Python for Data Analysis v2 | Notes_ Chapter 1-2
本人以简书作者 SeanCheney 系列专题文章并结合原书为学习资源,记录个人笔记,仅作为知识记录及后期复习所用,原作者地址查看 简书 SeanCheney,如有错误,还望批评指教。——ZJ
原作者:SeanCheney | 链接 | 來源:简书
Github:wesm | Github:中文 BrambleXu|
简书:利用Python进行数据分析·第2版
环境:Python 3.6
第1章 准备工作
1.1 本书的内容
学习目标: 学会利用 Python 进行数据控制、处理、整理、分析等方面的具体细节和基本要点。掌握 Python 编程和用于数据处理的库和工具环境,成为数据分析专家。
什么样的数据?
- 结构化数据(structured data)
- 表格型数据,其中各列可能是不同的类型(字符串、数值、日期等)。比如保存在关系型数据库中或以制表符/逗号为分隔符的文本文件中的那些数据。
- 多维数组(矩阵)。
- 通过关键列(对于SQL用户而言,就是主键和外键)相互联系的多个表。
- 间隔平均或不平均的时间序列。
这绝不是一个完整的列表。大部分数据集都能被转化为更加适合分析和建模的结构化形式。
1.2 为什么要使用Python进行数据分析
- Python 现在已经成为最受欢迎的动态编程语言之一
- Python 发展出了一个巨大而活跃的科学计算(scientific computing)社区。
- Python 从一个边缘或“自担风险”的科学计算语言,成为了数据科学、机器学习、学界和工业界软件开发最重要的语言之一。
- 由于Python的库(例如 pandas 和 scikit-learn)不断改良,使其成为数据分析任务的一个优选方案。结合其在通用编程方面的强大实力,我们完全可以只使用Python这一种语言构建以数据为中心的应用。
- 解决“两种语言”问题 ,(很多组织通常都会用一种类似于领域特定的计算语言(如SAS和R)对新的想法进行研究、原型构建和测试,然后再将这些想法移植到某个更大的生产系统中去(可能是用Java、C#或C++编写的))Python不仅适用于研究和原型构建,同时也适用于构建生产系统。
1.3 重要的Python库
NumPy (Numerical Python的简称)是Python科学计算的基础包。本书大部分内容都基于NumPy以及构建于其上的库。它提供了以下功能(不限于此):
- 快速高效的多维数组对象ndarray。
- 用于对数组执行元素级计算以及直接对数组执行数学运算的函数。
- 用于读写硬盘上基于数组的数据集的工具。
- 线性代数运算、傅里叶变换,以及随机数生成。
成熟的C API, 用于Python插件和原生C、C++、Fortran代码访问NumPy的数据结构和计算工具。 - NumPy在数据分析方面还有另外一个主要作用,即作为在算法和库之间传递数据的容器。
pandas:提供了快速便捷处理结构化数据的大量数据结构和函数。
- 助使Python成为强大而高效的数据分析环境
- 本书用得最多的 pandas 对象是 DataFrame,它是一个面向列(column-oriented)的二维表结构,另一个是 Series ,一个一维的标签化数组对象。
- pandas 兼具 NumPy 高性能的数组计算功能以及电子表格和关系型数据库(如SQL)灵活的数据处理功能。
- 它提供了复杂精细的索引功能,以便更为便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。
- 因为数据操作、准备、清洗是数据分析最重要的技能,pandas 是本书的重点。
- 有标签轴的数据结构,支持自动或清晰的数据对齐。这可以防止由于数据不对齐,和处理来源不同的索引不同的数据,造成的错误。
- 集成时间序列功能。
- 相同的数据结构用于处理时间序列数据和非时间序列数据。
- 保存元数据的算术运算和压缩。
- 灵活处理缺失数据。
- 合并和其它流行数据库(例如基于SQL的数据库)的关系操作。
matplotlib:是最流行的用于绘制图表和其它二维数据可视化的Python库
IPython 和 Jupyter:
- IPython 大大提高交互式计算和软件开发的生产率
- IPython 鼓励“执行-探索”的工作流,它还可以方便地访问系统的shell和文件系统
- Jupyter 一个更宽泛的多语言交互计算工具的计划
- Jupyter notebook,现在支持40种编程语言。IPython 现在可以作为Jupyter 使用 Python的内核(一种编程语言模式)
SciPy: 是一组专门解决科学计算中各种标准问题域的包的集合
- scipy.integrate:数值积分例程和微分方程求解器。
- scipy.linalg:扩展了由numpy.linalg提供的线性代数例程和矩阵分解功能。
- scipy.optimize:函数优化器(最小化器)以及根查找算法。
- scipy.signal:信号处理工具。
- scipy.sparse:稀疏矩阵和稀疏线性系统求解器。
- scipy.special:SPECFUN(这是一个实现了许多常用数学函数(如伽玛函数)的Fortran库)的包装器。
