CIFAR-10整体解析与评价
1. 综述
CIFAR-10是机器学习分类问题中的一个标尺问题。目标是将RGB 32*32的图像分成10类:飞机(airplane),汽车(automobile),鸟(bird),猫(cat),鹿(deer),狗(dog),青蛙(frog),马(horse),船(ship),卡车(truck)。

2. 目标
建立一个相对小的卷积神经网络分类图像。在这个过程中,
1. 强调了网络结构、训练和评估的规范组织方式。
2. 提供了构建更大和更精细的模型的模板。
选择CIFAR-10的原因:一是它足够复杂,可以训练TensorFlow的大规模模型的大部分能力;二是,它足够小,可以快速训练,这对于尝试新想法和实验新技术是理想的。
3. 重点
本教程为在TensorFlow中设计更大和更精细的模型了展示几个重要构想:
- 核心数学元素包括:卷积,激活函数ReLu, 池化max-pooling,标准化local response normalization
- 可视化(visualization)训练过程中的网络激活(network activities),包含图像输入,损失函数,激活值和梯度的分布。
- 计算学习参数的移动平均(moving average),使用移动平均法提升预测效果。
- 实现随时间下降的学习率(learning rate)。
-
对输入数据预提取队列(queues),让模型从硬盘延迟和图像预处理中独立出来。
也提供了多GPU版本,暂时忽略。
4.模型结构
模型是一个包含卷积和非线性的多层结构,后面连着全连接层和softmax分类器。模型遵循Alex Krizhevsky描述的结构。
共有1,068,298个学习参数,在单张影像上计算inference需要19.5M个乘-加操作。
在单GPU加速的电脑上训练了3个多小时,精度达到86%。本电脑GPU是NVIDIA GeForce GTX 750。
5.代码组织
代码文件
| 文件 | 说明 |
| cifar10_input.py | 读取本地CIFAR-10的二进制文件格式的内容 |
| cifar10.py | 建立CIFAR-10的模型 |
| cifar10_train.py | 在CPU或GPU上训练CIFAR-10的模型 |
| cifar10_multi_gpu_train.py | 在多GPU上训练CIFAR-10的模型。 |
| cifar10_eval.py | 评估CIFAR-10模型的预测性能 |
6.CIFAR-10模型
cifar-10文件包含了网络的各个操作,完整的训练图包含765个操作。通过使用一下模块构建图,我们可以使代码更具复用性。
1. 模型输入(Model Inputs): inputs() 和distorted_inputs()分别为评估和训练阶段读取和预处理图像。
2. 模型预测(Model predictions):inference()进行推导(inference)操作。
3. 模型训练(Model training): loss()计算损失,train()计算梯度和更新参数。可视化summaries。
通过Tensorboard可以看到384个维度:

6.1 模型输入
用inputs()和distorted_inputs()函数从CIFAR-10二进制文件中输入图像。因为文件包含字节固定长度的记录,所以使用tf.FixedLengthRecordReader。关于Reader如何工作,详见Reading Data。
图像处理方法:
- 图像被裁剪成24*24大小,评估时从中心裁剪,训练时随机裁剪。
- 近似白化图像,让模型对动态范围不敏感。
训练时,人工对图像增加一些列随机变形操作,以增大图像数据集:
- 随机从左到右翻转(flip)图像。
- 随机扭曲图像亮度(image brightness)。
- 随机扭曲图像对比度(iamge contrast)。
使用iamge_summary,可以在TensorBoard中可视化图像,验证输入图像是否正确。读取图像并扭曲图像很耗费时间,为防止减慢训练,在16个独立线程里处理。
6.2模型预测
用inference()计算预测值的逻辑斯(logits)。下图展示模型层次组成 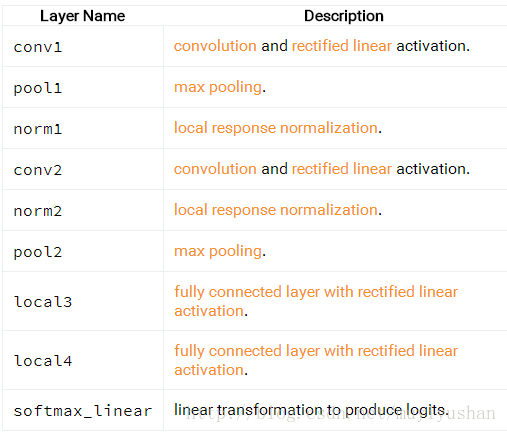
如下解释:
TensorBoard绘制的计算图

