阿里巴巴研发工程师面经
前缀:
分享一些面试的题目吧,是否拿到offer,还要等2周以后。
阿里印象:
面试地点是在塘苗路18号,一淘那边。
给我的感觉一淘的办公环境着实一般,和网易杭州和MSRA是差了一个档次的。
开始到的时候,很多人也在等,本来通知是4:40,结果等到5:20才面试,等待的过程中发现很多认识的人,阿里如此早的启动招聘,感觉浙大的所有人都被他给面了。
一面:
凭直觉觉得面试官会比较累了,毕竟有一天的面试,所以我展示一些真实的自己---幽默随和
我第一句问面试官的问题是: 饿,你也用小米呀,你的会经常死机吗?
结果他就笑了,随便回答一下,感觉气场上,我就觉得稳住了。
然后就正式面试了,先是自我介绍,然后又聊聊自己做过的东西,关于MSRA实习项目和关于科研项目的。
主要的技术面问题分享一下吧,可能大家对这个比较关心。
1. kmp最基本的考察
2. java序列化怎么实现,自己设计一个
3. 系统调度算法,什么时候会进行进程切换
4. 线程进程的区别
5. 虚函数 和 重载实现
6. acid
7. 单元最短路径算法,考虑dijkstra在产品中的应用
感觉还有很多问题,不过都记不清了。
二面:
二面等了很久,真的很久,我进去二面的时候,都已经7:40差不多了。
面试官就是随意了解一些之前做过的东西,然后问问如何能和淘宝联系起来,问问为什么不考虑网易游戏(因为个人简历感觉比较match游戏公司)。
总之二面也是终面,基本没有什么技术问题。
很多二十分钟就面完了。
其实感觉今天面试还是比较happy的,感觉一面的时候气场表现的很好,我们两个聊得很happy的感觉。
接下来就不清楚了,等通知~
笔试部分:
顺便补充一下阿里巴巴笔试的题目。
1. 有一个有超大的集合A,里面存储产品ID,作为用户浏览LOG,可能有重复ID。
还有一个产品库集合B,里面也是产品ID
求B-A。
从july那里学到一个思路,直接贴上好了,自己写的不怎么好。
http://blog.csdn.net/v_july_v/article/details/7382693
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 分而治之/hash映射:遍历文件a,对每个url求取
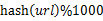 ,然后根据所取得的值将url分别存储到1000个小文件(记为
,然后根据所取得的值将url分别存储到1000个小文件(记为 )中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为
)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件(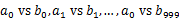 )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。 - hash统计:求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
2, 是关于字符串查找的
例如字符串数组 A = {"you", "are", "a good boy"}
现在有一句query. "kuku are good boys"
因为are在字典A里,所以返回true,但是 good boys不是在字典里面的。
1. 写代码
bool check( std::vector
2. 当A有如下性质的时候,如何使性能最好: A中元素很多,但是长度比较小。
感觉第一个就是枚举query的所有后缀(以单词为单位的),然后去dict里遍历。
第二个问,我给出的是trie树