- scipy.stats:标准连续和离散概率分布(如密度函数、采样器、连续分布函数等)、各种统计检验方法,以及更好的描述统计法。
scikit-learn: scikit-learn 成为了 Python 的通用机器学习工具包
- 分类:SVM、近邻、随机森林、逻辑回归等等。
- 回归:Lasso、岭回归等等。
- 聚类:k-均值、谱聚类等等。
- 降维:PCA、特征选择、矩阵分解等等。
- 选型:网格搜索、交叉验证、度量。
- 预处理:特征提取、标准化。
- 与p andas、statsmodels 和 IPython一起,scikit-learn 对于 Python成为高效数据科学编程语言起到了关键作用。
statsmodels: 是一个统计分析包,statsmodels包含经典统计学和经济计量学的算法
- 回归模型:线性回归,广义线性模型,健壮线性模型,线性混合效应模型等等。
- 方差分析(ANOVA)。
- 时间序列分析:AR,ARMA,ARIMA,VAR和其它模型。
- 非参数方法: 核密度估计,核回归。
- 统计模型结果可视化。
1.4 1.5 (略)
1.6 本书导航
与外部世界交互
阅读编写多种文件格式和数据商店;
数据准备
清洗、修改、结合、标准化、重塑、切片、切割、转换数据,以进行分析;
转换数据
对旧的数据集进行数学和统计操作,生成新的数据集(例如,通过各组变量聚类成大的表);
建模和计算
将数据绑定统计模型、机器学习算法、或其他计算工具;
展示
创建交互式和静态的图表可视化和文本总结。
引入惯例
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import statsmodels as sm
第2章 Python 语法基础,IPython 和 Jupyter Notebooks
2.1 Python解释器
Python 是解释性语言。Python 解释器同一时间只能运行一个程序的一条语句。标准的交互 Python 解释器可以在命令行中通过键入 python 命令打开:
C:\Users\qhtf>python
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:57:36) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print(input('what\'s your name:'))
what's your name: ZJ
ZJ
>>> exit()
运行 Python 程序只需调用 Python 的同时,使用一个.py文件作为它的第一个参数。假设创建了一个 hello_world.py 文件,它的内容是:
print('Hello world')
你可以用下面的命令运行它(hello_world.py文件必须位于终端的工作目录):
$ python hello_world.py
Hello world
一些 Python 程序员总是这样执行 Python 代码的,从事数据分析和科学计算的人却会使用 IPython,一个强化的 Python 解释器,或 Jupyter notebooks,一个网页代码笔记本,它原先是 IPython 的一个子项目。
当你使用
%run命令,IPython会同样执行指定文件中的代码,结束之后,还可以与结果交互:
D:\github\pythonpractice>ipython
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:57:36) [MSC v.1900 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 6.2.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: %run hello.py
Hello World
In [2]: exit()
2.2 IPython 基础
运行 IPython Shell
- 你可以用 ipython 在命令行打开 IPython Shell,就像打开普通的 Python 解释器
- 你可以通过输入代码并按Return(或Enter),运行任意Python语句。当你只输入一个变量,它会显示代表的对象:
In [1]: import numpy as np
In [2]: data = {i : np.random.randn() for i in range(7)}
In [3]: data
Out[3]:
{0: -0.7871942220349025,
1: 0.5968958863243701,
2: -0.670023515225677,
3: -0.030930268126603183,
4: 2.0550986476324473,
5: -0.7468422713170355,
6: -0.2948531366214833}
In [4]: exit()
运行 Jupyter Notebook (略)
Tab 自动补全(略)
自省:在变量前后使用问号?,可以显示对象的信息:
In [1]: b = [2,3,4,5]
In [2]: b?