6.3模型训练
N-way 分类一般用多项式逻辑回归,比如Softmax。损失函数的total loss包括交叉熵(cross-entropy),正则化的weight decay loss。
在tensorboard中可视化total loss 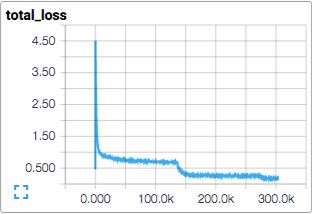
使用SGD和指数衰减的学习率 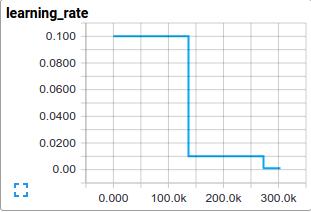
7.启动和训练模型
运行代码
python cifar10_train.py
输出
"D:\Program Files (x86)\Anaconda3 4.2\envs\tensorflow\python.exe" D:/PycharmProject/cifar/cifar10/cifar10_train.py
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2018-01-25 09:40:55.645287: I C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\35\tensorflow\core\platform\cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
2018-01-25 09:40:57.199692: I C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\35\tensorflow\core\common_runtime\gpu\gpu_device.cc:1030] Found device 0 with properties:
name: GeForce GTX 750 Ti major: 5 minor: 0 memoryClockRate(GHz): 1.0845
pciBusID: 0000:03:00.0
totalMemory: 2.00GiB freeMemory: 1.65GiB
2018-01-25 09:40:57.199971: I C:\tf_jenkins\home\workspace\rel-win\M\windows-gpu\PY\35\tensorflow\core\common_runtime\gpu\gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: GeForce GTX 750 Ti, pci bus id: 0000:03:00.0, compute capability: 5.0)
2018-01-25 09:41:14.963154: step 0, loss = 4.68 (65.5 examples/sec; 1.955 sec/batch)
2018-01-25 09:41:15.462490: step 10, loss = 4.65 (2563.4 examples/sec; 0.050 sec/batch)
2018-01-25 09:41:15.867777: step 20, loss = 4.58 (3158.3 examples/sec; 0.041 sec/batch)
2018-01-25 09:41:16.277066: step 30, loss = 4.38 (3127.4 examples/sec; 0.041 sec/batch)
2018-01-25 09:41:16.678350: step 40, loss = 4.36 (3189.8 examples/sec; 0.040 sec/batch)
2018-01-25 09:41:17.084650: step 50, loss = 4.31 (3150.4 examples/sec; 0.041 sec/batch)
2018-01-25 09:41:17.481927: step 60, loss = 4.22 (3221.9 examples/sec; 0.040 sec/batch)
…
每10个step输出一次,有total loss,每秒处理样本数和运行一个batch需要的时间。
cifar-10周期性地在checkpoint files中保存模型参数。checkpoint files会在cifar10_eval.py中测试预测效果。
cifar10_train.py使用SummaryWriter周期性地保存中间数据,tensorboard可以实现可视化。
在CMD中输入
tensorboard --logdir=D:\tmp\cifar10_train
在谷歌浏览器(推荐)中进入提示网页,(我的:http://desktop-ic1scc2:6006),即可打开tensorboard。
8.评估模型
输入
python cifar10_eval.py
输出
2018-1-25 09:30:44.391206: precision @ 1 = 0.860
…
精度在86%左右。
参考:官方教程Convolutional Neural Networks