Go的研习笔记-day9(以Java的视角学习Go)
结构(struct)与方法(method)
Go 通过类型别名(alias types)和结构体的形式支持用户自定义类型,或者叫定制类型。一个带属性的结构体试图表示一个现实世界中的实体。结构体是复合类型(composite types),当需要定义一个类型,它由一系列属性组成,每个属性都有自己的类型和值的时候,就应该使用结构体,它把数据聚集在一起。然后可以访问这些数据,就好像它是一个独立实体的一部分。结构体也是值类型,因此可以通过 new 函数来创建。
组成结构体类型的那些数据称为 字段(fields)。每个字段都有一个类型和一个名字;在一个结构体中,字段名字必须是唯一的。
结构体的概念在软件工程上旧的术语叫 ADT(抽象数据类型:Abstract Data Type),在一些老的编程语言中叫 记录(Record),比如 Cobol,在 C 家族的编程语言中它也存在,并且名字也是 struct,在面向对象的编程语言中,跟一个无方法的轻量级类一样。不过因为 Go 语言中没有类的概念,因此在 Go 中结构体有着更为重要的地位。
所以通过与Java比较可知struct其实就是一个无方法的class类似。
- 结构体定义
结构体定义的一般方式如下:
type identifier struct {
field1 type1
field2 type2
...
}
type T struct {a, b int} 也是合法的语法,它更适用于简单的结构体。
结构体里的字段都有 名字,像 field1、field2 等,如果字段在代码中从来也不会被用到,那么可以命名它为 _。
结构体的字段可以是任何类型,甚至是结构体本身,也可以是函数或者接口。可以声明结构体类型的一个变量,然后像下面这样给它的字段赋值
var s T
s.a = 5
s.b = 8
数组可以看作是一种结构体类型,不过它使用下标而不是具名的字段
使用 new
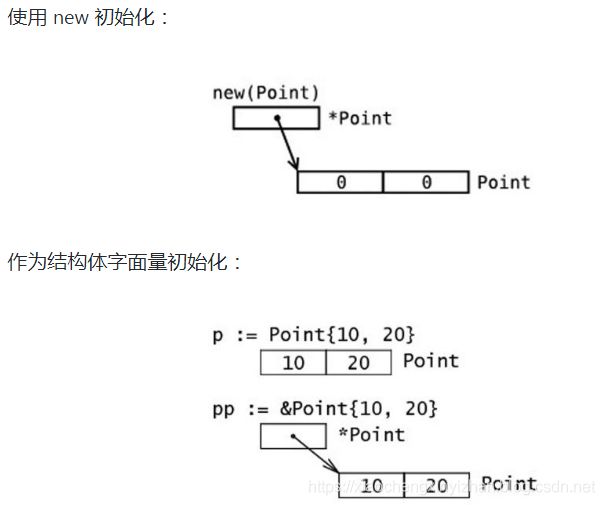
使用 new 函数给一个新的结构体变量分配内存,它返回指向已分配内存的指针:var t *T = new(T),如果需要可以把这条语句放在不同的行(比如定义是包范围的,但是分配却没有必要在开始就做)。
var t *T
t = new(T)
写这条语句的惯用方法是:t := new(T),变量 t 是一个指向 T的指针,此时结构体字段的值是它们所属类型的零值。
声明 var t T 也会给 t 分配内存,并零值化内存,但是这个时候 t 是类型T。在这两种方式中,t 通常被称做类型 T 的一个实例(instance)或对象(object)。
例子用法:
package main
import "fmt"
type struct1 struct {
i1 int
f1 float32
str string
}
func main() {
ms := new(struct1)
ms.i1 = 10
ms.f1 = 15.5
ms.str= "Chris"
fmt.Printf("The int is: %d\n", ms.i1)
fmt.Printf("The float is: %f\n", ms.f1)
fmt.Printf("The string is: %s\n", ms.str)
fmt.Println(ms)
}
与面向对象Java语言所作的那样,可以使用点号符给字段赋值:structname.fieldname = value。
同样的,使用点号符可以获取结构体字段的值:structname.fieldname。
在 Go 语言中这叫 选择器(selector)。无论变量是一个结构体类型还是一个结构体类型指针,都使用同样的 选择器符(selector-notation) 来引用结构体的字段:
type myStruct struct { i int }
var v myStruct // v是结构体类型变量
var p *myStruct // p是指向一个结构体类型变量的指针
v.i
p.i
初始化一个结构体实例(一个结构体字面量:struct-literal)的更简短和惯用的方式如下:
ms := &struct1{10, 15.5, "Chris"}
