WGAN(Wasserstein GAN)
W G A N ( W a s s e r s t e i n G A N ) WGAN(Wasserstein GAN) WGAN(WassersteinGAN)
https://arxiv.org/abs/1701.07875
https://zhuanlan.zhihu.com/p/25071913
GAN现在是机器学习中非常热门的研究课题。
一般有两种类型的GAN研究:
- 一种是在各种各样的问题中应用GAN,
- 另一种是试图稳定GAN的训练。
稳定GAN的训练过程是一个非常重要的事情
原始GAN训练过程中经常遇到的问题:
- 一 模式崩溃,生成器生成非常窄的分布,仅覆盖数据分 布中的单一模式。 模式崩溃的含义是
生成器只能生成非常相似的样本(例如, MNIST中的单个数字), 即生成的样本不是多样的。
比如只能生成图片1
- 二 没有指标可以告诉我们收敛情况。生成器和判别器的 loss并没有告诉我们任何收敛相关信息。当然,我们可以通
过不时地查看生成器生成的数据来监控训练进度。 但是, 这是一个手动过程。因此,我们需要有一个可解释的指标 可以告诉我们有关训练的进度。
原始GAN形式的问题
一句话概括:判别器越好,生成器梯度消失越严重。


原始GAN问题的根源可以归结为两点,
- 一是等价优化的距离衡量(JS散度) 不合理
- 二是生成器随机初始化后的生成分布很难与真实分布有不可 忽略的重叠。
解决问题的关键在于使用Wasserstein距离
- 衡量两个分布之间的距离 Wasserstein距离优越性在于: 即使两个分布没有任何重叠,也可以反应他们之间的距离
Wasserstein距离:
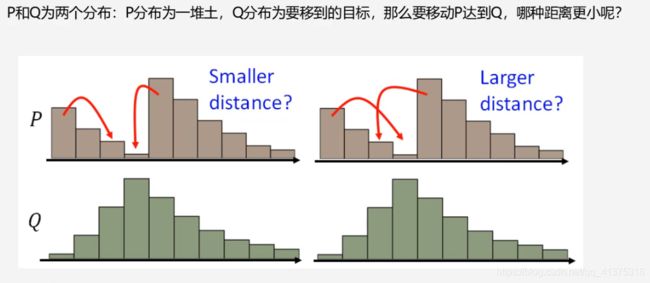



WGAN设计


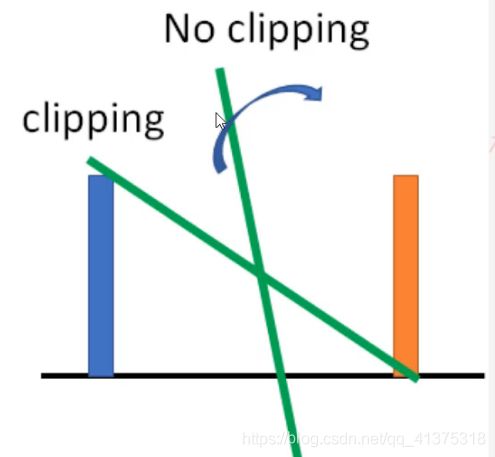

WGAN的实现
一、判别器最后一层去掉sigmoid
二、生成器和判别器的loss不取log
三、每次更新判别器的参数之后把它们的值截断到不超过一个固定常数c
四、不要用基于动量的优化算法(包括momentum和Adam), 推荐RMSProp
RMSProp适合梯度不稳定的情况。
- WGAN本作弓|入了Wasserstein距离,由于它相对KL散度与JS 散度具有优越的平滑特性,理论上可以解决梯度消失问题。接
着通过数学变换将Wasserstein距离写成可求解的形式,利用 一一个参数数值范围受限的判别器神经网络来较大化这个形式,
就可以近似Wasserstein距离。
- WGAN既解决了训练不稳定的问题,也提供了一个可靠的训 练进程指标,而且该指标确实与生成样本的质量高度相关。
LSGAN、BEGAN也是稳定训练的GAN,但与WGAN并没有本质上的区别
代码
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
import os
os.listdir('../input/anime-faces/data/data')[:10]

print('Tensorflow version: {}'.format(tf.__version__))
![]()
image_path = glob.glob('../input/anime-faces/data/data/*.png')
len(image_path)
![]()
def load_preprosess_image(path):
image = tf.io.read_file(path)
image = tf.image.decode_png(image, channels=3)
# image = tf.image.resize_with_crop_or_pad(image, 256, 256)
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
image_ds = tf.data.Dataset.from_tensor_slices(image_path)
AUTOTUNE = tf.data.experimental.AUTOTUNE
image_ds = image_ds.map(load_preprosess_image, num_parallel_calls=AUTOTUNE)
image_ds
![]()
BATCH_SIZE = 256
image_count = len(image_path)
image_ds = image_ds.shuffle(image_count).batch(BATCH_SIZE)
image_ds = image_ds.prefetch(AUTOTUNE)
def generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(8*8*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((8, 8, 256))) #8*8*256
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) #8*8*128
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) #16*16*128
model.add(layers.Conv2DTranspose(32, (5, 5), strides=(2, 2), padding='same', use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) #32*32*32
model.add(layers.Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
#64*64*3
return model
generator = generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
#plt.imshow((generated_image[0, :, :, :3] + 1)/2)
def discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(32, (5, 5), strides=(2, 2), padding='same',
input_shape=[64, 64, 3]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3)) # 32*32*32
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3)) # 16*16*64
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# model.add(layers.Dropout(0.3)) # 8*8*128
model.add(layers.Conv2D(256, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU()) # 4*4*256
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(1024))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(1))
return model
discriminator = discriminator_model()
decision = discriminator(generated_image)
print(decision)
![]()
def discriminator_loss(real_output, fake_output):
return tf.reduce_mean(fake_output) - tf.reduce_mean(real_output)
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.RMSprop(1e-4)
discriminator_optimizer = tf.keras.optimizers.RMSprop(5e-5)
EPOCHS = 800
noise_dim = 100
num_examples_to_generate = 4
seed = tf.random.normal([num_examples_to_generate, noise_dim])
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
for idx, grad in enumerate(gradients_of_discriminator):
gradients_of_discriminator[idx] = tf.clip_by_value(grad, -0.01, 0.01)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(6, 6))
for i in range(predictions.shape[0]):
plt.subplot(2, 2, i+1)
plt.imshow((predictions[i, :, :, :] + 1)/2)
plt.axis('off')
# plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
epoch_loss_avg_gen = tf.keras.metrics.Mean('g_loss')
epoch_loss_avg_disc = tf.keras.metrics.Mean('d_loss')
g_loss_results = []
d_loss_results = []
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch in dataset:
g_loss, d_loss = train_step(image_batch)
epoch_loss_avg_gen(g_loss)
epoch_loss_avg_disc(d_loss)
g_loss_results.append(epoch_loss_avg_gen.result())
d_loss_results.append(epoch_loss_avg_disc.result())
epoch_loss_avg_gen.reset_states()
epoch_loss_avg_disc.reset_states()
# print('.', end='')
# print()
if epoch%10 == 0:
# print('epoch:', epoch, 'g_loss:', g_loss, 'd_loss:', d_loss)
generate_and_save_images(generator,
epoch + 1,
seed)
generate_and_save_images(generator,
epochs,
seed)
train(image_ds, EPOCHS)

plt.plot(range(1, len(g_loss_results)+1), g_loss_results, label='g_loss')
plt.plot(range(1, len(d_loss_results)+1), d_loss_results, label='d_loss')
plt.legend()
