【python量化】用Python获取基金历史净值数据

写在前面
股票期货等历史数据可以通过很多接口以及库来获取,而针对基金数据获取的方式则比较少。下面这篇文章的主要内容是介绍如何通过Python爬取天天基金网的基金历史数据,以便于我们对基金进行数据分析以及计算其他分析指标。完整源码在文末。
准备工作
下面的代码是基于python3.7.2的版本实现的,需要用到的库有:
requests== 2.22.0
bs4== 4.8.2
numpy== 1.18.1
pandas== 1.0.1
matplotlib== 3.1.3
天天基金网是东方财富旗下的基金网站,其同样也提供了用于获取基金数据的接口:
http://fund.eastmoney.com/f10/F10DataApi.aspx
在使用这个接口时需要传入几个参数,像下面的形式:
http://fund.eastmoney.com/f10/F10DataApi.aspx?type=lsjz&code=050026&page=1&sdate=2020-01-01&edate=2020-03-01&per=20
其中,每个参数的意义是:
-
type:lsjz表示历史净值
-
code:表示基金代码,如050026表示博时医疗保健行业混合
-
page:表示获取的数据的页码
-
per:表示获取的数据每页显示的条数
-
sdate:表示开始时间
-
edate:表示结束时间
上面的例子获取的是050026基金从2020年01月01号到2020年03月01号的历史净值数据,其中结果返回第一页,一页有20条数据,通过浏览器打开如下图所示:
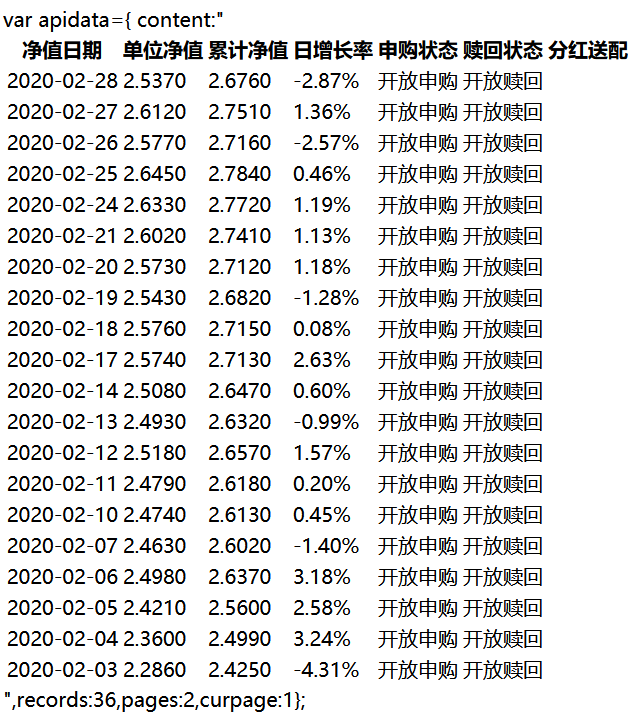
可以看到返回的结果是一个表格的形式,包含了基金的单位净值,累计净值,日增长率,申购状态以及赎回状态。其中单位净值即是当前基金的价格,它的计算方式是:单位净值=总净资产/基金份额。如果在交易日的交易结束(15:00之前)购买基金则是以当日的基金净值确认份额,即:购入份额=购买金额/当日基金净值。如果在交易日的交易时段结束后购买,则会以下一个交易日的基金净值来确认份额。累计净值则是基金的单位净值加上以往的分红,可以反应该基金自成立至今的整体收益。日增长率的计算方式是:(当前交易日净值-上一交易日净值)/上一交易日净值。在上面的返回结果中,还需要注意的是,记录一共有36条,有两页数据,返回的结果是第一页。
代码编写
在分析完接口以及返回数据类型之后,下面进行具体代码的编写。
首先,需要导入相关的库:
# 导入需要的模块
import requests
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
接下来先需要先编写一个函数用于获取来自这个接口的返回结果,以便于后面的调用:
def get_html(code, start_date, end_date, page=1, per=20):
url = 'http://fund.eastmoney.com/f10/F10DataApi.aspx?type=lsjz&code={0}&page={1}&sdate={2}&edate={3}&per={4}'.format(
code, page, start_date, end_date, per)
rsp = requests.get(url)
html = rsp.text
return html
下面再写一个用于返回获取得到基金数据的函数,其中调用bs4中的BeautifulSoup将html结果解析为一个对象,便于从网页中直接抓取数据。
def get_fund(code, start_date, end_date, page=1, per=20):
# 获取html
html = get_html(code, start_date, end_date, page, per)
soup = BeautifulSoup(html, 'html.parser')
由于前面提到的原因,这个接口返回的数据不是直接全部返回,而是以表格分页的形式返回的。所以我们可以先获取返回数据的总页数,然后分别遍历每一页的数据。同时将返回表格的表头信息保存下来以便于将其作为后面转换为DataFrame数据类型的列名。