// 此时ms的类型是 *struct1
或者:
var ms struct1
ms = struct1{10, 15.5, "Chris"}
混合字面量语法(composite literal syntax)&struct1{a, b, c} 是一种简写,底层仍然会调用 new (),这里值的顺序必须按照字段顺序来写。在下面的例子中能看到可以通过在值的前面放上字段名来初始化字段的方式。表达式 new(Type) 和 &Type{} 是等价的。
时间间隔(开始和结束时间以秒为单位)是使用结构体的一个典型例子:
type Interval struct {
start int
end int
}
初始化方式:
intr := Interval{0, 3} (A)
intr := Interval{end:5, start:1} (B)
intr := Interval{end:5} (C)
在(A)中,值必须以字段在结构体定义时的顺序给出,& 不是必须的。(B)显示了另一种方式,字段名加一个冒号放在值的前面,这种情况下值的顺序不必一致,并且某些字段还可以被忽略掉,就像(C)中那样
结构体类型和字段的命名遵循可见性规则,一个导出的结构体类型中有些字段是导出的,另一些不是,这是可能的。
下图说明了结构体类型实例和一个指向它的指针的内存布局:
type Point struct { x, y int }
类型 strcut1 在定义它的包 pack1 中必须是唯一的,它的完全类型名是:pack1.struct1。
package main
import (
"fmt"
"strings"
)
type Person struct {
firstName string
lastName string
}
func upPerson(p *Person) {
p.firstName = strings.ToUpper(p.firstName)
p.lastName = strings.ToUpper(p.lastName)
}
func main() {
// 1-struct as a value type:
var pers1 Person
pers1.firstName = "Chris"
pers1.lastName = "Woodward"
upPerson(&pers1)
fmt.Printf("The name of the person is %s %s\n", pers1.firstName, pers1.lastName)
// 2—struct as a pointer:
pers2 := new(Person)
pers2.firstName = "Chris"
pers2.lastName = "Woodward"
(*pers2).lastName = "Woodward" // 这是合法的
upPerson(pers2)
fmt.Printf("The name of the person is %s %s\n", pers2.firstName, pers2.lastName)
// 3—struct as a literal:
pers3 := &Person{"Chris","Woodward"}
upPerson(pers3)
fmt.Printf("The name of the person is %s %s\n", pers3.firstName, pers3.lastName)
}
在上面例子的第二种情况中,可以直接通过指针,像 pers2.lastName="Woodward" 这样给结构体字段赋值,没有像 C++ 中那样需要使用 -> 操作符,Go 会自动做这样的转换。
注意也可以通过解指针的方式来设置值:(*pers2).lastName = "Woodward"
- 结构体的内存布局
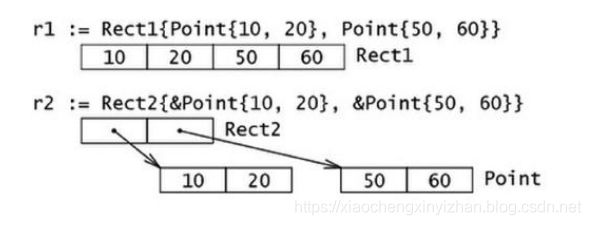
Go 语言中,结构体和它所包含的数据在内存中是以连续块的形式存在的,即使结构体中嵌套有其他的结构体,这在性能上带来了很大的优势。不像 Java 中的引用类型,一个对象和它里面包含的对象可能会在不同的内存空间中,这点和 Go 语言中的指针很像。下面的例子清晰地说明了这些情况:
