ARM和MIPS架构
ARM体系
1、历史
1978年12月5日,物理学家赫尔曼·豪泽(Hermann Hauser)和工程师Chris Curry,在英国剑桥创办了CPU公司(Cambridge Processing Unit),主要业务是为当地市场供应电子设备。

1979年,CPU公司改名为Acorn计算机公司。

起初,Acorn公司打算使用摩托罗拉公司的16位芯片,但是发现这种芯片太慢也太贵。"一台售价500英镑的机器,不可能使用价格100英镑的CPU!"他们转而向Intel公司索要80286芯片的设计资料,但是遭到拒绝,于是被迫自行研发。(Intel会不会为当年的这个决定后悔万分?)
1985年,Roger Wilson和Steve Furber设计了他们自己的第一代32位、6M Hz的处理器,用它做出了一台RISC指令集的计算机,简称ARM(Acorn RISC Machine)。这就是ARM这个名字的由来。

RISC的全称是"精简指令集计算机"(reduced instruction set computer),它支持的指令比较简单,所以功耗小、价格便宜,特别合适移动设备。早期使用ARM芯片的典型设备,就是苹果公司的牛顿PDA。
1990年11月27日,Acorn公司正式改组为ARM计算机公司。苹果公司出资150万英镑,芯片厂商VLSI出资25万英镑,Acorn本身则以150万英镑的知识产权和12名工程师入股。公司的办公地点非常简陋,就是一个谷仓。


公司成立后,业务一度很不景气,工程师们人心惶惶,担心将要失业。由于缺乏资金,ARM做出了一个意义深远的决定:自己不制造芯片,只将芯片的设计方案授权(licensing)给其他公司,由它们来生产。正是这个模式,最终使得ARM芯片遍地开花,将封闭设计的Intel公司置于"人民战争"的汪洋大海。
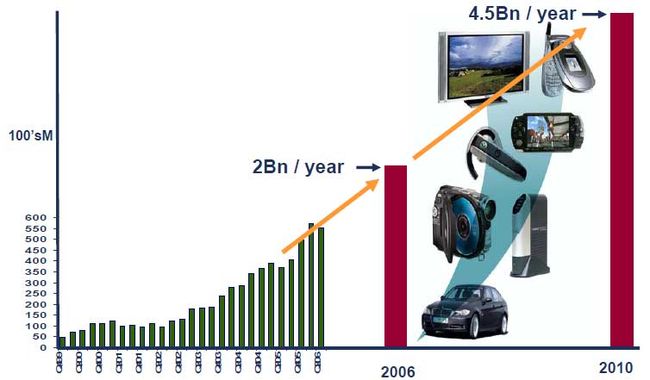
20世纪90年代,ARM公司的业绩平平,处理器的出货量徘徊不前。但是进入21世纪之后,由于手机的快速发展,出货量呈现爆炸式增长,ARM处理器占领了全球手机市场。2006年,全球ARM芯片出货量为20亿片,2010年预计将达到45亿片。
2007年底,ARM的雇员总数为1728人,持有专利700项(另有900项正在申请批准中),全球分支机构31家,合作伙伴200家,年收入2.6亿英镑。
2011年,ARM公司宣布收购了Keil公司。Keil公司是一家业界领先的微控制器(MCU)软件开发工具的独立供应商
展望未来,即使Intel成功地实施了Atom战略,将x86芯片的功耗和价格大大降低,它与ARM竞争也将非常吃力。因为ARM的商业模式是开放的,任何厂商都可以购买授权,所以未来并不是Intel vs. ARM,而是Intel vs. 世界上所有其他半导体公司。那样的话,Intel的胜算能有多少呢?

