts.charts.map import Map
from pyecharts.page import Page
from pyecharts.charts.bar import Bar
import jieba
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import numpy
import PIL.Image as Image
import os
import re
from snownlp import SnowNLP
from snownlp import sentiment
import time
import requests
def get_attr(friends, key):
return list(map(lambda user: user.get(key), friends))
def get_friends():
itchat.auto_login(hotReload=True)
friends = itchat.get_friends()
users = dict(province=get_attr(friends, "Province"),
city=get_attr(friends, "City"),
nickname=get_attr(friends, "NickName"),
sex=get_attr(friends, "Sex"),
signature=get_attr(friends, "Signature"),
remarkname=get_attr(friends, "RemarkName"),
pyquanpin=get_attr(friends, "PYQuanPin"),
displayname=get_attr(friends, "DisplayName"),
isowner=get_attr(friends, "IsOwner"))
return users
#性别
def sex_stats(users):
df = pd.DataFrame(users)
sex_arr = df.groupby(['sex'], as_index=True)['sex'].count()
data = dict(zip(list(sex_arr.index), list(sex_arr)))
data['不告诉你!'] = data.pop(0)
data['男生'] = data.pop(1)
data['姐妹'] = data.pop(2)
return data.keys(), data.values()
#地区1
def prov_stats(users):
prv = pd.DataFrame(users)
prv_cnt = prv.groupby('province', as_index=True)['province'].count().sort_values()
attr = list(map(lambda x: x if x != '' else '未知', list(prv_cnt.index)))
return attr, list(prv_cnt)
#地区2
def gd_stats(users):
df = pd.DataFrame(users)
data = df.query('province == "江苏"')
res = data.groupby('city', as_index=True)['city'].count().sort_values()
attr = list(map(lambda x: '%s市' % x if x != '' else '未知', list(res.index)))
return attr, list(res)
#画图
def create_charts():
users = get_friends()
page = Page()
#性别
data = sex_stats(users)
attr, value = data
chart = Pie('微信性别') # title_pos='center'
chart.add('', attr, value, center=[50, 50],
radius=[30, 70], is_label_show=True, legend_orient='horizontal', legend_pos='center',
legend_top='bottom', is_area_show=True)
page.add(chart)
#中国地图
data = prov_stats(users)
attr, value = data
chart = Map('中国地图',width=1100, height=600)
chart.add('', attr, value, is_label_show=True, is_visualmap=True, visual_text_color='#000')
page.add(chart)
chart = Bar('柱状图',width=900, height=500)
chart.add('', attr, value, is_stack=True, is_convert=True, label_pos='inside', is_legend_show=True,
is_label_show=True)
page.add(chart)
#江苏地图
data = gd_stats(users)
attr, value = data
chart = Map('江苏',width=1100, height=600)
chart.add('', attr, value, maptype='江苏', is_label_show=True, is_visualmap=True, visual_text_color='#000')
page.add(chart)
chart = Bar('柱状图',width=900, height=500)
chart.add('', attr, value, is_stack=True, is_convert=True, label_pos='inside', is_label_show=True)
page.add(chart)
page.render()
#分词
def jieba_cut(users):
signature = users['signature']
words = ''.join(signature)
res_list = jieba.cut(words, cut_all=True)
return res_list
#词云图
def create_wc(words_list):
#res_path = os.path.abspath('./../resource')
#res_path = os.path.abspath('C:\Users\zm\Desktop')
words = ' '.join(words_list)
# back_pic = numpy.array(Image.open("%s/china1.png" % res_path))
back_pic = numpy.array(Image.open("C:/Users/zm/Desktop/数据分析/tu.jpg"))
stopwords = set(STOPWORDS)
stopwords = stopwords.union(set(['class', 'span', 'amp','emoji', 'gua','emoji', 'emoji1f388','emoji2600', 'emoji2764','emoji1f604', 'emoji1f436']))
wc = WordCloud(background_color="white", margin=2,
#font_path='%s/hanyiqihei.ttf' % res_path,
#font_path="C:/Windows/Fonts/STFANGSO.ttf" ,
font_path="simhei.ttf",
mask=back_pic,
max_font_size=150,
stopwords=stopwords,
max_words=100).generate(words)
# image_colors = ImageColorGenerator(back_pic)
plt.imshow(wc)
# plt.imshow(wc.recolor(color_func=image_colors))
plt.axis('off')
plt.show()
#情感分析
emotions = []
for word in words:
nlp = SnowNLP(word)
emotions.append(nlp.sentiments)
count_good = len(list(filter(lambda x:x>0.66,emotions))) # 正面情感统计
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions))) # 中性情感统计
count_bad = len(list(filter(lambda x:x<0.33,emotions))) # 负面情感统计 # 计算情感比例值
t1,t2,t3=count_good * 100/len(emotions),count_normal * 100/len(emotions),count_bad * 100/len(emotions)
print('负面个签比例:','%.2f'%t1)
print('中性个签比例:','%.2f'%t2)
print('正面个签比例:','%.2f'%t3)
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title("zm的微信好友签名信息情感分析")
plt.savefig("analyseSignatureEmotional.jpg")
plt.show()
#头像部分处理
class FaceAPI:
def __init__(self):
appid = '10109383'
userId = '875974254'
secretId = 'AKIDd3D8rKrzCAsKXXKn8E5i6EAsLYVCuoiP'
secretKey = 'ZtwjGYbP1PYT9anmV3MRGrCKDuPffOr4'
endPoint = TencentYoutuyun.conf.API_YOUTU_END_POINT
self.youtu = TencentYoutuyun.YouTu(appid, secretId, secretKey, userId, endPoint)
def detectFace(self,image):
try:
retocr = self.youtu.DetectFace(image)
return len(retocr['face'])>0
except Exception as e:
return false
def extractTags(self,image):
try:
retocr = self.youtu.imagetag(image)
return retocr['tags']
except Exception as e:
return None
def analyseHeadImage():
# Init Path
itchat.auto_login(hotReload=True)
#获取朋友列表,返回字典类型的数据集,获取好友的索引数
#friends = itchat.get_friends(update=True)[0:256]
friends = itchat.get_friends(update=True)[:]
basePath = os.path.abspath('.')