type Rect1 struct {Min, Max Point }
type Rect2 struct {Min, Max *Point }
递归结构体
结构体类型可以通过引用自身来定义。这在定义链表或二叉树的元素(通常叫节点)时特别有用,此时节点包含指向临近节点的链接(地址)。如下所示,链表中的 su,树中的 ri 和 le 分别是指向别的节点的指针。
链表:
这块的 data 字段用于存放有效数据(比如 float64),su 指针指向后继节点。
代码实现:

type Node struct {
data float64
su *Node
}
链表中的第一个元素叫 head,它指向第二个元素;最后一个元素叫 tail,它没有后继元素,所以它的 su 为 nil 值。当然真实的链接会有很多数据节点,并且链表可以动态增长或收缩。
同样地可以定义一个双向链表,它有一个前趋节点 pr 和一个后继节点 su:
type Node struct {
pr *Node
data float64
su *Node
}
二叉树:
二叉树中每个节点最多能链接至两个节点:左节点(le)和右节点(ri),这两个节点本身又可以有左右节点,依次类推。树的顶层节点叫根节点(root),底层没有子节点的节点叫叶子节点(leaves),叶子节点的 le 和 ri 指针为 nil 值。在 Go 中可以如下定义二叉树:
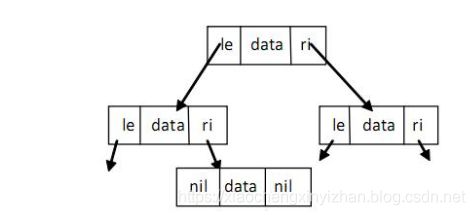
type Tree strcut {
le *Tree
data float64
ri *Tree
}
结构体转换
Go 中的类型转换遵循严格的规则。当为结构体定义了一个 alias 类型时,此结构体类型和它的 alias 类型都有相同的底层类型,它们可以如示例 10.3 那样互相转换,同时需要注意其中非法赋值或转换引起的编译错误。
package main
import "fmt"
type number struct {
f float32
}
type nr number // alias type
func main() {
a := number{5.0}
b := nr{5.0}
// var i float32 = b // compile-error: cannot use b (type nr) as type float32 in assignment
// var i = float32(b) // compile-error: cannot convert b (type nr) to type float32
// var c number = b // compile-error: cannot use b (type nr) as type number in assignment
// needs a conversion:
var c = number(b)
fmt.Println(a, b, c)
}
二、使用工厂方法创建结构体实例
- 结构体工厂
Go 语言不支持面向对象编程语言中那样的构造子方法,但是可以很容易的在 Go 中实现 “构造子工厂”方法。为了方便通常会为类型定义一个工厂,按惯例,工厂的名字以 new 或 New 开头。假设定义了如下的 File 结构体类型:
type File struct {
fd int // 文件描述符
name string // 文件名
}
下面是这个结构体类型对应的工厂方法,它返回一个指向结构体实例的指针:
func NewFile(fd int, name string) *File {
if fd < 0 {
return nil
}
return &File{fd, name}
}
然后这样调用它:
f := NewFile(10, "./test.txt")
如果想知道结构体类型T的一个实例占用了多少内存,可以使用:size := unsafe.Sizeof(T{})。
如何强制使用工厂方法
通过应用可见性规则可以禁止使用 new 函数,强制用户使用工厂方法,从而使类型变成私有的,就像在面向对象Java语言中那样private修饰。
type matrix struct {
...
