在多元回归分析中已经介绍过,当自变量之间具有显著的相关关系时,可能会存在多重共线性。严重的多重共线性会大大影响模型的预测结果。除了可以用容忍度与方差扩大因子来度量模型的多重共线性以外,还可以用条件数来度量,常用κ表示,条件数可以定义为:
![]() ,
,
其中,λ为![]() 的特征值(X代表自变量矩阵)。一般认为,当κ>15时,有共线性问题,当κ>30时,说明有严重的共线性问题。
的特征值(X代表自变量矩阵)。一般认为,当κ>15时,有共线性问题,当κ>30时,说明有严重的共线性问题。
本文拟采用R中lars包自带的diabetes数据集,该数据描述了一些关于糖尿病的血液等化验指标。通过str()函数先看一下该数据的结构。
> str(diabetes) 'data.frame': 442 obs. of 3 variables: $ x : AsIs [1:442, 1:10] 0.03808 -0.00188 0.0853 -0.08906 0.00538 ... ..- attr(*, "dimnames")=List of 2 .. ..$ : NULL .. ..$ : chr "age" "sex" "bmi" "map" ... $ y : num 151 75 141 206 135 97 138 63 110 310 ... $ x2: AsIs [1:442, 1:64] 0.03808 -0.00188 0.0853 -0.08906 0.00538 ... ..- attr(*, ".Names")= chr "age" "age" "age" "age" ... ..- attr(*, "dimnames")=List of 2 .. ..$ : chr "1" "2" "3" "4" ... .. ..$ : chr "age" "sex" "bmi" "map" ...
上说结果说明,diabetes数据为一个数据框,共有3列,442行。第一列是一个442X10数据框,是标准化后的自变量,第二列是因变量,第三列是442X64数据框,包括前者及一些交互作用。
VIF的值可以用软件包car中的vif()函数计算,条件数κ可以用R内置函数kappa()计算。
> write.csv(diabetes,"diabetes.csv",row.names = FALSE)
> diabetes.test<-read.csv("diabetes.csv")
> kappa(diabetes.test[,12:75])
[1] 11427.09
> vif.dia<-vif(lm(y~.,data = diabetes.test[,11:75]))
> sort(vif.dia,decreasing = TRUE)[1:5]
x2.tc x2.ldl x2.hdl x2.ltg x2.tc.ltg
1295001.21 1000312.11 180836.83 139965.06 61177.87
不管是从κ的值还是从VIF的值来看,该模型都存在严重的多重共线性。
1 岭回归
假定自变量数据矩阵![]() 为nxp矩阵,通常最小二乘法(ordinary least squares,或ols)通过使残差平方和达到最小以求得相应的β,即
为nxp矩阵,通常最小二乘法(ordinary least squares,或ols)通过使残差平方和达到最小以求得相应的β,即
![]() .
.
岭回归则需要一个惩罚项来约束系数的大小,即在上面的公式中增加![]() ,既要使得残差平方和小,又要避免系数过大。
,既要使得残差平方和小,又要避免系数过大。
![]()
说白了,岭回归就是通过牺牲最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数,对于病态数据以及共线性强的数据具有良好效果。也就是说,在约束条件
![]()
下,满足
![]() .
.