2、RISC和CISC
RISC:精简指令集处理器,Reduced Instruction Set Computer
RISC结构简单,选取了使用频率高的简单指令,指令长度固定,多为单周期指令
在功耗、体积、价格等方面有很大优势,多用于嵌入式领域
CISC:复杂指令集处理器
侧重于硬件执行指令的功能性,CISC指令及处理器的硬件结构复杂
CISC指令复杂,指令长度与周期不固定,在处理能力上有优势
3、ARM产品线
ARM11以后的产品改用Cortex命名,并分成A、R、M三个分支,旨在为各种不同的市场提供服务
Cortex-A: 面向尖端的基于虚拟内存的操作系统和用户应用
Cortex-R: 实时处理器为要求可靠性、容错功能和实时响应的嵌入式系统提供高性能解决方案
Cortex-M: 针对成本和功耗敏感的MCU和终端应用,一般不跑操作系统

4、ARM架构和ARM内核
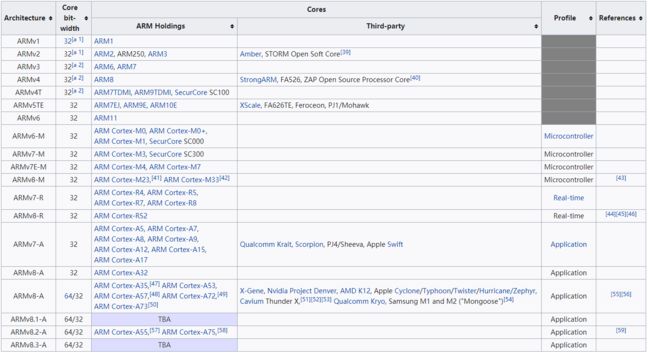
ARM处理器与架构对应表
ARM核对应的时间表
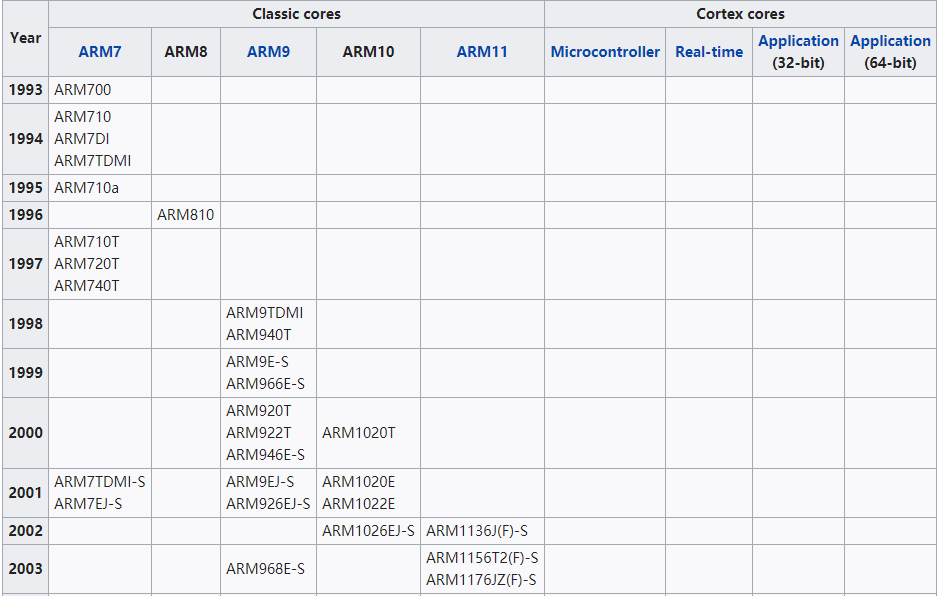
5、ARM的特点
ARM 数据类型约定:
Byte:8bits(1byte)
Halfword:16bits(2byte)
Word:32bits(4byte)
Char:八位(Java中为16位)
指令集:
大部分ARM支持ARM指令集与Thumb指令集
ARM指令集32bit,即每条指令占用32为的存储空间
Thumb指令集16bit
注意:
Thumb指令集不是完整的指令集,它是ARM指令集的子集。但是Thumb指令具有更高的代码密度,即占用存储空间小,仅为ARM代码规格的65%,但其性能却下降的很少。所以,Thumb指令集使ARM处理器能应用到有限的存储带宽,并且,代码密度要求很高的嵌入式系统中去。
运行ARM指令:
所有指令必须word对齐
pc值由其[31:2]决定,[1:0]位未定义,因为指令存储的起始地址必须为4的整数倍
ARM中指令本身是多少位在内存存储时就应该多少位对其
多字节数据的存储:
小端对齐:低地址放低有效位,高地址放高有效位
大端对齐:低地址放高有效位,高地址放低有效位
ARM默认是小端对齐
6、ARM的工作模式
ARM Cortex-A处理器有8个基本工作模式:
User: 非特权模式,一般在执行上层的应用程序时处理器处于该模式
FIQ: 当一个高优先级的中断产生时处理器将自动进入这种模式
IRQ: 当一个低优先级(normal) 中断产生时将会进入这种模式
SVC: 当复位或软中断指令执行时将会进入这种模式
Abort: 当存取异常时将会进入这种模式
Undef: 当执行未定义指令时会进入这种模式
System: 使用和User模式相同寄存器集的特权模式
Cortex-A处理器特有模式:
Monitor:为了安全而扩展出的用于执行安全监控代码的模式
模式的分类:
1)除User模式外其他七种模式都是特权模式 - 权限比较高
2)FIQ、IRQ、SVC、Abort、Undef异常模式 - 产生异常时进入这几种模式
特定的模式下执行特定的代码,完成特定的功能,拥有特定的权限