}
func NewMatrix(params) *matrix {
m := new(matrix) // 初始化 m
return m
}
在其他包里使用工厂方法:
package main
import "matrix"
...
wrong := new(matrix.matrix) // 编译失败(matrix 是私有的)
right := matrix.NewMatrix(...) // 实例化 matrix 的唯一方式
map 和 struct vs new() 和 make()
package main
type Foo map[string]string
type Bar struct {
thingOne string
thingTwo int
}
func main() {
// OK
y := new(Bar)
(*y).thingOne = "hello"
(*y).thingTwo = 1
// NOT OK
z := make(Bar) // 编译错误:cannot make type Bar
(*z).thingOne = "hello"
(*z).thingTwo = 1
// OK
x := make(Foo)
x["x"] = "goodbye"
x["y"] = "world"
// NOT OK
u := new(Foo)
(*u)["x"] = "goodbye" // 运行时错误!! panic: assignment to entry in nil map
(*u)["y"] = "world"
}
因为 new(Foo) 返回的是一个指向 nil 的指针,它尚未被分配内存。所以在使用 map 时要特别谨慎
三、使用自定义包中的结构体
package structPack
type ExpStruct struct {
Mi1 int
Mf1 float32
}
package main
import (
"fmt"
"./struct_pack/structPack"
)
func main() {
struct1 := new(structPack.ExpStruct)
struct1.Mi1 = 10
struct1.Mf1 = 16.
fmt.Printf("Mi1 = %d\n", struct1.Mi1)
fmt.Printf("Mf1 = %f\n", struct1.Mf1)
}
四、带标签的结构体
结构体中的字段除了有名字和类型外,还可以有一个可选的标签(tag):它是一个附属于字段的字符串,可以是文档或其他的重要标记。标签的内容不可以在一般的编程中使用,只有包 reflect 能获取它。它可以在运行时自省类型、属性和方法,比如:在一个变量上调用 reflect.TypeOf() 可以获取变量的正确类型,如果变量是一个结构体类型,就可以通过 Field 来索引结构体的字段,然后就可以使用 Tag 属性。
package main
import (
"fmt"
"reflect"
)
type TagType struct { // tags
field1 bool "An important answer"
field2 string "The name of the thing"
field3 int "How much there are"
}
func main() {
tt := TagType{true, "Barak Obama", 1}
for i := 0; i < 3; i++ {
refTag(tt, i)
}
}
func refTag(tt TagType, ix int) {
ttType := reflect.TypeOf(tt)
ixField := ttType.Field(ix)
fmt.Printf("%v\n", ixField.Tag)
}
五、匿名字段和内嵌结构体
- 定义
结构体可以包含一个或多个 匿名(或内嵌)字段,即这些字段没有显式的名字,只有字段的类型是必须的,此时类型就是字段的名字。匿名字段本身可以是一个结构体类型,即 结构体可以包含内嵌结构体。
可以粗略地将这个和面向对象语言中的继承概念相比较,随后将会看到它被用来模拟类似继承的行为。Go 语言中的继承是通过内嵌或组合来实现的,所以可以说,在 Go 语言中,相比较于继承,组合更受青睐。
package main
import "fmt"
type innerS struct {
in1 int
in2 int
}
type outerS struct {
b int
c float32
int // anonymous field
innerS //anonymous field
}
func main() {
outer := new(outerS)
outer.b = 6
outer.c = 7.5
outer.int = 60
outer.in1 = 5
outer.in2 = 10
fmt.Printf("outer.b is: %d\n", outer.b)
fmt.Printf("outer.c is: %f\n", outer.c)
fmt.Printf("outer.int is: %d\n", outer.int)
fmt.Printf("outer.in1 is: %d\n", outer.in1)
fmt.Printf("outer.in2 is: %d\n", outer.in2)
// 使用结构体字面量
outer2 := outerS{6, 7.5, 60, innerS{5, 10}}
fmt.Println("outer2 is:", outer2)
}
通过类型 outer.int 的名字来获取存储在匿名字段中的数据,于是可以得出一个结论:在一个结构体中对于每一种数据类型只能有一个匿名字段。
内嵌结构体
同样地结构体也是一种数据类型,所以它也可以作为一个匿名字段来使用,如同上面例子中那样。外层结构体通过 outer.in1 直接进入内层结构体的字段,内嵌结构体甚至可以来自其他包。内层结构体被简单的插入或者内嵌进外层结构体。这个简单的“继承”机制提供了一种方式,使得可以从另外一个或一些类型继承部分或全部实现。
package main
import "fmt"
type A struct {
ax, ay int
}
type B struct {
A
bx, by float32
}
func main() {
b := B{A{1, 2}, 3.0, 4.0}
fmt.Println(b.ax, b.ay, b.bx, b.by)
fmt.Println(b.A)
}
命名冲突
当两个字段拥有相同的名字(可能是继承来的名字)时该怎么办呢?