显然这里需要确定λ和s的值,一般用交叉验证或者MallowsCp等准则通过计算来确定。
R中的MASS包提供了lm.ridge()函数用于实现岭回归。
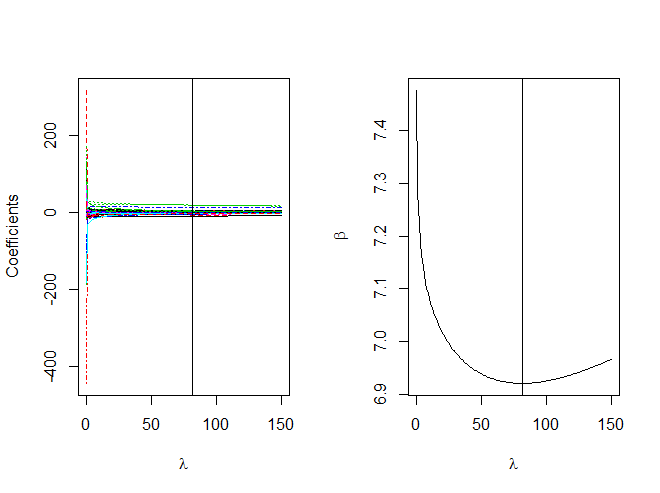
> library(MASS) > ridge.dia<-lm.ridge(y~.,lambda = seq(0,150,length.out = 151),data = diabetes.test[,11:75],model = TRUE) #拟合回归模型 > names(ridge.dia) #查看回归模型的详细内容 >[1] "coef" "scales" "Inter" "lambda" "ym" "xm" "GCV" "kHKB" "kLW" >#coef:回归系数矩阵,每一行对应一个λ。 >#scales:自变量矩阵的标度。 >#Inter:是否包括截距? >#lambda:λ向量。 >#ym:因变量的均值。 >#xm:自变量矩阵按列计算的均值。 >#GCV:广义交叉验证GVC向量。 >#kHKB:岭常量的kHKB估计。 >#kLW:岭常量的L-W估计。 > ridge.dia$lambda[which.min(ridge.dia$GCV)] #输出使GCV最小时的λ值 [1] 81 > ridge.dia$coef[,which.min(ridge.dia$GCV)] #找到GCV最小时对应的系数,该结果是一个向量,长度为自变量的个数 > par(mfrow=c(1,2)) >#绘制回归系数关于λ的图形,并作出GCV取取最小值的那条竖线。 > matplot(ridge.dia$lambda,t(ridge.dia$coef),xlab = expression(lambda),ylab = "Coefficients",type = "l",lty = 1:20) > abline(v=ridge.dia$lambda[which.min(ridge.dia$GCV)]) >#绘制GCV关于λ的图形,并作出GCV取取最小值的那条竖线。 > plot(ridge.dia$lambda,ridge.dia$GCV,type = "l",xlab = expression(lambda),ylab = expression(beta)) > abline(v=ridge.dia$lambda[which.min(ridge.dia$GCV)])
2 lasso回归
与岭回归类似,但是其惩罚项却不是系数的平方和,而是系数绝对值之和。即在约束条件![]() 下,系数仍然需要满足最小二乘法的约束条件。
下,系数仍然需要满足最小二乘法的约束条件。
R中的lars包可以用于计算lasso回归,计算过程如下。
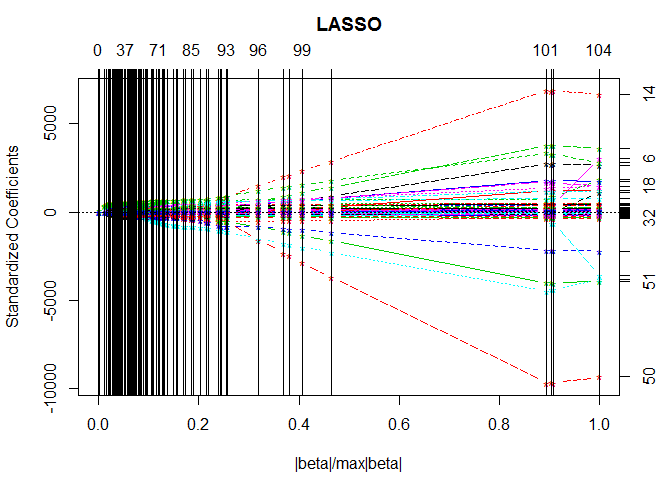
> library(lars) > x=as.matrix(diabetes.test[,1:10]) > y=as.matrix(diabetes.test[,11]) > x2=as.matrix(diabetes.test[,12:75]) > lasso.dia<-lars(x2,y) #lars函数只接受矩阵,所以要把上述的数据框转化为矩阵 > plot(lasso.dia) #绘制回归结果,该图最左边是只包含截距一种成分,最右边是包含所有的变量,在不同的步数下,系数变化比较直观。 > summary(lasso.dia) #输出lasso对象的细节,包括Df、RSS和Cp值。(Cp是MallowsCp统计量,通常选取Cp最小的那个模型)。
如果从k个自变量中选取p个参与回归,那么Cp统计量定义为:
![]()
其中:
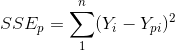 ,表示p个自变量参与回归的误差平方和。
,表示p个自变量参与回归的误差平方和。
Ypi:该模型的第i个预测值。
S2:均方残差,可用样本的MSE估计。
N:样本容量。
详细信息参见:https://en.wikipedia.org/wiki/Mallows%27s_Cp
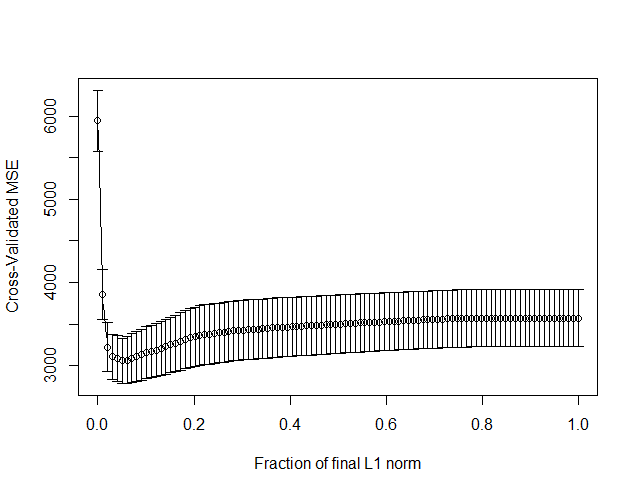
> cvdia<-cv.lars(x2,y,K = 10) #进行10折交叉验证
> best<-cvdia$index[which.min(cvdia$cv)] #选择适合的值(随机性使得结果不同)
> coef<-coef.lars(lasso.dia,mode="fraction",s=best) #使得CV最小步时的系数。
>该函数同时会绘制CV的变化图,可以看出在什么时候CV达到极小值。由于在做k折交叉验证的时候,样本的分组是随机地,因此用CV和Cp
>选择的结果可能会不同