Type: list
String form: [2, 3, 4, 5]
Length: 4
Docstring:
list() -> new empty list
list(iterable) -> new list initialized from iterable's items
In [3]: exit()
- 这可以作为对象的自省。如果对象是一个函数或实例方法,定义过的文档字符串,也会显示出信息。假设我们写了一个如下的函数:
In [1]: def add_number(a, b):
...: '''
...: Add two numbers together
...: Returns
...: ---------
...: the_sum : type of arguments
...: '''
...: return a + b
...:
- 然后使用?符号,就可以显示如下的文档字符串:
In [2]: add_number?
Signature: add_number(a, b)
Docstring:
Add two numbers together
Returns
---------
the_sum : type of arguments
File: d:\github\pythonpractice\
Type: function
In [3]: exit()
- 使用??会显示函数的源码:
In [2]: add_number??
Signature: add_number(a, b)
Source:
def add_number(a, b):
'''
Add two numbers together
Returns
---------
the_sum : type of arguments
'''
return a + b
File: d:\github\pythonpractice\1-0d88bc512be6>
Type: function
- ?还有一个用途,就是像 Unix 或 Windows 命令行一样搜索 IPytho n的命名空间。字符与通配符结合可以匹配所有的名字。例如,我们可以获得所有包含load的顶级 NumPy 命名空间:
def f(x,y,z):
return (x +y)/z
a = 5
b = 6
c = 7.5
result = f(a,b,c)
%run命令 :你可以用%run命令运行所有的 Python 程序。
In [1]: %run ipython_script_test.py
In [2]: c
Out[2]: 7.5
In [3]: result
Out[3]: 1.4666666666666666- 如果一个 Python 脚本需要命令行参数(在 sys.argv 中查找),可以在文件路径之后传递,就像在命令行上运行一样。
如果想让一个脚本访问 IPython 已经定义过的变量,可以使用 %run -i。
在Jupyter notebook中,你也可以使用
%load,它将脚本导入到一个代码格中:
In [4]: %load ipython_script_test.py
In [5]: # %load ipython_script_test.py
...: def f(x,y,z):
...: return (x +y)/z
...:
...: a = 5
...: b = 6
...: c = 7.5
...:
...: result = f(a,b,c)
中断运行的代码: 代码运行时按 Ctrl-C,无论是
%run或长时间运行命令,都会导致KeyboardInterrupt。这会导致几乎左右Python程序立即停止,除非一些特殊情况。从剪贴板执行程序:如果使用 Jupyter notebook,你可以将代码复制粘贴到任意代码格执行。在 IPython shell 中也可以从剪贴板执行。假设在其它应用中复制了如下代码:
x = 5
y = 7
if x > 5:
x += 1
y = 8- 最简单的方法是使用
%paste和%cpaste函数。%paste可以直接运行剪贴板中的代码:
In [6]: %paste
x = 5
y = 7
if x > 5:
x += 1
y = 8
## -- End pasted text --%cpaste功能类似,(输入命令后 Ctrl-V)但会给出一条提示:
In [18]: %cpaste
Pasting code; enter '--' alone on the line to stop or use Ctrl-D.
:x = 5
:y = 7
:if x > 5:
: x += 1
:
: y = 8
:--键盘快捷键

- Jupyter notebooks 有另外一套庞大的快捷键。因为它的快捷键比 IPython 的变化快,建议你参阅 Jupyter notebook 的帮助文档。
魔术命令
- IPython 中特殊的命令( Python 中没有)被称作“魔术”命令。这些命令可以使普通任务更便捷,更容易控制 IPython 系统。
- 魔术命令是在指令前添加百分号
%前缀。 - 例如,可以用
%timeit(这个命令后面会详谈)测量任何 Python 语句,例如矩阵乘法,的执行时间:
In [10]: import numpy as np
In [11]: a = np.random.randn(100, 100)
In [12]: %timeit np.dot(a,a)
53.5 µs ± 451 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
- 魔术命令可以被看做IPython中运行的命令行。许多魔术命令有“命令行”选项,可以通过?查看:
In [21]: %debug?
Docstring:
::
%debug [--breakpoint FILE:LINE] [statement [statement ...]]