# 获取总页数
pattern = re.compile('pages:(.*),')
result = re.search(pattern, html).group(1)
total_page = int(result)
# 获取表头信息
heads = []
for head in soup.findAll("th"):
heads.append(head.contents[0])
接下来需要对表格每一页的数据进行遍历,并将数据存储到一个列表中。
# 数据存取列表
records = []
# 获取每一页的数据
current_page = 1
while current_page <= total_page:
html = get_html(code, start_date, end_date, current_page, per)
soup = BeautifulSoup(html, 'html.parser')
# 获取数据
for row in soup.findAll("tbody")[0].findAll("tr"):
row_records = []
for record in row.findAll('td'):
val = record.contents
# 处理空值
if val == []:
row_records.append(np.nan)
else:
row_records.append(val[0])
# 记录数据
records.append(row_records)
# 下一页
current_page = current_page + 1
最后将数据转换为一个DataFrame对象,然后按照日期进行升序排序,最后将其返回。
# 将数据转换为Dataframe对象
np_records = np.array(records)
fund_df = pd.DataFrame()
for col, col_name in enumerate(heads):
fund_df[col_name] = np_records[:, col]
# 按照日期排序
fund_df['净值日期'] = pd.to_datetime(fund_df['净值日期'], format='%Y/%m/%d')
fund_df = fund_df.sort_values(by='净值日期', axis=0, ascending=True).reset_index(drop=True)
fund_df = fund_df.set_index('净值日期')
# 数据类型处理
fund_df['单位净值'] = fund_df['单位净值'].astype(float)
fund_df['累计净值'] = fund_df['累计净值'].astype(float)
fund_df['日增长率'] = fund_df['日增长率'].str.strip('%').astype(float)
return fund_df
运行实例
下面对代码进行运行,以基金050026从2020年02月01号到2020年06月01号的数据获取为例:
fund_df = get_fund('050026' ,start_date='2020-02-01',end_date='2020-06-01')
print(fund_df)
返回结果如下:
单位净值 累计净值 日增长率 申购状态 赎回状态 分红送配
净值日期
2020-02-03 2.2860 2.4250 -4.31% 开放申购 开放赎回 nan
2020-02-04 2.3600 2.4990 3.24% 开放申购 开放赎回 nan
2020-02-05 2.4210 2.5600 2.58% 开放申购 开放赎回 nan
2020-02-06 2.4980 2.6370 3.18% 开放申购 开放赎回 nan
2020-02-07 2.4630 2.6020 -1.40% 开放申购 开放赎回 nan
... ... ... ... ... ... ...