> min(lasso.dia$Cp) #输出最小的Cp值,结果是第15个
[1] 18.19822
> coef1=coef.lars(lasso.dia,mode="step",s=15) #使lasso.dia最小步时的系数
> CpStep<-data.frame(step=0:104,Df=lasso.dia$df,RSS=lasso.dia$RSS,Cp=lasso.dia$Cp)
> CpStep[9:20,] #可以看出,在第15步时,Cp达到最小值18.2。
step Df RSS Cp
8 8 9 1344199 50.39965
9 9 10 1334100 48.83518
10 10 11 1322126 46.60943
11 11 12 1260433 26.83646
12 12 13 1249726 25.05780
13 13 14 1234993 21.85823
14 14 15 1225552 20.52619
15 15 16 1213289 18.19822
16 16 17 1212253 19.83278
17 17 18 1210149 21.08995
18 18 19 1206003 21.62691
19 19 20 1204605 23.13358
> coef[coef!=0] #ceof!=0,表示变量被选择,这里根据CV的值选择了32个变量。
x2.age x2.sex x2.bmi x2.map x2.tc x2.hdl
5.486124 -191.689017 494.870609 301.605908 -47.000781 -248.744630
x2.ltg x2.glu x2.age.2 x2.bmi.2 x2.ltg.2 x2.glu.2
510.705978 50.731562 50.410322 40.870850 -5.528215 93.918944
x2.age.sex x2.age.map x2.age.ldl x2.age.hdl x2.age.ltg x2.age.glu
146.377002 25.700401 -48.088912 26.623122 53.103657 20.494559
x2.sex.bmi x2.sex.map x2.sex.ldl x2.sex.hdl x2.bmi.map x2.map.hdl
31.092360 51.752425 -19.335826 51.477231 124.491470 36.622384
x2.map.glu x2.tc.hdl x2.tc.tch x2.ldl.ltg x2.ldl.glu x2.hdl.tch
-29.354628 8.037888 -60.747576 79.299479 8.188651 -59.171992
x2.tch.ltg x2.tch.glu
-67.607937 24.396984
> coef[coef1!=0] #根据Cp选择了14个变量
x2.sex x2.bmi x2.map x2.hdl x2.ltg x2.glu x2.age.2
-191.68902 494.87061 301.60591 -248.74463 510.70598 50.73156 50.41032
x2.bmi.2 x2.glu.2 x2.age.sex x2.age.map x2.age.ltg x2.age.glu x2.bmi.map
40.87085 93.91894 146.37700 25.70040 53.10366 20.49456 124.49147
3 适应性lasso回归
适应性lasso回归的系数β也要满足最小二乘公式的条件,但是,其惩罚项为系数绝对值的加权平均值。即约束条件变为:
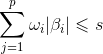 ,
,
式中,![]() ,而γ是一个调整参数。上面介绍的岭回归和lasso回归是其方法的特例。
,而γ是一个调整参数。上面介绍的岭回归和lasso回归是其方法的特例。
R中的msgps包不仅提供了计算适应性lasso(alasso)回归的方法,还提供了弹性网络及广义弹性网络等方法。其最优策略包括Cp统计量、AIC信息准则、GCV准则以及BIC信息准则。
实现适应性lasso回归的过程如下。
> #adaptive lasso
> y=diabetes.test[,11]
> al=msgps(x2,y,penalty = "alasso",gamma = 1,lambda = 0)
> summary(al) #
Call: msgps(X = x2, y = y, penalty = "alasso", gamma = 1, lambda = 0)
Penalty: "alasso"