Activate the interactive debugger.
This magic command support two ways of activating debugger.
One is to activate debugger before executing code. This way, you
can set a break point, to step through the code from the point.
You can use this mode by giving statements to execute and optionally
a breakpoint.
The other one is to activate debugger in post-mortem mode. You can
activate this mode simply running %debug without any argument.
If an exception has just occurred, this lets you inspect its stack
frames interactively. Note that this will always work only on the last
traceback that occurred, so you must call this quickly after an
exception that you wish to inspect has fired, because if another one
occurs, it clobbers the previous one.
If you want IPython to automatically do this on every exception, see
the %pdb magic for more details.
positional arguments:
statement Code to run in debugger. You can omit this in cell
magic mode.
optional arguments:
--breakpoint , -b
Set break point at LINE in FILE.
- 魔术函数默认可以不用百分号,只要没有变量和函数名相同。这个特点被称为“自动魔术”,可以用
%automagic打开或关闭。 - IPython 的文档可以在 shell 中打开,我建议你用
%quickref或%magic学习下所有特殊命令。

集成 Matplotlib
- IPython 在分析计算领域能够流行的原因之一是它非常好的集成了数据可视化和其它用户界面库,比如 matplotlib。
%matplotlib魔术函数配置了 IPython shell 和 Jupyter notebook 中的matplotlib。这点很重要,其它创建的图不会出现(notebook)或获取 session的控制,直到结束(shell)。- 在 IPython shell 中,运行
%matplotlib可以进行设置,可以创建多个绘图窗口,而不会干扰控制台 session:
In [31]: %matplotlib
Using matplotlib backend: TkAgg
- 在 JUpyter 中,命令有所不同
%matplotlib inline%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.plot(np.random.randn(50).cumsum())[]
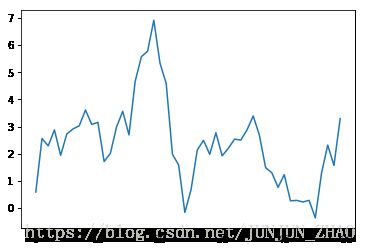
2.3 Python语法基础
- 语言的语义 ,Python的语言设计强调的是可读性、简洁和清晰。
- 使用缩进,而不是括号,Python 使用空白字符(tab 和空格)来组织代码,而不是像其它语言,比如 R、C++、JAVA 和 Perl 那样使用括号。
- 强烈建议你使用四个空格作为默认的缩进,可以使用tab代替四个空格。
- 万物皆对象,Python语言的一个重要特性就是它的对象模型的一致性。每个数字、字符串、数据结构、函数、类、模块等等,都是在Python解释器的自有“盒子”内,它被认为是Python对象。
- 注释 (略)
- 函数和对象方法调用(略)
- 变量和参数传递(略)
- 当你将对象作为参数传递给函数时,新的局域变量创建了对原始对象的引用,而不是复制。如果在函数里绑定一个新对象到一个变量,这个变动不会反映到上一层。因此可以改变可变参数的内容。假设有以下函数:
In [1]: def append_element(some_list, element):
...: some_list.append(element)
...:
In [2]: data = [1, 2, 3]
In [3]: append_element(data, 4)
In [4]: data
Out[4]: [1, 2, 3, 4]
- 动态引用,强类型 ,Python 被认为是强类型化语言,意味着每个对象都有明确的类型(或类),默许转换只会发生在特定的情况下,例如:
In [9]: a = 4.5
In [10]: b = 2
In [11]: print('a is {0}, b is {1}'.format(type(a), type(b)))
a is <class 'float'>, b is <class 'int'>
In [12]: a / b
Out[12]: 2.25
- isinstance 函数检查对象是某个类型的实例:
In [13]: a = 5
In [14]: isinstance(a, int)
Out[14]: True