- 外层名字会覆盖内层名字(但是两者的内存空间都保留),这提供了一种重载字段或方法的方式;
- 如果相同的名字在同一级别出现了两次,如果这个名字被程序使用了,将会引发一个错误(不使用没关系)。没有办法来解决这种问题引起的二义性,必须由程序员自己修正。
方法
方法是什么
一个类型加上它的方法等价于面向对象中的一个类。一个重要的区别是:在 Go 中,类型的代码和绑定在它上面的方法的代码可以不放置在一起,它们可以存在在不同的源文件,唯一的要求是:它们必须是同一个包的。
类型 T(或 *T)上的所有方法的集合叫做类型 T(或 *T)的方法集(method set)。
因为方法是函数,所以同样的,不允许方法重载,即对于一个类型只能有一个给定名称的方法。但是如果基于接收者类型,是有重载的:具有同样名字的方法可以在 2 个或多个不同的接收者类型上存在,比如在同一个包里这么做是允许的:
func (a *denseMatrix) Add(b Matrix) Matrix
func (a *sparseMatrix) Add(b Matrix) Matrix
别名类型没有原始类型上已经定义过的方法。
定义方法的一般格式如下:
func (recv receiver_type) methodName(parameter_list) (return_value_list) { … }
举个例子:
package main
import "fmt"
type TwoInts struct {
a int
b int
}
func main() {
two1 := new(TwoInts)
two1.a = 12
two1.b = 10
fmt.Printf("The sum is: %d\n", two1.AddThem())
fmt.Printf("Add them to the param: %d\n", two1.AddToParam(20))
two2 := TwoInts{3, 4}
fmt.Printf("The sum is: %d\n", two2.AddThem())
}
func (tn *TwoInts) AddThem() int {
return tn.a + tn.b
}
func (tn *TwoInts) AddToParam(param int) int {
return tn.a + tn.b + param
}
输出:
The sum is: 22
Add them to the param: 42
The sum is: 7
下面是非结构体类型上方法的例子:
package main
import "fmt"
type IntVector []int
func (v IntVector) Sum() (s int) {
for _, x := range v {
s += x
}
return
}
func main() {
fmt.Println(IntVector{1, 2, 3}.Sum()) // 输出是6
}
- 函数和方法的区别
函数将变量作为参数:Function1(recv)
方法在变量上被调用:recv.Method1()
在接收者是指针时,方法可以改变接收者的值(或状态),这点函数也可以做到(当参数作为指针传递,即通过引用调用时,函数也可以改变参数的状态)。
不要忘记 Method1 后边的括号 (),否则会引发编译器错误:method recv.Method1 is not an expression, must be called
接收者必须有一个显式的名字,这个名字必须在方法中被使用。
receiver_type 叫做 (接收者)基本类型,这个类型必须在和方法同样的包中被声明。
在 Go 中,(接收者)类型关联的方法不写在类型结构里面,就像类那样;耦合更加宽松;类型和方法之间的关联由接收者来建立。
方法没有和数据定义(结构体)混在一起:它们是正交的类型;表示(数据)和行为(方法)是独立的。
- 指针或值作为接收者
package main
import (
"fmt"
)
type B struct {
thing int
}
func (b *B) change() { b.thing = 1 }
func (b B) write() string { return fmt.Sprint(b) }
func main() {
var b1 B // b1是值
b1.change()
fmt.Println(b1.write())
b2 := new(B) // b2是指针
b2.change()
fmt.Println(b2.write())
}
/* 输出:
{1}
{1}
*/
指针方法和值方法都可以在指针或非指针上被调用,如下面程序所示,类型 List 在值上有一个方法 Len(),在指针上有一个方法 Append(),但是可以看到两个方法都可以在两种类型的变量上被调用。
package main
import (
"fmt"
)
type List []int
func (l List) Len() int { return len(l) }
func (l *List) Append(val int) { *l = append(*l, val) }