gamma: 1
lambda: 0
df:
tuning df
[1,] 0.000 0.000
[2,] 0.449 1.037
[3,] 1.698 4.412
[4,] 2.957 9.147
[5,] 4.400 12.255
[6,] 5.469 13.958
[7,] 6.677 16.225
[8,] 8.009 18.733
[9,] 9.767 22.160
[10,] 12.113 26.121
[11,] 14.386 28.954
[12,] 16.463 31.118
[13,] 18.832 33.066
[14,] 21.622 36.323
[15,] 24.583 40.062
[16,] 27.704 43.350
[17,] 30.924 45.307
[18,] 34.629 47.100
[19,] 38.619 49.103
[20,] 45.410 54.288
tuning.max: 45.41
ms.coef:
Cp AICC GCV BIC
(Intercept) 1.521e+02 1.521e+02 1.521e+02 152.13
x2.age 0.000e+00 0.000e+00 0.000e+00 0.00
x2.sex -2.138e+02 -2.138e+02 -2.169e+02 -163.49
x2.bmi 5.054e+02 5.054e+02 5.054e+02 505.39
x2.map 3.108e+02 3.108e+02 3.139e+02 275.38
x2.tc -1.486e+02 -1.486e+02 -1.486e+02 -148.57
x2.ldl 1.678e+01 1.678e+01 1.803e+01 10.57
x2.hdl -2.294e+02 -2.294e+02 -2.300e+02 -219.44
x2.tch 0.000e+00 0.000e+00 0.000e+00 0.00
x2.ltg 7.031e+02 7.031e+02 7.031e+02 672.61
x2.glu 0.000e+00 0.000e+00 0.000e+00 0.00
x2.age.2 0.000e+00 0.000e+00 0.000e+00 0.00
x2.bmi.2 0.000e+00 0.000e+00 0.000e+00 0.00
x2.map.2 0.000e+00 0.000e+00 0.000e+00 0.00
x2.tc.2 9.573e+01 9.573e+01 1.392e+02 -36.68
x2.ldl.2 -7.149e+01 -7.149e+01 -1.001e+02 0.00
x2.hdl.2 -2.487e+01 -2.487e+01 -3.170e+01 0.00
x2.tch.2 8.579e+01 8.579e+01 9.387e+01 13.68
x2.ltg.2 3.506e+02 3.506e+02 3.655e+02 159.76
x2.glu.2 3.605e+01 3.605e+01 4.103e+01 0.00
x2.age.sex 1.616e+02 1.616e+02 1.635e+02 99.46
x2.age.bmi 0.000e+00 0.000e+00 0.000e+00 0.00
x2.age.map 0.000e+00 0.000e+00 0.000e+00 0.00
x2.age.tc 0.000e+00 0.000e+00 0.000e+00 0.00
x2.age.ldl 0.000e+00 0.000e+00 0.000e+00 0.00
x2.age.hdl 0.000e+00 0.000e+00 0.000e+00 0.00
x2.age.tch 0.000e+00 0.000e+00 0.000e+00 0.00
x2.age.ltg 3.170e+01 3.170e+01 3.730e+01 0.00
x2.age.glu 0.000e+00 0.000e+00 0.000e+00 0.00
x2.sex.bmi 0.000e+00 0.000e+00 0.000e+00 0.00
x2.sex.map 1.616e+01 1.616e+01 2.487e+01 0.00
x2.sex.tc 2.860e+01 2.860e+01 3.605e+01 0.00
x2.sex.ldl -5.408e+01 -5.408e+01 -6.341e+01 0.00
x2.sex.hdl 2.424e+01 2.424e+01 2.922e+01 0.00
x2.sex.tch 0.000e+00 0.000e+00 0.000e+00 0.00