- isinstance 可以用类型元组,检查对象的类型是否在元组中:
In [15]: a = 5; b = 4.5
In [16]: isinstance(a, (int, float))
Out[16]: True
In [18]: isinstance(b, (bool, int))
Out[18]: False
- 属性和方法 ,Python 的对象通常都有属性(其它存储在对象内部的 Python 对象)和方法(对象的附属函数可以访问对象的内部数据)。可以用 obj.attribute_name 访问属性和方法
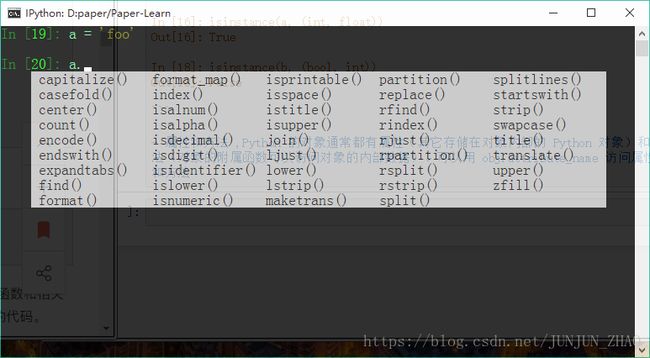
- 也可以用getattr函数,通过名字访问属性和方法:
In [23]: getattr(a,'split')
Out[23]: <function str.split>
- 鸭子类型,经常地,你可能不关心对象的类型,只关心对象是否有某些方法或用途。这通常被称为“鸭子类型”,来自“走起来像鸭子、叫起来像鸭子,那么它就是鸭子”的说法。
例如,你可以通过验证一个对象是否遵循迭代协议,判断它是可迭代的。对于许多对象,这意味着它有一个
__iter__魔术方法,其它更好的判断方法是使用 iter 函数这个函数会返回字符串以及大多数Python集合类型为True:
In [24]: def isiterable(obj):
...: try:
...: iter(obj)
...: return True
...: except TypeError: # not iterable
...: return False
...:
In [25]: isiterable('a string')
Out[25]: True
In [26]: isiterable([2,3,4,5])
Out[26]: True
In [28]: isiterable(6)
Out[28]: False
In [29]: p = 6
In [30]: isiterable(p)
Out[30]: False
In [31]: p = '6'
In [32]: isiterable(p)
Out[32]: True
- 我总是用这个功能编写可以接受多种输入类型的函数。常见的例子是编写一个函数可以接受任意类型的序列(list、tuple、ndarray)或是迭代器。你可先检验对象是否是列表(或是NUmPy数组),如果不是的话,将其转变成列表:
In [33]: if not isinstance(x, list) and isiterable(x):
...: x = list(x)引入
- 在 Python 中,模块就是一个有.py扩展名、包含 Python 代码的文件。假设有以下模块:
# some_module.py
PI = 3.14159
def f(x):
return x + 2
def g(a, b):
return a + b
如果想从同目录下的另一个文件访问 some_module.py 中定义的变量和函数,可以:
In [4]: import some_module
In [5]: result = some_module.f(5)
In [6]: result
Out[6]: 7
In [7]: pi = some_module.PI
In [8]: pi
Out[8]: 3.14159
In [9]: from some_module import f,g,PI
In [10]: result = g(5,PI)
In [11]: result
Out[11]: 8.14159
- 使用 as 关键词,你可以给引入起不同的变量名:
import some_module as sm
from some_module import PI as pi, g as gf
r1 = sm.f(pi)
r2 = gf(6, pi)
- 二元运算符和比较运算符
- 要判断两个引用是否指向同一个对象,可以使用is方法。is not可以判断两个对象是不同的
In [14]: c =list(a)
In [15]: type(a)
Out[15]: list
In [16]: type(b)
Out[16]: list
In [17]: type(c)
Out[17]: list
In [18]: a is b
Out[18]: True
In [19]: a is c
Out[19]: False
In [20]: a is not c
Out[20]: True
- 因为 list 总是创建一个新的 Python 列表(即复制),我们可以断定 c 是不同于 a的。使用 is 比较与
==运算符不同,如下:
In [40]: a == c
Out[40]: True- is 和 is not 常用来判断一个变量是否为 None,因为只有一个 None 的实例:
In [22]: a = None
In [23]: a is None
Out[23]: True

- 可变与不可变对象
- Python中的大多数对象,比如列表、字典、NumPy数组,和用户定义的类型(类),都是可变的。意味着这些对象或包含的值可以被修改
In [29]: a_list = ['foo', 2, [4,5]]
In [30]: a_list[2]
Out[30]: [4, 5]
In [31]: a_list[2] = (3,4)
In [32]: a_list
Out[32]: ['foo', 2, (3, 4)]
In [33]: a = (3,4)
In [34]: type(a)
Out[34]: tuple
- 其它的,例如 字符串 和 元组,是不可变的:
In [35]: a_tuple = (3, 5, (4,5))
In [36]: a_tuple[1] = 'what'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