7、不同版本的ARM的区别
1、架构不同
ARM7:ARMv4架构
ARM9:ARMv5架构,
ARM11:ARMv6架构,
ARM-Cortex 系列:ARMv7架构。
2、具体特点
ARM7:没有MMU(内存管理单元),只能叫做MCU(微控制器),不能运行诸如Linux、WinCE等这些现代的多用户多进程操作系统,因为运行这些系统需要MMU,才能给每个用户进程分配进程自己独立的地址空间。ucOS、ucLinux这些精简实时的RTOS不需要MMU,当然可以在ARM7上运行。
ARM9、ARM11,是嵌入式CPU(处理器),带有MMU,可以运行诸如Linux等多用户多进程的操作系统,应用场合也不同于ARM7。
Cortex来命名,并分成Cortex-A、Cortex-R、Cortex-M三个系列。三大系列分工明确:
“A”系列面向尖端的基于虚拟内存的操作系统和用户应用;
“R”系列针对实时系统;
“M”系列对微控制器。
简单的说Cortex-A系列是用于移动领域的CPU,Cortex-R和Cortex-M系列是用于实时控制领域的MCU。所以看上去ARM7跟Cortex-M很像,因为他们都是MCU,但确是不同代不同架构的MCU(Cortex-M比ARM7高了三代!),所以性能也有很大的差距。此外,Cortex-M系列还细分为M0、M3、M4和超低功耗的M0+,用户依据成本、性能、功耗等因素来选择芯片。
8、ARM的流水线
流水线技术通过多个功能部件并行工作来缩短程序执行时间,提高处理器核的效率和吞吐率,从而成为微处理器设计中最为重要的技术之一。
ARM7处理器核使用了典型三级流水线的冯·诺伊曼结构(指令和数据存储在一起)。
ARM9系列则采用了基于五级流水线的哈佛结构(指令和数据分开存储)。通过增加流水线级数简化了流水线各级的逻辑,进一步提高了处理器的性能。
ARM7的三级流水线在执行单元完成了大量的工作,包括与操作数相关的寄存器和存储器读写操作、ALU操作以及相关器件之间的数据传输。执行单元的工作往往占用多个时钟周期,从而成为系统性能的瓶颈。
ARM9采用了更为高效的五级流水线设计,增加了2个功能部件分别访问存储器并写回结果,且将读寄存器的操作转移到译码部件上,使流水线各部件在功能上更平衡;同时其哈佛架构避免了数据访问和取指的总线冲突。
然而,不论是三级流水线还是五级流水线,当出现多周期指令、跳转分支指令和中断发生的时候,流水线都会发生阻塞,而且相邻指令之间也可能因为寄存器冲突导致流水线阻塞,降低流水线的效率。
8.1、 ARM7流水线技术
ARM7系列处理器中每条指令分取指、译码、执行三个阶段,分别在不同的功能部件上依次独立完成。
取指部件完成从存储器装载一条指令,
通过译码部件产生下一周期数据路径需要的控制信号,完成寄存器的解码,
再送到执行单元完成寄存器的读取、ALU运算及运算结果的写回,需要访问存储器的指令完成存储器的访问。
流水线上虽然一条指令仍需3个时钟周期来完成,但通过多个部件并行,使得处理器的吞吐率约为每个周期一条指令,提高了流式指令的处理速度,从而可达到 0.9 MIPS/MHz的指令执行速度(MIPS(Million Instructions Per Second):单字长定点指令平均执行速度 Million Instructions Per Second的缩写,每秒处理的百万级的机器语言指令数。)
