python爬取百度图片
实验目的:在python语言中掌握正则表达式的使用;文件的读写操作。
实验要求:独立完成,并上机实践
实验内容:
一、爬取百度图片
1、准备工作:
安装爬虫需要的包: requests、lxml 、urllib
说明:requests 是用来获取网页信息的;lxml 用来解析html信息;
2、百度搜索图片的网址分析
如果在百度图片搜索中按“猫”关键字搜索后得到的url地址为:
http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1575430765250_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1575430765252%5E00_1583X701&sid=&word=%E7%8C%AB
点击下一页:得到的url地址:
http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E7%8C%AB&pn=20&gsm=&ct=&ic=0&lm=-1&width=0&height=0
3、在网页的源代码中找到要下载的图片的地址
单击网页右键,可以进入网页源代码:发现图片的地址是红色下划线部分:

因此,我们只要用正则表达式来表达该地址,即"objURL":"(.?)"。
4、编写代码
思路:(1)输入要下载的图片的关键字word(如猫、狗、玫瑰花、李小龙等)。与上面的第2步的地址分析得到下载的图片的地址为:
url = ‘http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=’ + word + ‘&pn=’
(2)用requests.get(url,timeout=10)活动百度图片的html代码
(3)用re.findall(’“objURL”:"(.?)",’, html, re.S)找到当前页面所有的图片地址。
(4)按图片地址依次把图片写入文件。
**
5、完整代码
import re
import requests
from urllib import error
import os
num = 0
numPicture = 0
file = ''
List = []
def dwonPicture(html, keyword):
global num
# 找到当前页面所有的图片地址
'''
re.S的作用:如果不使用re.S参数,则只在每一行内进行匹配,
如果一行没有,就换下一行重新开始匹配
.*?任意个数的字符
'''
pic_url = re.findall('"objURL":"(.*?)",', html, re.S) # 先利用正则表达式找到图片url
print('找到关键词:' + keyword + '的图片,即将开始下载图片...')
for each in pic_url:
print('正在下载第' + str(num + 1) + '张图片,图片地址:' + str(each))
try:
if each is not None:
pic = requests.get(each, timeout=7) # 获取百度图片的html代码
else:
continue
except BaseException:
print('错误,当前图片无法下载')
continue
string = file + r'\\' + keyword + '_' + str(num) + '.jpg'
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
num += 1
if num >= numPicture:
return
if __name__ == '__main__': # 主函数入口
word = input("请输入搜索关键词(如猫、狗、玫瑰花、黄山等): ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&pn='
numPicture = int(input('请输入要下载的图片数量 '))
file = input('输入存储图片的文件夹的名称(如猫、狗、玫瑰花等')
flag = os.path.exists(file)#判断文件夹是否存在
if flag == 1:
print('该文件已存在,请重新输入')
file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可')
os.mkdir(file)
else:
os.mkdir(file)
pn= 0
tmp = url
while pn < numPicture:
try:
url = tmp + str(pn)
result = requests.get(url, timeout=10) # 获得百度图片的html的代码
print(url)
except error.HTTPError as e:
print('网络有问题,请联网后再试一试')
pn = pn + 20
else:
dwonPicture(result.text, word)
pn = pn + 20
print('当前搜索结束,感谢使用')
**
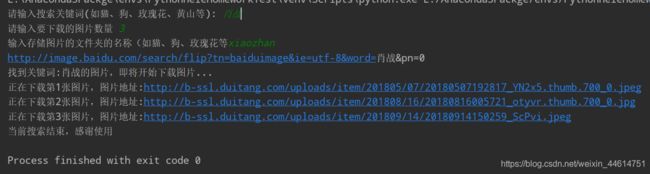
运行结果: