Python利用scrapy框架抓取链家楼盘信息的简单案例以及利用布隆过滤器对URL的去重
spiderMiddleware 爬虫中间件,起到对spider进行各项扩展的功能
在middlewares.py中增加以下部分,注意还需要在settings中设置以是生效
1.设置随机User-Agent
2.设置随机访问时间间隔
from fake_useragent import UserAgent
#设置随机User-Aagent
class RandomUserAgent(object):
def process_request(self, request, spider):
ua = UserAgent()
request.headers['User-Agent'] = ua.random
#设置爬虫访问频率,访问频率控制在2s~3s范围内
class RandomDelayMiddleware(object):
def __init__(self, delay_min,delay_max):
self.delay_min = delay_min
self.delay_max = delay_max
@classmethod
def from_crawler(cls, crawler):
delay_min = crawler.spider.settings.get("RANDOM_DELAY_MIN", 2)
delay_max = crawler.spider.settings.get("RANDOM_DELAY_MAX", 3)
if not isinstance(delay_min, int):
raise ValueError("RANDOM_DELAY_MIN need a int")
if not isinstance(delay_max, int):
raise ValueError("RANDOM_DELAY_MAX need a int")
return cls(delay_min,delay_max)
def process_request(self, request, spider):
delay = random.randint(self.delay_min, self.delay_max)
logging.info(">>> request.url is {0},random delay: {1} s <<<".format(request.url,delay))
time.sleep(delay)
settings.py
1.在settings.py里进行随机User-Agent的配置,键值对中的键不能随意修改,要根据项目文件的对应路径,并且将系统默认的随机请求头给禁掉,再添加我们自己定义的随机User-Agent
DOWNLOADER_MIDDLEWARES = {
'spider_project.middlewares.RandomUserAgent': 300,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None
}2.在settings.py中设置设置随机访问时间间隔
1)DOWNLOAD_DELAY 下载随机延时范围,比如上面设置了3秒,那么随机延时范围将是[0, 3]
2)设置访问时间间隔,注意总的延时范围应该是两者之和,即:
DOWNLOAD_DELAY_MIN + 0 < total_delay < DOWNLOAD_DELAY_MAX + RANDOM_DELAYDOWNLOAD_DELAY = 3
DOWNLOADER_MIDDLEWARES = {
'spider_project.middlewares.RandomUserAgent': 300,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'spider_project.middlewares.RandomDelayMiddleware': 999
}
3.settings.py 中配置代理IP
使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网站封了IP,但是使用代理IP就不怕它封了我们的IP
获取代理IP的网站:www.goubanjia.com,www.xicidaili.com
使用代理来隐藏真实访问中,代理也不允许频繁访问某一个固定网站,所以代理最好配置多个
PROXIES = [
{'ip_port': '223.199.26.27:8746', 'user_passwd': 'user1:pass1'},
{'ip_port': '183.166.21.218:9999', 'user_passwd': 'user2:pass2'},
{'ip_port': '223.199.18.87:9999', 'user_passwd': 'user3:pass3'},
{'ip_port': '114.99.13.4:9999', 'user_passwd': 'user4:pass4'},
{'ip_port': '47.112.214.45:8000', 'user_passwd': 'user5:pass5'},
]item.py
明确需要爬取的目标/产品,爬虫提取出的数据将存入item
# -*- coding: utf-8 -*-
import scrapy
class SpiderProjectItem(scrapy.Item):
# define the fields for your item here like:
#楼盘名称
name = scrapy.Field()
#连接
# herf = scrapy.Field()
#参考图片
# img = scrapy.Field()
#位置
location = scrapy.Field()
#单价
danjia = scrapy.Field()
#建筑面积
area = scrapy.Field()
#在售房型
type = scrapy.Field()
#地区
region = scrapy.Field()spidertest.py
编写一个爬虫文件
这里对所爬取的页面xml文件进行截取相应字段用到的是BeautifulSoup模块
BeautifulSoup和lxml的原理不一样,BeautifulSoup是基于DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多。而lxml只会局部遍历,另外lxml是用c写的,而BeautifulSoup是用python写的,因此性能方面自然会差很多。
#这是自定义的需要保存的字段,导入spider_project项目中,items文件中的 SpiderProjectItem类)
from spider_project.items import SpiderProjectItem
from bs4 import BeautifulSoup
#导入request模块,需要跟进URL的时候,需要用它
from scrapy.http import Request
import scrapy
import math
import lxml
class Pro_spider(scrapy.Spider):
#定义爬虫名,唯一,在爬虫项目entrypoint入口execute方法需用到
name = 'test'
#spider 允许爬取的域名列表
allow_domains = ['lianjia.com']
#设置开始第一批爬取的url
base_url = 'https://hz.fang.lianjia.com/loupan/'
regions = {
'xihu':'西湖',
'xiacheng':'下城',
'jianggan':'江干',
'gongshu':'拱墅',
'shangcheng':'上城',
'binjiang':'滨江',
'yuhang':'余杭',
'xiaoshan':'萧山'
}
def start_requests(self): #生成Requests对象交给Scrapy下载并返回response,此方法仅能被调用一次
index = 1
for region in list(self.regions.keys()):
url = self.base_url + region + "/" +'pg{0}'.format(index)
#参数dont_filter=True确保request不被过滤
#yield Request 请求新的url,后面跟的是回调函数,你需要哪一个函数来处理这个返回值,就调用哪一个函数,函数返回值会以参数形式传递给所调用的函数
yield Request(url,callback=self.parse_page,dont_filter=True,meta={'region':region,'index':index})
def parse_page(self,response): #获取每一个region下房产信息的页数