func main() {
// 值
var lst List
lst.Append(1)
fmt.Printf("%v (len: %d)", lst, lst.Len()) // [1] (len: 1)
// 指针
plst := new(List)
plst.Append(2)
fmt.Printf("%v (len: %d)", plst, plst.Len()) // &[2] (len: 1)
}
- 方法和未导出字段
如何在另一个程序中修改或者只是读取一个 Person 的名字呢?假设我们现在是面向对象的Java语言,我们通常可以使用setter方法或者getter方法更改和获取名称。在go语言中可以通过设置set方法来实现。
package person
type Person struct {
firstName string
lastName string
}
func (p *Person) FirstName() string {
return p.firstName
}
func (p *Person) SetFirstName(newName string) {
p.firstName = newName
}
package main
import (
"./person"
"fmt"
)
func main() {
p := new(person.Person)
// p.firstName undefined
// (cannot refer to unexported field or method firstName)
// p.firstName = "Eric"
p.SetFirstName("Eric")
fmt.Println(p.FirstName()) // Output: Eric
}
== 并发访问对象==
对象的字段(属性)不应该由 2 个或 2 个以上的不同线程在同一时间去改变。如果在程序发生这种情况,为了安全并发访问,可以使用包 sync中的方法或者通过 goroutines 和 channels 探索另一种方式。
内嵌类型的方法和继承
当一个匿名类型被内嵌在结构体中时,匿名类型的可见方法也同样被内嵌,这在效果上等同于外层类型 继承 了这些方法:将父类型放在子类型中来实现亚型。这个机制提供了一种简单的方式来模拟经典面向对象语言中的子类和继承相关的效果,也类似 Ruby 中的混入(mixin)。
假定有一个 Engine 接口类型,一个 Car 结构体类型,它包含一个 Engine 类型的匿名字段:
type Engine interface {
Start()
Stop()
}
type Car struct {
Engine
}
我们可以构建如下的代码:
func (c *Car) GoToWorkIn() {
// get in car
c.Start()
// drive to work
c.Stop()
// get out of car
}
这里面其实*Car的结构体相当于面向对象语言Java中的实现类
下面是 method3.go 的完整例子,它展示了内嵌结构体上的方法可以直接在外层类型的实例上调用:
package main
import (
"fmt"
"math"
)
type Point struct {
x, y float64
}
func (p *Point) Abs() float64 {
return math.Sqrt(p.x*p.x + p.y*p.y)
}
type NamedPoint struct {
Point
name string
}
func main() {
n := &NamedPoint{Point{3, 4}, "Pythagoras"}
fmt.Println(n.Abs()) // 打印5
}
内嵌将一个已存在类型的字段和方法注入到了另一个类型里:匿名字段上的方法“晋升”成为了外层类型的方法。当然类型可以有只作用于本身实例而不作用于内嵌“父”类型上的方法,
可以覆写方法(像字段一样):和内嵌类型方法具有同样名字的外层类型的方法会覆写内嵌类型对应的方法。
- 如何在类型中嵌入功能
主要有两种方法来实现在类型中嵌入功能:
- A:聚合(或组合):包含一个所需功能类型的具名字段。
- B:内嵌:内嵌(匿名地)所需功能类型,
为了使这些概念具体化,假设有一个 Customer 类型,我们想让它通过 Log 类型来包含日志功能,Log 类型只是简单地包含一个累积的消息(当然它可以是复杂的)。如果想让特定类型都具备日志功能,你可以实现一个这样的 Log 类型,然后将它作为特定类型的一个字段,并提供 Log(),它返回这个日志的引用。
方式 A 可以通过如下方法实现
package main
import (
"fmt"
)
type Log struct {
msg string
}
type Customer struct {
Name string
log *Log
}
func main() {
c := new(Customer)
c.Name = "Barak Obama"
c.log = new(Log)
c.log.msg = "1 - Yes we can!"