在三级流水线下,通过R15访问PC(程序计数器)时会出现取指位置和执行位置不同的现象。这须结合流水线的执行情况考虑,取指部件根据PC取指,取指完成后PC+4送到PC,并把取到的指令传递给译码部件,然后取指部件根据新的PC取指。因为每条指令4字节,故PC值等于当前程序执行位置+8。
8.2、 ARM9流水线技术
ARM9系列处理器的流水线分为取指、译码、执行、访存、回写。
取指部件完成从指令存储器取指;
译码部件读取寄存器操作数,与三级流水线中不占有数据路径区别很大;
执行部件产生ALU运算结果或产生存储器地址(对于存储器访问指令来讲);
访存部件访问数据存储器;
回写部件完成执行结果写回寄存器。
把三级流水线中的执行单元进一步细化,减少了在每个时钟周期内必须完成的工作量,进而允许使用较高的时钟频率,且具有分开的指令和数据存储器,减少了冲突的发生,每条指令的平均周期数明显减少。
8.3、 三级流水线运行情况分析
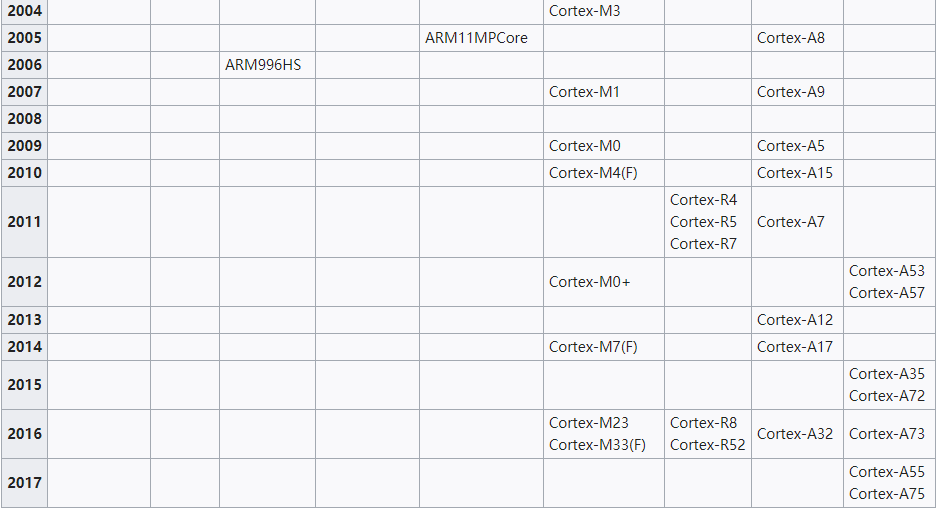
三级流水线在处理简单的寄存器操作指令时,吞吐率为平均每个时钟周期一条指令;但是在存在存储器访问指令、跳转指令的情况下会出现流水线阻断情况,导致流水线的性能下降。图1给出了流水线的最佳运行情况,图中的MOV、ADD、SUB指令为单周期指令。从T1开始,用3个时钟周期执行了3条指令,指令平均周期数(CPI)等于1个时钟周期。
流水线中阻断现象也十分普遍,下面就各种阻断情况下的流水线性能进行详细分析。
1 带有存储器访问指令的流水线
对存储器的访问指令LDR就是非单周期指令,如图2所示。这类指令在执行阶段,首先要进行存储器的地址计算,占用控制信号线,而译码的过程同样需要占用控制信号线,所以下一条指令(第一个SUB)的译码被阻断,并且由于LDR访问存储器和回写寄存器的过程中
需要继续占用执行单元,所以下一条(第一个 SUB)的执行也被阻断。由于采用冯·诺伊曼体系结构,不能够同时访问数据存储器和指令存储器,当LDR处于访存周期的过程中时,MOV指令的取指被阻断。因此处理器用8个时钟周期执行了6条指令,指令平均周期数(CPI)=1.3个时钟周期。
2 带有分支指令的流水线
当指令序列中含有具有分支功能的指令(如BL等)时,流水线也会被阻断,如图3所示。分支指令在执行时,其后第1条指令被译码,其后第2条指令进行取指,但是这两步操作的指令并不被执行。因为分支指令执行完毕后,程序应该转到跳转的目标地址处执行,因此在流水线上需要丢弃这两条指令,同时程序计数器就会转移到新的位置接着进行取指、译码和执行。此外还有一些特殊的转移指令需要在跳转完成的同时进行写链接寄存器、程序计数寄存器,如BL执行过程中包括两个附加操作——写链接寄存器和调整程序指针。这两个操作仍然占用执行单元,这时处于译码和取指的流水线被阻断了。
3 中断流水线