input -36-785d8261e70a> in <module>()
----> 1 a_tuple[1] = 'what'
TypeError: 'tuple' object does not support item assignment
In [37]:
标量类型
- Python 的标准库中有一些内建的类型,用以处理数值数据、字符串、布尔值,和日期时间。这些单值类型被称为标量类型,本书中称其为标量。
- 日期和时间处理会另外讨论,因为它们是标准库的datetime模块提供的。

数值类型
- Python的主要数值类型是 int 和 float 。int可以存储任意大的数
- 浮点数使用 Python 的 floa t类型。每个数都是双精度(64位)的值。也可以用科学计数法表示
- 要获得C-风格的整除(去掉小数部分),可以使用底除运算符//
字符串
- 单引号,双引号,三引号
- 字符串 c 实际包含四行文本,”“”后面和 lines 后面的换行符。可以用 count 方法计算 c 中的新的行
In [1]: c = """
...: This is a long string that
...: spans multiple lines
...: """
In [2]: c.count('\n')
Out[2]: 3
- Python 的字符串是不可变的,不能修改字符串
- 许多Python对象使用 str 函数可以被转化为字符串
In [2]: c.count('\n')
Out[2]: 3
In [3]: a = 5.6
In [4]: s = str(a)
In [5]: type(s)
Out[5]: str
In [6]: type(a)
Out[6]: float
- 字符串是一个序列的 Unicode 字符,因此可以像其它序列,比如列表和元组(下一章会详细介绍两者)一样处理:
In [7]: s = 'python'
In [8]: list(s)
Out[8]: ['p', 'y', 't', 'h', 'o', 'n']
In [9]: s[:3]
Out[9]: 'pyt'
In [10]: s[0:3]
Out[10]: 'pyt'
In [11]: s[::]
Out[11]: 'python'
In [12]: s[3:]
Out[12]: 'hon'
- 反斜杠是转义字符,意思是它备用来表示特殊字符,比如换行符\n或Unicode字符。要写一个包含反斜杠的字符串,需要进行转义:
In [13]: s = '12//14'
In [14]: s
Out[14]: '12//14'
In [15]: s = '12\\14'
In [16]: s
Out[16]: '12\\14'
In [17]: print(s)
12\14
- 如果字符串中包含许多反斜杠,但没有特殊字符,这样做就很麻烦。幸好,可以在字符串前面加一个r,表明字符就是它自身:r 表示 raw。
In [20]: s = r'this\has\no\special\characters'
In [21]: s
Out[21]: 'this\\has\\no\\special\\characters'
In [22]: print(s)
this\has\no\special\characters
- 将两个字符串合并
+,会产生一个新的字符串 - 字符串的模板化或格式化,是另一个重要的主题。Python 3拓展了此类的方法,这里只介绍一些。字符串对象有format方法,可以替换格式化的参数为字符串,产生一个新的字符串:
In [24]: template = '{0:.2f} {1:s} are worth US${2:d}'
在这个字符串中,
- {0:.2f}表示格式化第一个参数为带有两位小数的浮点数。
- {1:s}表示格式化第二个参数为字符串。
- {2:d}表示格式化第三个参数为一个整数。
字符串格式化是一个很深的主题,有多种方法和大量的选项,可以控制字符串中的值是如何格式化的。推荐参阅 Python 官方文档。
字节和 Unicode
- 在 Python 3 及以上版本中,Unicode 是一级的字符串类型,这样可以更一致的处理 ASCII 和 Non-ASCII 文本。
In [26]: val = "español"
In [27]: val
Out[27]: 'español'
In [28]: val_utf8 = val.encode('utf-8')
In [29]: val_utf8
Out[29]: b'espa\xc3\xb1ol'
In [30]: type(val_utf8)
Out[30]: bytes
- 如果你知道一个字节对象的 Unicode 编码,用 decode 方法可以解码:
In [31]: val_utf8.decode('utf-8')
Out[31]: 'español'
- 虽然 UTF-8 编码已经变成主流,,但因为历史的原因,你仍然可能碰到其它编码的数据:
In [37]: val.encode('latin1')
Out[37]: b'espa\xf1ol'
In [38]: val.encode('utf-16')
Out[38]: b'\xff\xfee\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
In [39]: val.encode('utf-16le')
Out[39]: b'e\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
- 工作中碰到的文件很多都是字节对象,盲目地将所有数据编码为 Unicode 是不可取的。 虽然用的不多,你可以在字节文本的前面加上一个b:
In [40]: bytes_val = b'this is bytes'