// shorter
c = &Customer{"Barak Obama", &Log{"1 - Yes we can!"}}
// fmt.Println(c) &{Barak Obama 1 - Yes we can!}
c.Log().Add("2 - After me the world will be a better place!")
//fmt.Println(c.log)
fmt.Println(c.Log())
}
func (l *Log) Add(s string) {
l.msg += "\n" + s
}
func (l *Log) String() string {
return l.msg
}
func (c *Customer) Log() *Log {
return c.log
}
相对的方式 B 可能会像这样:
package main
import (
"fmt"
)
type Log struct {
msg string
}
type Customer struct {
Name string
Log
}
func main() {
c := &Customer{"Barak Obama", Log{"1 - Yes we can!"}}
c.Add("2 - After me the world will be a better place!")
fmt.Println(c)
}
func (l *Log) Add(s string) {
l.msg += "\n" + s
}
func (l *Log) String() string {
return l.msg
}
func (c *Customer) String() string {
return c.Name + "\nLog:" + fmt.Sprintln(c.Log)
}
- 多重继承
多重继承指的是类型获得多个父类型行为的能力,它在传统的面向对象语言中通常是不被实现的(C++ 和 Python 例外)。因为在类继承层次中,多重继承会给编译器引入额外的复杂度。但是在 Go 语言中,通过在类型中嵌入所有必要的父类型,可以很简单的实现多重继承。
package main
import (
"fmt"
)
type Camera struct{}
func (c *Camera) TakeAPicture() string {
return "Click"
}
type Phone struct{}
func (p *Phone) Call() string {
return "Ring Ring"
}
type CameraPhone struct {
Camera
Phone
}
func main() {
cp := new(CameraPhone)
fmt.Println("Our new CameraPhone exhibits multiple behaviors...")
fmt.Println("It exhibits behavior of a Camera: ", cp.TakeAPicture())
fmt.Println("It works like a Phone too: ", cp.Call())
}
- 通用方法和方法命名
在编程中一些基本操作会一遍又一遍的出现,比如打开(Open)、关闭(Close)、读(Read)、写(Write)、排序(Sort)等等,并且它们都有一个大致的意思:打开(Open)可以作用于一个文件、一个网络连接、一个数据库连接等等。具体的实现可能千差万别,但是基本的概念是一致的。在 Go 语言中,通过使用接口(参考 第 11 章),标准库广泛的应用了这些规则,在标准库中这些通用方法都有一致的名字,比如 Open()、Read()、Write()等。
- 和其他面向对象语言比较 Go 的类型和方法
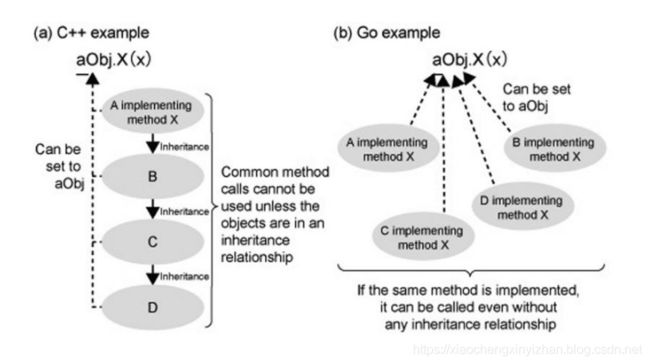
在如 C++、Java、C# 和 Ruby 这样的面向对象语言中,方法在类的上下文中被定义和继承:在一个对象上调用方法时,运行时会检测类以及它的超类中是否有此方法的定义,如果没有会导致异常发生。
在 Go 语言中,这样的继承层次是完全没必要的:如果方法在此类型定义了,就可以调用它,和其他类型上是否存在这个方法没有关系。在这个意义上,Go 具有更大的灵活性。
也就是通俗的说,面向对象语言传统来看的话需要显示继承关系,但是对于go语言来说,只要有相同方法被实现,则Ok。