处理器中断的发生具有不确定性,与当前所执行的指令没有任何关系。在中断发时,处理器总是会执行完当前正被执行的指令,然后去响应中断。如图4所示,在 Ox90000处的指令ADD执行期间IRQ中断发生,这时要等待ADD指令执行完毕,IRQ才获得执行单元,处理器开始处理IRQ中断,保存程序返回地址并调整程序指针指向Oxl8内存单元。在Oxl8处有IRO中断向量(也就是跳向IRQ中断服务的指令),接下来执行跳转指令转向中断服务程序,流水线又被阻断,执行0x18处指令的过程同带有分支指令的流水线。
8.4、 五级流水线运行分析
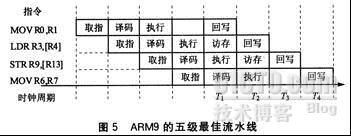
五级流水线技术在多种RISC处理器中被广泛使用,被认为是经典的处理器设计方式。五级流水线中的存储器访问部件(访存)和寄存器回写部件,解决了三级流水线中存储器访问指令在指令执行阶段的延迟问题。图5为五级流水线的运行情况(五级流水线也存在阻断)。
1 五级流水线互锁分析
五级流水线只存在一种互锁,即寄存器冲突。读寄存器是在译码阶段,写寄存器是在回写阶段。如果当前指令(A)的目的操作数寄存器和下一条指令(B)的源操作数寄存器一致,B指令就需要等A回写之后才能译码。这就是五级流水线中的寄存器冲突。如图6所示,LDR指令写R9是在回写阶段,而MOV中需要用到的 R9正是LDR在回写阶段将会重新写入的寄存器值,MOV译码需要等待,直到LDR指令的寄存器回写操作完成。(注:现在处理器设计中,可以通过寄存器旁路技术对流水线进行优化,解决流水线的寄存器冲突问题。)
虽然流水线互锁会增加代码执行时间,但是为初期的设计者提供了巨大的方便,可以不必考虑使用的寄存器会不会造成冲突;而且编译器以及汇编程序员可以通过重新设计代码的顺序或者其他方法来减少互锁的数量。另外分支指令和中断的发生仍然会阻断五级流水线。
2 五级流水线优
采用重新设计代码顺序在很多情况下可以很好地减少流水线的阻塞,使流水线的运行流畅。下面详细分析代码优化对流水线的优化和效率的提高。
考虑到通过减少流水线的冲突可以提高流水线的执行效率,而流水线的冲突主要来自寄存器冲突和分支指令,因此对代码作如下两方面调整
- 将两个循环合并成一个循环能够充分减少循环跳转的次数,减少跳转带来的流水线停滞;
- 调整代码的顺序,将带有与临近指令不相关的寄存器插到带有相关寄存器的指令之间,能够充分地避免寄存器冲突导致的流水线阻塞。
流水线的优化问题主要应从两方面考虑:
①通过合并循环等方式减少分支指令的个数,从而减少流水线的浪费;
②通过交换指令的顺序,避免寄存器冲突造成的流水线停滞。
MIPS体系(龙芯)
1、历史
MIPS是世界上很流行的一种RISC处理器。MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessor without interlocked pipelined stages),其机制是尽量利用软件办法避免流水线中的数据相关问题。它最早是在80年代初期由斯坦福(Stanford)大学Hennessy教授领导的研究小组研制出来的。MIPS公司的R系列就是在此基础上开发的RISC工业产品的微处理器。这些系列产品为很多计算机公司采用构成各种工作站和计算机系统。 MIPS是出现最早的商业RISC架构芯片之一,新的架构集成了所有原来MIPS指令集,并增加了许多更强大的功能。