2020-05-26 3.1830 3.3220 2.91% 开放申购 开放赎回 nan
2020-05-27 3.1130 3.2520 -2.20% 开放申购 开放赎回 nan
2020-05-28 3.0820 3.2210 -1.00% 开放申购 开放赎回 nan
2020-05-29 3.1480 3.2870 2.14% 开放申购 开放赎回 nan
2020-06-01 3.2160 3.3550 2.16% 开放申购 开放赎回 nan
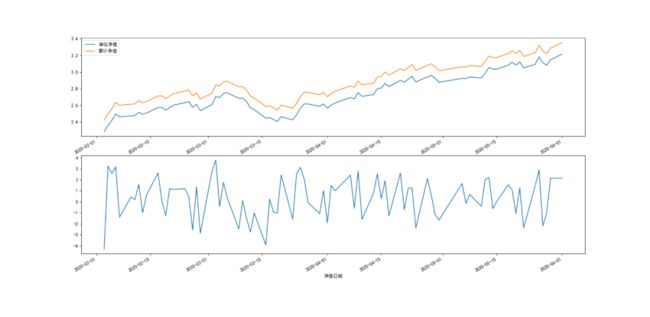
下面对其单位净值,累计净值以及日增长率进行可视化:
fig, axes = plt.subplots(nrows=2, ncols=1)
fund_df[['单位净值', '累计净值']].plot(ax=axes[0])
fund_df['日增长率'].plot(ax=axes[1])
plt.show()
效果如下图所示:
完整源码
完整代码如下:
# 导入需要的模块
import requests
from bs4 import BeautifulSoup
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
# 处理乱码
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
matplotlib.rcParams['axes.unicode_minus'] = False
def get_html(code, start_date, end_date, page=1, per=20):
url = 'http://fund.eastmoney.com/f10/F10DataApi.aspx?type=lsjz&code={0}&page={1}&sdate={2}&edate={3}&per={4}'.format(
code, page, start_date, end_date, per)
rsp = requests.get(url)
html = rsp.text
return html
def get_fund(code, start_date, end_date, page=1, per=20):
# 获取html
html = get_html(code, start_date, end_date, page, per)
soup = BeautifulSoup(html, 'html.parser')
# 获取总页数
pattern = re.compile('pages:(.*),')
result = re.search(pattern, html).group(1)
total_page = int(result)
# 获取表头信息
heads = []
for head in soup.findAll("th"):
heads.append(head.contents[0])
# 数据存取列表
records = []
# 获取每一页的数据
current_page = 1
while current_page <= total_page:
html = get_html(code, start_date, end_date, current_page, per)
soup = BeautifulSoup(html, 'html.parser')
# 获取数据
for row in soup.findAll("tbody")[0].findAll("tr"):
row_records = []
for record in row.findAll('td'):
val = record.contents
# 处理空值
if val == []:
row_records.append(np.nan)
else:
row_records.append(val[0])
# 记录数据
records.append(row_records)
# 下一页
current_page = current_page + 1
# 将数据转换为Dataframe对象
np_records = np.array(records)
fund_df = pd.DataFrame()
for col, col_name in enumerate(heads):
fund_df[col_name] = np_records[:, col]
# 按照日期排序
fund_df['净值日期'] = pd.to_datetime(fund_df['净值日期'], format='%Y/%m/%d')
fund_df = fund_df.sort_values(by='净值日期', axis=0, ascending=True).reset_index(drop=True)
fund_df = fund_df.set_index('净值日期')
# 数据类型处理
fund_df['单位净值'] = fund_df['单位净值'].astype(float)
fund_df['累计净值'] = fund_df['累计净值'].astype(float)
fund_df['日增长率'] = fund_df['日增长率'].str.strip('%').astype(float)
return fund_df
if __name__ == '__main__':
fund_df = get_fund('050026' ,start_date='2020-02-01',end_date='2020-06-01')
print(fund_df)
fig, axes = plt.subplots(nrows=2, ncols=1)
fund_df[['单位净值', '累计净值']].plot(ax=axes[0])
fund_df['日增长率'].plot(ax=axes[1])
plt.show()

了解更多人工智能与量化金融知识<-请扫码关注
![]()