soup = BeautifulSoup(response.text,'lxml') #创建 beautifulsoup 对象
totalpage = math.floor(int(soup.find(attrs={'data-current': 1})['data-total-count']) / 10 + 1) # 向下取整
# print(totalpage)
for index in range(1,totalpage+1):
url = self.base_url + response.meta['region'] + "/" + 'pg{0}'.format(index)
yield Request(url,callback=self.parse, dont_filter=True,meta={'region': response.meta['region'],'index': index})
def parse(self,response):
Item = SpiderProjectItem()
soup = BeautifulSoup(response.text,'lxml')
loupans = soup.find_all('div',class_='resblock-desc-wrapper')
# print(len(loupans))
for loupan in loupans:
#获取楼盘名称
Item['name'] = loupan.find_all('a',class_='name')[-1].get_text()
#获取楼盘详细位置,列表形式,"滨江,长河,闻涛路绿城九龙仓柳岸晓风"
location_info =loupan.find('div',class_='resblock-location').find_all(['span', 'a'])
location = ''
for item in location_info:
location += item.string
# print(location)
Item['location'] = location
#获取每平方单价
Item['danjia'] = loupan.find('span',class_='number').string
#获取建筑面积
try:
Item['area'] = str(loupan.find('div',class_='resblock-area').get_text()).split()[-1]
except Exception as error:
Item['area'] = None
#获取房型
nums = len(loupan.find('a',class_='resblock-room').find_all('span'))
# try:
type = ''
for num in range(0,nums):
type += str(loupan.find('a',class_='resblock-room').find_all('span')[num].get_text()) + '/'
# Item['type'] = type
if len(type):
Item['type'] = type
else:
Item['type'] = None
#获取地区
Item['region'] = response.meta['region']
yield Itempipelines.py
item中保存的数据需要进一步处理,比如清洗,去虫,存储等,这里我们将item中的数据存入mysql
# -*- coding: utf-8 -*-
import pymysql
class SpiderProjectPipeline(object):
def open_spider(self,spider):
self.connect = pymysql.connect(
host = '127.0.0.1',
user = 'root',
passwd = '********',
database = 'spider_test',
port = 8635,
charset = 'utf8',
use_unicode = False
)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
insert_sql = "INSERT INTO item_info(name,region," \
"location,area,danjia,type)" \
"VALUES (" \
" %s, %s, %s, " \
" %s," \
" %s, %s)"
params = (
item['name'],item['region'],item['location'],
item['area'],item['danjia'],item['type']
)
self.cursor.execute(insert_sql,params)
self.connect.commit()
def spider_close(self,spider):
self.cursor.close()
self.connect.close()
scrapy默认是不能在IDE中调试的,我们在根目录中新建一个entrypoint.py,作为调试的入口
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'test']) #test为先前定义的spider名字查询抓取结果

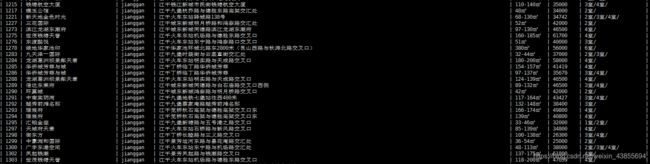
URL的去重
关于布隆过滤器原理 文档地址:https://www.cnblogs.com/yscl/p/12003359.html
安装崔神发布的scrapy-redis-bloomfilter 文档地址: https://cloud.tencent.com/developer/article/1084962
pip3 install scrapy-redis-bloomfiltersettings.py中的配置
BLOOMFILTER_HASH_NUMBER = 6 #定义散列函数个数
BLOOMFILTER_BIT = 30 #申明位数组的长度爬虫文件改进部分
from spider_project.items import SpiderProjectItem
from bs4 import BeautifulSoup
from scrapy.http import Request
import scrapy
import math
from scrapy_redis_bloomfilter.bloomfilter import BloomFilter
import redis
import lxml
import logging
class Pro_spider(scrapy.Spider):
......
#以连接池方式连接redis
pool = redis.ConnectionPool(host='10.10.0.244', port=6379, db=0)
redis_conn = redis.Redis(connection_pool=pool)
def parse_page(self,response):
soup = BeautifulSoup(response.text,'lxml')
totalpage = math.floor(int(soup.find(attrs={'data-current': 1})['data-total-count']) / 10 + 1)
for index in range(1,totalpage+1):
url = self.base_url + response.meta['region'] + "/" + 'pg{0}'.format(index)
# 使用布隆过滤器进行去重
if not self.url_filter(url, 'url_finger'):
yield Request(url,callback=self.parse, dont_filter=True,meta={'region': response.meta['region'],'index': index})
def url_filter(self,url,key):
bf = BloomFilter(server=self.redis_conn, key=key,
hash_number=self.settings.get("BLOOMFILTER_HASH_NUMBER_URL"),
bit=self.settings.get("BLOOMFILTER_BIT_URL"))
#exists()方法,url存在返回1, 否则返回false
if bf.exists(url):
logging.info(f'去重url:{url}')
return(True)
else:
bf.insert(url)
return(False)查看终端去重输出效果