x2.sex.ltg 0.000e+00 0.000e+00 0.000e+00 0.00
x2.sex.glu 0.000e+00 0.000e+00 0.000e+00 0.00
x2.bmi.map 1.138e+02 1.138e+02 1.181e+02 68.38
x2.bmi.tc 0.000e+00 0.000e+00 0.000e+00 0.00
x2.bmi.ldl 0.000e+00 0.000e+00 0.000e+00 0.00
x2.bmi.hdl 0.000e+00 0.000e+00 0.000e+00 0.00
x2.bmi.tch 0.000e+00 0.000e+00 0.000e+00 0.00
x2.bmi.ltg 0.000e+00 0.000e+00 0.000e+00 0.00
x2.bmi.glu 0.000e+00 0.000e+00 0.000e+00 0.00
x2.map.tc 1.927e+01 1.927e+01 1.927e+01 11.19
x2.map.ldl 0.000e+00 0.000e+00 0.000e+00 0.00
x2.map.hdl 0.000e+00 0.000e+00 7.460e+00 0.00
x2.map.tch 0.000e+00 0.000e+00 0.000e+00 0.00
x2.map.ltg 0.000e+00 0.000e+00 0.000e+00 0.00
x2.map.glu 0.000e+00 0.000e+00 0.000e+00 0.00
x2.tc.ldl 8.889e+01 8.889e+01 8.889e+01 60.92
x2.tc.hdl -3.331e-15 -3.331e-15 -3.331e-15 19.89
x2.tc.tch -2.611e+02 -2.611e+02 -2.741e+02 -135.52
x2.tc.ltg -6.278e+02 -6.278e+02 -6.614e+02 -299.63
x2.tc.glu 0.000e+00 0.000e+00 0.000e+00 0.00
x2.ldl.hdl -9.076e+01 -9.076e+01 -1.113e+02 -23.00
x2.ldl.tch 0.000e+00 0.000e+00 0.000e+00 0.00
x2.ldl.ltg 5.358e+02 5.358e+02 5.446e+02 333.20
x2.ldl.glu 0.000e+00 0.000e+00 0.000e+00 0.00
x2.hdl.tch -2.362e+01 -2.362e+01 -2.362e+01 -23.62
x2.hdl.ltg 2.455e+02 2.455e+02 2.499e+02 128.06
x2.hdl.glu 0.000e+00 0.000e+00 1.243e+00 0.00
x2.tch.ltg 0.000e+00 0.000e+00 0.000e+00 0.00
x2.tch.glu 9.573e+01 9.573e+01 9.573e+01 78.33
x2.ltg.glu 0.000e+00 0.000e+00 0.000e+00 0.00
ms.tuning:
Cp AICC GCV BIC
[1,] 7.987 7.987 8.433 5.111
ms.df:
Cp AICC GCV BIC
[1,] 18.68 18.68 19.47 13.27
>plot(al)
调整参数选的是γ=45.21,为最大值,这时的各个准则及自由度如上所示。
4 偏最小二乘回归
相关细节可参见:https://en.wikipedia.org/wiki/Partial_least_squares_regression
偏最小二乘回归有点类似于主成分回归。偏最小二乘回归是在因变量和自变量中先各自寻找一个因子,条件是这两个因子在其他可能的成分中最相关,然后在这选中的一对因子的正交空间中再选一对最相关的因子。如此下去,直到这些对因子有充分代表性为止。R中的pls包可以用来计算偏最小二乘回归,其计算过程如下。
> ap=plsr(y~x2,64,validation="CV") #求出所以可能的64个因子
> ap$loadings #看代表性,选取一部分因子,部分结果如下图所示,可以看出,前29个因子的累计方差已经可以解释总方差的80%以上。
Comp 1 Comp 2 Comp 3 Comp 4 Comp 5 Comp 6 Comp 7 Comp 8 Comp 9
SS loadings 1.142 1.612 1.371 1.378 1.516 1.494 1.476 1.494 1.938
Proportion Var 0.018 0.025 0.021 0.022 0.024 0.023 0.023 0.023 0.030