1999年,MIPS公司发布MIPS32和MIPS64架构标准,为未来MIPS处理器的开发奠定了基础。新的架构集成了所有原来MIPS指令集,并且增加了许多更强大的功能。MIPS公司陆续开发了高性能、低功耗的32位处理器内核(core)MIPS324Kc与高性能64位处理器内核MIPS64 5Kc。2000年,MIPS公司发布了针对MIPS32 4Kc的版本以及64位MIPS 64 20Kc处理器内核。
2、MIPS指令集
所有的指令长度都是32位
指令操作必须适合流水线
所以需要在软件层面尽量避免内部的互锁
https://blog.csdn.net/qq_41191281/article/details/85933985
3、结构
MIPS采用冯诺依曼结构
ARM与MIPS对比
流水线结构
MIPS 是最简单的体系结构之一,所以使大学喜欢选择 MIPS 体系结构来介绍计算体系结构课程。
ARM:barrel shifter
shifter是两面性的,一方面它可以提高数学逻辑运算速度,另一方面它也增加了硬件的复杂性。所以和可以完成同样功能的adder/shift register相比,效率更高,但是也占用更多的芯片面积。
MIPS:"branch delay slot" and "load delay slot"
MIPS使用编译器来解决上面的两个问题。因为MIPS最初的设计思想就是使用简单的RISC硬体,然后靠编译器及其他软体技术,来达成RISC的完整概念。
指令结构
MIPS有32位和64位架构,ARM只有32位架构。ARM11 局部64位
MIPS是开放式的架构, 用户可以在开发的内核中加入自己的指令,
ARM has 4-bit condition code in every instruction
ARM 在这一点很像x86。MIPS在MIPS IV也加入"conditional move"指令,来提高pipeline的效率。
在节省代码空间方面,MIPS16 很类似ARM Thumb
寄存器
由于MIPS内核中有32个寄存器(Register),而ARM只有16个,这种结构设计上的先天优势,决定了在同等性能表现下,MIPS的芯片面积和功耗会更小。
ARM 有一组特殊用途寄存器cp0-cp15,可以使用MCR,MRC等指令控制
MIPS也有cp0 0-30,使用mfc0, mtc0 指令控制。
地址空间
MIPS 起始地址是0xbfc00000, 会有4Mbyte的大小限制,但一般MIPS芯片都会采取一些方法解决这个问题。
ARM没有这种问题。
MIPS24K 起始地址改到了0xbf000000,现在有16Mbyte的空间了。
应用
ARM 由于功耗小,普遍用在在手机/PDA等便携式消费电子领域;
MIPS 在住宅网关、线缆调制解调器、线缆机顶盒等,由于MIPS 多核的发展,现在大型网关设备也多用它。
ARM 采用硬核授权;MIPS 采用软核授权,用户可以自己配置,做自己的产品。
未来发展
ARM的下一代走向多内核结构,而MIPS公司的下一代核心则转向硬件多线程功能(multithreading)