Go 不需要一个显式的类定义,如同 Java、C++、C# 等那样,相反地,“类”是通过提供一组作用于一个共同类型的方法集来隐式定义的。类型可以是结构体或者任何用户自定义类型。
比如:我们想定义自己的 Integer 类型,并添加一些类似转换成字符串的方法,在 Go 中可以如下定义
type Integer int
func (i *Integer) String() string {
return strconv.Itoa(int(*i))
}
在 Java 或 C# 中,这个方法需要和类 Integer 的定义放在一起,在 Ruby 中可以直接在基本类型 int 上定义这个方法。
总结
在 Go 中,类型就是类(数据和关联的方法)。Go 不知道类似面向对象语言的类继承的概念。继承有两个好处:代码复用和多态。
在 Go 中,代码复用通过组合和委托实现,多态通过接口的使用来实现:有时这也叫 组件编程(Component Programming)。
许多开发者说相比于类继承,Go 的接口提供了更强大、却更简单的多态行为。
- 类型的 String() 方法和格式化描述符
如果类型定义了 String() 方法,它会被用在 fmt.Printf() 中生成默认的输出:等同于使用格式化描述符 %v 产生的输出。还有 fmt.Print() 和 fmt.Println() 也会自动使用 String() 方法。
package main
import (
"fmt"
"strconv"
)
type TwoInts struct {
a int
b int
}
func main() {
two1 := new(TwoInts)
two1.a = 12
two1.b = 10
fmt.Printf("two1 is: %v\n", two1)
fmt.Println("two1 is:", two1)
fmt.Printf("two1 is: %T\n", two1)
fmt.Printf("two1 is: %#v\n", two1)
}
func (tn *TwoInts) String() string {
return "(" + strconv.Itoa(tn.a) + "/" + strconv.Itoa(tn.b) + ")"
}
备注
不要在 String() 方法里面调用涉及 String() 方法的方法,它会导致意料之外的错误,比如下面的例子,它导致了一个无限递归调用(TT.String() 调用 fmt.Sprintf,而 fmt.Sprintf 又会反过来调用 TT.String()…),很快就会导致内存溢出:
type TT float64
func (t TT) String() string {
return fmt.Sprintf("%v", t)
}
t.String()
- 垃圾回收和 SetFinalizer
Go 开发者不需要写代码来释放程序中不再使用的变量和结构占用的内存,在 Go 运行时中有一个独立的进程,即垃圾收集器(GC),会处理这些事情,它搜索不再使用的变量然后释放它们的内存。可以通过 runtime 包访问 GC 进程。
通过调用 runtime.GC() 函数可以显式的触发 GC,但这只在某些罕见的场景下才有用,比如当内存资源不足时调用 runtime.GC(),它会在此函数执行的点上立即释放一大片内存,此时程序可能会有短时的性能下降(因为 GC 进程在执行)。
如果想知道当前的内存状态,可以使用:
// fmt.Printf("%d\n", runtime.MemStats.Alloc/1024)
// 此处代码在 Go 1.5.1下不再有效,更正为
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%d Kb\n", m.Alloc / 1024)
上面的程序会给出已分配内存的总量,单位是 Kb。
如果需要在一个对象 obj 被从内存移除前执行一些特殊操作,比如写到日志文件中,可以通过如下方式调用函数来实现:
runtime.SetFinalizer(obj, func(obj *typeObj))
func(obj *typeObj) 需要一个 typeObj 类型的指针参数 obj,特殊操作会在它上面执行。func 也可以是一个匿名函数。
在对象被 GC 进程选中并从内存中移除以前,SetFinalizer 都不会执行,即使程序正常结束或者发生错误。