baseFolder = basePath + '\\user\\'
if not os.path.exists(baseFolder) :
# if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if not os.path.exists(imgFile):
# if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.savefig("analyseHeadImage.jpg")
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open("C:/Users/zm/Desktop/数据分析/tu.jpg"))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=85,
random_state=75,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig("wordcloudHeadImage.jpg")
plt.show()
def get_imgs():#完成主要的下载头像的任务
#使用热登录(已经登录的程序,再一次运行程序不需要扫描验证码),执行这一步就会有二维码需要扫描登录
itchat.auto_login(hotReload=True)
#获取朋友列表,返回字典类型的数据集,获取好友的索引数
#friends = itchat.get_friends(update=True)[0:256]
friends = itchat.get_friends(update=True)[:]
#为图片命名的变量
num = 0
#遍历好友列表
for i in friends:
#获取好友的头像
img = itchat.get_head_img(userName=i["UserName"])
#在项目文件的主创建一个user文件用于放头像,并写入对应的图片名,空白的
fileImage = open( "./user/" + str(num) + ".jpg",'wb')
#将获取到的头像文件写到创建的图片文件中
fileImage.write(img)
#关闭资源
fileImage.close()
num += 1
#制作大的大头像
def get_big_img():
pics = listdir("user") #获取usr文件夹所有文件的名称
numPic = len(pics)
toImage = Image.new("RGB", (800, 800))#创建图片大小
x = 0 #用于图片的位置
y = 0
for i in pics: #遍历user文件夹的图片
try:
img = Image.open("user/{}".format(i))
#img=open("user/{}".format(i)) #依次打开图片
except IOError:
print("Error: 没有找到文件或读取文件失败",i)
else:
img = img.resize((50, 50), Image.ANTIALIAS)#重新设置图片的大小
toImage.paste(img, (x * 50, y * 50)) #将图片粘贴到最后的大图片上,需要注意对应的位置
x += 1
if x == 16: #设置每一行排16个图像
x = 0
y += 1
toImage.save("user/" +"bigPhoto.jpg") #保存图片为bigPhoto.jpg
itchat.send_image("user/" +"bigPhoto.jpg", 'filehelper') #将做好图片发送东自己的手机上
#好友分类部分
def get_data():
# 扫描二维码登陆微信,实际上就是通过网页版微信登陆
itchat.auto_login()
# 获取所有好友信息
friends = itchat.get_friends(update=True) # 返回一个包含用户信息字典的列表
return friends
# 处理数据
def parse_data(data):
friends = []
for item in data[1:]: # 第一个元素是自己,排除掉
friend = {
'NickName': item['NickName'], # 昵称
'RemarkName': item['RemarkName'], # 备注名
'Sex': item['Sex'], # 性别:1男,2女,0未设置
'Province': item['Province'], # 省份
'City': item['City'], # 城市
'Signature': item['Signature'].replace('\n', ' ').replace(',', ' '), # 个性签名(处理签名内容换行的情况)
'StarFriend': item['StarFriend'], # 星标好友:1是,0否
'ContactFlag': item['ContactFlag'] # 好友类型及权限:1和3好友,259和33027不让他看我的朋友圈,65539不看他的朋友圈,65795两项设置全禁止
}
print(friend)
friends.append(friend)
return friends
# 存储数据,存储到文本文件
def save_to_txt():
friends = parse_data(get_data())
for item in friends:
with open('friends.txt', mode='a', encoding='utf-8') as f:
f.write('%s,%s,%d,%s,%s,%s,%d,%d\n' % (
item['NickName'], item['RemarkName'], item['Sex'], item['Province'], item['City'], item['Signature'],
item['StarFriend'], item['ContactFlag']))
# 获取特殊好友
star_list = [] # 星标朋友
deny_see_list = [] # 不让他看我的朋友圈
no_see_list = [] # 不看他的朋友圈
with open('friends.txt', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
# # 获取好友名称
name = row.split(',')[1] if row.split(',')[1] != '' else row.split(',')[0]
# 获取星标朋友
star = row.split(',')[6]
if star == '1':
star_list.append(name)
# 获取设置了朋友圈权限的朋友
flag = row.split(',')[7].replace('\n', '')
if flag in ['259', '33027', '65795']:
deny_see_list.append(name)
if flag in ['65539', '65795']:
no_see_list.append(name)
print('星标好友:', star_list)
print('不让他看我的朋友圈:', deny_see_list)
print('不看他的朋友圈:', no_see_list)
attr = ['星标朋友', '不让他看我的朋友圈', '不看他的朋友圈']
value = [len(star_list), len(deny_see_list), len(no_see_list)]
bar = Bar('特殊好友分析', '', title_pos='center')
bar.add('', attr, value, is_visualmap=True, is_label_show=True)
bar.render('特殊好友分析.html')