gru
gru
在 GRU 中,如下图所示,只有两个门:重置门(reset gate)和更新门(update gate)
RNN的一个特点是所有的隐层共享参数(U,V,W),整个网络只用这一套参数。gru也是如此
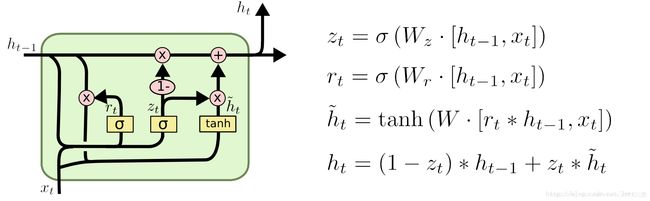
“ * ”代表点乘
其中, rt表示重置门,zt表示更新门。
1重置门rt决定是否将之前的状态忘记。(作用相当于合并了 LSTM 中的遗忘门和传入门)
2将先前隐藏状态ht-1和遗忘门输出的向量进行点乘。当rt趋于0的时候,前一个时刻的状态信息ht−1会被忘掉,隐藏状态会被重置为当前输入的信息。
3得到了新的隐藏状态ĥ , 但是还不能直接输出,而是通过更新门来控制最后的输出:ht=(1−zt)∗ht−1+zt∗ĥ t
和 LSTM 比较一下:
- GRU 少一个门,同时少了细胞状态Ct。
- 在 LSTM 中,通过遗忘门和传入门控制信息的保留和传入;GRU 则通过重置门来控制是否要保留原来隐藏状态的信息,但是不再限制当前信息的传入。
- 在 LSTM 中,虽然得到了新的细胞状态 Ct,但是还不能直接输出,而是需要经过一个过滤的处理:ht=ot∗tanh(Ct);同样,在 GRU 中, 虽然我们也得到了新的隐藏状态ĥ , 但是还不能直接输出,而是通过更新门来控制最后的输出:ht=(1−zt)∗ht−1+zt∗ĥ t
作者:gzj_1101
来源:CSDN
原文:https://blog.csdn.net/gzj_1101/article/details/79376798
版权声明:本文为博主原创文章,转载请附上博文链接!
计算
https://www.cnblogs.com/wushaogui/p/9176617.html
假设现有
一个样本,Shape=(13,5),时间步是13,每个时间步的特征长度是5.形象点,我把一个样本画了出来:

使用Keras框架添加LSTM层时,我的设置是这样的keras.layers.LSTM(10),也就是我现在设定,每个时间步经过LSTM后,得到的中间隐向量是10维(意思是5->10维),13个时间步的数据若把每部的结果输出得到的是(13,10)的数据.若只输出最后的结果就是(1,10)的数据
每个时间步对应神经元(参数)一样.计算参数时算一个时间步中参与的神经元个数即可.
先看基础 RNN 的计算公式:
h(t)=f(W[x(t),h(t−1)]+b)
Xt是新的输入,Ht-1是上一层的隐藏状态
x: `[n_features, 1]`([input_dimension,1])
h: `[n_units, 1]`([output_dimension,1])
[Xt,Ht-1]:`[n_units+n_features, 1]`
W: `[n_units, n_units+n_features]`
b: `[n_units, 1]`
rnn参数数量 = (n_features + n_units) * n_units + n_units
gru参数数量 = (n_features + n_units) * (n_units * 3) + (n_units * 3)
keras API
keras.layers.GRU(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, implementation=1, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False, reset_after=False)
输入尺寸
3D 张量,尺寸为 (batch_size, timesteps, input_dim) 对横向的文本,timestep就是宽。
units: 正整数,输出空间的维度。
return_sequences: 布尔值。false是返回输出序列中的最后一个输出
true是全部序列,也就是全部状态。即(batchsize,time_steps,units)o_backwards: 布尔值 (默认 False)。 如果为 True,则向后处理输入序列并返回相反的序列。(batch_size,units)