In [41]: bytes_val
Out[41]: b'this is bytes'
In [42]: decode = bytes_val.decode('utf-8')
In [43]: decode # this is str (Unicode) now
Out[43]: 'this is bytes'
- 布尔值 Python 中的布尔值有两个,True 和 False。比较和其它条件表达式可以用 True 和 False 判断。布尔值可以与 and 和 or 结合使用
类型转换 str、bool、int 和 float也是函数,可以用来转换类型
bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。
In [44]: True and True
Out[44]: True
In [45]: False or True
Out[45]: True
In [46]: False and False
Out[46]: False
In [47]: s = '3.14159'
In [48]: fval = float(s)
In [49]: type(fval)
Out[49]: float
In [50]: int(fval)
Out[50]: 3
In [51]: bool(fval)
Out[51]: True
In [52]: bool(0)
Out[52]: False
- None 是 Python 的空值类型。如果一个函数没有明确的返回值,就会默认返回None,None 也常常作为函数的默认参数
In [55]: c
Out[55]: True
In [56]:
In [56]: a = None
In [57]: a is None
Out[57]: True
In [58]: b = 5
In [59]: b is not None
Out[59]: True
In [63]: def add_and_maybe_multiply(a, b, c=None):
...: result = a + b
...: if c is not None:
...: result = result * c
...: return result
...:
In [64]: add_and_maybe_multiply(4,5,7)
Out[64]: 63
In [65]: add_and_maybe_multiply(4,5,None)
Out[65]: 9
In [66]:
- 另外,None 不仅是一个保留字,还是唯一的 NoneType 的实例:
In [66]: type(None)
Out[66]: NoneType
日期和时间
- Python 内建的 datetime 模块提供了 datetime、date 和 time 类型。datetime类型结合了 date 和 time,是最常使用的
In [72]: from datetime import datetime, date, time
In [73]: dt = datetime(2018, 3, 30, 9, 36 ,21)
In [74]: dt.day
Out[74]: 30
In [75]: dt.month
Out[75]: 3
In [76]: dt.year
Out[76]: 2018
In [77]: dt.minute
Out[77]: 36
- 根据 datetime 实例,你可以用 date 和 time 提取出各自的对象
In [78]: dt.date()
Out[78]: datetime.date(2018, 3, 30)
In [79]: dt.time()
Out[79]: datetime.time(9, 36, 21)
- strftime 方法可以将 datetime 格式化为字符串
In [83]: dt.strftime('%m/%d/%Y %H:%M')
Out[83]: '03/30/2018 09:36'
In [84]: dt.strftime('%y/%m/%d %H:%M')
Out[84]: '18/03/30 09:36'
In [85]: dt.strftime('%Y/%m/%d %H:%M')
Out[85]: '2018/03/30 09:36'
- strptime 可以将字符串转换成 datetime 对象
In [90]: datetime.strptime('20180330', '%Y%m%d')
Out[90]: datetime.datetime(2018, 3, 30, 0, 0)

- 当你聚类或对时间序列进行分组,替换 datetimes 的 time 字段有时会很有用。例如,用 0 替换分和秒:
In [98]: dt.replace(minute=0, second=0)
Out[98]: datetime.datetime(2018, 3, 30, 9, 0)
In [99]: dt.replace(minute=1, second=1)
Out[99]: datetime.datetime(2018, 3, 30, 9, 1, 1)
因为 datetime.datetime 是不可变类型,上面的方法会产生新的对象
两个 datetime 对象的差会产生一个 datetime.timedelta 类型
In [100]: dt2 = datetime(2018,2, 15, 22, 30)
In [101]: delta = dt2 -dt
In [102]: delta
Out[102]: datetime.timedelta(-43, 46419)
In [103]: type(delta)
Out[103]: datetime.timedelta
In [104]: dt