Cumulative Var 0.018 0.043 0.064 0.086 0.110 0.133 0.156 0.179 0.210
Comp 10 Comp 11 Comp 12 Comp 13 Comp 14 Comp 15 Comp 16 Comp 17
SS loadings 1.890 2.152 1.847 1.693 1.667 1.487 2.532 2.056
Proportion Var 0.030 0.034 0.029 0.026 0.026 0.023 0.040 0.032
Cumulative Var 0.239 0.273 0.302 0.328 0.354 0.377 0.417 0.449
Comp 18 Comp 19 Comp 20 Comp 21 Comp 22 Comp 23 Comp 24 Comp 25
SS loadings 1.854 1.690 1.633 1.785 1.905 2.101 1.579 1.442
Proportion Var 0.029 0.026 0.026 0.028 0.030 0.033 0.025 0.023
Cumulative Var 0.478 0.504 0.530 0.558 0.588 0.620 0.645 0.668
Comp 26 Comp 27 Comp 28 Comp 29 Comp 30 Comp 31 Comp 32 Comp 33
SS loadings 2.058 2.157 1.936 2.010 1.730 1.614 1.865 2.170
Proportion Var 0.032 0.034 0.030 0.031 0.027 0.025 0.029 0.034
Cumulative Var 0.700 0.734 0.764 0.795 0.822 0.847 0.877 0.911
Comp 34 Comp 35 Comp 36 Comp 37 Comp 38 Comp 39 Comp 40 Comp 41
SS loadings 2.286 1.477 1.672 2.145 1.823 1.736 2.173 1.608
Proportion Var 0.036 0.023 0.026 0.034 0.028 0.027 0.034 0.025
Cumulative Var 0.946 0.969 0.995 1.029 1.057 1.085 1.119 1.144
Comp 42 Comp 43 Comp 44 Comp 45 Comp 46 Comp 47 Comp 48 Comp 49
SS loadings 1.664 4.401 1.450 1.796 1.907 2.436 1.267 2.017
Proportion Var 0.026 0.069 0.023 0.028 0.030 0.038 0.020 0.032
Cumulative Var 1.170 1.238 1.261 1.289 1.319 1.357 1.377 1.408
Comp 50 Comp 51 Comp 52 Comp 53 Comp 54 Comp 55 Comp 56 Comp 57
SS loadings 4.171 1.805 1.278 5.221 1.332 10.436 1.160 1.863
Proportion Var 0.065 0.028 0.020 0.082 0.021 0.163 0.018 0.029
Cumulative Var 1.473 1.502 1.522 1.603 1.624 1.787 1.805 1.834
Comp 58 Comp 59 Comp 60 Comp 61 Comp 62 Comp 63 Comp 64
SS loadings 1.302 1.919 4.460 1.134 1.033 1.000 1.000
Proportion Var 0.020 0.030 0.070 0.018 0.016 0.016 0.016
Cumulative Var 1.855 1.885 1.954 1.972 1.988 2.004 2.019
>ap$coefficients #查看各个因子作为原变量的线性组合时的系数,该结果是一个多维数组。
> dim(ap$coefficients)
[1] 64 1 64
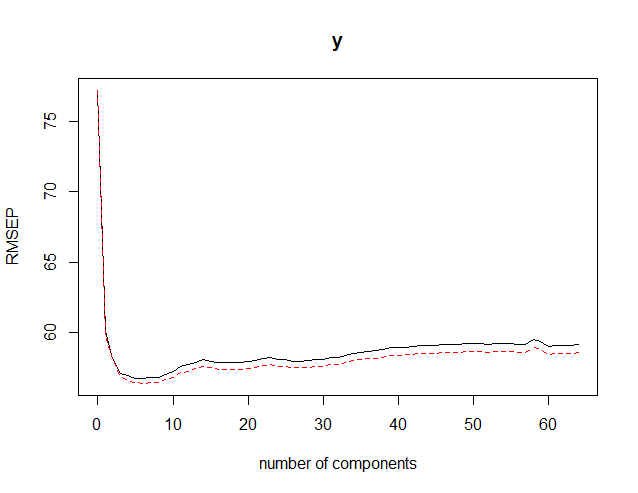
> validationplot(ap) #该图可用来根据CV准则挑选因子数量。可以从图中看出,5个因子时RMSEP值最小。
致谢:部分内容来自于吴喜之《复杂数据分析——基于R的应用》,数据为R中lars包自带数据集diabetes。