Out[104]: datetime.datetime(2018, 3, 30, 9, 36, 21)
结果 timedelta(-43, 46419) 指明了 timedelta 将-43天、46419 秒的编码方式。
将 timedelta 添加到 datetime,会产生一个新的偏移 datetime:
In [104]: dt
Out[104]: datetime.datetime(2018, 3, 30, 9, 36, 21)
In [105]: dt + delta
Out[105]: datetime.datetime(2018, 2, 15, 22, 30)
控制流
- Python 有若干内建的关键字进行条件逻辑、循环和其它控制流操作。
- if、elif 和 else
- if 后面可以跟一个或多个 elif,所有条件都是 False 时,还可以添加一个else:
- 如果某个条件为 True,后面的 elif 就不会被执行。当使用 and 和 or时,复合条件语句是从左到右执行:
- 也可以把比较式串在一起:
In [120]: 4 > 3 > 2 > 1
Out[120]: True
- for 循环 ,for 循环是在一个集合(列表或元组)中进行迭代,或者就是一个迭代器。for 循环的标准语法是:
for value in collection:
# do something with value- 你可以用 continue 使 for 循环提前,跳过剩下的部分。看下面这个例子,将一个列表中的整数相加,跳过 None:
In [108]: sequence = [1, 2, None, 4, None, 5]
In [109]: total = 0
In [110]: for value in sequence:
...: if value is None:
...: continue
...: total += value
- 可以用 break 跳出 for 循环。下面的代码将各元素相加,直到遇到 5:
In [111]: sequence = [1, 2, 0, 4, 6, 5, 2, 1]
In [112]: total_value_5 = 0
In [113]: for value in sequence:
...: if value == 5:
...: break
...: total_value_5 += value
- break 只中断 for 循环的最内层,其余的 for 循环仍会运行:
In [114]: for i in range(4):
...: for j in range(4):
...: if j > i:
...: break
...: print((i,j))
...:
(0, 0)
(1, 0)
(1, 1)
(2, 0)
(2, 1)
(2, 2)
(3, 0)
(3, 1)
(3, 2)
(3, 3)
- 如果集合或迭代器中的元素序列(元组或列表),可以用 for 循环将其方便地拆分成变量:
for a, b, c in iterator:
# do something
- While 循环 while 循环指定了条件和代码,当条件为 False 或用 break 退出循环,代码才会退出:
x = 256
total = 0
while x > 0:
if total > 500:
break
total += x
x = x // 2
- pass 是 Python 中的非操作语句。代码块不需要任何动作时可以使用(作为未执行代码的占位符);因为 Python 需要使用空白字符划定代码块,所以需要 pass:
if x < 0:
print('negative!')
elif x == 0:
# TODO: put something smart here
pass
else:
print('positive!')
range 函数返回一个迭代器,它产生一个均匀分布的整数序列:
range 的三个参数是(起点,终点,步进)
In [124]: range(10)
Out[124]: range(0, 10)
In [125]: print(range(10))
range(0, 10)
In [126]: list(range(10))
Out[126]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [127]: list(range(0,20, 5))
Out[127]: [0, 5, 10, 15]
In [128]: list(range(10, 2, -2))
Out[128]: [10, 8, 6, 4]
- range 产生的整数不包括终点。range的常见用法是用序号迭代序列:
seq = [1, 2, 3, 4]
for i in range(len(seq)):
val = seq[i]
- 可以使用 list 来存储 range 在其他数据结构中生成的所有整数,默认的迭代器形式通常是你想要的。下面的代码对 0 到 99999 中 3 或 5 的倍数求和,虽然range可以产生任意大的数,但任意时刻耗用的内存却很小。
In [129]: sum = 0
In [130]: for i in range(100000):
...: if i % 3 == 0 or i % 5 ==0:
...: sum += i
...:
In [131]: sum
Out[131]: 2333316668
三元表达式
- Python 中的三元表达式可以将 if-else 语句放到一行里。语法如下:
value = true-expr if condition else false-expr
In [132]: x = 5
In [133]: 'None-negative' if x>=0 else 'Negative'
Out[133]: 'None-negative'